






MySQL数据库
一、MySQL介绍
1)查询IP地址
在命令提示框中输入:
ping 域名即可查询
补充:
1.查询IP地址时不一定能查到,原因:
防止非法人员攻击服务器
IP地址已经进行加密
2.查询的IP地址不一定准确((使用其他没有分配的地址))
2)访问服务器
-
通过域名访问:百度一下,你就知道
-
通过IP地址访问:https://127.0.0.1
补充:
1.访问特定服务的:加端口号(类似医生分眼科、神经科、内科、外科)
2.解析网址URL:
https:// www. baidu.com :8090
通信协议 web协议 域名 端口号
3.自己电脑的域名:localhost
4.自己电脑的IP:127.0.0.1
5.获取自己计算机在局域网中的IP地址:(别人可以通过IP访问你的服务器,只要你打开)
命令提示框中输入:
ipconfig获取IP地址https://ip地址:端口号
3)数据的存储形式
-
内存(加载资源在缓冲区,自动清除)
-
文件(磁盘)
-
第三方服务器
-
数据库服务器
4)数据库
1.什么是数据库
数据库是按照一定的形式来组织、存储数据的,目的是为了对数据进行方便操作-------增删改查
2.数据库发展历史
网状数据库------->层次性数据库----->关系型数据库------>非关系数据库
MySQL(免费)、oracle ..... redits
常见关系数据库:
-
SQlite:微型数据库,常用于移动设备
-
MySQL:开源中小系统 ,用于各种系统
-
postgreSQL:开源中小型数据库
-
SQL Server:微软中型数据库,只能用于Windows系统
-
Oracle:中大型数据库,用于各种系统
..............
关系型数据库(mysql)
关系型数据库的逻辑结构
server------>Database--->Table----->Row------>colum
-
服务器 开启服务(存储/维护数据) mysqld.exe
-
客户端 连接服务器(可以使用增删改查) mysql.exe
3)mysql发展历史
-
1996年,瑞典 MySQL AB公司发展开源MySQL数据库,做的相当好
-
2008被sun公司收购
-
sun被oracle公司收购,oracle数据库收费,但可以使用MySQL数据库(知识更新速度慢)
-
MySQL以前的员工不乐意这一做法,以女儿名字Maria 和 DB命名Maria DB数据库,并维持更新(兼容MySQL)
二、MySQL使用
1)进入
交互模式:mysql.exe -hlocalhost -P3306 -uroot -p (简写:mysql -uroot)
客户端 域名 端口号 用户名 密码
脚本模式:mysql -uroot<拖拽文件即可复制路径
2)退出
quit;
3)常用命令
-
show databases; 显示所有数据库
-
use 数据库名 ; 进入某一数据库
-
show tables; 显示所有表
-
desc 表名; 显示某张表头
使用:临时查看数据
三、SQL命令
1)SQL语法规范
-
一条SQL语句跨越多行,以英文的分号结束
-
中途语句出错,以下的语句都不会执行
-
建议关键字(固定不变的内容)大写,非关键字小写;
-
不区分大小写
-
单行注释# ;多行注释/* 注释内容*/
2)常用SQL(Structured Query Language 结构化查询语言)命令:用于操作关系数据库
1.创建数据库
create database 数据库名;
2.删除数据库
drop database if exists 数据库名;(存在数据库丢弃)
加if的条件是先判断是否存在,防止报错
a.创建数据表
-
创建表头
create table 表名(
表头名 INT,
...........
);
create table student(
id INT,
name VARCHAR(8), #variable character缩写,建议先存英文
sex VARCHAR(1),
score INT #存储整型数据
);-
插入数据
insert into student values(
"1",
"tom",
"M",
"59"
);
insert into student values(
"2",
"jerry",
"f",
"68"
);
insert into student values(
"3",
"marry",
"M",
"49"
);
#插入多组数据简写形式(尽量不建议这样写,维护困难)
insert into student values(),(),.....();补充:
建议将电话号码、邮箱、密码等存储为字符串形式,如果写成整形,会出现以下错误:
位数过多存储不够,显示存储最大数
如果开头是0,默认存储为单个0
b、删除数据
delete from 表名 while 条件控制删除的值;
c.查询数据
select * from student;
(建议不在脚本中查询,中文会乱码,即使设置了)
d、修改数据
update 表名 set 对应表头名="修改的值",对应表头名="修改的值",....... while 条件控制需要修改的值 ;
补充:
删除数据和修改数据一定要使用条件,否则应用到全部
3)标准SQL语句分类:
DDL: Data Define Language 定义数据结构
create/ drop/alter(修改)
DML: Data Manipulate Language 操作数据
insert/update/delete
DQL : Data Query Language 查询数据
select
DCL:Data Control Language 控制用户权限
grant(授权)/revoke(收权)
【实现不同用户使用数据,防止被泄露】
4)中文乱码问题
1、计算机存储字符
-
美国:(ASCLL码:总共有128个)
-
欧洲:(Latin-1):总共256个,兼容ASCLL
-
中国:(GB2312):常用6000多汉字进行编码,兼容ASCLL
(GBK):对两万多汉字进行编码,兼容ASCLL,GB2312
Unicode:对世界主流国家语言进行编码,兼容ASCLL,不兼容GB2312;具体分为utf-8\utf-16\utf-32存储方案
MySQL欧洲发明的,默认使用Latin-1
2、解决乱码方案:
脚本文件(设置编码格式为UTF8)-----提交------>客户端-------提交------>数据库
所以要解决上面的问题
-
脚本另存为utf8;
-
客户端设置utf8;
set names utf8;(写在脚本文件开头)
-
浏览器设置utf8
在创建数据库时并设置编码格式
create database student charset=utf8;

5)软件实现流程:
1.软件定义期
(1)可行性研究阶段
技术/人力/设备/资金/时间/回报率/政策/风俗...(2)需求分析阶段
包括功能性需求分析和非功能性需求分析
非功能性需求是保证功能性需求运转的前提。2.软件开发期
(3)概要设计阶段 —— 架构师
子系统、模块、技术选型...(4)详细设计阶段 —— 产品经理
产品的原型(5)编码实现阶段
UI设计 —— 效果图
前端 —— 将效果图转为html,css,js文件
后端 —— 为前端提供项目所需要的数据</span></span>(6)测试阶段 —— 软件测试工程师
软件测试3.软件维护期
(7)部署阶段 —— 运维工程师
部署到服务器(8)软件维护阶段
三.学子商城功能性需求分析
前台子系统:www.codeboy.com:9999
后台子系统:www.codeboy.com:9999/admin/login.html
-
前台子系统
-
商品模块:首页、列表、详情..
-
用户模块:注册、登录、个人中心、收藏夹...
-
购物车模块:添加、修改、删除...
-
后台子系统
-
商品模块:添加、修改、删除、搜索...
-
用户模块:列表、修改、删除、详情、搜索...
-
订单模块:列表、修改、删除、详情、搜索
-
移动端子系统
商品模块:首页、列表、详情..
-
用户模块:注册、登录、个人中心、收藏夹...
-
购物车模块:添加、修改、删除...
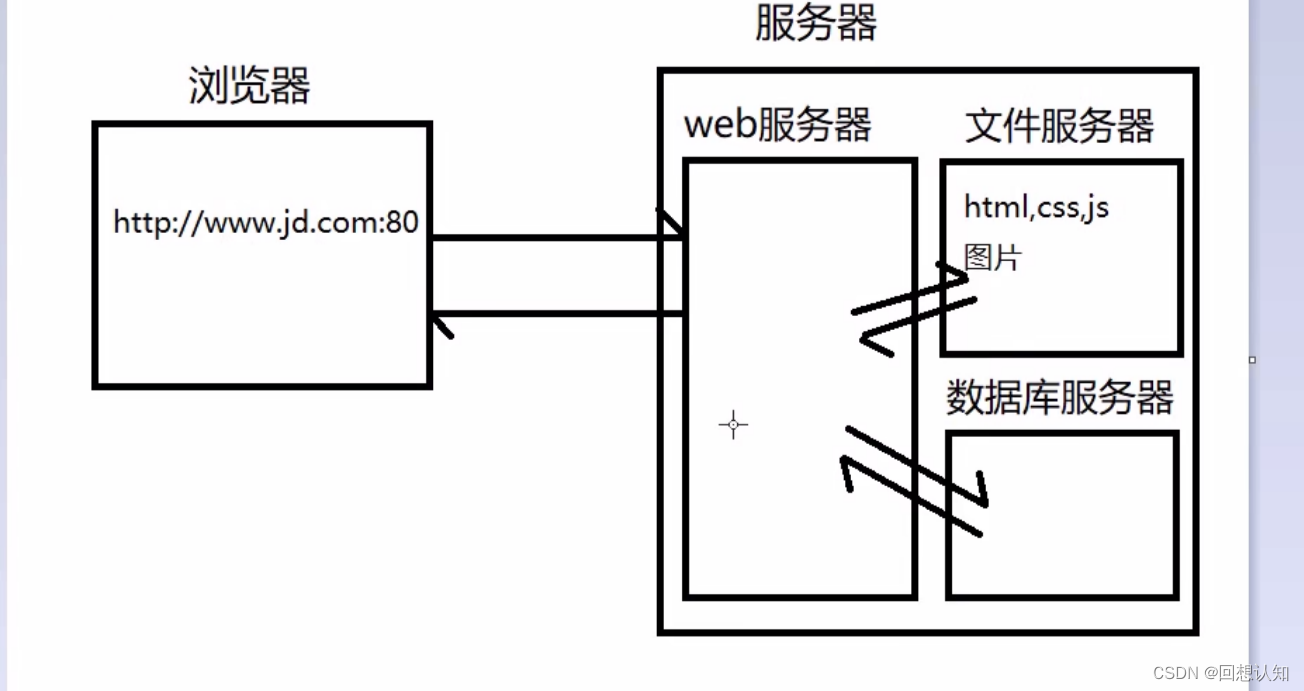
四.服务器
硬件:就是一台计算机,访问一个网站就是在访问一台远程计算机
软件:计算机提供多种服务,例如:WEB服务、游戏服务、数据库服务、视频服务器...
淘宝部署到服务器
6)MySQL中的列类型
创建数据表的时候,指定的列可以存储的数据类型
create table info(
id 列类型,
........
);一、分类理解
-
TB GB MB KB
换算单位:1024,即1GB=1024MB
-
Byte Bit
字节 位(二进制的0或1)
1 Byte=8 Bit
1.数值型:值可以使用引号包裹(建议不包裹)
-
TINYINT 微整型 1字节 存储位数2^8
-
SMALLINT 小整形 2字节 2^16 -32768~32767(6万多)
-
INT 整型 4字节 2^32 -2147483648~2147483647(42亿多)
-
BIGINT 大整形 8字节 2^64 几乎用不到
-
FLOAT 单精度浮点型 4字节 最多3.4E38 ,会产生计算误差(原因使用科学计数法,舍去了小数位)
-
DOUBLE 双精度浮点型 8字节 范围比BIGINT更大,可能产生计算误差
-
DECIMAL(M,N) 定点小数,不会产生计算误差(常用)
M为有效位数 ;N 为小数位
-
BOOL 只有两位【2^(1/8)字节】,保存了TRUE(1) 和FALSE (0) ,但是真正存储的时候会转化为TINYINT
补充:
以上数据类型可以不用引号包裹,不会出错
bool值为指定的TRUE 或FALSE时,坚决不能包裹,否则出错;建议直接使用0或1代替(方便,不会出错)
2.日期时间型:必须使用引号
-
DATE 日期型 “2020-10-12”
-
TIME 时间型 “23:23:34”
-
DATETIME 日期时间型 “2020-10-12 23:23:34”
上面中间是空格
3.字符串类型:必须使用引号
-
VARCHAR(位数) 变长字符串
-
CHAR(位数) 定长字符串 可能会浪费资源,但是操作(增删改查)比较快,【最大位数255】;常用于定长的数据,如telphone IDcard 车牌号........
-
TEXT(位数) 最多两个G数据:2G
两者区别:未填满时
定长字符串有剩余空间会自动使用\0 填满
变长字符串有剩余空间会使用一个\0填充一个位置,代表结束
4.为什么要指定类型,还建议刚用就好?
-
节省空间,防止造成资源浪费(特别是在早期,内存和磁盘资源不是很大的时候)
-
使用较小的存储位数,查询更快
7)MySQL中的列约束(限制数据插入)
MySQL在插入数据时,进行特定的验证:只有满足条件才允许插入到数据表中,否则为非法插入
写入的位置:在列类型后面写入
1.主键约束
PRIMARY KEY
使用:
-
主键约束关键字不能重复出现(一般用在编号列)
-
约束的值不能重复出现
-
查询的记录会自动从小到大排序
-
加快查找速度
-
可以插入NULL(无法确定的数据),NULL代表任何值,重复不出错
2.非空约束 NOT NULL
-
声明后不可使用无法确定的数据:NULL
3.唯一约束 UNOQUE
-
不可插入重复的值
-
允许插入NULL,可以插入多个
4.默认值约束(DEFAULT 默认值)
使用方式:
-
插入值时指认
insert into 表 values(1,DEFAULT,.....);
-
指认确切的数据
insert into 表(表头1,表头2,........) values(......);
-
未指认的使用默认值
5.检查约束CHECK
对输入的数据进行自定义验证
-
CHECK(a>10 AND a<100)
一般不建议使用,有些甚至不支持,会降低数据的插入速度
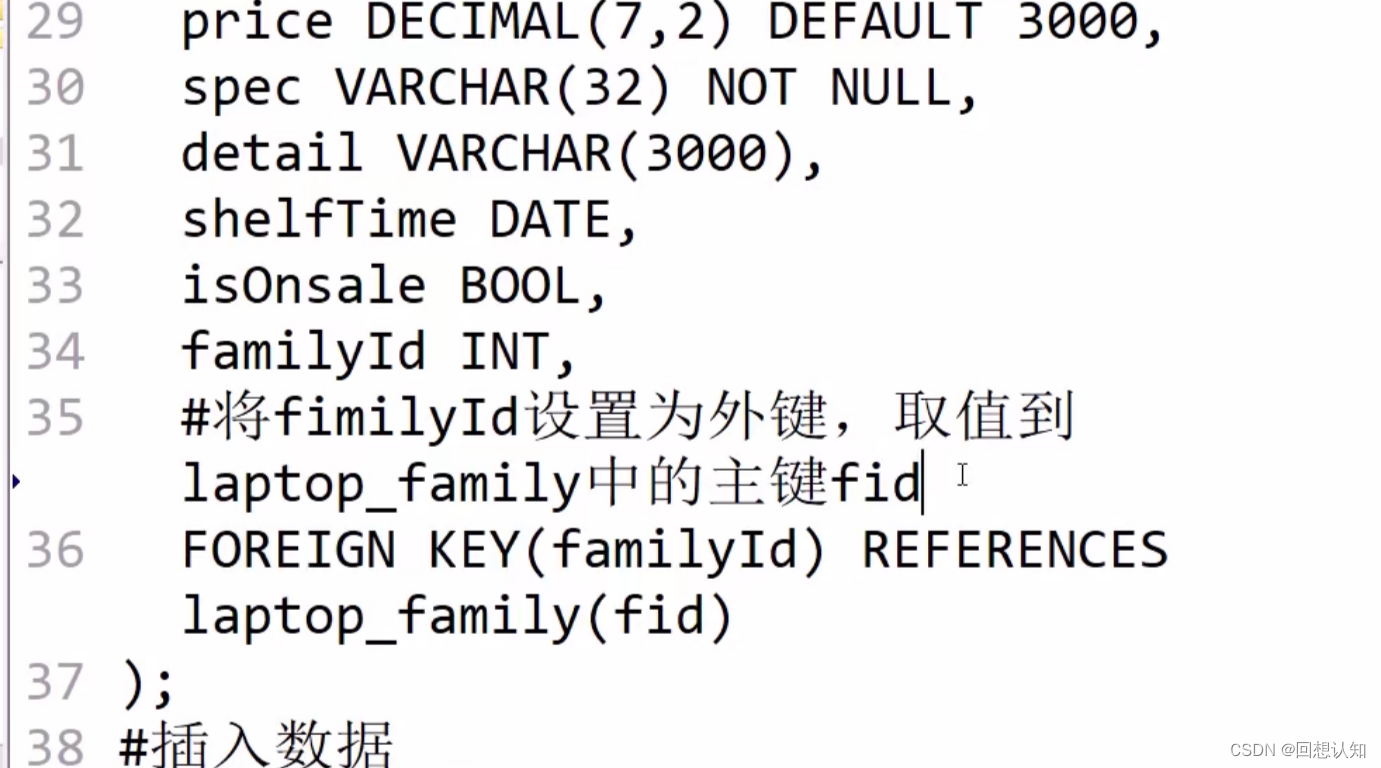
6.外键约束 FOREIGN KEY
-
取值是指定表列的数据(即必须出现过)
-
可以使用NULL
-
指定表列必须是主键约束
-
两表列数据类型必须相同
使用方式: FOREIGN KEY(外键列)REFERENCES 数据表(主键列)
7.自增列 AUTO_INCREMENT
-
自动从设置最大的值+1开始
-
如果赋值为NULl,默认把NULL看做0,之后出现的依次+1
-
适用于整数列
四、MySQL数据查询
1)简单查询
1. 查询所有列
select * from 表名;
2.查询特定列
select 列名1,列名2.... from 表名;
3.起别名 as关键字可省略,
select 列名1 as 名, 列名2 as 名...... from 表名;
4.合并相同的项
根据列属性值合并
select DISTINCT 列名 from 表名;
5.查询执行计算
select 列名1*12,列名2+500,........ from 表名;
可以用于计算工资,奖金等等
6. 对查询到的结果排序
select * from 表名 order by did ASC;
ASC:升序 ascendent
DESC:降序 descendent
order by 可以按照数值、时间日期、字符串排序(默认升序)
select * from 表名 order by 指定的列名 ASC/DESC;
2)条件查询 while
-
比较运算符:< <= > >= = !=
select * from 表名 WHILE id>20 and/or id<30;
select * from 表名 WHile 20<id <30;
-
while 列名 (not) between 起始值 and 终止值
-
while 列名 (not) in(起始值,终止值)
-
while 列名 is (not) NULL:单独对数据空的判断,其他条件不可查询NULL
-
♟♟♟模糊条件查询♟♟♟
select * from 数据表 while 列名 like "%词语%";
表示在“词语”前后有0或任意多个字符,只要含有“词语”这两个字即可
补充:
%:表示0或任意多个字符
_:表示任意1个字符
例子:
%词语:表示以“词语”两字结尾
词语%:表示以“词语”两字开头
-
♟♟♟分页查询♟♟♟
查询的结果包含很多数据,一次显示不完或不方便查看,此时就要使用分页查询
控制条件:
-
当前页码
-
每页显示数据量大小
数据条从0开始,开始(每页):每页显示条数:(页码-1)*每页数据条数
select * from 数据表 limit start,count;
start:代表每页开始的第一条数据
count:每页显示数量
以上两个变量皆为数值型数据
数据库的存储建议
-
性别:建议使用bool类型存储在数据库,后期使用数据库时使用js在进行相应的变化,因为显示要求不同,会造成后期麻烦,重复操作数据库
-
时间日期:因为存在很多格式,所以最好存储为毫秒数,后期在进行相应处理
存储毫秒数= 存储时间-计算机元年时间(1970/1/1/00:00:00)
列类型使用 BIGINT
3)复杂查询
1.聚合查询
通过聚合函数进行查询
select count(unane) from 数据表名;
聚合函数:
count():统计个数(注意:参数的值含有NULL,则不会统计,建议使用
select count(*) from 数据表名;,因为所有数据都不可能为空,起码编号不为空)sum():求和
avg():求平均
max()
min()
avg()=sum()/count()
2.分组查询
只能查询分组条件和聚合函数的组合体:增加其他查询不报错,但是显示不准确
select sex,max(salary) from 数据表名 group by sex;
补充:
提取年份:year()
提取月份:month()
3.子查询
select * from emp while depid=(select did from emp while depid=10)
后面查询的结果是前面的条件:把一个SQL语句的结果作为另一个SQL语句的查询条件
4.多表查询(多表组合查询)
select ename,did from 数据表1,数据表2 ;
此种查询会出现:笛卡尔积(卷积,分配运算符)
解决方法:增加查询条件
select ename,did from 数据表1,数据表2 while depid=did;(有主键和外键约束的条件)
但是:无法查询出含有NULL的值(其中任意一个,全部)
解决:提出新方案
(1)内连接
select ename,dname from 数据表1 inner join 数据表2 on 查询条件;
不能解决
(2)外连接
-
左外连接
select ename,dname from 数据表1 left outer join 数据表2 on 查询条件
outer可以省略
数据表1:为左侧表
显示左侧表中所有记录
-
select ename,dname from 数据表1 right outer join 数据表2 on 查询条件
显示右侧表中所有数据
数据表1:为右侧表
上面的左右针对的是紧跟from的表而言的
-
全连接:左右都显示
MySQL不支持
使用js解决:
union:合并相同记录
union all:不合并相同记录
(select ename,dname from 数据表1 left outer join 数据表2 on 查询条件)
`union [all]
(select ename,dname from 数据表1 right outer join 数据表2 on 查询条件)















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









