






1.Hive产生背景
传统Hadoop架构存在的一些问题 MapReduce编程必须掌握Java,门槛较高
传统数据库开发、DBA、运维人员学习门槛高
HDFS上没有Schema的概念,仅仅是一个纯文本文件
Hive的产生 为了让用户从一个现有数据基础架构转移到Hadoop上
现有数据基础架构大多基于关系型数据库和SQL查询
Facebook诞生了Hive
2.Hive是什么 它是基于Hadoop的数据仓库工具
方便的将结构化数据文件映射为一张数据库表
提供SQL查询功能,SQL语句底层转换为MR作业执行 Hive提供了一系列功能可以方便进行数据ETL
Hive目前是Apache基金会的项级项目
Hive作为数据仓库工具,非常适合数据仓库联机分析处理(OLAP)
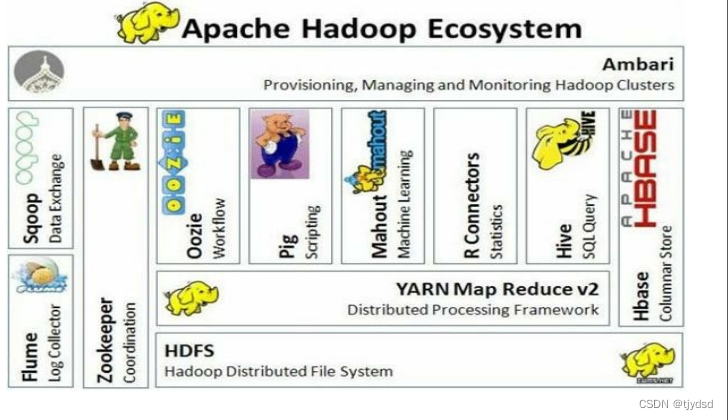
3.Hive在Hadoop生态系统中的位置
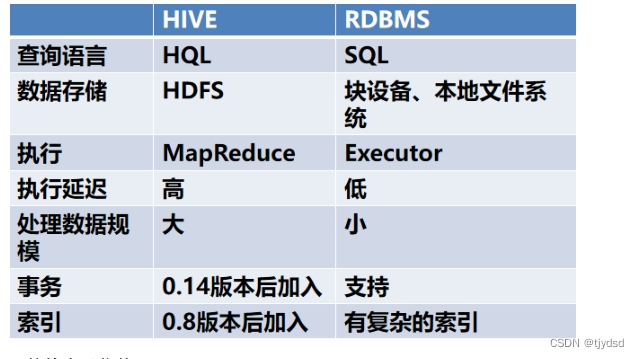
4、hive与传统关系型数据库的异同
延展性,Hive 支持自定义函数,用户可根据需求自定义
可扩展,Hive 可以自由 展集群规模在生产环境中,Hive 有如下优势
Hive 支持用户自定义函数、脚本等
Hive 支持 HDFS 与 HBase上的ad-hoc(点对点模式)
MapReduce、Tez、Spark、Flink 等
Hive 支持运行在不同的计算框架上
Hive 与SQL有着相似的语法,大大提高开发效率
5.Hive 的特点及优势
Hive与SQL有着相似的语法,大大提高开发效率
Hive支持运行在不同的计算框架上
MapReduce, Tez. Spark, Flink 等
Hive支持HDFS与HBase上的ad-hoc(点对点模式)
Hive支持用户自定义函数、脚本等
在生产环境中,Hive有如下优势
可扩展,Hive可以自由扩展集群规模
延展性,Hive支持自定义函数,用户可根据需求自定义
容错性,良好的容错性
6.Hive的架构设计
Hive的架构设计包括三个部分
Hive Client Hive客户端,可通过Java、Python等语言连接Hive并进行与RDBMS类似的SQL查询
操作
Hive Service
Hive服务端,客户端必须通过服务端与Hive交互,主要包括
CLI、HiveServer、HiveWebInterface等组件
Hive Storage and Computing
包含Hive的数据存储与计算的内容,Hive元数据存储在RDBMS中,数据存储在HDFS
中,计算由MR完成
7.Hive的工作流程图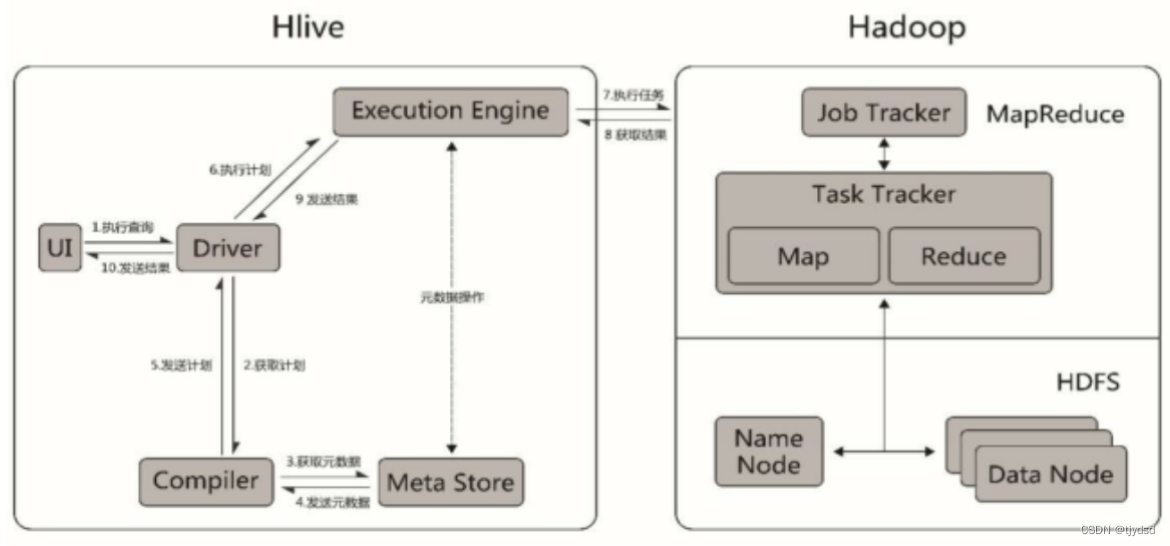















 5996
5996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









