






一、select语句
Hive SELECT 语句用于对表进行查询,即按照规定的语法规则从表中选取数据,并将查询结果保存在结果表中。其基本语法结构如下。
【语法】
SELECT [ALL | DISTINCT] select_expr,select, expr,...
FROM table_reference
[WHERE where_condition
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list ]]
[LIMIT [offset,] rows]
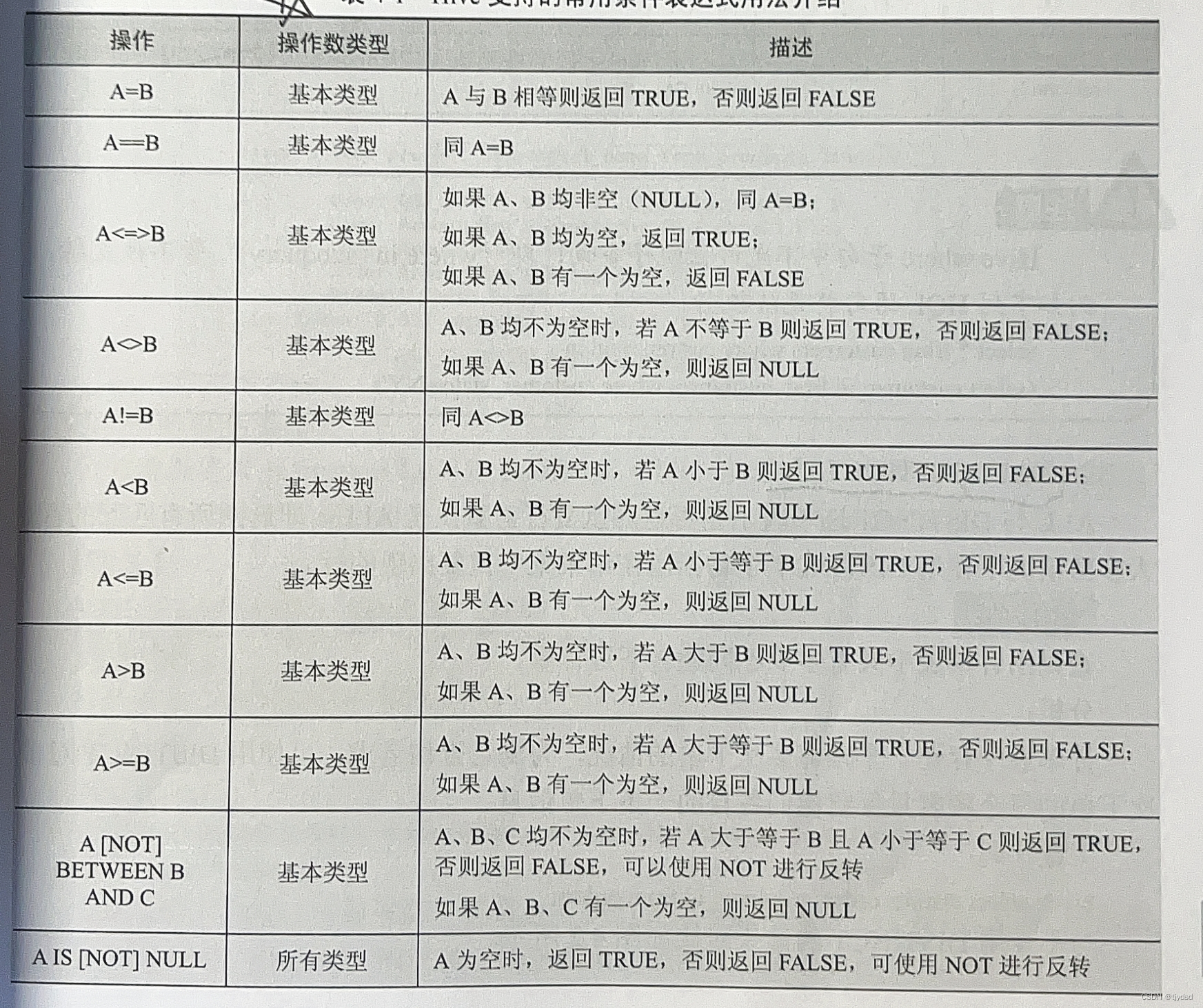
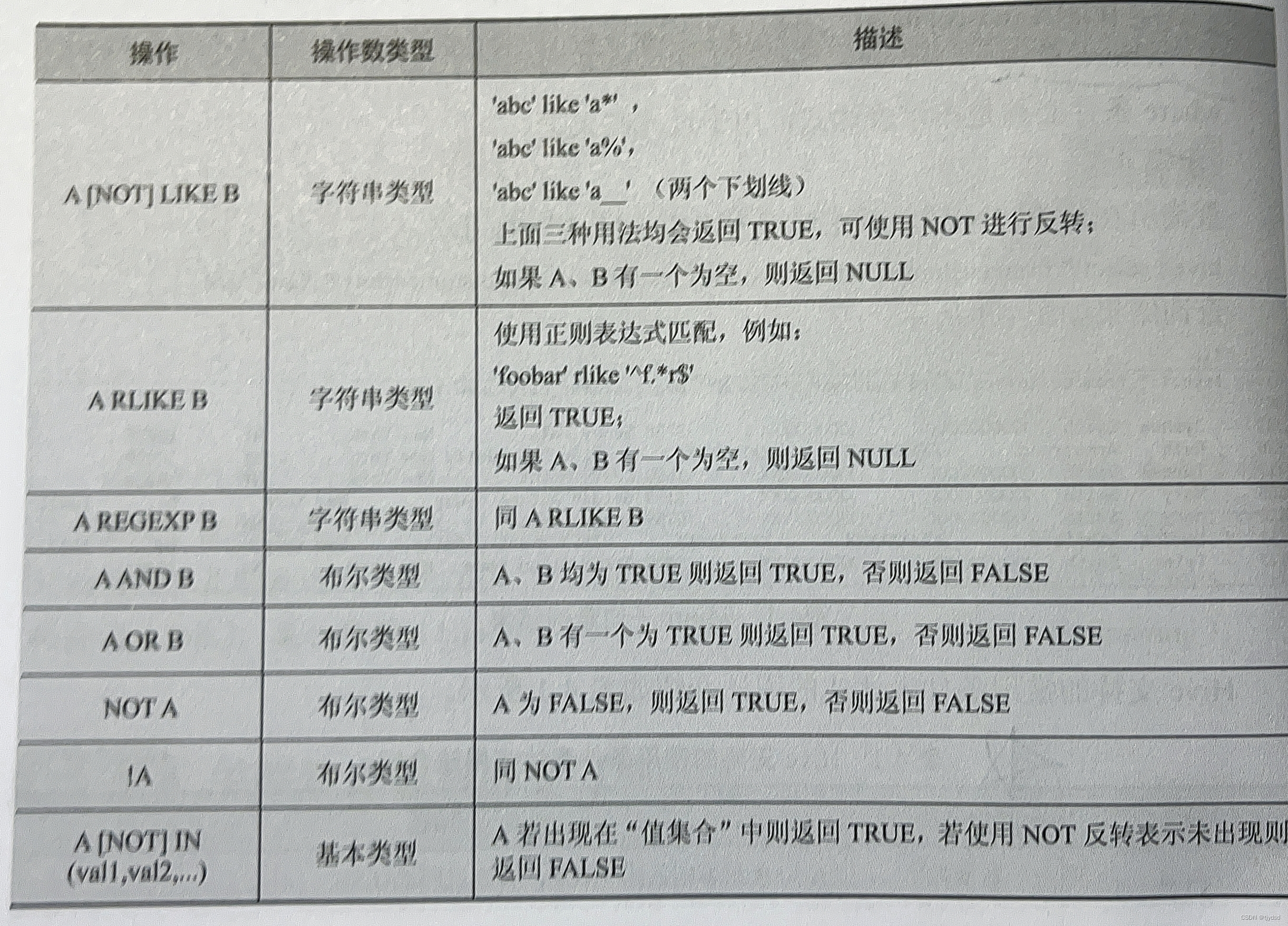
1. where 子句
where 条件必须是布尔表达式,用于过滤结果集。
Hive 支持的常用条件表达式的用法介绍如表所示。
注意
Hive where 子句中不允许出现子查询,即 “where in (subquery)”暂不被支持,例如下列 HQL 语句将无法执行。
select * from customers where customer id in (select customer _id from customers where customer _state=NY')
2.ALL、DISTINCT子句
ALL 与DISTINCT选项表示是否返回重复行,默认是ALL,即返回所有匹配的行。
大多数情况下使用 DISTINCT 子句指出在结果集中重复出现的行
3. LIMIT子句
LIMIT 子句用于限制SELECT 语句返回的行数,其后的整型参数表示共返回多少行。
注意从2.0版本开始Hive 支持两个参数(均整数),分别表示从指定位置(第一
个参数)开始和返回指定的行数(第二个参数)。
4.公共表表达式
公共表表达式(Common Table Expressions,CTE)可以表示一个临时的结果集(表),该表通过一个简单的查询指定,只要在CTE 语句范围内均可共享该临时表。
【语法】
WITH t1 AS (SELECT...) SELECT * FROM TI;
5. 嵌套查询
嵌套查询也称为子查询,通常用于 FROM 子句后。
【语法】
SELECT • FROM (subquery) [AS] name •••
> 子查询必须给定名称,因为 FROM 子句中的每个表必须有表名。
> 子查询中的列必须有唯一的名称,并且在外部查询中可以引用。
> 子查询中可以进行 UNION 和JOIN 操作。
> Hive 支持任意级别的子查询。
> “AS”关键字在 Hive0.13版本后才被支持。
6. 列匹配正则表达式
Hive SELECT 语句支持使用正则表达式指定列名称,凡是符合正则表达式规则的列名将被作为结果集中的一列。
【语法】
SELECT regex _expr' FROM table reference
正则表达式须用一对反引号“”引住,同时设置 “hive.support.quoted.identifiers"属性为 “none”,使 Hive 将反引号解释正则表达式。
7. 虚拟列
虚拟列是并未在表中真正存在的列,但对于数据进行相关验证时非常有用。Hive 的两个常用虚拟列介绍如下。
> INPUT_FILE_NAME:包含 Mapper 任务运行时的输入文件名,也就是该行数据包含于哪个文件中。
> BLOCK_OFFSET_
_INSIDE__FILE:包含文件中的块内偏移量。
其中“_”为两个下划线。















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









