






16.Java反射核心的四个类
Java反射主要涉及以下几个类:
1. **Class**:此类代表正在运行的Java应用程序中的类和接口。对于任何给定的类,都可以通过Class类的实例来获取,这个实例通常被称为类对象。类对象表示正在运行的Java应用程序中的类或接口。例如,Employee类一般是用来描述员工信息的类,Class类是专门用来描述“类和接口”的类[4]。
2. **Field**:此类代表类或接口的单个字段。Field类的实例通常被称为字段对象。
3. **Method**:此类代表类或接口的单个方法。Method类的实例通常被称为方法对象。
4. **Constructor**:此类代表类的单个构造方法。Constructor类的实例通常被称为构造器对象。
以上四个类共同构成了Java反射的基础,通过它们可以在运行时动态地创建对象、执行方法、访问成员变量等。
17.持久化的概念
持久化是一种将数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)的过程。这通常涉及到将内存中的数据模型转换为存储模型,并将存储模型转换回内存中的数据模型。持久化的主要应用是将内存中的对象存储在关系型的数据库中,但也可能存储在磁盘文件中、XML数据文件中等等。
持久化的主要目的是为了保证数据的安全性和可靠性,即使计算机关闭或重启,也能保证数据不会丢失。此外,通过持久化,还可以实现数据的共享和同步,使得不同的程序和系统可以访问相同的数据。
在软件开发中,持久化常常用于将程序的状态、用户的设置等信息保存起来,以便在下次启动程序时能够恢复这些信息。例如,许多操作系统都会将系统的设置信息持久化到硬盘上,这样在系统重启后,用户就不需要重新设置这些信息。
总的来说,持久化是一种非常重要的技术,它保证了数据的安全性和可靠性,同时也提高了程序的可用性和易用性。
18.@SpringBootApplication注解的相关概念
`@SpringBootApplication`是Spring Boot的核心注解,它是一个组合注解,整合了多个常用的Spring Boot注解,用于简化开发过程。
1. **@SpringBootConfiguration**:这是一个`@Configuration`注解的变种,用于标记一个类为Spring Boot的配置类。这意味着这个类中的方法将被Spring Boot用作配置源。
2. **@EnableAutoConfiguration**:这个注解启用了Spring Boot的自动配置机制。Spring Boot会根据项目中已有的依赖关系,自动选择合适的配置。
3. **@ComponentScan**:这个注解用于自动扫描指定包及其子包下的所有类,并将这些类注册为Spring Bean。如果这个注解没有设置任何参数,Spring Boot会默认扫描当前类所在的包及其子包。
此外,`@SpringBootApplication`还包含了一些默认配置,如:
- 将`@SpringBootConfiguration`的`proxyBeanMethods`属性设置为`true`,这允许Spring Boot代理Bean的方法。
- 将`@EnableAutoConfiguration`的`excludedClasses`属性设置为空,这表示不排除任何自动配置类。
- 将`@ComponentScan`的`basePackages`属性设置为当前类所在的包,这表示只扫描当前包及其子包。
总的来说,`@SpringBootApplication`是一个非常方便的注解,它可以帮助开发者快速地创建和配置Spring Boot应用。
19.ApplicationContextAware接口
ApplicationContextAware是Spring中的一个接口,它允许一个bean在运行时知道Spring应用程序上下文的存在。具体来说,当一个bean实现了ApplicationContextAware接口后,这个bean就可以方便地获取到ApplicationContext中的所有bean。(类似于@Autowired注解注入bean)
ApplicationContextAware接口只有一个方法setApplicationContext(), 实现了setApplicationContext方法以后,当Spring容器初始化完以后,它就会检查一下哪些类实现了ApplicationContext接口,然后它就会去调用setApplicationContext方法。Spring容器会把自身作为参数传递给这个方法。在这个方法中,可以将Spring容器赋值给bean的一个成员变量,这样bean就可以在后续的方法中使用这个Spring容器。
下面是一个简单的例子:
假设我们有一个服务类UserService,这个服务类需要依赖于另一个服务类AuthService。如果我们想通过UserService来获取AuthService,那么我们可以让UserService实现ApplicationContextAware接口,然后在setApplicationContext()方法中保存Spring容器,最后在UserService的其他方法中使用这个Spring容器来获取AuthService。
首先,我们需要让UserService实现ApplicationContextAware接口:
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
public class UserService implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public void someMethod() {
// 使用applicationContext获取AuthService
AuthService authService = this.applicationContext.getBean(AuthService.class);
// ...
}
}然后,在setApplicationContext()方法中,我们将Spring容器保存到了UserService的一个成员变量中。这样,在UserService的其他方法中,我们就可以使用这个Spring容器来获取其他的bean。
最后,在someMethod()方法中,我们使用了applicationContext来获取AuthService。这样,我们就成功地在UserService中获取到了AuthService。
这就是ApplicationContextAware在实际应用中的一个例子。通过实现这个接口,我们可以轻松地在运行时获取到Spring容器,从而方便地获取其他的bean。
注:`ApplicationContextAware`和`@Autowired`都可以用于获取Spring容器中的bean,但它们的使用场景和方法有所不同。
`@Autowired`是一种依赖注入的注解,它主要用于在类的属性或方法上声明依赖关系,Spring容器会自动将所需的bean注入到这些位置。例如,如果我们有一个`UserService`类,它需要一个`AuthService`对象,我们可以在`UserService`类的属性上使用`@Autowired`注解,Spring就会自动将`AuthService`对象注入到这个属性中。
而`ApplicationContextAware`则是一种接口,它提供了一个方法`setApplicationContext()`,当Spring容器创建bean时,会将当前的`ApplicationContext`对象作为参数传入这个方法。这样,bean就可以在运行时获取到Spring容器,进而获取其他的bean。例如,如果我们有一个`UserService`类,它需要一个`AuthService`对象,我们可以让`UserService`实现`ApplicationContextAware`接口,然后在`setApplicationContext()`方法中保存Spring容器,最后在其他方法中使用这个Spring容器来获取`AuthService`。
总的来说,`@Autowired`主要用于在编译时就确定bean的依赖关系,而`ApplicationContextAware`则提供了一种在运行时获取bean的方式。两者各有优劣,可以根据实际情况选择使用。
20.比较器
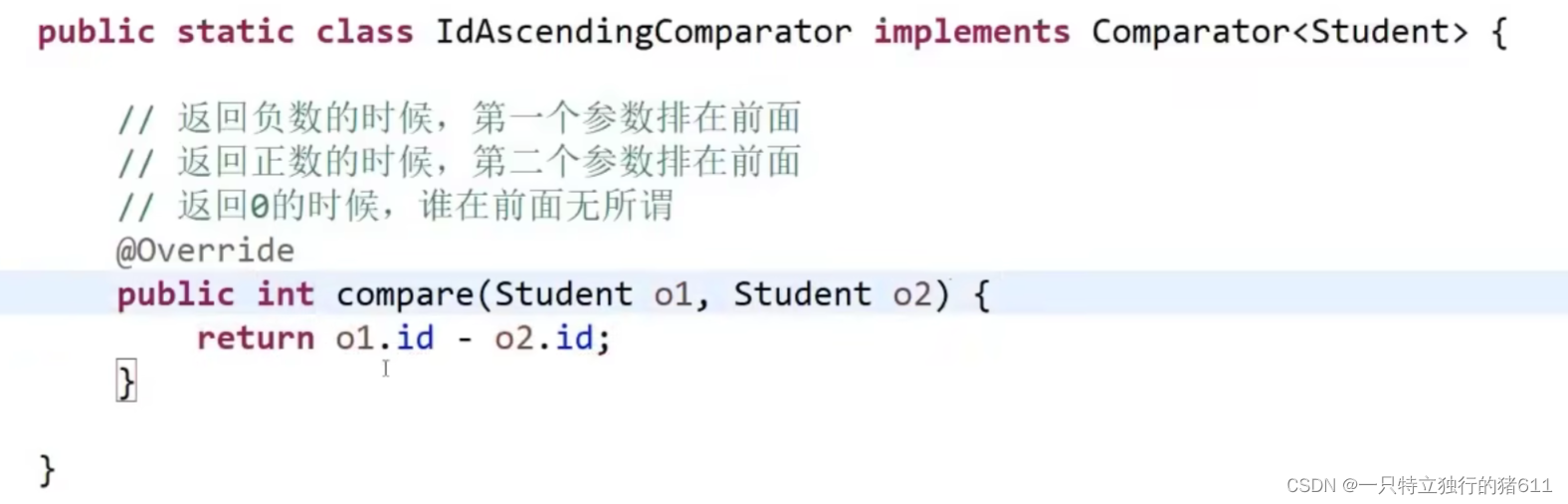
20.1比较器的概念
在Java中,有两种类型的比较器:`Comparable` 和 `Comparator`。
Comparable
`Comparable` 是一个接口,定义在 `java.lang` 包中。当一个类实现了 `Comparable` 接口时,就意味着这个类的对象可以进行比较。`Comparable` 接口中有一个方法 `compareTo()`,这个方法用于比较当前对象和参数对象的大小。通常,如果 `compareTo()` 方法的返回值为负数,说明当前对象小于参数对象;如果返回值为0,说明两者相等;如果返回值为正数,说明当前对象大于参数对象。例如,`String` 类和 `Integer` 类都已经实现了 `Comparable` 接口,因此我们可以直接比较字符串或者整数的大小。
Comparator
`Comparator` 也是一个接口,定义在 `java.util` 包中。`Comparator` 接口中有一个方法 `compare()`,这个方法也是用于比较两个对象的大小。与 `Comparable` 不同的是,`Comparator` 允许我们在运行时动态地指定比较方式,而不需要在编写类时就确定好比较方式。例如,如果我们想要按照学生的年龄来比较,就可以创建一个 `Comparator` 实例,然后在比较时使用这个实例。
总的来说,`Comparable` 和 `Comparator` 都是用来比较对象大小的,但 `Comparable` 是内建在类中的比较方式,而 `Comparator` 则是外部的比较方式,可以根据需要动态改变比较方式。
20.2两种比较器的区别
在Java中,`Comparable` 和 `Comparator` 都是用于比较对象大小的接口,但它们有一些重要的区别:
1. **来源**:`Comparable` 是一个内置在类中的比较方式,当你创建一个新的类时,可以直接实现 `Comparable` 接口,然后重写 `compareTo()` 方法来实现比较逻辑。而 `Comparator` 是一个外部的比较方式,你需要创建一个新的比较器对象,然后通过这个对象来比较两个对象的大小。
2. **比较方式**:`Comparable` 的比较方式是固定的,一旦你在类中实现了 `Comparable` 接口,你就不能再改变比较方式。而 `Comparator` 的比较方式是可以根据需要自己定义的,你可以创建多个比较器对象,每个对象都可以有不同的比较方式。
3. **适用范围**:`Comparable` 的比较方式只适用于该类的对象,而 `Comparator` 的比较方式可以适用于不同类型的对象。也就是说,如果你有一个 `Comparator` 对象,你可以用它来比较任何类型的对象,只要这两个对象都可以转换为相同的类型。
总的来说,`Comparable` 和 `Comparator` 都是Java中用于集合排序的接口,但它们有各自的优缺点。在实际编程中,我们需要根据具体情况选择使用哪种方式,才能更加高效地完成任务。
20.3使用案例
Comparable 接口的使用示例
假设我们有一个名为 Student 的类,它代表一个学生,包含姓名和成绩两个属性。我们希望按照学生的成绩进行排序,那么我们可以让 Student 类实现 Comparable 接口,并重写 compareTo() 方法:
public class Student implements Comparable<Student> {
private String name;
private double score;
// 构造函数和其他方法省略
@Override
public int compareTo(Student other) {
return Double.compare(this.score, other.score); // 比较成绩
}
}现在,我们有了一个 Student 对象列表,我们可以使用 Arrays.sort() 方法对其进行排序:
List<Student> students = ...; // 初始化学生列表
Arrays.sort(students.toArray(new Student[0])); // 使用默认排序在这个例子中,Student 类实现了 Comparable 接口,所以我们可以直接使用 Arrays.sort() 方法进行排序,无需额外的比较器。
Comparator 接口的使用示例
有时候,我们可能需要按照不同的标准进行排序,这时可以使用 Comparator 接口。例如,我们可能希望先按照成绩排序,如果成绩相同,再按照姓名排序。我们可以创建一个比较器类来实现这种比较方式:
public class StudentComparator implements Comparator<Student> {
@Override
public int compare(Student student1, Student student2) {
int result = Double.compare(student1.getScore(), student2.getScore()); // 比较成绩
if (result == 0) { // 如果成绩相同,比较姓名
result = student1.getName().compareTo(student2.getName());
}
return result;
}
}然后,我们可以使用 Arrays.sort() 方法,并将我们的比较器传递给它:
List<Student> students = ...; // 初始化学生列表
Arrays.sort(students.toArray(new Student[0]), new StudentComparator()); // 使用自定义排序在这个例子中,我们创建了一个 StudentComparator 类来实现自定义的比较方式,并通过 Arrays.sort() 方法传递给 Student 对象列表,从而实现按照成绩和姓名的组合进行排序。
20.4总结
Comparable 和 Comparator 都是用于比较对象大小的接口,但 Comparable 是在类内部实现的比较方式,而 Comparator 是在类外部实现的比较方式。Comparable 适合于在类设计阶段就已经考虑到了比较的需求,而 Comparator 更适合于在运行时根据需要动态地指定比较方式。在实际编程中,我们需要根据具体的情况选择使用哪种方式,以达到最佳的效果
21.MySql中的explain命令
在MySQL数据库中,EXPLAIN 是一个非常重要的命令,它用于分析SQL查询的执行计划,帮助我们理解MySQL是如何处理我们的SQL语句,以及如何优化查询性能。
EXPLAIN 命令的使用方法非常简单,只需要在SQL语句前加上 EXPLAIN 关键字即可。例如,如果你想查看 SELECT * FROM table WHERE condition 这条SQL语句的执行计划,你可以这样写:
EXPLAIN SELECT * FROM table WHERE condition;EXPLAIN 命令会输出一个包含以下列的结果:
id: 执行编号,有几个SELECT就有几个id。select_type: 表示本行是简单的还是复杂的SELECT。table: 正在访问哪一个表(表名或别名)。type: 表示关联类型或访问类型,即 MySQL 决定如何查找表中的行。possible_keys: 哪些索引可以优化查询。key: 实际采用哪个索引来优化查询。key_len: 索引字段的长度。ref: 显示了之前的表在key列记录的索引中查找值所用的列或常量。rows: 为了找到所需的行而需要读取的行数(估算值,并不精确)。Extra: 执行情况的额外描述和说明。
通过分析这些信息,你可以了解查询的执行计划,包括查询的表的读取顺序、数据读取操作的操作类型、哪些索引可以使用、哪些索引被实际使用、表之间的引用、每张表有多少行被优化器查询等信息。
需要注意的是,EXPLAIN 命令只能提供查询执行的近似结果,并不能显示关于查询的执行计划的所有信息。此外,EXPLAIN 也不会告诉你触发器、存储过程或用户自定义函数对查询的影响情况,也不会告诉你 MySQL 在查询执行中所做的特定优化。
22.Java中的三种拷贝
在Java中,有三种对象拷贝的方式:浅拷贝、深拷贝和延迟拷贝。
简述深拷贝和浅拷贝的区别:
浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
浅拷贝概念:
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
深拷贝概念:
深拷贝则是对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。假设B复制了A,修改A的时候,看B是否发生变化:如果B跟着也变了,说明是浅拷贝(修改堆内存中的同一个值);如果B没有改变,说明是深拷贝(修改堆内存中的不同的值)。
延迟拷贝
延迟拷贝是一种特殊的拷贝方式,它在需要时才进行拷贝,从而避免了不必要的开销。
在Java中,你可以通过多种方式来实现这些拷贝方式,比如使用`System.arraycopy()`函数来进行数组拷贝,或者实现`Cloneable`接口并重写`clone()`方法来进行对象拷贝等。
需要注意的是,选择哪种拷贝方式取决于你的具体需求,每种方式都有其适用场景。例如,如果你希望拷贝后的对象能够独立于原对象,那么应该选择深拷贝。
23.MySQL中的执行顺序
在MySQL中,SQL语句的执行顺序并不是按照它们在语句中出现的顺序,而是遵循一定的规则。以下是MySQL中SQL语句的基本执行顺序:
- FROM 和 JOIN:首先,MySQL会确定查询中涉及的所有表和它们之间的关联关系。这包括解析FROM子句和JOIN子句,并进行表的连接操作,如内连接、左连接、右连接等。
- WHERE:一旦确定了哪些行需要从表中检索,MySQL会使用WHERE子句来过滤这些行。WHERE子句中的条件用于限制返回的行数。
- GROUP BY:如果查询中包含GROUP BY子句,MySQL会对结果集进行分组。分组是基于指定的列或表达式的值进行的。
- HAVING:HAVING子句在分组后应用,用于过滤分组后的结果集。与WHERE不同,HAVING允许我们基于聚合函数的结果进行过滤。
- SELECT:这一步,MySQL会处理SELECT子句,确定要返回的列和表达式。这包括列的选择、聚合函数的应用等。
- DISTINCT:如果查询中使用了DISTINCT关键字,MySQL会删除结果集中的重复行。
- ORDER BY:在返回最终结果之前,MySQL会根据ORDER BY子句对结果集进行排序。排序可以是升序(ASC)或降序(DESC)。
- LIMIT 和 OFFSET:最后,如果查询中包含了LIMIT和OFFSET子句,MySQL会限制返回的行数,并可能跳过一定数量的行。这通常用于分页。
需要注意的是,这个执行顺序是逻辑上的,MySQL查询优化器可能会根据具体情况对查询进行重写或调整执行计划,以达到更高的性能。因此,实际的物理执行顺序可能与这个逻辑顺序有所不同。理解查询的执行顺序可以帮助我们编写更高效、更有针对性的查询语句。例如,将过滤条件放在WHERE子句中通常比放在HAVING子句中更高效,因为WHERE过滤发生在分组之前,可以减少需要处理的行数。同样,合理地使用索引也可以显著提高查询性能。
24.final关键字
在Java中,final关键字主要用于三种情况:修饰类、修饰方法和修饰变量。以下是final关键字在不同场景下的基本用法和特点:
修饰类
当final关键字用于修饰一个类时,意味着这个类不能被其他类继承。这是一个明确的信号,表明开发者不希望这个类有子类,从而保持了这个类的完整性和稳定性。例如:
public final class FinalClass {
// 类体...
}
在这个例子中,FinalClass是一个不能被继承的类。
修饰方法
当final关键字用于修饰一个方法时,意味着这个方法不能被任何子类重写。这通常用于确保方法的行为不会被改变,特别是在那些不应该被重写的方法上。例如:
public final void finalMethod() {
// 方法体...
}
在这个例子中,finalMethod方法不能在任何子类中被重写。
修饰变量
当final关键字用于修饰一个变量时,意味着这个变量的值一旦被设定之后就不能再被改变。这通常用于确保变量的值在整个程序运行期间保持不变,类似于常量的概念。例如:
final int constantValue = 10;
在这个例子中,constantValue变量的值在初始化后就不能被改变了。
需要注意的是,final关键字修饰的变量必须在声明时就初始化,或者至少在第一次使用之前必须初始化。这是因为final变量的值是不可变的,所以必须知道它们的初始值。
总的来说,final关键字在Java中用于确保某些事物(类、方法或变量)的状态不可改变,这对于保证代码的预期行为和避免不必要的复杂性非常有帮助。
25.Java中的函数式接口
在Java中,函数式接口是一种特殊类型的接口,它们具有一个并且只有一个抽象方法。这意味着它们可以用来表示单个行为或操作。函数式接口的主要用途是与Lambda表达式一起使用,以使代码更加简洁和易于理解。
函数式接口可以是Java API中已经存在的接口,如Runnable,Comparator等,也可以是自定义的接口。例如,下面是一个简单的自定义函数式接口:
@FunctionalInterface
public interface SimpleFunctionalInterface {
void execute();
}
在这个例子中,SimpleFunctionalInterface是一个函数式接口,因为它只有一个名为execute的抽象方法。
函数式接口可以通过Lambda表达式来实现,如下所示:
SimpleFunctionalInterface functionalInterface = () -> {
System.out.println("Hello from Lambda Expression!");
};
在这个例子中,我们创建了一个SimpleFunctionalInterface的实例,并使用了Lambda表达式来提供execute方法的实现。
函数式接口还可以用于Java Stream API,以提供一种更自然的方式来处理集合中的元素。例如,我们可以使用函数式接口来筛选集合中的元素:
List<String> list = Arrays.asList("a", "b", "c", "d", "e");
Predicate<String> predicate = (String s) -> s.equalsIgnoreCase("a");
List<String> filteredList = list.stream().filter(predicate).collect(Collectors.toList());
在这个例子中,我们使用了Predicate这个函数式接口来创建一个谓词,该谓词用于判断字符串是否等于"a"(忽略大小写)。然后,我们使用Stream API的filter方法来过滤集合中的元素,最后收集结果到一个新的列表中。
总之,函数式接口是Java中一种重要的概念,它与Lambda表达式一起使用,可以使代码更加简洁和易于理解。
26.sql注意事项
1、统计 COUNT(列名) 和COUNT(*)均可,区别是前者只会统计非NULL。
2、where后面不能跟聚合函数,用的话应该在Having使用,因此需要先分组GroupBy
where是基于行过滤,having是基于分组过滤
3、虽然执行顺序中having、group by在select后面,但是它们还是可以用select中定义的别名
执行顺序 :from > on > where > group by > having > select > distinct > order by > top
但是,MYSQL 中HAVING是可以使用SELECT中定义的别名。HAVING、GROUP BY都可以使用SELECT中定义的别名。
具体来说,在执行 SELECT 子句时,系统先计算 SELECT 中的列表达式和函数等,然后为这些列赋予一个列别名,并生成一个虚拟的查询结果表。接着,系统按照 GROUP BY 子句中的指定字段分组,并对每个分组进行计算,生成虚拟的分组结果表。最后,HAVING 子句基于这个虚拟的分组结果表进行筛选操作。
由于在执行 HAVING 子句时已经生成了虚拟的查询结果表和虚拟的分组结果表,已经存在列别名,但是没有值,因此 HAVING 子句可以直接引用 SELECT 列别名。
4、聚合函数本质:对指定的列进行聚合,如果我们用了group by,我们可以对每个分组应用内聚合函数。在分组内部,聚合函数会自动处理所有重复的行。举例子:
一个表中,记录了销售员ID、销售日期。需求是计算每个销售员的总销售额。
我们对ID进行分组,这样通过聚合函数SUM能将同一分组的销售额累加起来【即同一个销售员】
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales_records
GROUP BY salesperson_id;














 5502
5502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









