







变量:
- 变量的名称=变量的值
不使用变量打印九次 “今天天气真好" ,如果需要变成打印"今天天气不好"需要修改九行代码
对于重复使用,并且经常需要修改的数据,可以定义为变量,来提高编程效率。
定义变量的语法为: |变量名=变量值。(这里的=作用是赋值。)
定义变量后可以使用变量名来访问变量值。
#定义一个变量表示这个字符串。如果需要修改内容,只需要修改变量对应的值即可
weather =“今天天气真好"
print(weather) # 注意,变量名不需要使用引号包裹
print (weather)
print(weather)
说明:
●变量即是可以变化的量,可以随时进行修改。
●程序就是用来处理数据的,而变量就是用来存储数据的I
类型:
程序中:在** Python里为了应对不同的业务需求,也把数据分为不同的类型。
*★
如下图所示:
Numbers (数字)一
int (有符号整型)
long (长整型[也可以代表八进制和十六进制])
float (浮点型)
.complex (复数)
●布尔类型
●True
●False .
String (字符串)
List (列表)
.Tuple (元组)
Dictionary (字典)
书写方式:
井list 列表
#应用场景:当获取到了很多个数据的时候那么我们可以将他们存储到列表中然后直接使用列表访问
name_ list = [' 周杰伦','科比']
print(name_ list)
# tuple 元组
age_ tuple = (18,19,20,21 )
pr int(age_ tuple)
# dict 字典
#应用场景: scrapy框架使用
白#格式:变量的名字= {key: value, key1: value1}
person = {'name': '红浪漫','age' :18}
pr int(person)
使用type进行查看变量的类型:
类型转换:
#整型转换为字符串,大 部分的应用场景
a=80
pr int(type(a) )
#强制类型转换为字符串的方法是str()
b = str(a)
print(b)
pr int( type(b))
白#布尔类型转换为字符串
a = True
pr int(type(a))
b = str(a)
print(b)
pr int(type(b))
转布尔类型:
#如果对非0的整数进行bool类型的转换那么就全都是木True
#a=1
# print(type(a))
#将整数变成布尔类型的数据
# b = bool(a)
# print(b)
# print(type(b))
a =2
pr int( type(a))
b = bool(a)
pr int(b)
pr int( type(b))
运算符:

#字符串的加法是进行拼接的
#a='123'
#b='456'
# print(a + b)
白井在python中 +两端都是字符串才可以进行加法运算
a
= '123'
b=456
# print(a + b)
print(a + str(b))
#字符串的乘法是将字符串重复多少次
a='我爱你你爱我蜜雪冰城甜蜜蜜'
print(a*3)
赋值运算符:
5.2赋值运算符
运算符 描述 实例
= 赋值运算符 把=号右边的结果赋给左边的变量,如num= 1 + 2*3,结果num的值为7
#单个变量赋值
>>> num = 16
>>> 》> num
>>> 10
>>> #同时为多个变量赋值(使用等号连接)
>>> a=b=4
>>> a
>>> b
4
#多个变量赋值(使用逗号分隔)
>>> num1, f1, str1 = 100, 3.14, "hello"
>>> 》》> num1
>>> 100
>>> f1
>>> 3.14
a =10
print(a)
b =c=20
print(b)
print(C)
#多个变量赋值(使用逗号分隔)
d,e,f = 1,2,3
print(d)
print(e)
print(f)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YOWlmybX-1659855276949)(python:.assets/image-20220731102650057.png)]](https://img-blog.csdnimg.cn/bed2c2271b26405f9d58d269078bf2c8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F1hE7HjB-1659855276949)(python:.assets/image-20220731102919795.png)]](https://img-blog.csdnimg.cn/ec064955ecbf4986b5e6083a16284a00.png)
#!=不等
判断!=两边的变量是否不一-致
#a=10
#b=10
# print(a != b)
#扩展:<> python2版本使用python3遗弃
白# print(10 <>. 20)
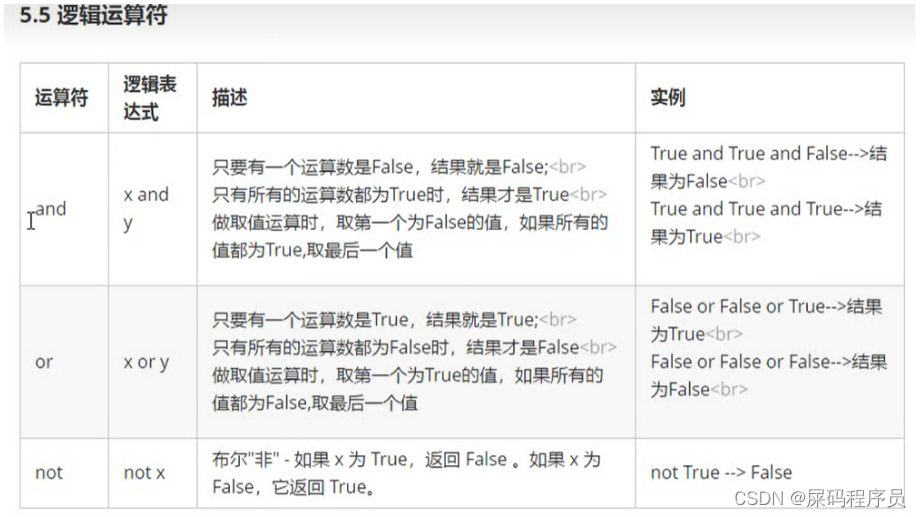
#逻辑运算符and与or或
not非
#and与
# and两边的数据必须全部都是true的时候才会返回true只要有一端返回的是false 那么就返回false
# and两端都是false的时候返回的是false
print(10 > 20 and 10 > 11)
# and一端是true-端是false 返回的是false
print(10 > 5 and 10 >11 )
# and-端返回的是false一端返回的是true返回的是false
print(10 > 11 and 10 > 5)
# and两端返回的都是true则返回的是的trud
print(10 > 5 and 10 > 6)
#or或者
# or的两端只要有一端是true 那么结果就是true
# or的两端都是false则返回的是false
print(10 > 20 or 10 > 21)
# or的两端前面的是true后面的是false 那么返回的是true
print(10 > 5 or 10 > 20)
# or的两端前面的是false后面的是true那么 返回的是true
print(10 > 20 or 10 > 5)
# or的两端都是true那么 返回的是true
print(10>5or10>6)
# not
非
取反
pr int(not True)
pr int(not False)
print(not (10 > 20) )
注意点“:
白# and的性能优化
#a=36
# a> 10 and print( 'hello world')
# and的性能优化当and 前面的结果是false的情况下那么后面的代码就不再执行了
# a< 10 and print('hello world')
# or的性能优化
日# or只要有一方为true那么结果就是true
a=38
# a>39 or print('你好世界')
a > 37 or print('你好 世界')
白# and短路与
白# .or
短路或
输出:
#普通输出
print('故事里的小黄花,从出生那年就飘着')
白#格式化输出
# scrapy框架的时候excel文件 mysql redis
age = 18
name = ' 红浪漫晶哥'
# %s代表的是字符串
%d代表的是数值
pr int( '我的名字是%s ,我的年龄是%d' % (name ,age))
输入:
# password = input(' 请输入您的银行卡密码')
# print( '我的密码是:%S' % password)
name = input('请输入您的名字')
print( '我的名字是:%s' % name)
控制语句if:
#if关键字的语句结构
规
if判断条件:
白#
代码(如果判断条件为true的时候执行f下面的内容)
age = 17
户#吉多
abc语言
白#如果您的年龄大于18了那么你就可以开车了
if age > 18:
print( '你可以开车了')
井True代表的是男False代表的是女
gender = True
if gender
==,True:
# if下面的代码必须是-个tab键或者四个空格
print('你是一个男性')
案列:
白#在控制台.上输入一个年龄 如果您的年龄大于18了那么打印可以去网吧了
白# input返回的是字符串类型
age = input( '请输入您的年龄')
#字符串和整数int是不可以比较的
if int(age) > 18:
print('您成年了,可以去网吧了')
ifelse:
# else:
白#
判断条件为false的时候执行的代码
age = 17
if age > 18:
print('你可以去网吧了')
else:
pr int('回家写作业去吧')|
案列:
#在控制台上输入一个年龄
如果您的年龄大于18了那么输出 欢迎光临红浪漫男宾-位
#否则那么输出 回家洗冼睡
age = int(input('请输入您的年龄'))
if age > 18:
pr int( '欢迎光临红浪漫,候-位')
else:
print( '洗洗睡吧')
for循环:
#循环字符串
# range(5)
# range(1, 6)
# range(1, 10,3)
#循环一个列表
#一个一个的输出叫做循环也叫做遍历
s = ' china'
#案列1
# range(5)
白# range方法的结果-个可以遍历的对象
for i in range(5):
print(i)
#输出结果为 0,1,2,3,4
#案例2
# range( 1,6)
# range (起始值,结束值)
#左闭右开区间
# for i in range(1,6):
print(i)
#输出结果 为 1,2,3,4,5
#案列3
# range(1, 10,3)
# range (起始值,结束值,步长)
#1 4 7 10
for i in range(1,11 ,3):
print(i )
#输出结果为 1 4 7 10
应用场景:
#应用场景会爬取一个列表返回给我们
#循环一个列表.
a_ list = ['周杰伦', '林俊杰','陶品','庞龙']
白#遍历列表中的元素
# fori in a_ _list:
# print(i)
#遍历列表中的下标
I
#判断列表中的元素的个数
# print(len(a_ list))
白#01 2
for i in range(len(a_ list)):
print(i)
#注意 遍历集合长度 使用len()函数
字符串高级:
8.数据类型高级
8.1字符串高级
字符串的常见操作包括:
●获取长度:len
len函数可以获取字符串的长度。
●查找内容:find
查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一-次
出现的开始位置索引值,如果不存在,则返回-1.
●判断:startswith,endswith 判断字符串是不是以谁谁谁开头/结尾
●计算出现次数:count
返回str在start和end之间在mystr里面出现的次数
●替换内容:replace
替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。
●切割字符重:split
通过参数的内容切割字符串
●修改大小写:upper,lower
将字符串中的大小写互换
●空格处理:strip
去空格
●字符串拼接:join
字符串拼接
列表高级:
列表的增删改查
添加:
添加元素有一下几个方法:
●append 在末尾添加元素
# append
追加
在列表的最后来添加一个对象/数据
food_ list = ['铁锅炖大鹅', '酸菜五花肉']
print(food_ list)
food_ list . append( '小鸡炖蘑菇')
print(food_ list)
●insert 在指定位置插入元素
# insert
插入
char_ list = ['a','C','d']
print(char_ list )
# index的值就是 你想插入数据的那个下标
char_ list. insert(1,'b')
print(char_ list)
●extend 合并两个列表
# extend
num_ list = [1,2,3]
num1_ list = [4,5,6]
#直接将第二个列表添加到第一个列表的后面
num_ list. extend(num1_ list)
pr int(num_ list)
修改:
city_ list = ['北京','上海','深圳', '武汉','西安']
print(city_ list)
)#将列表中的元素的值修改I
#可以通过下标来修改,注意列表中的下标是从0开始的
city_ _list[4] = '大连'
print(city_ _list)
查找:
第一种方式:
# in是判断某一个元素是否在某一个列表中
food_ list = ['锅包肉', '汆白肉', '东北乱炖']
#判断一下在控制台输入的那个数据是否在列表中
food = input(' 请输入您想吃的食物')
if food in food_ list:
print( '在' )
else:
print('不在,一边拉去')
第二种方法:not in
# not in
ball_ list = ['篮球','台球']
#在控制台上输入你喜欢的球类然后判断是否不在这个列表中
ball = input('请输入您喜欢的球类')
if ball not in ball_ list:
print('不在' )
else:
print('在' )
删除:
列表元素的常用删除方法有:
●del:根据下标进行删除
a_ _list = [1,2,3,4,5]
print(a_ list)
#根据下标来删除列表中的元素
#爬取的数据中有个别的数据是我们不想要的那么我们就可以通过下标的方式来删除
del a_ list[2]
print(a_ list)
●pop: 删除最后一个元素
b_ list = [1,2,3,4,5]
print(b_ list)
# pop是删除列表中的最后- -个元素
b_ list. pop()
print(b_ list)
●remove: 根据元素的值进行删除
C_ list = [1,2,3,4,5]
print(C_ list)|
#根据元素来删除列表中的数据
C_ list. remove(3)
print(C_ list)
元组高级:
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号:
a_ tuple_ = (5)
pr int( type(a_ tuple))
#当元组中只要一个元素的时候 那么他是整型数据
#定义只有一个元素的元组,需要在唯一的元素后写一个逗号
b_ tuple = (5,)
print( type(b_ tuple))
切片:
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法: [起始:结束:步长],也可以简化使用[起始:结束]
注意:选取的区间从”起始"位开始,到“结束’位的前一-位结束(不包含结束位本身),步长表示选取间隔。
s ='hello world'
#在切片中直接写一个下标
print(s[0] )
#左闭右开区间
包含坐标的数据不包含右边的数据
print(s[0:4] )
#是从起始的值开始-直到末尾
print(s[1:] )
#是下标为0的索引的元素开始一 直到第二参数为止 遵循左闭右开区间
print(s[:4] )
'# hello world
#从下标为0的位置开始到下标为6的位置结束 每次增长2个长度
print(s[0:6:2] )
字典的高级:
查询:
#定义一个字典
person = {'name':'吴签' ,'age' :28}
#访问person的name
# print(person[ 'name '])
# print(person['age '])
#使用[]的方式,获取字典中不存在的key的时候会发生异常 keyerror
# . print(person['sex'])
#不能使用.的方式来访问字典的数据
# print(person. name)
#是可以使用。get()进行访问的
# print(person. get( 'name'))
# print(person.get( 'age'))
#使用.的方式,获取字典中不存在的key的时候会 返回None值
pr int( person.get('sex' ))
修改:
person = {'name' : '张三','age':18}
#修改之前的字典
pr int(person)
#修改name的值为法外狂徒
# person['name'] = ' 法外狂徒'
白#修改之后的字典
print( person)
添加:
person = {'name': '老马'}
pr int(person)
#给字典添加一个新的key value
#如果使用变量名字['键'] =数据时这个键如果 在字典中不存在那么 就会变成新增元素
person['age'] = 18
#如果这个键在字典中存在那么就会变成这个元素
person['name'] = '阿马'
pr int(person)
删除:
# del
(1)删除字典中指定的某一个元素
person = {'name': '老马','age' :18}
#删除之前
# print(person)
# del person['age ']
##删除之后
# print(person)
#(2 )删除整个字典
#删除之前
pr int(person)
del person
#删除之后
pr int(person)
# clear
#(3) 清空字典但是保留字典对象
pr int( person)
person. clear( )
字典的遍历:
#遍历--》就是数据一个一个的输出
person = {'name':'阿马','age':18,'sex':'男'}
# (1)遍历字典的key
#字典.keys() 方法获取的字典中所有的key值key是一 个变量的名字 我们可以随便起
# for key in person. keys():
print(key)
# (2)遍历字典的value
#字典.values( )方法获取字典 中所有的value值value也是 一个变量我们可以随便命名
# for value in person. values():
# print(value )
# (3)遍历字典的key和value
# for key, value in person. items():
print(key, value)
# (4)遍历字典的项/元素
for i te in person. items( ):
print( item)
函数:
定义格式:
def函数名():
代码
9.2调用函数
定义了函数之后,就相当于有了一个具有某些功能的代码,想要让这些代码能够执行,需要调用它
调用函数很简单的,通过函数名()即可完成调用
#定义完函数后,函数是不会自动执行的,需要调用它才可以
f1()
函数定义好以后,函数体里的代码并不会执行,如果想要执行函数体里的内容,需要手动的调用函数。
每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了。
9.4函数返回值
"返回值”介绍
现实生活中的场景:
我给女儿10块钱,让她给我买个冰淇淋。这个例子中,10块钱是 我给女儿的,就相当于调用函数时传递到参
数,让女儿买冰淇淋这个事情最终的目标,我需要让她把冰淇淋带回来,此时冰淇淋就是返回值
综_上所述:
●所谓“返回值”,就是程序中函数完成- -件事情后,最后给调用者的结果
带有返回值的函数
想要在函数中把结果返回给调用者,需要在函数中使用return
如下示例:
def add2num(a, b):
C=a+b
return C # return 后可以写变量名
或者
def add2num(a, b):
return a+b # return 后可以写计算表达式
文件:
10.文件
日10.1 文件的打开与关闭
打开文件/创建文件
在python,使用open函数,可以打开一个已经存在的文件, 或者创建一个新文件
open(文件路径,访问模式)
示例如下:
f = open('test.txt', 'W')
说明:
文件路径
●绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一-目了然的。
。例如: | E:\python ,从电脑的盘符开始,表示的就是一 个绝对路径。
●相对路径:是从当前文件所在的文件夹开始的路径。
。| test.txt, 是在当前文件夹查找test . txt | 文件
。[ ./test.txt, 也是在当前文件夹里查找test.txt文件,| ./表示的是当前文件夹。
。…/test. txt,从当前文件夹的上一级文件夹里查找test.txt文件。[ …/ 表示的是上一级文件夹
。demo/test. txt,在当前文件夹里查找demo这个文件夹,并在这个文件夹里查找test.txt文件。
模式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B6bNUsUZ-1659855276950)(python:.assets/image-20220731150433547.png)]](https://img-blog.csdnimg.cn/208fd37c1e4e4091a3e8fc82174f7ef0.png)
测试:
#创建一个test.txt文件
# open(文件路径,模式)
# 模式: w 可写
# r 可读
t= open("test.txt", "w")
# 写入数据
t.write("hello world")
#关闭文件
t.close()
文件的读写:
# t= open("test.txt", "a")
#
# t.write("helloworld\n"*5)
# #
# t.close()
#如果我再次来运行这段代码会 打印10次还是打印5呢?
#如果文件存在会先情况原来的数据然后再写
#我想在每一次执行之后都要追加数据
#如果模式变为了a那么就会执行追加的操作
# 读取数据
t= open("test.txt", "r")
read= t.read() #一字节一字节的读取,效率较低
print(read)
readline= t.readline() #但是只能读一行
print(readline)
# readlines 可以按照行来读取但是 会将所有的数据都读取到并且以一个列表的形式返回
#而列表的元素是一行一行的数据
content =t. readlines( )
print( content)
序列化和反序列化:
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无
法直接写入到一一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
’ 00
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字
节序列恢复到内存中,就是反序列化。
Python中提供了JSON这个模块用来实现数据的序列化和反序列化。
JSON模块
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串。
使用JSON实现序列化
JSON提供了dump和dumps方法,将一个对象进行序列化。
dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
#序列化的2种方式
# dumps()
# (1 )创建一个文件
fp = open('test. txt','w')
# (2)定义一个列表
name_ list = ['zs','ls']
#导入json模块到该文件中
import json
#序列化
# .将python对象变成json字符串
#我们在使用scrapy框架的时候 该框架会返回-一个对象我们要将对象写入到文件中就要使用json. dumps
names = json. dumps(name_ list)
#将names写入到文件中
fp. write( names)
fp. close( )
#dump
#在将对象转换为字符串的同时,指定一个文件的对象然后把转换后的字符串写入到这个文件里
fp = open( 'text.txt', 'w')
name_ _list = ['zS', 'ls']
import json
#相当于names = json. dumps(name_ list) 和fp. wri te(names)
json. dump(name_ list, fp)
fp. close( )
反序列化:
#反序列化
#将json的字符串变成-个python对象
fp = open('text.txt','r')
content = fp. read()
#读取之后是字符串类型的
print( content)
print( type( content))
# loads
import json
#将json字符串变成py thon对象
result = json. loads( content)
#转换之后
print(result)
print( type( result))
#load
fp = open( 'text. txt','r')
import json
result = json. load(fp)
print( result)
pr int( type( result))
fp. close( )|
异常:
程序在运行过程中,由于我们的编码不规范,或者其他原因-些客观原因,导致我们的程序无法继续运行,此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的健壮性,我们在程序设计里提出了异常处理这个概念。
# fp =open('text. txt', 'r')
#
# fp.read()
#
# fp. close()
#异常的格式
# try:
可能出现异常的代码
# except异常的类型
友好的提示.
try:
fp = open( 'text. txt','r')
fp. read( )
except FileNotFoundError :
print( '系统正在升级,请稍后再试。。。')
爬虫:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbbFtj6d-1659855276950)(python:.assets/image-20220731153038852.png)]](https://img-blog.csdnimg.cn/067219d053ce40f8a9b20816a43db20a.png)
如果我们把互联网比作- -张大的蜘蛛网, 那一台计算机上的数据便是蜘蛛网_上的一个猎物,而爬虫程序就是一只小
蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据url(http:/ /www. taobao. com)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心?
1.爬取网页:爬取整个网页包含 了网页中所有得内容
2.解析数据:将网页中你得到的数据进行解析
3.难点:爬虫和反爬虫之间的博弈
用途:
1.爬取网页:爬取整个网页包含 了网页中所有得内容
2.解析数据:将网页中你得到的数据进行解析
3.难点:爬虫和反爬虫之间的博弈
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZsB9dELZ-1659855276950)(python:.assets/image-20220731153455240.png)]](https://img-blog.csdnimg.cn/5b65844d0a8145fb9d30e781dc87f281.png)
4.爬虫分类?
通用爬虫:
实例
百度、360、 google、 sougou等搜索弓 |擎- - -伯乐在线
功能
访问网页- >抓取数据- >数据存储- >数据处理- >提供检索服务
robots协议
-个约定俗成的协议,添加robots . txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用
自己写的爬虫无需遵守
网站排名(SEO)
1.根据pagerank算法值进行排名(参考 个网站流量、点击率等指标)
2.百度竞价排名
缺点
1.抓取的数据大多是无用的
2.不能根据用户的需求来精准获取数据
聚焦爬虫
功能
根据需求,实现爬虫程序,抓取需要的数据
设计思路
1.确定要爬取的url
如何获取url
2.模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问
3.解析htm1字符串(根据- 定规则提取需要的数据)
如何解析
5.反爬手段?
1.User- Agent:
User Agent中文名为用户代理,简称UA, 它是一个特殊字符串头, 使得服务器能够识别客户使用的操作系统及版
本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
2. .代理IP
西次代理
快代理
什么是高匿名、匿名和透明代理?它们有什么区别?
1.使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2.使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3.使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
3.验证码访问
打码平台
云打码平台
超级哆
4.动态加载网页网站返回的是js数据 并不是网页的真实数据
selenium驱动真实的浏览器发送请求
5.数据加密
分析js代码
urllib库使用:
urllib. request . urlopen()模拟浏览器向服务器发送请求
response
服务器返回的数据
response的数据类型是HttpRes ponse
字节-->字符串
解码decode
字符串-->字节
编码encode
read( )
字节形式读取=进制
扩展: rede(5 )返回前几个字节
readline( )
读取- -行
readlines() - -行- -行读取直至结束
getcode()
获取状态码
getur1()
获取ur1
getheaders()获取headers
urllib. request . urlretrieve( )
请求网页
请求图片
请求视频
urllib 拉取百度页面原码:
#使用urllib来获取百度首页的源码
import urllib.request
#定义一个url 就是要访问的地址
url="http://www.baidu.com"
#模拟浏览器向服务器发送请求
response= urllib.request.urlopen(url)
#获取响应中的页面源码
#read()方法 返回的是字节形式的二进制数据
#要将二进制的数据转换为字符串
#二进制--》字符串解码decode( '编码的格式' )
content = response.read().decode('utf-8')
#打印数据
print(content)
一个类型六个方法:
import urllib.request
url="http://www.baidu.com"
response=urllib.request.urlopen(url)
# 一个类型和六个方法.
# response是HTTPResponse的类型
# print( type(response))
# 一个一个字节的读取
content=response.read()
print(content)
#返回多少个字节
# content = response. read(5)
# print( content)
#读取一行
# content = response. readline( )
# print( content)
# 一行一行的读取 直到读完
# content = response. readlines( )
#print( content)
#返回状态码如果是200 了那么就证明我们的逻辑没有错
# . print(response. getcode())
#返回的是url地址
# . print(response. geturl())
#获取是一个状态信息
print( response . getheaders())
#一个类型HTTPResponse
#六个方法read
#readline readlines getcode geturl getheaders
urllib下载:
import urllib.request
# 下载网页
url_page="http://www.baidu.com"
# url代表的是下载的路径 filename文件的名字
#在python中可以变量的名字也 可以直接写值
# urllib. request. urlretrieve(url_page, '百度.html')
#下载图片
#图片连接地址
# url_image="https://image.baidu.com/search/index?ct=201326592&z=undefined&tn=baiduimage&ipn=d&word=lisa&step_word=&ie=utf-8&in=&cl=2&lm=-1&st=undefined&hd=undefined&latest=undefined©right=undefined&cs=1859975430,1209084167&os=1412329483,2753000318&simid=4270983323,717977720&pn=1&di=7108135681917976577&ln=1161&fr=&fmq=1659255087387_R&fm=&ic=undefined&s=undefined&se=&sme=&tab=0&width=undefined&height=undefined&face=undefined&is=0,0&istype=0&ist=&jit=&bdtype=0&spn=0&pi=0&gsm=0&objurl=https%3A%2F%2Fgimg2.baidu.com%2Fimage_search%2Fsrc%3Dhttp%253A%252F%252Fb-ssl.duitang.com%252Fuploads%252Fitem%252F201902%252F19%252F20190219172715_fREAJ.thumb.700_0.jpeg%26refer%3Dhttp%253A%252F%252Fb-ssl.duitang.com%26app%3D2002%26size%3Df9999%2C10000%26q%3Da80%26n%3D0%26g%3D0n%26fmt%3Dauto%3Fsec%3D1661847083%26t%3Ddef62aee40c81582b2f31930658d1d63&rpstart=0&rpnum=0&adpicid=0&nojc=undefined&tt=1&dyTabStr=MCwzLDQsNSw2LDcsOCwxLDIsOQ%3D%3D"
# urllib.request.urlretrieve(url_image,'lisa.jpg')
#下载视频
#视屏连接地址
#但是唯一要注意的就是 在py这个编译器中没有办法进行播放视屏 所以还是去文件夹本地进行查找播放
url_video="https://vd4.bdstatic.com/mda-ngw5avrb6ubs83pf/sc/cae_h264/1659243829047255544/mda-ngw5avrb6ubs83pf.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1659257191-0-0-6e97200e324b0a67fec01119f6dd7b26&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0991362931&vid=17239941656927962922&abtest=103579_1-103747_2&klogid=0991362931"
urllib.request.urlretrieve(url_video,'lisa.mp4')
请求对象定制:
这里我们将连接定义为了https 之后爬取的数据就变得很少, 这是就遇到了反爬机制 所以获取请求头中的 User-Agent 给够数据
import urllib.request
url="https://www.baidu.com"
#打开百度页面 打开控制台 网略 获取请求头中的 User-Agent
headers={
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
#因为urlopen方法中不能存储字典所以headers不能传递进去
#请求对象的定制
#注意因为参数顺序的问题 不能直接写url 和headers 中间还有data 所以需要关键字传参
request=urllib.request.Request(url=url,headers=headers)
response= urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
请求的quote:
-
当我们进行搜索某个人得时候 会发现带着的参数从写入py编译器时,是unicode编码 那么我们要进行书写就很麻烦 这是要怎么办呢?
-
使用quote进行编写
import urllib.request # 原链接 # url="https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6" url="https://www.baidu.com/s?wd=" headers={ 'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77' } # 使用quote进行编写 变成一个unicode 编码 name = urllib.parse.quote("周杰伦") # 进行连接拼接 url=url+name request=urllib.request.Request(url=url,headers=headers) response= urllib.request.urlopen(request) content=response.read().decode('utf-8') print(content)
请求后跟多参数 urlencoed:
import urllib.request
import urllib.parse
#请求资源路径
base_url="https://www.baidu.com/s?"
# 直接将连接后跟的多个参数写成一个字典形式
data={
'wd':'周杰伦 ',
'sex':'男',
'location':'中国台湾省'
}
# 使用urlencode 方法进行解析 编码
new_url=urllib.parse.urlencode(data)
#进行连接拼接
url=base_url+new_url
# 防止反爬
headers={
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
#获取网页源码的数据
content=response.read().decode("utf-8")
print(content)
post请求 百度翻译:
import urllib.request
url=" https://fanyi.baidu.com/v2transapi"
headers={
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
data={
'kw':'spider'
}
# post参数必须进行编码
data=urllib.parse.urlencode(data).encode('utf-8')
# post的请求的参数是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数必须要进行编码
request=urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器发送数据
response=urllib.request.urlopen(request)
# 获取响应数据
content=response.read().decode('utf-8')
print(content)
import json
obj=json.loads(content)
print(obj)
# post请求方式的参数必须编码
# data = urllib. parse. urlencode(data)
# 编码之后必须调用encode方法data = urllib. parse. urlencode(data). encode( 'utf-8')
# 参数是放在请求对象定制的方法中 request = urllib. request. Request(url=urI, data=data, headers
详细翻译:
这也是第二个反爬机制
import urllib.request
# 找到详细翻译的连接
url="https://fanyi.baidu.com/v2transapi?from=en&to=zh"
# 获取请求头中的cookie 起决定因素的就是cookie
headers={
'Cookie':'BIDUPSID=D900AB5C6372B625EB0337DC72F92973; PSTM=1639643948; BAIDUID=D900AB5C6372B625A9AE584735292AF4:FG=1; __yjs_duid=1_950153676c8c3be21ab6fa341bb6b81f1639750214229; REALTIME_TRANS_SWITCH=1; SOUND_PREFER_SWITCH=1; SOUND_SPD_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; BAIDUID_BFESS=D900AB5C6372B625A9AE584735292AF4:FG=1; ZFY=zqigZJowTKSANvjIWY7H:ATgpgHkUTyxP5ljzt9t5IlE:C; H_PS_PSSID=36829_36552_36462_36255_36726_36974_36413_36845_36955_36166_36918_36570_36745_26350_36934; delPer=0; PSINO=3; BA_HECTOR=ag8k8l2hak85a4a48k8nq1vu1hecka817; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; APPGUIDE_10_0_2=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1659261259; ab_sr=1.0.1_YzMxZDAwMTliYzY5N2JmN2VkNWQ5ZTEzZDMzZDY2ZDY5ODc1YTMwZDBhOGUxNDc4Nzk1NDczMmI3MGJkZTAzMDVkZGNjZTFkNmE0MmEwZjU5N2JhODI2N2JiMDE4Mjg3MWU2ZDU5YWQ4NWE3MmE3YWVlYjkwMDljOTA5MjUxOTVlZTE2OWIzZTFmNmM2MGE4MGIyMzQxOWJmZDU3ZTViMw==; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1659261273',
}
# 获取From Data中的参数
data={
'from': 'en',
'to': 'zh',
'query': 'spider',
'simple_means_flag':'3',
'sign':'63766.268839',
'token': 'a5eca4f8a4d46aa69015ecda8e790b52',
'domain': 'common'
}
# post参数必须进行编码 并且调用encode方法
data=urllib.parse.urlencode(data).encode('utf-8')
# post的请求的参数是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数必须要进行编码
request=urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器发送数据
response=urllib.request.urlopen(request)
# 获取响应数据
content=response.read().decode('utf-8')
print(content)
import json
obj=json.loads(content)
print(obj)
# post请求方式的参数必须编码
# data = urllib. parse. urlencode(data)
# t编码之后必须调用encode方法data = urllib. parse. urlencode(data). encode( 'utf-8')
# t参数是放在请求对象定制的方法中 request = urllib. request. Request(url=urI, data=data, headers
ajax的get请求:
获取豆瓣电影的第一页数据
import urllib.request
url="https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
# 请求对象定制
request=urllib.request.Request(url=url,headers=headers)
# 模拟浏览器发送数据
response = urllib.request.urlopen(request)
# 获取响应数据
content= response.read().decode('utf-8')
print(content)
# 下载数据到本地
# open 默认情况下使用的是gbk的编码 如果我们要想保存汉子,那么在open方法中指定编码格式为utf-8
# fp=open("douban.json","w",encoding="utf-8")
# fp.write(content)
# 写入数据 方式二 和上面的方式一样
with open( ' douban1. json', 'w', encoding='utf-8') as fp:
fp. write( content)
获取豆瓣电影前十页数据:
import urllib.request
import urllib.parse
def create_request(page):
# 获取到起始页前面的参数作为默认连接
base_url="https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
# 书写拼接在后面的参数
data={
'start':(page-1)*20,
"limt":20
}
# 进行字符编码
new_url = urllib.parse.urlencode(data)
# url拼接
url=base_url+new_url
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
#定制对象
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取网页返回数据
content=response.read().decode("utf-8")
# 之后将上面返回的数据 存入文件 由于是遍历加函数 所以我们使用拼接页数来标识每一个文件 记得页数要转换为字符串才能进行拼接
with open('douan1'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
# 入口
if __name__=="__main__":
start_page=int(input("请输入其实页码"))
end_page=int(input("请输入结束页码"))
# 对输入页数进行遍历
for page in range(start_page,end_page+1): #加一 是应为我们使用的是range进行遍历 左闭右开区间
create_request(page) # 调用函数 将遍历的参数传递过去
Handler处理器
为什么要学习handler?
urllib. request . urlopen(url)
不能定制请求头
urllib. request . Request (url , headers , data)
可以定制请求头
Handler
定制更高级的请求头(随着业务逻辑的复杂请求对象的定制已经满足不了我们的需求(动态
cookie和代理不能使用请求对象的定制)
基本使用:
import urllib.request
url="http://baidu.com"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
request = urllib.request.Request(url=url, headers=headers)
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
response = opener.open(request)
# 获取返回值
content = response.read().content('utf-8')
print(content)
14.代理服务器
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服
务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度
扩展:通常代理服务器都设置-一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲
区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息, 传给用户,以提高访问速度。
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
2.代码配置代理
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener . open函数发送请求
import urllib.request
url="https://ip.900cha.com/"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
proxies={
'http':'121.230.211.142:3256'
}
handler= urllib.request.ProxyHandler(proxies=proxies)
opener= urllib.request.build_opener(handler)
response = opener.open(request)
# response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
with open('daili.html', 'w', encoding='utf-8') as fp:
fp.write(content)
解析:
-
获取网页源码中的部分数据。
-
在chrome浏览器中安转xpath工具
-
安装完成之后 重启浏览器 之后打开插件出现小黑框说明安装成功
-
之后再在python文件夹中的Script文件中安装一个库 lxml 打开dos命令框进行安装
pip install lxml
基本语法:
xpath基本语法:
JLSCECUCAOWAUCSUT J00 SU U 0102A100 Ou
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/:找直接子节点
2.谓词查询
//div[@id]
//div[@id="maincontent" ]
3.属性查询
//@class
4.模糊查询
//div[contains(@id, "he")]
//div[starts-with(@id,"he")]
5.内容查询
//div/h1/text()
6.逻辑运算
//div[@id="head" and
@class=TSs- down"]
//title| //price
获取input框中的值 @value
//input[@id="su"]/@value
测试:
import urllib.request
from lxml import html
# xpath解析本地文件
parse = html.parse("Ceshi.html")
print(parse)
#查找ul下面的li text()获取标签中的内容
# li_list= parse.xpath('//body/ul/li/text()')
# print(li_list)
#查找所有有id的属性的li标签
# text( )获取标签中的内容
# li_list = tree. xpath('//ul/li[@id]/text()')
#找到id为I1的li标签 注意引号的问题
li_list = parse.xpath(' //ul/li [@id="l1"]/text()')
#查找所有有id的属性的li标签
# text( )获取标签中的内容
# li_ _list = tree. xpath('//ul/li[@id]/text()')
#找到id为11的li标签注意 引号的问题
# 1i_ _list = tree. xpath('//ul/li[@id="I1"]/text()')
#查找到id为1 1的Ii标签的class的属性值
# li=tree. xpath( '//ul/li[@id="I1"]/@class')
#查询id中包含l的Ii标签
# li_ list = tree. xpath( '//ul/li[contains(@id, "I ")]/text()')
案例获取百度中"百度一下":
import urllib.request
url="http://www.baidu.com"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
#解析源码 来获取我们想要的数据
from lxml import etree
# 解析服务器的响应
html_html = etree.HTML(content)
# 返回回来的是一个列表 ['百度一下']
xpath= html_html.xpath('//input[@id="su"]/@value')
print(xpath)
# 获取第一个数据 百度一下
xpath1= html_html.xpath('//input[@id="su"]/@value')[0]
print(xpath1)
下载站长素材中的图片:
import urllib.request
from lxml import etree
# url="https://sc.chinaz.com/tupian/shanshuifengjing.html"
# url1="https://sc.chinaz.com/tupian/shanshuifengjing_2.html"
def create_request(page):
# 之所以要进行判断 是因为我们获取的连接发现虽然只是后面多加一个数字 但是没有改变第一页的连接却不会改变
if(page==1):
url="https://sc.chinaz.com/tupian/shanshuifengjing.html"
else:
url="https://sc.chinaz.com/tupian/shanshuifengjing_"+str(page)+".html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
print(url)
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
html = etree.HTML(content) #获取到源码进行解析
name_list=html.xpath("//div[@id='container']//a/img/@alt") #在源码中查找图片名称 返回一个列表
#注意点: 一般获页面的图片都会进行懒加载,所以获取的时候我们要记性查看 加载之前的src 名称
src_list=html.xpath("//div[@id='container']//a/img/@src") #在源码中查找图片连接 返回一个列表
for i in range(len(src_list)):
name=name_list[i]
src=src_list[i]
print(name+" "+src) #通过输出发现连接少了 https: 所以下面进行拼接
url="https:"+src
# 之后使用filename 进行拼接文件名和格式即可 进行下载
urllib.request.urlretrieve(url,filename=name+".jpg")
# 之后使用filename 进行拼接文件名和格式即可 进行下载 下载在文件中
# urllib.request.urlretrieve(url,filename='../风景images/'+name+".jpg")
#入口
if __name__=="__main__":
start_page=int(input("请输入其实页码"))
end_page=int(input("请输入结束页码"))
for page in range(start_page,end_page+1):
content=create_request(page) #调用获取网页源码函数
down_load(content) #之后将网页源码进行传递
Selenium
1.Selenium
1.什么是selenium?
(1) Selenium是一 个用于web应用程序测试的工具。
(2) Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver (FirfoxDriver, IternetExplorerDriver, OperaDriver, ChromeDriver) 驱动
真实浏览器完成测试。
(4) selenium也是支持无界面浏览器操作的。
2.为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
3.如何安装selenium?
(1)操作谷歌浏览器驱动下载地址
http://chromedriver . storage . googleapis . com/ index . html
(2)谷歌驱动和谷歌浏览器版本之间的映射表
http://blog . csdn . net/huilan_ same/ article/ details/51896672
(3)查看谷歌浏览器版本
谷歌浏览器右上角-- >帮助–>关于
(4)之后将解压之后的exe文件直接copy一份到项目包下
(5)之后再在prthon的安装位置打开Scripts文件夹 进行安装selenium pip install selenium
基本使用:
import urllib.request
from selenium import webdriver
url="https://www.jd.com/"
# 创建浏览器操作对象
path='chromedriver.exe'
browser = webdriver.Chrome(path)
browser.get(url)
content = browser.page_source
with open("jindon.html",'w',encoding='utf-8') as fp:
fp.write(content)
元素定位:
4-1: selenium的元素定位?
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先
要找到它们,WebDr iver提供很多定位元素的方法
方法:
1. find_ element_ _by_ id
eg: button = browser. find_ _element_ by_ _id('su')
2. find_ elements_ _by_ name
eg:name = browser . find_ element_ _by_ name( 'wd' )
3. find_ elements_ by_ xpath
eg:xpath1 = browser . find_ elements_ by_ xpath( '//input[@id="su"]')
4. find_ elements_ by_ tag_ name
eg:names = browser . find_ _elements_ by_ _tag_ name( ' input')
5. find_ elements_ _by_ _CSS_ selector
eg:my_ _input = browser .find_ elements_ _by_ _CSS_ selector( ' #kw')[0]
6. find_ elements_ by_ link_ text
eg :browser . find_ element_ _by_ _link_ text("新闻")
scrapy
(1) scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖
掘,信息处理或存储历史数据等一系列的程序中。
安装:
( 1 ) pip install scrapy
(2)报错1 : building ’ twisted. test. raiser’ extension
error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft V
Build Tools”: http:llandinghub. visuals tudio. com/visual- cpp- build- tool
解决1
http://www.1 fd. uci. edu/-gohlke/py thonl ibs/# twis ted
Twis ted-20.3.0-cp37-cp37m-win_ amd64. whI
cp是你的python版本
amd是你的操作系统的版本
下载完成之后使用pip install twisted的路径 安装
切记安装完twisted再次安装scrapy
(3)报错2 提示python -m pip install --upgrade pip
解决2
运行python -m pip install --upgrade pip
安装方式二(简单):
- 打开pychrom
- 点击左上角file
- 点击 settings
- 点击Project:项目名称
- 点击 Python Interpreter
- 点击 + 号
- 搜索想要的库 直接install 即可
爬虫基本使用:
1.创建爬虫的项目
scrapy startproject 项目的名字
注意:项目的名字不允许使用数字开头也不能包含中文
2.创建爬虫文件
要在spiders文件夹中去创建爬虫文件
cd项目的名字\项目的名字\spiders
cd scrapy_ baidu_ 091\scrapy baidu_ 091 \spiders
创建爬虫蚊件
scrapy genspider爬虫文件的名字
要爬取网页
eg : scrapy genspider
baidu http: / /www. baidu. com .
-般情况下不需要添加http协议因为start_ ur ls的值是根据allowed domains
修改的所以添加 了http的话那么start_ _urls就需要我们手动去修改了
3.运行爬虫代码
scrapy crawl 爬虫的名字
eg :
scrapy crawl baidu{
步骤:
-
首先打开Pycharm的终端 进行创建项目 输入
scrapy startproject 项目名称注意:项目名字不允许包含数字和中文。
-
之后再在spiders文件夹中进行创建爬虫哦你文件 所以就要cd 到spiders文件中了。
-
之后创建一个爬取百度的爬虫文件:
scrapy genspider 爬虫文件的名字 连接import scrapy class BaiduSpider(scrapy.Spider): # 爬虫的名字 用于运行爬虫的时候 使用的值 name = 'baidu' # 允许访问的值 allowed_domains = ['www.baidu.com'] # 起始的url地址 指的是第一次要访问的域名 # start_ urls是在al lowed_ domains的前面添加一 个http:// # . 在allowed_ domains的后面添加 - 个 / start_urls = ['http://www.baidu.com/'] # 是执行了start_ urls之后执行的方法 方法中的response 就是返回的那个对象 # 相当于response = urllib. request. urlopen() # response= requests.get() def parse(self, response): print("你好啊啊啊啊啊") -
运行爬虫文件
scrapy crawl 爬虫的名字 -
但是运行之后我们发现没有爬取到 因为这里有一个君子协议,我们可以直接将目录中的 settings文件中的 ROBOTSTXT_OBEY = True 给注释掉。之后就会不遵守君子协议了。就可以爬取到了。
项目结构和基本方法:
- scr apy项目的结构
项目名字
项目名字
spiders文件夹( 存储的是爬虫文件)
ini t
自定义的爬虫文件 核心功能文件
init
i tems 定义数据结构的地方爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等
2、response的属性和方法
response. text 获取的是响应的字符串.
response. body 获取的是二进制数据
r esponse. xpath 可以直接是xpath方法来解析response中的内容
r esponse. extract( ) 提取seletor对象的data属性值
response. extract_ _first() 提取的seletor 列表的第-个数据
scrapy架构组成
import scr apy
1 class CarSpider(scrapy. Spider):
name = 'car'
allowed_ domains = [ ' https: //car。autohome . com. cn/price/brand- 15. html']
#注意如果你的请求的接口是html为结尾的那么 是不需要加/的
start_ _urls = ['https://car 。autohome . com. cn/price/brand- 15. html']
def parse(self, response):
name_ list = response . xpath( ' //div[@class= "main-title"]/a/text()')
price_ list = response . xpath(' //div [@class= "main-lever"]//span/ span/ text()'
#通过遍历进行输出
for i in range(len(name_ list)):
name = name_ list[i] . extract( )
price = price_ _list[i] .extract() #获取data中的方法
pr int(name, price)|
(1) 引擎
—》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器
—》从引擎处获取到请求对象后,请求数据
(3) spiders
—》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说, Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
(4) 调度器
—》有自己的调度规则,无需关注
(5) 管道(Item pipeline) - - -》最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,-些组件 会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline” )是实现了简单方法的python类。他们接收到Item并通过它执行- -些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1.清理HTML数据
2.验证爬取的数据(检查item包含某些字段)
3.查重(并丢弃)
4.将爬取结果保存到数据库中
scrapy工作原理
1.引擎向spiders要url
2、引擎将要爬取的ur!给调度器
3、调度器会将url生成请求对象放入到指定的队列中
4、从队列中出队-个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求获取互联网数据
7.下载器将数据返回给引擎
8、引擎将数据再次给到spiders
9、spiders通过xpath解析该数据 ,得到数据或者url
10、spiders将数据或者ur!给到引擎
11、引擎判断该数据还是url ,是数据,交给管道( item
pipeline )处理,是ur|交给调度器处理
获取当当网图书数据:
-
创建项目
-
创建文件 dangdang。py
- 注意点:导入ScrapyDdItem时 不要ALt+Enter进行自动导入 一定要自己手动导入 只用导入items 文件上一层即可 报错不用管 只要 ScrapyDdItem被调用时不报错即可 否者就会出现文件根本没有被调用
import scrapy from scrapy_dd.items import ScrapyDdItem class DangdangSpider(scrapy.Spider): name = 'dangdang' allowed_domains = ['http://category.dangdang.com/cp01.01.02.00.00.00.html'] start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html'] def parse(self, response): # pipelines 下载数据 # item 定义数据的 # url="//ul[@id='component_59']/li/a/img/@src" # alt="//ul[@id='component_59']/li/a/img/@alt" # price='//ul[@id="component_59"]/li/p[@class="price"]/span[1]/text()' # 所有的seletor的对象都可以在此调用xpath方法 对返回的源码进行解析 li_list = response.xpath("//ul[@id='component_59']/li") print(li_list) #获取到的是一个一个的li # 之后再进行遍历li 并再次解析获取其中的图片链接 名字等 for li in li_list: # 由于页面使用了懒加载,所以我们获取的图片的连接不是src 而是data-original 但是第一张图片是src 所以进行下面的判断 src=li.xpath(".//img/@data-original").extract() if src: #如果src 不为空 就直接等于src 否者src 后面的路径就改为src src=src else: src=li.xpath(".//img/@src").extract() name=li.xpath(".//img/@alt").extract() price=li.xpath("./p[@class='price']/span[1]/text()").extract() # 调用items文件进行封装 book=ScrapyDdItem(src=src,name=name,price=price) # 返回出去 之后pipelines文件 进行接收 yield book print(book) -
首先测试对方是否设置反爬 如果有 就直接将setting文件中的 ROBOTSTXT_OBEY = True 给注释掉
-
之后再在items文件中进行设置 对应的属性名称
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyDdItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field()、 # 图片 src=scrapy.Field() # 名字 name=scrapy.Field() # 价格 price=scrapy.Field() -
之后在 pipelines 文件中进行获取数据冰鞋入文件
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter # 如果想要使用管道的话 那么就必须在settings中开启管道 class ScrapyDdPipeline: # item就是yield后面的book对象 def process_item(self, item, spider): print("sjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj") # 注意写入模式要改为a with open("book.json","a",encoding='utf-8') as fp: # 注意点使用文件读写时 只能是字符串 fp.write(str(item)) return item -
但是上面的写入方式不好 重复打开文件写入 建议使用下面的形式:
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter # 如果想要使用管道的话 那么就必须在settings中开启管道 class ScrapyDdPipeline: def open_spider(self,spider): print("方法执行之前执行。。。。。。。。。") self.fp=open('book.json','w',encoding='utf-8') # item就是yield后面的book对象 def process_item(self, item, spider): # 执行写入 self.fp.write(str(item)) return item def close_spider(self,spider): print("方法执行之后执行。。。") self.fp.close()
开启多管道进行多任务 边下图片 边写json文件:
- 就在上面的案例基础上进行 直接在 pipelines 文件中进行书写
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想要使用管道的话 那么就必须在settings中开启管道
class ScrapyDdPipeline:
def open_spider(self,spider):
print("方法执行之前执行。。。。。。。。。")
self.fp=open('book.json','w',encoding='utf-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
# 执行写入
self.fp.write(str(item))
# # 注意写入模式要改为a
# with open("book.json","a",encoding='utf-8') as fp:
# # 注意点使用文件读写时 只能是字符串
# fp.write(str(item))
return item
def close_spider(self,spider):
print("方法执行之后执行。。。")
self.fp.close()
import urllib.request
# 定义管道类
# 在settings文件中开启管道
# 将图片下载到books文件中
class DangDangLoad:
def process_item(self,item,spider):
print(item.get('src'))
url='https:'+item.get('src')[0] #由于我的是列表,所以还要进行书写遍历 如果在文件中定义了 就可以不用遍历了。
filename='./books/'+item.get('name')[0]+'.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
-
在settings文件中在开启一个管道:
#直接模仿上面的形式进行书写 DangDangLoad 就是类名 # 开启下载图片管道 'scrapy_dd.pipelines.DangDangLoad': 301,
当当网多页数据下载和爬取:
-
还是四个文件的改动:
-
改写 items文件 写对应dangdang文件爬取回来的数据
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyDdItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field()、 # 图片 src=scrapy.Field() # 名字 name=scrapy.Field() # 价格 price=scrapy.Field() -
关闭协议开启多管道
#关闭协议 直接注释掉 ROBOTSTXT_OBEY = True #开启管道 ITEM_PIPELINES = { 'scrapy_dd.pipelines.ScrapyDdPipeline': 300, # 开启下载图片管道 'scrapy_dd.pipelines.DangDangLoad': 301, } -
首先创建一个文件dangdang: 主文件
import scrapy from scrapy_dd.items import ScrapyDdItem class DangdangSpider(scrapy.Spider): name = 'dangdang' "如果是多页下载的话那么必须要调整的是al lowed_ domains的范围一般情况 下只写域名" allowed_domains = ['category.dangdang.com'] start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html'] # "http://category.dangdang.com/cp01.01.02.00.00.00.html" # " http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html" # "http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html" base_urls='http://category.dangdang.com/pg' page=1 def parse(self, response): # pipelines 下载数据 # item 定义数据的 # url="//ul[@id='component_59']/li/a/img/@src" # alt="//ul[@id='component_59']/li/a/img/@alt" # price='//ul[@id="component_59"]/li/p[@class="price"]/span[1]/text()' # 所有的seletor的对象都可以在此调用xpath方法 对返回的源码进行解析 li_list = response.xpath("//ul[@id='component_59']/li") print(li_list) #获取到的是一个一个的li # 之后再进行遍历li 并再次解析获取其中的图片链接 名字等 for li in li_list: # 由于页面使用了懒加载,所以我们获取的图片的连接不是src 而是data-original 但是第一张图片是src 所以进行下面的判断 src=li.xpath(".//img/@data-original").extract() if src: #如果src 不为空 就直接等于src 否者src 后面的路径就改为src src=src else: src=li.xpath(".//img/@src").extract() name=li.xpath(".//img/@alt").extract() price=li.xpath("./p[@class='price']/span[1]/text()").extract() # 调用items文件进行封装 book=ScrapyDdItem(src=src,name=name,price=price) # 返回出去 之后pipelines文件 进行接收 yield book if self.page<100: self.page=self.page+1 url=self.base_urls+str(self.page)+'-cp01.01.02.00.00.00.html' # 怎么去调用parse方法 # scrapy.Reques # t就是scrpay的get请求 # url就是请求地址 # callback是你要执行的那个函数注意不需要加() yield scrapy.Request(url=url,callback=self.parse) -
之后改写pipelies文件:
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter # 如果想要使用管道的话 那么就必须在settings中开启管道 class ScrapyDdPipeline: def open_spider(self,spider): print("方法执行之前执行。。。。。。。。。") self.fp=open('book.json','w',encoding='utf-8') # item就是yield后面的book对象 def process_item(self, item, spider): # 执行写入 self.fp.write(str(item)) # # 注意写入模式要改为a # with open("book.json","a",encoding='utf-8') as fp: # # 注意点使用文件读写时 只能是字符串 # fp.write(str(item)) return item def close_spider(self,spider): print("方法执行之后执行。。。") self.fp.close() import urllib.request # 定义管道类 # 在settings文件中开启管道 # 将图片下载到books文件中 class DangDangLoad: def process_item(self,item,spider): print(item.get('src')) url='https:'+item.get('src')[0] #由于我的是列表,所以还要进行书写遍历 如果在文件中定义了 就可以不用遍历了。 filename='./books/'+item.get('name')[0]+'.jpg' urllib.request.urlretrieve(url=url,filename=filename) return item
读书网 使用crawlspider:
第一步就是下载 pymysql 还是和上面下载插件的方式一样
7.CrawlSpider案例
需求:读书网数据入库
1.创建项目: scrapy startproject dushuproject
2.跳转到spiders路径cd\dushuproject \dushuproject\spiders
3.创建爬虫类: scrapy genspider -t crawl read WWW . dushu. com
4. items
5. spiders
6. settings
7. pipelines
数据保存到本地
数据保存到mysq1数据库
3.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy .linkextractors. LinkExtractor(
allow = (),
#正则表达式提取符合正则的链接
deny = (),
(不用)正则表达式 不提取符合正则的链接
allow_ domains = (),
(不用)允许的域名
deny_ domains = (),
(不用)不允许的域名
restrict_ xpaths = (), # xpath,提取符合xpath规则的链接
restrict_ CSS = ()
#提取符合选择器规则的链接)
4.模拟使用
正则用法: links1 = LinkExtractor(allow=r’list_ 23 \d+. html’)
xpath用法: links2 = LinkExtractor(restrict_ xpaths=r’ //div[@class=“x”]‘)
css用法: links3 = LinkExtractor(restrict_ css=’.x’)
- .提取连接
link . extract_ links(response)
6.注意事项
[注1] callback只能写函数名字符串,callback= ’ parse_ item’
[注2]在基本的spider中,如果重新发送请求,那里的callback写的是
callback=self.parse_ item [注-
-稍后看] follow=true 是否跟进就是按照提取连接规则进行提取
步骤:
使用crawlspider 可以不用在写那么多的分页查询 整理
只需要创建时使用 crawl 创建,书写第三步就可以实现全部查完
-
创建项目
scrapy startproject Dushuwang -
创建文件
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html -
之后书写文件
LinkExtractor(allow=r'书写页码的连接 使用正则进行书写') -
运行
scrapy crawl read -
在items文件中构建数据结构
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DushuwangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() src=scrapy.Field() name=scrapy.Field() pass -
在settings文件中开启管道,书写mysql配置
#mysql配置 DB_HOST='localhost' # 端口号直接书写数字即可 DB_PORT=3306 DB_USER='root' DB_PASSWORD='xu083114' DB_NAME='mysqldb' # 字符集不允许书写斜杠 DB_CHARSET='utf8' 开启管道 ITEM_PIPELINES = { 'Dushuwang.pipelines.DushuwangPipeline': 300, 'Dushuwang.pipelines.Mysqldb': 301, } -
书写read文件进行操作:
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from Dushuwang.items import DushuwangItem class ReadSpider(CrawlSpider): name = 'read' #书写域名即可 allowed_domains = ['www.dushu.com'] # 图书连接 start_urls = ['https://www.dushu.com/book/1188_1.html'] # 多页操作 使用正则进行拼接 rules = ( Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'), callback='parse_item', follow=True), ) def parse_item(self, response): # 解析源码获取内容 img_list=response.xpath('//div[@class="bookslist"]//img') # 进行遍历 for img in img_list: src=img.xpath('./@data-original').extract_first() #获取图片链接 name=img.xpath('./@alt').extract_first() #获取alt print(src) print(name) book=DushuwangItem(src=src,name=name) # 返回到管道文件 pipelines中 yield book -
在管道文件中进行操作,存放数据
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter class DushuwangPipeline: # 这些步骤还是进行读取数据存入json文件中 def open_spider(self,spider): self.fp=open('book.json','w',encoding='utf-8') def process_item(self, item, spider): self.fp.write(str(item)) return item def close_spider(self,spider): self.fp.close() # 进行将数据存放入数据库 mysql # 加载settings文件 from scrapy.utils.project import get_project_settings import pymysql class Mysqldb: def open_spider(self,spider): settings = get_project_settings() # 书写配置 self.host=settings['DB_HOST'] self.port=settings['DB_PORT'] self.user=settings['DB_USER'] self.password=settings['DB_PASSWORD'] self.name=settings['DB_NAME'] self.charset=settings['DB_CHARSET'] self.connect() #连接数据库 # 书写连接 def connect(self): self.conn=pymysql.connect( host=self.host, port=self.port, user=self.user, password=self.password, db=self.name, charset=self.charset ) self.cursor=self.conn.cursor() def process_item(self,item,spider): # 创建sql语句 sql='insert into DuShuWang(name,src) values("{}","{}")'.format(item['name'],item['src']) # 进行连接 self.cursor.execute(sql) self.conn.commit() return item # 关闭 def close_spider(self,spider): self.cursor.close() self.conn.close()
使用正则进行拼接
rules = (
Rule(LinkExtractor(allow=r’/book/1188_\d+.html’), callback=‘parse_item’, follow=True),
)
def parse_item(self, response):
解析源码获取内容
img_list=response.xpath('//div[@class="bookslist"]//img')
进行遍历
for img in img_list:
src=img.xpath('./@data-original').extract_first() #获取图片链接
name=img.xpath('./@alt').extract_first() #获取alt
print(src)
print(name)
book=DushuwangItem(src=src,name=name)
# 返回到管道文件 pipelines中
yield book
8. 在管道文件中进行操作,存放数据
```py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DushuwangPipeline:
# 这些步骤还是进行读取数据存入json文件中
def open_spider(self,spider):
self.fp=open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
# 进行将数据存放入数据库 mysql
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class Mysqldb:
def open_spider(self,spider):
settings = get_project_settings()
# 书写配置
self.host=settings['DB_HOST']
self.port=settings['DB_PORT']
self.user=settings['DB_USER']
self.password=settings['DB_PASSWORD']
self.name=settings['DB_NAME']
self.charset=settings['DB_CHARSET']
self.connect() #连接数据库
# 书写连接
def connect(self):
self.conn=pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor=self.conn.cursor()
def process_item(self,item,spider):
# 创建sql语句
sql='insert into DuShuWang(name,src) values("{}","{}")'.format(item['name'],item['src'])
# 进行连接
self.cursor.execute(sql)
self.conn.commit()
return item
# 关闭
def close_spider(self,spider):
self.cursor.close()
self.conn.close()















 75万+
75万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









