






环境:
确定谷歌的版本:
版本 96.0.4664.45(正式版本) (64 位)
 确定chromedriver的版本:(谷歌版本为多少就选择哪个版本的)
确定chromedriver的版本:(谷歌版本为多少就选择哪个版本的)
下载链接:CNPM Binaries Mirror
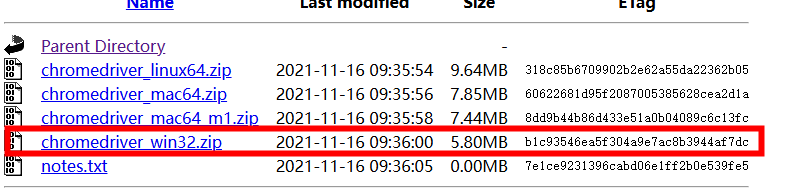 我的电脑为Windows,直接选取win32(不管是64或者32的都选择32的就可以)
我的电脑为Windows,直接选取win32(不管是64或者32的都选择32的就可以)
确定爬取的网站:
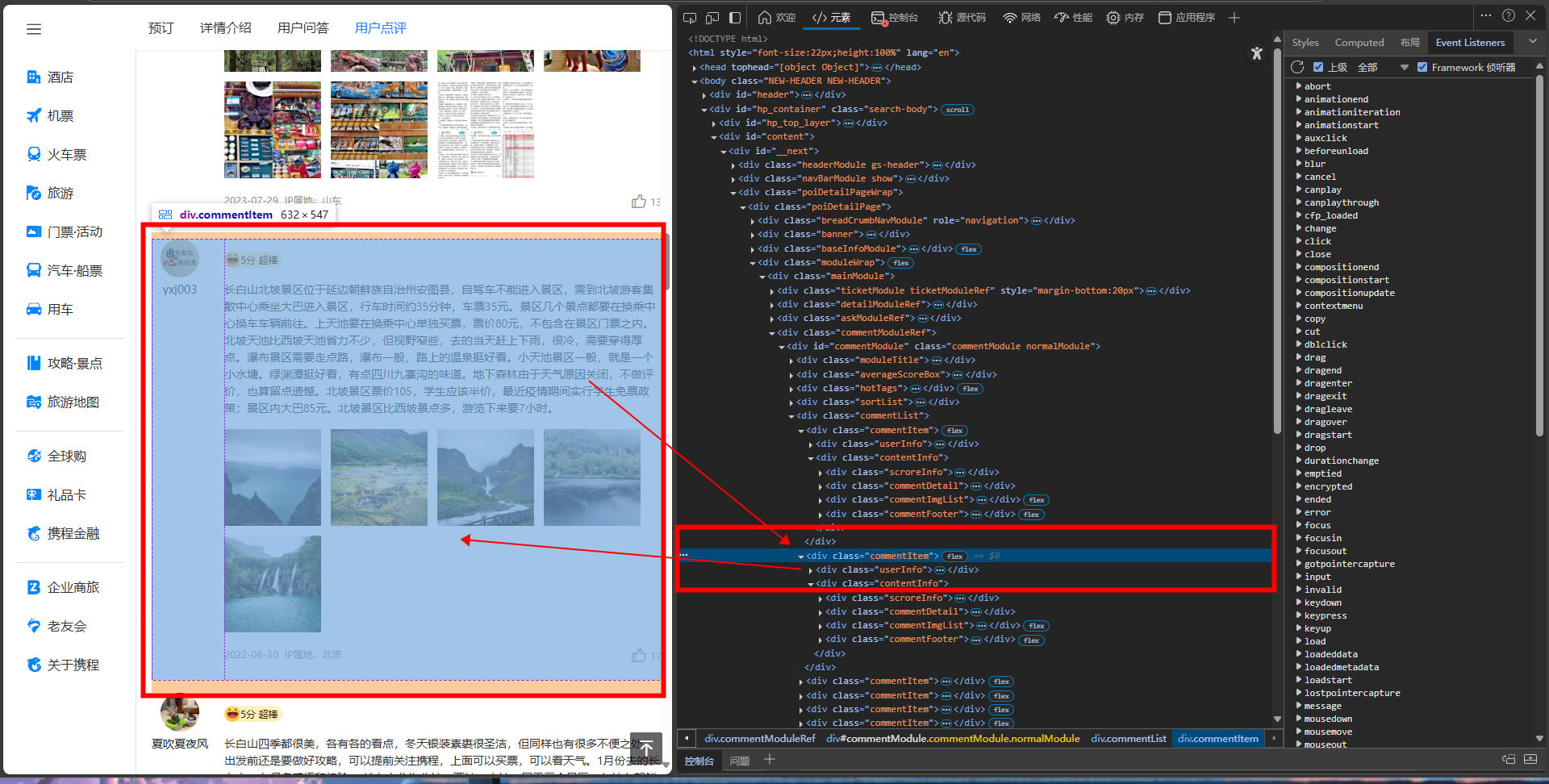
url:https://you.ctrip.com/sight/antu643/136032.html?scene=online定位爬取的元素:
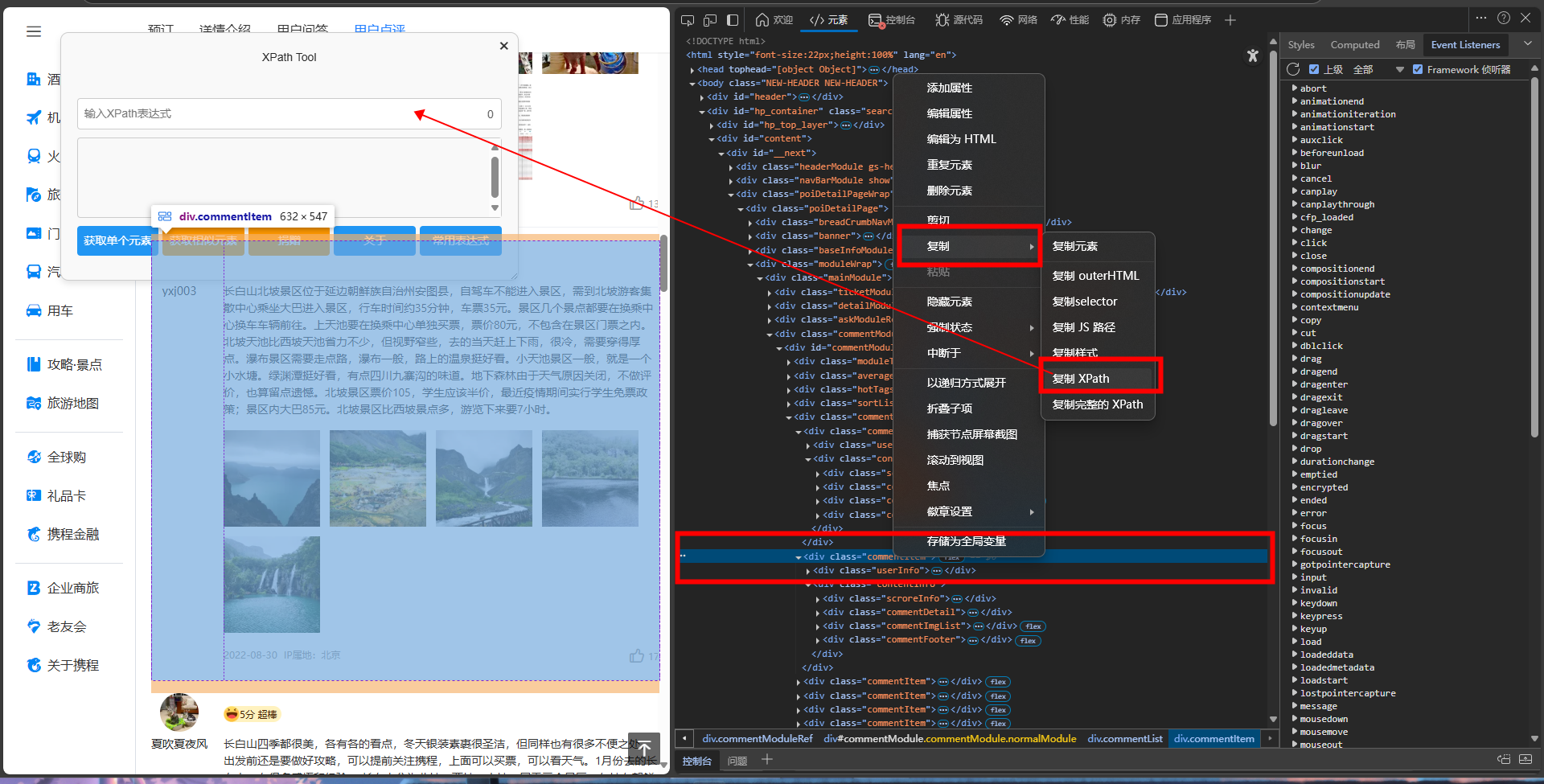
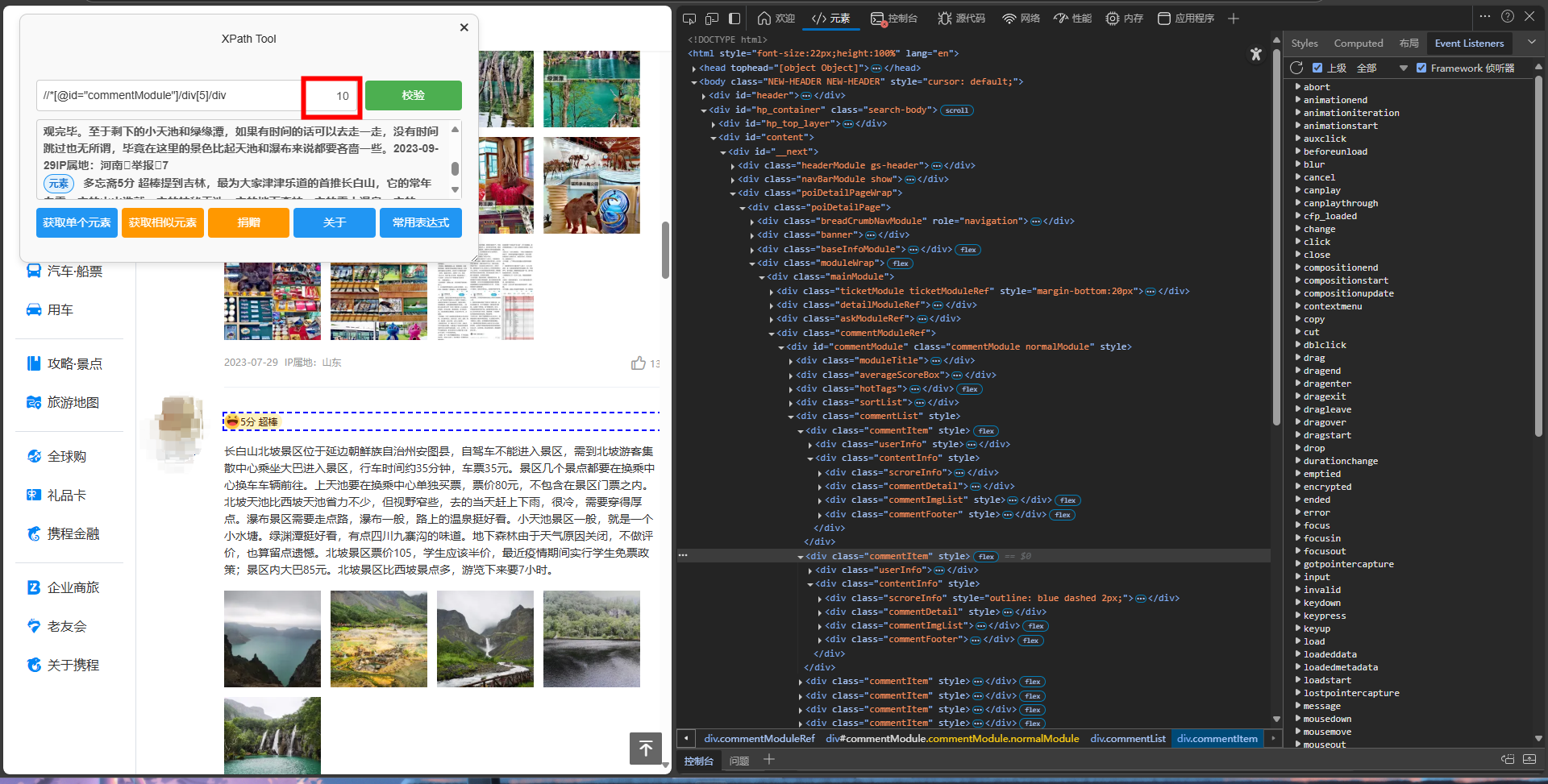
检验xpath:
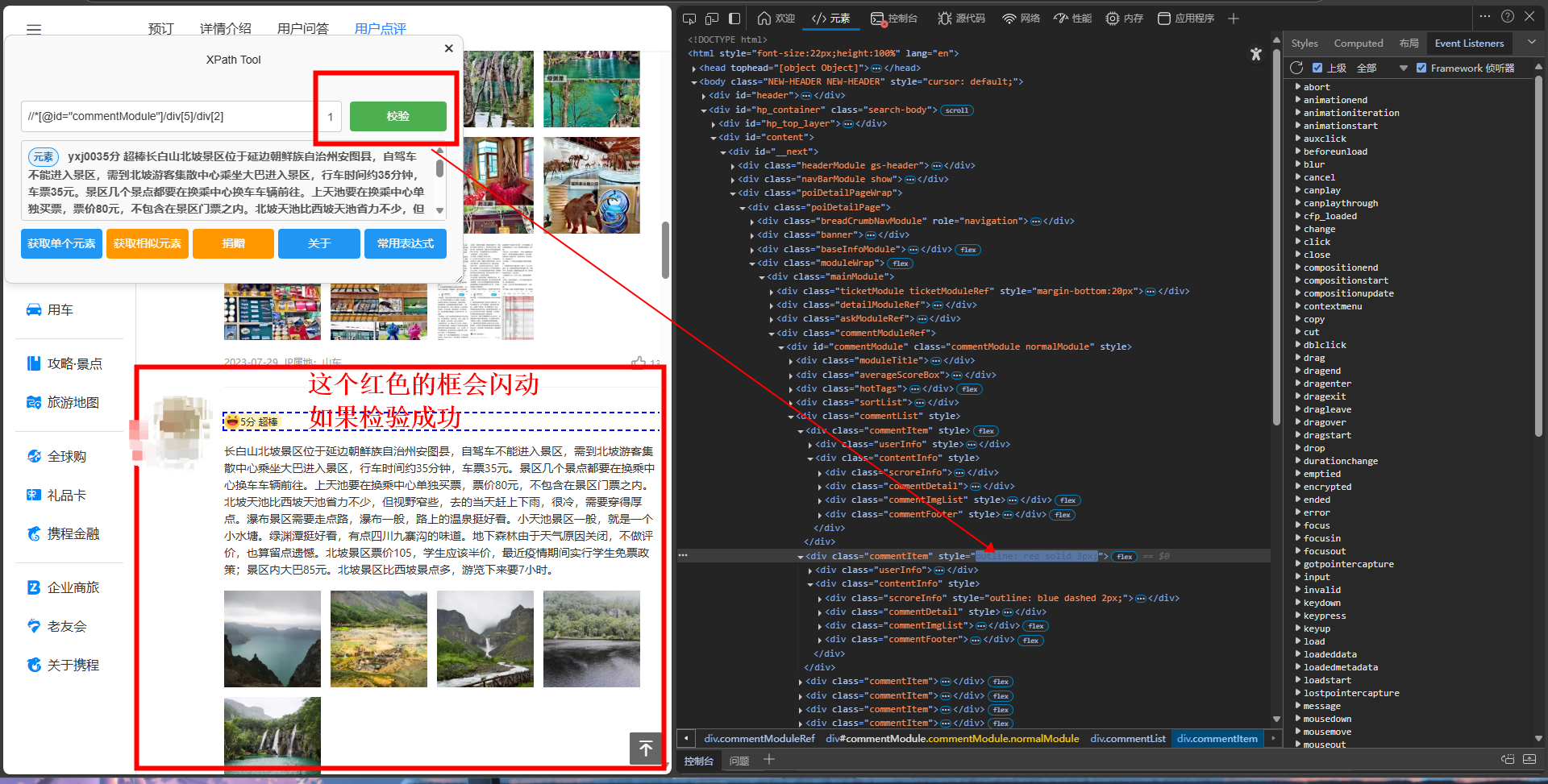
定位本页所有评论:
好了直接上代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import time
import json
import os
import random
# # 获取配置对象 => 什么样的浏览器就选择什么浏览器配置
# option = webdriver.ChromeOptions()
# option.add_experimental_option("detach", True)
#
# # 获取driver对象, 并将配置好的option传入进去
# driver = webdriver.Chrome(options=option)
# driver.get('https://you.ctrip.com/sight/antu643/136032.html?scene=online')
# time.sleep(10)
# print("=========第一次尝试=========")
# # 新增爬取文本的操作
# try:
# # 定位元素
# element = driver.find_element("xpath", '//*[@id="commentModule"]/div[5]/div[1]')
#
# # 获取文本内容
# text_content = element.text
#
# # 打印提取的文本
# print("提取到的文本内容:")
# print(text_content)
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("=========First Over!!!!=========")
# time.sleep(20)
# 新增爬取文本的操作
# print("=========第二次尝试=========")
# try:
# # 定位所有匹配的评论元素(使用 find_elements 获取列表)
# comment_elements = driver.find_elements("xpath", '//*[@id="commentModule"]/div[5]/div')
#
# # 检查是否找到了评论
# if not comment_elements:
# print("未找到评论内容!")
# else:
# # 遍历每个评论元素并提取文本
# for idx, element in enumerate(comment_elements, start=1):
# # 获取评论文本
# text_content = element.text.strip() # strip() 去除多余空格
# print(f"评论 {idx}:")
# print(text_content)
# print("-" * 50) # 分隔线
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("=========Second Over!!!=========")
# time.sleep(20)
# print("=========Try Three=========")
# # 新增爬取文本的操作
# try:
# # 定位所有匹配的评论元素(使用 find_elements 获取列表)
# comment_elements = driver.find_elements("xpath", '//*[@id="commentModule"]/div[5]/div')
#
# # 检查是否找到了评论
# if not comment_elements:
# print("未找到评论内容!")
# else:
# comments_list = [] # 存储所有评论的列表
#
# # 遍历每个评论元素并提取文本
# for idx, element in enumerate(comment_elements, start=1):
# # 获取评论文本
# text_content = element.text.strip() # strip() 去除多余空格
# print(f"评论 {idx}:")
# print(text_content)
# print("-" * 50) # 分隔线
#
# # 添加到评论列表
# comments_list.append({
# "id": idx,
# "content": text_content
# })
#
# # 保存为 JSON 文件(项目根目录)
# json_file_path = os.path.join(os.getcwd(), "comments.json")
#
# with open(json_file_path, "w", encoding="utf-8") as f:
# json.dump(comments_list, f, ensure_ascii=False, indent=4) # 格式化输出
#
# print(f"评论数据已保存至:{json_file_path}")
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("========Three Over========")
print("========Four Start========")
# 配置浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 添加随机User-Agent
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15"
]
option.add_argument(f"user-agent={random.choice(user_agents)}")
# 禁用自动化特征检测
option.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=option)
# 使用已有的date目录
date_dir = os.path.join(os.getcwd(), "date_CBSBP")
if not os.path.exists(date_dir):
raise Exception(f"目录 {date_dir} 不存在,请先创建该目录")
print(f"将使用已有目录: {date_dir}")
# 访问目标页面
driver.get('https://you.ctrip.com/sight/antu643/136032.html?scene=online')
time.sleep(10 + random.randint(1, 5)) # 随机初始等待
# 在开始爬取前点击一次指定元素
# try:
# click_element = WebDriverWait(driver, 15).until(
# EC.element_to_be_clickable((By.XPATH, '//*[@id="commentModule"]/div[4]/span[2]'))
# )
# exit()
# # click_element.click()
# # print("已成功点击评论筛选元素")
# # time.sleep(5) # 等待评论加载完成
# # except Exception as e:
# # print(f"点击评论筛选元素失败: {e}")
# # driver.quit()
# # exit()
# 存储所有评论
all_comments = []
max_pages = 150 # 最多爬取150页
current_page = 1
try:
while current_page <= max_pages:
print(f"\n========= 正在爬取第 {current_page} 页 =========")
# 随机滚动页面模拟人工操作
for _ in range(3):
driver.execute_script("window.scrollBy(0, 500)")
time.sleep(random.uniform(0.5, 2))
# 提取当前页的评论
try:
comment_elements = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.XPATH, '//*[@id="commentModule"]/div[5]/div'))
)
except Exception as e:
print(f"定位评论元素失败: {e}")
comment_elements = []
if not comment_elements:
print("未找到评论内容!尝试刷新页面...")
driver.refresh()
time.sleep(10)
continue
else:
comments_list = [] # 当前页评论列表
for idx, element in enumerate(comment_elements, start=1):
try:
text_content = element.text.strip()
print(f"评论 {idx}:")
print(text_content[:50] + "...") # 只打印前50个字符
print("-" * 50)
# 添加到当前页评论列表
comments_list.append({
"page": current_page,
"id": idx,
"content": text_content
})
except Exception as e:
print(f"提取评论{idx}时出错: {e}")
# 添加到总评论列表
all_comments.extend(comments_list)
# 每页保存到date目录
json_file_path = os.path.join(date_dir, f"comments_page_{current_page}.json")
with open(json_file_path, "w", encoding="utf-8") as f:
json.dump(comments_list, f, ensure_ascii=False, indent=4)
print(f"第 {current_page} 页评论已保存至:{json_file_path}")
# 检查是否已达到最大页数
if current_page >= max_pages:
print(f"已达到最大爬取页数 {max_pages},停止爬取。")
break
try:
# 随机等待时间
wait_time = 10 + random.randint(-5, 5)
print(f"等待{wait_time}秒后继续下一页...")
time.sleep(wait_time)
# 尝试翻页
for attempt in range(3): # 最多尝试3次
try:
# 定位页码输入框
page_input = WebDriverWait(driver, 15).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[10]/div/input'))
)
# 定位跳转按钮
page_button = WebDriverWait(driver, 15).until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[10]/div/span/button'))
)
# 输入下一页页码
for _ in range(3): # 确保输入成功
page_input.clear()
page_input.send_keys(str(current_page + 1))
time.sleep(0.5)
# 随机点击延迟
time.sleep(random.uniform(0.5, 2))
# 点击跳转按钮
driver.execute_script("arguments[0].click();", page_button)
# 等待页面加载
time.sleep(5 + random.randint(1, 3))
# 验证是否翻页成功
try:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, f'//*[@id="commentModule"]/div[5]/div'))
)
current_page += 1
break # 翻页成功,退出重试循环
except:
if attempt == 2:
raise Exception("翻页后未加载新内容")
continue
except Exception as e:
if attempt == 2: # 最后一次尝试
raise
print(f"翻页尝试 {attempt + 1} 失败: {e}")
time.sleep(5)
driver.refresh()
time.sleep(5)
except Exception as e:
print(f"翻页最终失败: {e}")
break
finally:
# 保存所有评论到date目录
all_comments_path = os.path.join(date_dir, "all_comments.json")
with open(all_comments_path, "w", encoding="utf-8") as f:
json.dump(all_comments, f, ensure_ascii=False, indent=4)
print(f"\n所有评论已保存至:{all_comments_path}")
print(f"共爬取 {len(all_comments)} 条评论。")
# 关闭浏览器
driver.quit()
print("Four Over!!!")
print("Four Over!!!")
代码前部分的注释为测试阶段,读者可以注释掉后面的去一个一个测试,最终爬取的程序就是上传程序没有注释代码
由于上面代码后面评论页数不足150页会重复爬取最后一页数据直到爬取满150页,所以下面是更新后的代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import time
import json
import os
import random
# # 获取配置对象 => 什么样的浏览器就选择什么浏览器配置
# option = webdriver.ChromeOptions()
# option.add_experimental_option("detach", True)
#
# # 获取driver对象, 并将配置好的option传入进去
# driver = webdriver.Chrome(options=option)
# driver.get('https://you.ctrip.com/sight/antu643/136032.html?scene=online')
# time.sleep(10)
# print("=========第一次尝试=========")
# # 新增爬取文本的操作
# try:
# # 定位元素
# element = driver.find_element("xpath", '//*[@id="commentModule"]/div[5]/div[1]')
#
# # 获取文本内容
# text_content = element.text
#
# # 打印提取的文本
# print("提取到的文本内容:")
# print(text_content)
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("=========First Over!!!!=========")
# time.sleep(20)
# 新增爬取文本的操作
# print("=========第二次尝试=========")
# try:
# # 定位所有匹配的评论元素(使用 find_elements 获取列表)
# comment_elements = driver.find_elements("xpath", '//*[@id="commentModule"]/div[5]/div')
#
# # 检查是否找到了评论
# if not comment_elements:
# print("未找到评论内容!")
# else:
# # 遍历每个评论元素并提取文本
# for idx, element in enumerate(comment_elements, start=1):
# # 获取评论文本
# text_content = element.text.strip() # strip() 去除多余空格
# print(f"评论 {idx}:")
# print(text_content)
# print("-" * 50) # 分隔线
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("=========Second Over!!!=========")
# time.sleep(20)
# print("=========Try Three=========")
# # 新增爬取文本的操作
# try:
# # 定位所有匹配的评论元素(使用 find_elements 获取列表)
# comment_elements = driver.find_elements("xpath", '//*[@id="commentModule"]/div[5]/div')
#
# # 检查是否找到了评论
# if not comment_elements:
# print("未找到评论内容!")
# else:
# comments_list = [] # 存储所有评论的列表
#
# # 遍历每个评论元素并提取文本
# for idx, element in enumerate(comment_elements, start=1):
# # 获取评论文本
# text_content = element.text.strip() # strip() 去除多余空格
# print(f"评论 {idx}:")
# print(text_content)
# print("-" * 50) # 分隔线
#
# # 添加到评论列表
# comments_list.append({
# "id": idx,
# "content": text_content
# })
#
# # 保存为 JSON 文件(项目根目录)
# json_file_path = os.path.join(os.getcwd(), "comments.json")
#
# with open(json_file_path, "w", encoding="utf-8") as f:
# json.dump(comments_list, f, ensure_ascii=False, indent=4) # 格式化输出
#
# print(f"评论数据已保存至:{json_file_path}")
#
# except Exception as e:
# print(f"爬取文本时出现错误: {e}")
# print("========Three Over========")
print("========Four Start========")
# 配置浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 添加随机User-Agent
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15"
]
option.add_argument(f"user-agent={random.choice(user_agents)}")
# 禁用自动化特征检测
option.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=option)
# 使用已有的date目录
date_dir = os.path.join(os.getcwd(), "date_CBSXP")
if not os.path.exists(date_dir):
raise Exception(f"目录 {date_dir} 不存在,请先创建该目录")
print(f"将使用已有目录: {date_dir}")
# 访问目标页面
driver.get('https://you.ctrip.com/sight/fusong2479/136039.html?scene=online')
time.sleep(10 + random.randint(1, 5)) # 随机初始等待
# 获取最大页数
def get_max_pages():
try:
max_page_element = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[8]/a'))
)
max_pages = int(max_page_element.text)
print(f"检测到最大页数: {max_pages}")
return max_pages
except Exception as e:
print(f"获取最大页数失败: {e}, 使用默认值150")
return 150 # 如果获取失败,使用默认值
# 存储所有评论
all_comments = []
max_pages = get_max_pages() # 动态获取最大页数
current_page = 1
try:
while current_page <= max_pages:
print(f"\n========= 正在爬取第 {current_page} 页(共{max_pages}页) =========")
# 随机滚动页面模拟人工操作
for _ in range(3):
driver.execute_script("window.scrollBy(0, 500)")
time.sleep(random.uniform(0.5, 2))
# 提取当前页的评论
try:
comment_elements = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.XPATH, '//*[@id="commentModule"]/div[5]/div'))
)
except Exception as e:
print(f"定位评论元素失败: {e}")
comment_elements = []
if not comment_elements:
print("未找到评论内容!尝试刷新页面...")
driver.refresh()
time.sleep(10)
continue
else:
comments_list = [] # 当前页评论列表
for idx, element in enumerate(comment_elements, start=1):
try:
text_content = element.text.strip()
print(f"评论 {idx}:")
print(text_content[:50] + "...") # 只打印前50个字符
print("-" * 50)
# 添加到当前页评论列表
comments_list.append({
"page": current_page,
"id": idx,
"content": text_content
})
except Exception as e:
print(f"提取评论{idx}时出错: {e}")
# 添加到总评论列表
all_comments.extend(comments_list)
# 每页保存到date目录
json_file_path = os.path.join(date_dir, f"comments_page_{current_page}.json")
with open(json_file_path, "w", encoding="utf-8") as f:
json.dump(comments_list, f, ensure_ascii=False, indent=4)
print(f"第 {current_page} 页评论已保存至:{json_file_path}")
# 检查是否已达到最大页数
if current_page >= max_pages:
print(f"已达到最大爬取页数 {max_pages},停止爬取。")
break
try:
# 随机等待时间
wait_time = 10 + random.randint(-5, 5)
print(f"等待{wait_time}秒后继续下一页...")
time.sleep(wait_time)
# 尝试翻页
for attempt in range(3): # 最多尝试3次
try:
# 定位页码输入框
page_input = WebDriverWait(driver, 15).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[10]/div/input'))
)
# 定位跳转按钮
page_button = WebDriverWait(driver, 15).until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[10]/div/span/button'))
)
# 输入下一页页码
for _ in range(3): # 确保输入成功
page_input.clear()
page_input.send_keys(str(current_page + 1))
time.sleep(0.5)
# 随机点击延迟
time.sleep(random.uniform(0.5, 2))
# 点击跳转按钮
driver.execute_script("arguments[0].click();", page_button)
# 等待页面加载
time.sleep(5 + random.randint(1, 3))
# 验证是否翻页成功
try:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, f'//*[@id="commentModule"]/div[5]/div'))
)
current_page += 1
break # 翻页成功,退出重试循环
except:
if attempt == 2:
raise Exception("翻页后未加载新内容")
continue
except Exception as e:
if attempt == 2: # 最后一次尝试
raise
print(f"翻页尝试 {attempt + 1} 失败: {e}")
time.sleep(5)
driver.refresh()
time.sleep(5)
except Exception as e:
print(f"翻页最终失败: {e}")
break
finally:
# 保存所有评论到date目录
all_comments_path = os.path.join(date_dir, "all_comments.json")
with open(all_comments_path, "w", encoding="utf-8") as f:
json.dump(all_comments, f, ensure_ascii=False, indent=4)
print(f"\n所有评论已保存至:{all_comments_path}")
print(f"共爬取 {len(all_comments)} 条评论。")
# 关闭浏览器
driver.quit()
print("Four Over!!!")
print("Four Over!!!")
最后让我们感谢工程师!!!!


















 6013
6013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









