










文章目录
- 1. NLU \textbf{1. NLU} 1. NLU的概念与背景
- 2. NLU \textbf{2. NLU} 2. NLU的主要任务
- 3. \textbf{3. } 3. 自然语言的统计特性
- 4. \textbf{4.} 4. 词袋语言模型
- 5 \textbf{5 } 5 主题语言模型
有关 Github \text{Github} Github仓库,欢迎来 Star \text{Star} Star
1. NLU \textbf{1. NLU} 1. NLU的概念与背景
1️⃣ NLU \text{NLU} NLU与 NLP \text{NLP} NLP
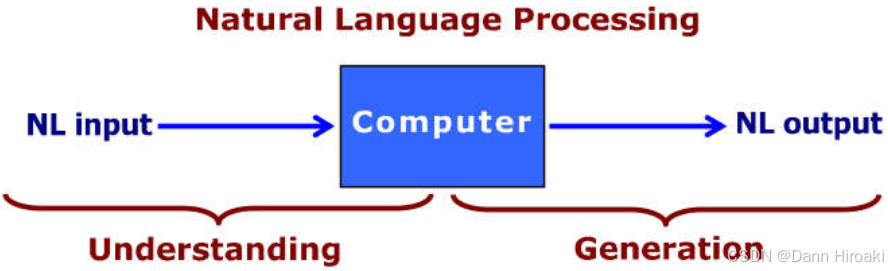
- 自然语言理解:
- 含义:让计算机理解人类语言的结构 + + +语义
- 应用:信息检索/情感识别/机器翻译/拼写检查/知识图谱构建
- 自然语言处理:对自然语言的分析/理解/生成,即 NLU+NLG(Generation) \text{NLU+NLG(Generation)} NLU+NLG(Generation)
2️⃣ AI-Hard \text{AI-Hard} AI-Hard问题
- 含义:问题等同于 AI \text{AI} AI核心的问题,即如何让计算机具有人类智能
- 典型: NLU/NLP \text{NLU/NLP} NLU/NLP, CV \text{CV} CV
3️⃣ NLU \text{NLU} NLU面临的挑战
- 计算机的特性:善于处理明确/结构化/无歧义的语言(如编程语言)
- 自然语言特性:具有复杂的上下文以及歧义性( Ambiguity \text{Ambiguity} Ambiguity)
歧义类型 含义 示例 词汇歧义 词汇具有不同含义 Fuck \text{Fuck} Fuck可以是动词/语气词 句法歧义 一个句子被解析成不同的结构 南京市长江大桥 语义歧义 句中包含了不明确的词 John kissed his wife, and so did Sam \text{John kissed his wife, and so did Sam} John kissed his wife, and so did Sam 回指歧义 之前提到的词,在后面句子含义不同 小李告诉小王他生了 语用歧义 短语/句子不同语境下含义不同 可以站起来吗 (询问能力 or \text{or} or请求)
2. NLU \textbf{2. NLU} 2. NLU的主要任务
2.1. NLU \textbf{2.1. NLU} 2.1. NLU的语法任务
2.1.1. \textbf{2.1.1. } 2.1.1. 词汇层面的任务
1️⃣词干抽取( Stemming \text{Stemming} Stemming)
- 含义:抽取词的词干( Stem \text{Stem} Stem)与词根( root \text{root} root),比如 Niubilitiness → { 词干: Niubility 词根: Niubi \text{Niubilitiness}\to\begin{cases}\text{词干: Niubility}\\\\词根\text{: Niubi}\end{cases} Niubilitiness→⎩ ⎨ ⎧词干: Niubility词根: Niubi
- 处理方法:
方法 含义 限制 利用形态规则 机械地去处所有后缀,如 -ing/-tion \text{-ing/-tion} -ing/-tion 不规则变形词不适用 基于词典 按照词典中的映射还原词性 受限于词典规模 高级方法 n-gram \text{n-gram} n-gram法/隐马可夫/机器学习 受限于语料库大小 2️⃣词形还原( Lemmatization \text{Lemmatization} Lemmatization)
- 含义:将不同形式词汇还原为词目( Lemma \text{Lemma} Lemma),如 am, is, are, was, were→be \text{am, is, are, was, were→be} am, is, are, was, were→be
- 对比:词干抽取完全不考虑上下文,词形还原考虑一定的上下文
- 示例: We are meeting in the zoom meeting → 词形还原 词干抽取 { 词干抽取: meet 词形还原: meet+meeting \text{We are meeting in the zoom meeting}\xrightarrow[词形还原]{词干抽取}\begin{cases}\text{词干抽取: meet}\\\\\text{词形还原: meet+meeting}\text{}\end{cases} We are meeting in the zoom meeting词干抽取词形还原⎩ ⎨ ⎧词干抽取: meet词形还原: meet+meeting
- 处理方法:
- 基于规则:人工给予的语言学规则,或者机器学习训练出来的规则
- 基于词典:受限于词典,只适用于简单语言
💡词形还原/词干抽取并非 100% \text{100\%} 100%必要,比如细颗粒度情感分析就需要高精度文本(时态/复数等)3️⃣词性标注( Part-of-speech tagging \text{Part-of-speech tagging} Part-of-speech tagging)
- 含义:为文本中每个词标记词性(名词/动词/形容词)
- 方法:基于规则(人工),基于隐马可夫模型( HMM \text{HMM} HMM),基于机器学习(SVM/神经网络)
- 挑战:分词 & \text{\&} &词义多义性
4️⃣术语抽取( Terminology extraction \text{Terminology extraction} Terminology extraction)
- 含义:信息抽取的子任务,识别文本中特定领域的专门术语
- 方法:机器学习,统计( TF/IDF \text{TF/IDF} TF/IDF),外部知识库
- 挑战:新术语/跨领域术语
2.1.2. \textbf{2.1.2. } 2.1.2. 句法层面的任务
1️⃣句法分析( Parsing \text{Parsing} Parsing)
- 含义:分析文本中单词/短语之间的句法关系
- 方法:统计学(概率上下文无关文法/最大化信息熵的原则),机器学习方法( RNN \text{RNN} RNN)
2️⃣断句( Sentence breaking \text{Sentence breaking} Sentence breaking)
- 含义:句子边界消歧(例如 . \text{ . } . 可表示短句/缩写/小数点等) + + +句子分割
- 方法:基于最大熵,神经网络
3️⃣分词( Word segmentation \text{Word segmentation} Word segmentation)
- 含义:仅对词汇间没有明显边界的语言/中文而言,将连续字符分割为有意义单词
- 方法:基于字典(正逆向匹配),基于统计( HMM/SVM \text{HMM/SVM} HMM/SVM)
- 难处:未登录词/切分歧义
2.2. NLU \textbf{2.2. NLU} 2.2. NLU的语义任务
2.2.1. \textbf{2.2.1. } 2.2.1. 文本生成/转换
1️⃣机器翻译
- 含义:将文本/语音从一种语言翻译到另一种语言
- 方法:基于规则(源/目标语言形态语法等),基于统计(用大型语料库构建概率模型),神经网络
- 难题:词句歧义/对语料库大小强依赖/低频词句/长句子
2️⃣问答与对话
- 含义:实现自然语言形式的人机交互
- 分类:
- 5W1H \text{5W1H} 5W1H类问题:即 Who/What/When/Where/Why & How \text{Who/What/When/Where/Why \& How} Who/What/When/Where/Why & How
- Open/Closed-domain \text{Open/Closed-domain} Open/Closed-domain类:回答可以没有限制 or \text{or} or 专注于某一领域
- 方法:检索法(从库中抽取语料回答),生成法(检索 + + +推理), Pipeline \text{Pipeline} Pipeline, Seq2Seq \text{Seq2Seq} Seq2Seq
- 难题:多知识约束/多轮对话/多模态/可解释性…
3️⃣自动文摘
- 含义:为文档生成一段包含原文档要点的压缩文档,例如搜索引擎结果
- 方法:对要点进行不修改的抽取,对要点概括(修改/复述)
- 难题:难以评估,可理解性问题,需要背景知识
2.2.2. \textbf{2.2.2. } 2.2.2. 文本信息提取
1️⃣命名实体识别( NER, Named entity recognition \text{NER, Named entity recognition} NER, Named entity recognition)
- 命名实体:现实世界中的某个对象,如 Obama is the president of the United States \text{\textcolor{red}{Obama} is the \textcolor{red}{president} of \textcolor{red}{the United States}} Obama is the president of the United States
- NER \text{NER} NER:信息提取的子任务,识别文本中所有实体 + + +分配到特定类别(名字/时间/数量)
- 方法:语法规则(效果好但需要大量人工规则),统计方法(需要标注大量数据)
- 难题:领域依赖性(如医学实体/术语),实体类型多样
2️⃣关系抽取
- 含义:检测文本中实体的语义关系,并将各种关系分类
- 方法:结合了领域知识的机器学习
- 难点:训练集难以构建,自然语言的歧义
2.2.3. \textbf{2.2.3. } 2.2.3. 文本内容分析
1️⃣文本分类
- 含义:自动将文本划分到预定类中,比如垃圾邮件过滤/情感识别/黄色内容识别
- 方法:特征提取 → \to →训练分类器(朴素贝叶斯/ KNN \text{KNN} KNN/ SVM \text{SVM} SVM)
- 难题:特征难提取(需要大量标注),数据非平衡问题
2️⃣情感分析
- 含义:识别文本中的情感状态,主观评价等
- 方法:情感词库( Happy/Fucking \text{Happy/Fucking} Happy/Fucking),统计方法( SVM/ \text{SVM/} SVM/潜在语义分析)
- 难题:修辞的多样(反语/讽刺),分面观点(即将复杂事物分解为不同方面)
3️⃣主题分割
- 含义:将单个长文本分为多个较短的,主题一致的片段
- 方法:
- 基于内容变化:同一主题内容有高度相似性 → \to →通过聚类
- 基于边界特性:主题切换时会有边界(如过渡性/总结性文本)
- 难点:任务目标模糊(主题多样),无关信息干扰,歧义性
2.2.4. \textbf{2.2.4. } 2.2.4. 文本歧义消解
1️⃣词义消歧
- 含义:确定一词多义词的含义
- 方法:基于词典(叙词表/词汇知识库),基于机器学习(小语料库的半监督学习/标注后的监督学习)
- 难题:词义的离散型(一个词的不同含义可能完全不搭边),需要常识
2️⃣共指消解
- 含义:识别文本中表示同一个事物的不同代称
- 示例:甲队打败了乙队,他们更强 → 消解后 \xrightarrow{消解后} 消解后虽然甲队打败了乙队,但他们更强
- 方法:
- 启发式:如最接近语法兼容词,即在代词前寻找最近的 + + +语法匹配的词
- 基于 ML \text{ML} ML:如 Mention-Pair Models / Mention-Ranking Models \text{Mention-Pair Models / Mention-Ranking Models} Mention-Pair Models / Mention-Ranking Models
- 难题:如何应用背景知识,歧义(哪哪都有它,考试的万金油解答嘿嘿)

3. \textbf{3. } 3. 自然语言的统计特性
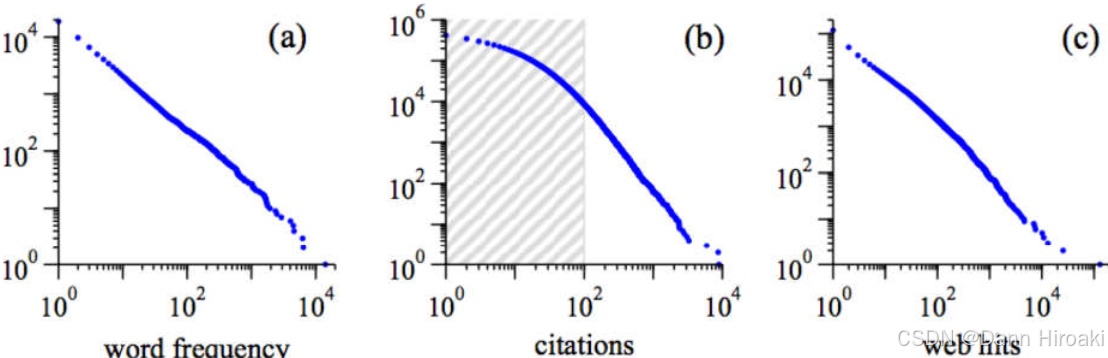
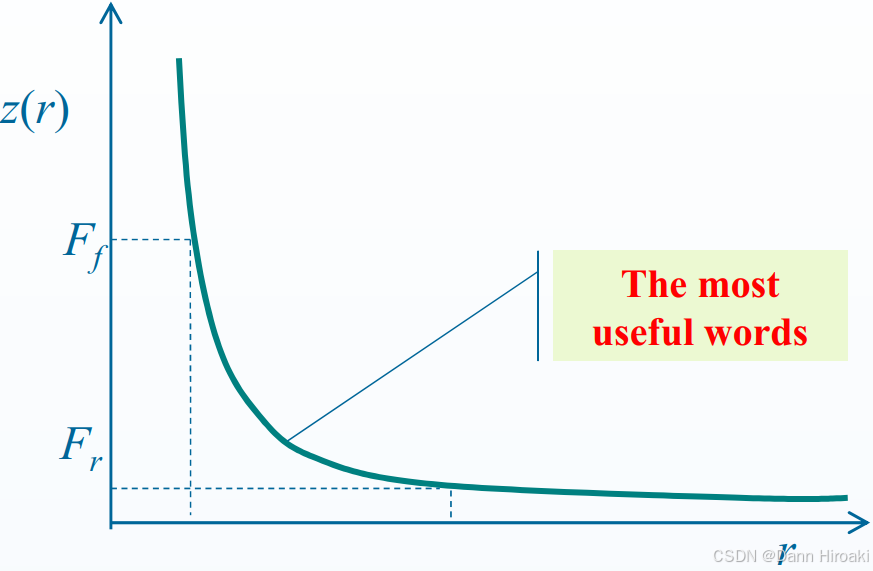
3.1. Zipf \textbf{3.1. Zipf} 3.1. Zipf定律
1️⃣ Zipf \text{Zipf} Zipf定律
- 内容:令出现频率第 r r r高的词汇出现频率为 f ( r ) f(r) f(r),则有 f ( r ) = Const r s f(r)\text{=}\cfrac{\text{Const}}{r^{s}} f(r)=rsConst其中 s ≈ 1 s\text{≈}1 s≈1
- 含义:对于词频分布,最常见词的分布极为普遍 + + +大多数词出现频率极低
- 解释:
解释模型 含义 米勒猴实验 胡乱生成的带有字母 + + +空格的序列,词频和排名也符合幂律关系 最小努力原则 通过词频差异最小化交流的成本 优先连接机制 网络结构中,新节点倾向于连接度数更大的点,与 Zipf \text{Zipf} Zipf类似 2️⃣ Zipf \text{Zipf} Zipf定律的实验
- 符合程度: f ( r ) = Const r s → log f ( r ) = log C − s log r f(r)\text{=}\cfrac{\text{Const}}{r^{s}}\to{}\log{f(r)\text{=}}\log{C}-s\log{r} f(r)=rsConst→logf(r)=logC−slogr故可通过检测后者线性程度
- 实验结论:幂律分布很常见 + + +排名靠中间的术语会更符合
3️⃣ Zipf \text{Zipf} Zipf定律与索引
- 倒排索引:用于快速全文检索的数据结构,示例如下
- 文档
Doc1: fat cat rat rat Doc2: fat cat Doc3: fat- 构建的倒排索引
fat: Doc1 Doc2 Doc3 cat: Doc1 Doc2 rat: Doc1- 词频太高/太低的词都不适合索引,会导致返回太多/太少的文档,适中的才最有价值
- 基于 Zipf \text{Zipf} Zipf定律,去处高频 Stopword \text{Stopword} Stopword能优化倒排索引时空开销,如下为倒排索引的一个实例
3.2. Heaps \textbf{3.2. Heaps} 3.2. Heaps定律
1️⃣ Heaps \text{Heaps} Heaps定律
- 内容:词汇表大小 V V V与文本词数 n n n满足 V = K n β V\text{=}Kn^{\beta} V=Knβ
- 参数: 10 ≤ K ≤ 100 10\text{≤}K\text{≤}100 10≤K≤100且 0.4 ≤ β ≤ 0.6 0.4\text{≤}\beta\text{≤}0.6 0.4≤β≤0.6,当 K = 44 K\text{=}44 K=44与 β = 0.49 \beta\text{=}0.49 β=0.49最匹配
2️⃣用途:预测随文本增长词汇表 & \& &倒排索引大小的变化
3.3. Benford \textbf{3.3. Benford} 3.3. Benford定律(第一数字法则)
1️⃣ Benford \text{Benford} Benford定律
- 背景:在许多社会现象中,数据首位数往往分布不均(为 1 1 1概率最大 → 依次递减 \xrightarrow{依次递减} 依次递减为 9 9 9概率最小)
- 定律:令数据集中 d d d作为首字母的概率 P ( d ) = lg ( 1 + 1 d ) P(d)=\lg{\left(1+\cfrac{1}{d}\right)} P(d)=lg(1+d1), d > 9 d\text{>}9 d>9及非十进制时依旧适用
2️⃣对 Benford \text{Benford} Benford定律的一些思考
- 适用:跨数量级变化的数据集,如财务数据和自然现象
- 应用:检测数据造假、异常值、验证财务报告真实性
- 成因:还不具备完全的可解释性,大概是因为数据在对数尺的分布
4. \textbf{4.} 4. 词袋语言模型
4.1. BoW \textbf{4.1. BoW} 4.1. BoW模型
1️⃣基本步骤:以句 I love machine learning \text{I love machine learning} I love machine learning以及 Machine learning is fun \text{Machine learning is fun} Machine learning is fun为例
步骤 示例 分词 I love machine learning Machine learning is fun \text{I \\ love \\ machine \\ learning \\ }\text{Machine \\ learning \\ is \\ fun} I love machine learning Machine learning is fun 建表 V =[I, love, machine,lerning, is, fun] V\text{=[I, love, machine,lerning, is, fun]} V=[I, love, machine,lerning, is, fun] 向量化 第一句变为 A 1 =[1,1,1,1,0,0] A_1\text{=[1,1,1,1,0,0]} A1=[1,1,1,1,0,0]第二局变为 A 2 =[0,0,1,1,1,1] A_2\text{=[0,0,1,1,1,1]} A2=[0,0,1,1,1,1] 2️⃣特点
- 原理上:完全忽略了语法/词序,默认词与词间的概率分布独立
- 效果上:
- 优点:实现极其简单,但高效且应用广泛
- 缺点:无法区分 & \text{\&} &一义多词,如同义词替换后的两文档相似度低于实际值
4.2. TF-IDF \textbf{4.2. TF-IDF} 4.2. TF-IDF模型
1️⃣ TF-IDF \text{TF-IDF} TF-IDF值
- 计算: TF-IDF ( t , d ) =TF ( t , d ) ×IDF( t ) → { 词频TF ( t , d ) = 词 t 在文档 d 出现次数 文档 d 总词数 逆文档频IDF(t)= log 文档总数 DF ( t ) ( 包含 t 的文档数 ) + 1 \text{TF-IDF}(t,d)\text{=TF}(t,d)\text{×IDF(}t)\text{→}\small{}\begin{cases}词频\text{TF}(t,d)=\cfrac{词t在文档d出现次数}{文档d总词数}\\\\逆文档频\text{IDF(t)=}\log\cfrac{文档总数}{\text{DF}(t)(包含t的文档数)\text{+}1}\end{cases} TF-IDF(t,d)=TF(t,d)×IDF(t)→⎩ ⎨ ⎧词频TF(t,d)=文档d总词数词t在文档d出现次数逆文档频IDF(t)=logDF(t)(包含t的文档数)+1文档总数
- 含义: TF-IDF ( t , d ) \text{TF-IDF}(t,d) TF-IDF(t,d)越高,代表词 t t t对文档 d d d越重要
2️⃣ TF-IDF \text{TF-IDF} TF-IDF值改进:原始词频值往往不是所需的
- 对原始词频 TF ( t , d ) \text{TF}(t,d) TF(t,d)的改进
词频类型 公式 意义 对数 1 + log ( TF ( t , d ) ) 1\text{+}\log (\text{TF}(t,d)) 1+log(TF(t,d)) 压缩较高词频,减少其对相关性影响的夸大 增强 0.5 + 0.5 ×TF ( t , d ) max t TF ( t , d ) \displaystyle{}0.5\text{+}\cfrac{0.5 \text{×}\text{TF}(t,d)}{\max _{\mathrm{t}}\text{TF}(t,d)} 0.5+maxtTF(t,d)0.5×TF(t,d) 映射词频到 0.5 →1 0.5\text{→1} 0.5→1,防止高频词权重过大 布尔 { 1 if TF ( t , d ) > 0 0 otherwise \begin{cases}1 \,\text{ if } \text{TF}(t,d)>0 \\0 \,\text{ otherwise }\end{cases} {1 if TF(t,d)>00 otherwise 不关注具体的词频值,仅表示是否出现 平均对数 1 + log ( TF ( t , d ) ) 1 + log ( a v e t ∈ d , ( TF ( t , d ) ) ) \cfrac{1+\log \left(\text{TF}(t,d)\right)}{1+\log \left(\mathrm{ave}_{\mathrm{t∈d}}, \left(\text{TF}(t,d)\right)\right)} 1+log(avet∈d,(TF(t,d)))1+log(TF(t,d)) 使词频高的词与低的词之间的差距不会过大 - 对文档频率 DF ( t ) \text{DF}(t) DF(t)的改进: N N N是文档总数
文档频率 DF ( t ) \text{DF}(t) DF(t) 公式 意义 逆文档频率 IDF ( t ) \text{IDF}(t) IDF(t) 即 log N DF ( t ) \log{}\cfrac{N}{\text{DF}(t)} logDF(t)N者 log N DF ( t ) +1 \log{}\cfrac{N}{\text{DF}(t)\text{+1}} logDF(t)+1N 衡量词在文档集合中的稀有性 概率文档频率 ProbDF( t ) \text{ProbDF(}t) ProbDF(t) max { 0 , log N − DF ( t ) DF ( t ) } \max\left\{0,\log\cfrac{N-\text{DF}(t)}{\text{DF}(t)}\right\} max{0,logDF(t)N−DF(t)} 通过概率角度评估词的稀有性 - 归一化:对于 TF-IDF = [ TF-IDF ( t 1 , d 1 ) TF-IDF ( t 1 , d 2 ) ⋯ TF-IDF ( t 1 , d n ) TF-IDF ( t 2 , d 1 ) TF-IDF ( t 2 , d 2 ) ⋯ TF-IDF ( t 2 , d n ) ⋮ ⋮ ⋱ ⋮ TF-IDF ( t m , d 1 ) TF-IDF ( t m , d 2 ) ⋯ TF-IDF ( t m , d n ) ] \textbf{TF-IDF}\text{=}\begin{bmatrix} \text{TF-IDF}(t_1,d_1) & \text{TF-IDF}(t_1,d_2) & \cdots & \text{TF-IDF}(t_1,d_n) \\ \text{TF-IDF}(t_2,d_1) & \text{TF-IDF}(t_2,d_2) & \cdots & \text{TF-IDF}(t_2,d_n) \\ \vdots & \vdots & \ddots & \vdots \\ \text{TF-IDF}(t_m,d_1) & \text{TF-IDF}(t_m,d_2) & \cdots & \text{TF-IDF}(t_m,d_n) \\ \end{bmatrix} TF-IDF= TF-IDF(t1,d1)TF-IDF(t2,d1)⋮TF-IDF(tm,d1)TF-IDF(t1,d2)TF-IDF(t2,d2)⋮TF-IDF(tm,d2)⋯⋯⋱⋯TF-IDF(t1,dn)TF-IDF(t2,dn)⋮TF-IDF(tm,dn)
归一类型 公式 意义 余弦归一 TF-IDF × 1 ∑ i = 1 m ∑ j = 1 n [ TF-IDF ( t i , d j ) ] 2 \textbf{TF-IDF}\text{×}\cfrac{1}{\displaystyle{}\sqrt{\sum_{i=1}^{m}\sum_{j=1}^{n}[\text{TF-IDF}(t_i,d_j)]^{2}}} TF-IDF×i=1∑mj=1∑n[TF-IDF(ti,dj)]21 用于计算文档间的余弦相似度 基准归一 TF-IDF × 1 m n \textbf{TF-IDF}\text{×}\cfrac{1}{mn} TF-IDF×mn1 消除文档集合大小对权重的影响 字长归一 TF-IDF × 1 (CharLen) α \textbf{TF-IDF}\text{×}\cfrac{1}{\text{(CharLen)}^{\alpha}} TF-IDF×(CharLen)α1 适用于不同长度的文档,且 α < 1 \alpha\text{<}1 α<1 3️⃣基于 TF-IDF \text{TF-IDF} TF-IDF的余弦相似度
- TF-IDF \text{TF-IDF} TF-IDF值:对于文档 d 1 d_1 d1和 d 2 d_2 d2,词汇表长为 m m m
- TF-IDF = [ TF-IDF ( t 1 , d 1 ) TF-IDF ( t 1 , d 2 ) TF-IDF ( t 2 , d 1 ) TF-IDF ( t 2 , d 2 ) ⋮ ⋮ TF-IDF ( t m , d 1 ) TF-IDF ( t m , d 2 ) ] → 余弦归一化 [ tf-idf ( t 1 , d 1 ) tf-idf ( t 1 , d 2 ) tf-idf ( t 2 , d 1 ) tf-idf ( t 2 , d 2 ) ⋮ ⋮ tf-idf ( t m , d 1 ) tf-idf ( t m , d 2 ) ] \small\textbf{TF-IDF}\text{=}\begin{bmatrix} \text{TF-IDF}(t_1,d_1)&\text{TF-IDF}(t_1,d_2)\\ \text{TF-IDF}(t_2,d_1)&\text{TF-IDF}(t_2,d_2)\\ \vdots & \vdots \\ \text{TF-IDF}(t_m,d_1) & \text{TF-IDF}(t_m,d_2)\\ \end{bmatrix}\xrightarrow{余弦归一化}\begin{bmatrix} \text{tf-idf}(t_1,d_1)&\text{tf-idf}(t_1,d_2)\\ \text{tf-idf}(t_2,d_1)&\text{tf-idf}(t_2,d_2)\\ \vdots & \vdots \\ \text{tf-idf}(t_m,d_1) & \text{tf-idf}(t_m,d_2)\\ \end{bmatrix} TF-IDF= TF-IDF(t1,d1)TF-IDF(t2,d1)⋮TF-IDF(tm,d1)TF-IDF(t1,d2)TF-IDF(t2,d2)⋮TF-IDF(tm,d2) 余弦归一化 tf-idf(t1,d1)tf-idf(t2,d1)⋮tf-idf(tm,d1)tf-idf(t1,d2)tf-idf(t2,d2)⋮tf-idf(tm,d2)
- 两文档余弦值:
- 未归一化表示: sim ( d 1 , d 2 ) = ∑ j = 1 m TF-IDF ( t j , d 1 ) ⋅ TF-IDF ( t j , d 2 ) ∑ j = 1 m ( TF-IDF ( t j , d 1 ) ) 2 ⋅ ∑ j = 1 m ( TF-IDF ( t j , d 2 ) ) 2 \text{sim}(d_1, d_2) = \cfrac{\displaystyle{}\sum_{j=1}^m \text{TF-IDF}(t_j, d_1) \cdot \text{TF-IDF}(t_j, d_2)}{\displaystyle{}\sqrt{\sum_{j=1}^m (\text{TF-IDF}(t_j, d_1))^2} \cdot \sqrt{\sum_{j=1}^m (\text{TF-IDF}(t_j, d_2))^2}} sim(d1,d2)=j=1∑m(TF-IDF(tj,d1))2⋅j=1∑m(TF-IDF(tj,d2))2j=1∑mTF-IDF(tj,d1)⋅TF-IDF(tj,d2)
- 归一化表示 : sim ( d 1 , d 2 ) = ∑ j = 1 m tf-idf ( t j , d 1 ) ⋅ tf-idf ( t j , d 2 ) \displaystyle{}\text{sim}(d_1, d_2) = \sum_{j=1}^m \text{tf-idf}(t_j, d_1) \cdot \text{tf-idf}(t_j, d_2) sim(d1,d2)=j=1∑mtf-idf(tj,d1)⋅tf-idf(tj,d2)
5 \textbf{5 } 5 主题语言模型
5.0. \textbf{5.0. } 5.0. 概述
1️⃣分布模型: Doc. → 非监督学习 ( 聚类 ) 主题分布 { Topic 1 ( P T 1 ) → 非监督学习 ( 聚类 ) 词语分布 { Word 11 ( P W 11 ) Word 12 ( P W 11 ) ⋮ Word 1 m ( P W 1 m ) Topic 2 ( P T 2 ) → 非监督学习 ( 聚类 ) 词语分布 { Word 21 ( P W 21 ) Word 22 ( P W 21 ) ⋮ Word 2 m ( P W 2 m ) ⋮ Topic n ( P T n ) → 非监督学习 ( 聚类 ) 词语分布 { Word n 1 ( P W n 1 ) Word n 2 ( P W n 1 ) ⋮ Word n m ( P W n m ) \text{Doc.}\xrightarrow[非监督学习(聚类)]{主题分布} \begin{cases} \textbf{Topic 1}(P_{T_1})\xrightarrow[非监督学习(聚类)]{词语分布} \begin{cases} \text{Word}_{11}(P_{W_{11}})\\ \text{Word}_{12}(P_{W_{11}})\\ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\vdots \\ \text{Word}_{1m}(P_{W_{1m}})\\ \end{cases} \\ \textbf{Topic 2}(P_{T_2})\xrightarrow[非监督学习(聚类)]{词语分布} \begin{cases} \text{Word}_{21}(P_{W_{21}})\\ \text{Word}_{22}(P_{W_{21}})\\ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\vdots \\ \text{Word}_{2m}(P_{W_{2m}})\\ \end{cases} \\ \,\,\,\,\,\,\,\,\,\,\,\,\,\vdots \\ \textbf{Topic n}(P_{T_n})\xrightarrow[非监督学习(聚类)]{词语分布} \begin{cases} \text{Word}_{n1}(P_{W_{n1}})\\ \text{Word}_{n2}(P_{W_{n1}})\\ \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\vdots \\ \text{Word}_{nm}(P_{W_{nm}})\\ \end{cases} \end{cases} Doc.主题分布非监督学习(聚类)⎩ ⎨ ⎧Topic 1(PT1)词语分布非监督学习(聚类)⎩ ⎨ ⎧Word11(PW11)Word12(PW11)⋮Word1m(PW1m)Topic 2(PT2)词语分布非监督学习(聚类)⎩ ⎨ ⎧Word21(PW21)Word22(PW21)⋮Word2m(PW2m)⋮Topic n(PTn)词语分布非监督学习(聚类)⎩ ⎨ ⎧Wordn1(PWn1)Wordn2(PWn1)⋮Wordnm(PWnm)
- 主题分布:每篇文档由若干主题按一定比例构成
- 词语分布:每个主题包含一组特定的词语,每个词具有不同的出现概率
2️⃣概率模型
- 公式: p ( w ∣ D o c ) = ∑ i = 1 n p ( w ∣ T i ) ⋅ p ( T i ∣ D o c ) \displaystyle{}p(w | \mathrm{Doc})=\sum_{i=1}^n p\left(w | T_i\right) \cdot p\left(T_i | \mathrm{Doc}\right) p(w∣Doc)=i=1∑np(w∣Ti)⋅p(Ti∣Doc)
- 含义:将文档的内容视为不同主题的组合 → \to →由每主题的词语概率预测文档中词语的分布
5.1. \textbf{5.1. } 5.1. 基于矩阵分解的模型
5.1.1. LSA(SVD) \textbf{5.1.1. LSA(SVD)} 5.1.1. LSA(SVD)模型
1️⃣奇异值分解
- 含义:对任意 A m × n A_{m\text{×}n} Am×n可将其分解为三个矩阵 A m × n = U m × m Σ m × n V n × n T A_{m\text{×}n}\text{=}U_{m\text{×}m}\Sigma_{m\text{×}n}V_{n\text{×}n}^{T}\text{} Am×n=Um×mΣm×nVn×nT
矩阵类型 描述 左奇异矩阵 U m × m U_{m\text{×}m} Um×m 为正交矩阵即 U m × m U m × m T = I m × m U_{m\text{×}m}U_{m\text{×}m}^{T}\text{=}I_{m\text{×}m} Um×mUm×mT=Im×m 奇异值矩阵 Σ m × n \Sigma_{m\text{×}n} Σm×n 为对角矩阵(对角为是奇异值),如 [ α 1 0 0 ⋯ 0 ⋯ 0 0 α 2 0 ⋯ 0 ⋯ 0 0 0 α 3 ⋯ 0 ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 ⋯ α m ⋯ 0 ] m × n \small\begin{bmatrix}\alpha_1 & 0 & 0 & \cdots & 0& \cdots & 0 \\0 & \alpha_2 & 0 & \cdots & 0& \cdots & 0 \\0 & 0 & \alpha_3 & \cdots & 0& \cdots & 0 \\\vdots & \vdots & \vdots & \ddots & \vdots & &\vdots\\0 & 0 & 0 & \cdots & \alpha_m& \cdots & 0 \\\end{bmatrix}_{m \text{×} n} α100⋮00α20⋮000α3⋮0⋯⋯⋯⋱⋯000⋮αm⋯⋯⋯⋯000⋮0 m×n 右奇异矩阵 V n × n V_{n\text{×}n} Vn×n 为正交矩阵即 V n × n V n × n T = I n × n V_{n\text{×}n}V_{n\text{×}n}^{T}\text{=}I_{n\text{×}n} Vn×nVn×nT=In×n - Eckart–Young–Mirsky \text{Eckart–Young–Mirsky} Eckart–Young–Mirsky定理: A k = U k Σ k V k T A_k=U_k \Sigma_k V_k^T Ak=UkΣkVkT奇异值的截断
- U k U_k Uk 和 V k V_k Vk 分别是 U U U 和 V V V 的前 k k k 列
- Σ k \Sigma_k Σk 是奇异值矩阵 Σ \Sigma Σ 中前 k k k 个最大的奇异值组成的 k × k k\text{×}k k×k 子矩阵
2️⃣ LSA \text{LSA} LSA模型步骤:原始 Word-Doc \text{Word-Doc} Word-Doc矩阵 → 近似 奇异分解 \xrightarrow[近似]{奇异分解} 奇异分解近似其近似的低阶矩阵
- Word-Doc \text{Word-Doc} Word-Doc矩阵:
- A t × d = [ Doc 1 → Word 11 Doc 2 → Word 12 ⋯ Doc n → Word 1 d Doc 1 → Word 21 Doc 2 → Word 22 ⋯ Doc n → Word 2 d ⋮ ⋮ ⋱ ⋮ Doc 1 → Word t 1 Doc 2 → Word t 2 ⋯ Doc n → Word t d ] A_{t \text{×} d} = \begin{bmatrix} \text{Doc}_1 \text{→} \text{Word}_{11} & \text{Doc}_2 \text{→} \text{Word}_{12} & \cdots & \text{Doc}_n \text{→} \text{Word}_{1d} \\ \text{Doc}_1 \text{→} \text{Word}_{21} & \text{Doc}_2 \text{→} \text{Word}_{22} & \cdots & \text{Doc}_n \text{→} \text{Word}_{2d} \\ \vdots & \vdots & \ddots & \vdots \\ \text{Doc}_1 \text{→} \text{Word}_{t1} & \text{Doc}_2 \text{→} \text{Word}_{t2} & \cdots & \text{Doc}_n \text{→} \text{Word}_{td} \\ \end{bmatrix} At×d= Doc1→Word11Doc1→Word21⋮Doc1→Wordt1Doc2→Word12Doc2→Word22⋮Doc2→Wordt2⋯⋯⋱⋯Docn→Word1dDocn→Word2d⋮Docn→Wordtd
- Doc i →Word i j \text{Doc}_i\text{→Word}_{ij} Doci→Wordij可为词 Word i j \text{Word}_{ij} Wordij的词频或者 TF-IDF \text{TF-IDF} TF-IDF值
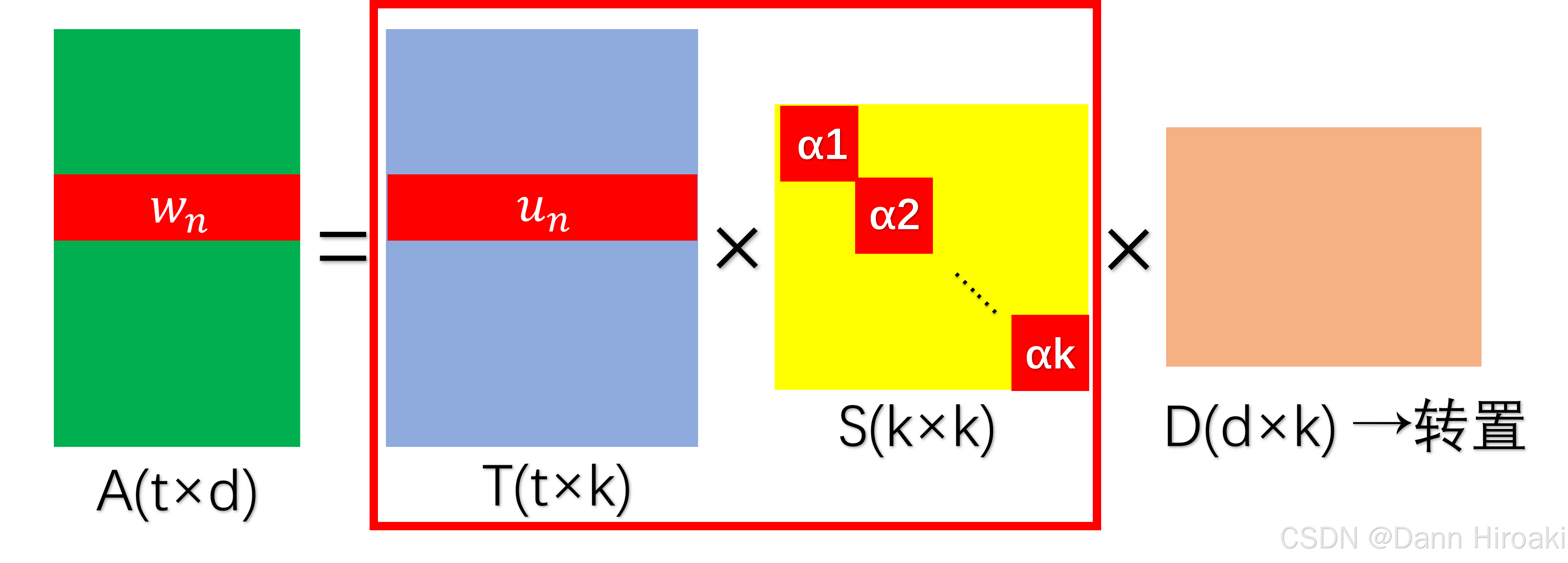
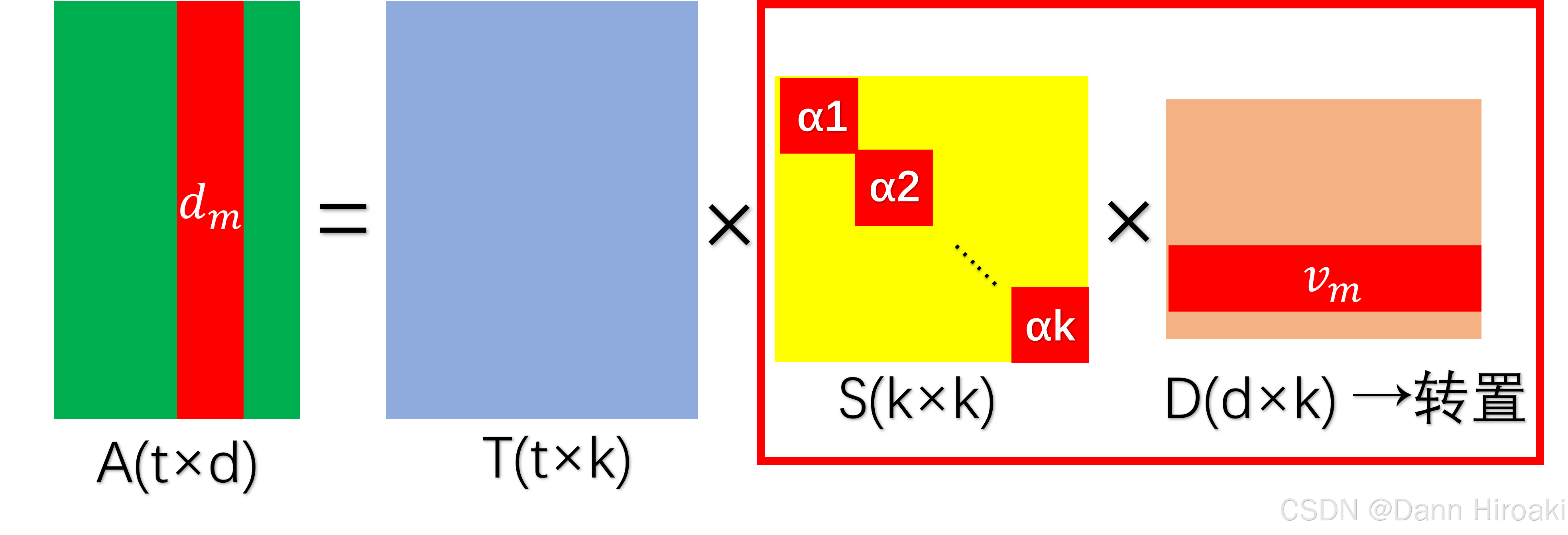
- A t × d A_{t\text{×}d} At×d奇异分解: A t × d = T t × n S n × n D d × n T A_{t\text{×}d}\text{=}T_{t\text{×}n}S_{n\text{×}n}D_{d\text{×}n}^{T}\text{} At×d=Tt×nSn×nDd×nT
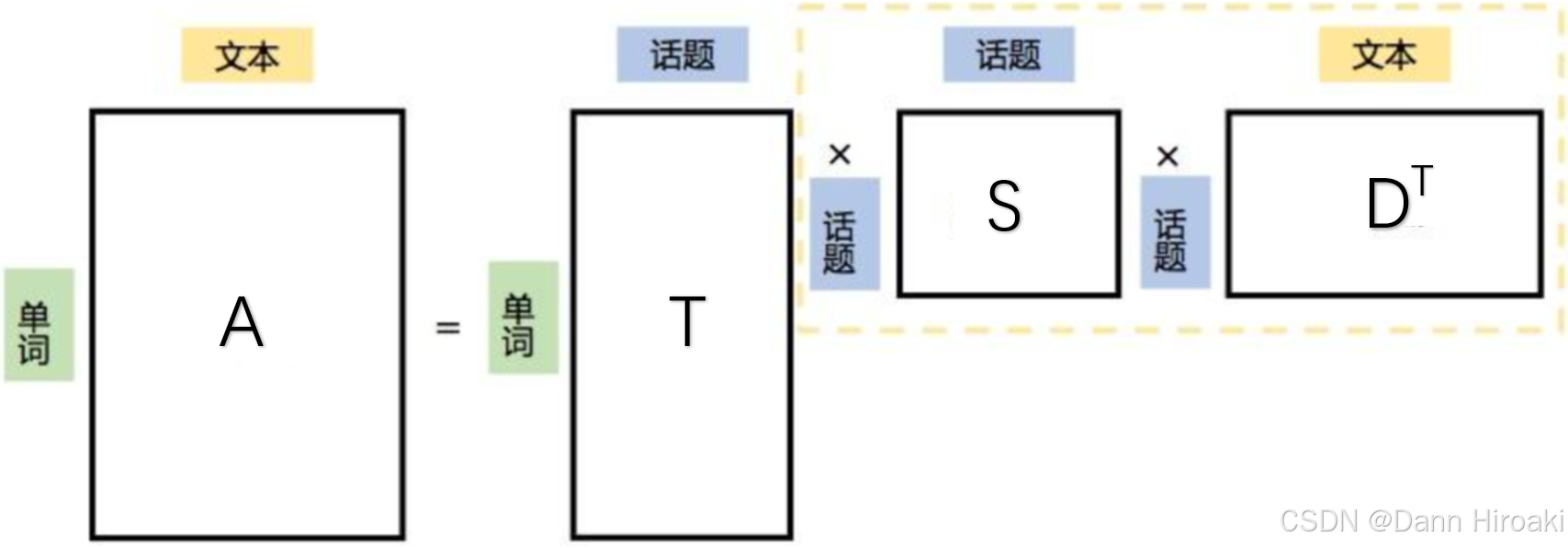
矩阵类型 描述 S n × n S_{n\text{×}n} Sn×n 奇异值按降序排列,代表重要的潜在语义的强度 T t × n T_{t\text{×}n} Tt×n 词汇矩阵,每列蕴含一个隐含概念(主题) D d × n D_{d\text{×}n} Dd×n 文档矩阵,每列蕴含一个隐含概念(主题) - 低秩近似: A → A k A\text{→}A_k A→Ak
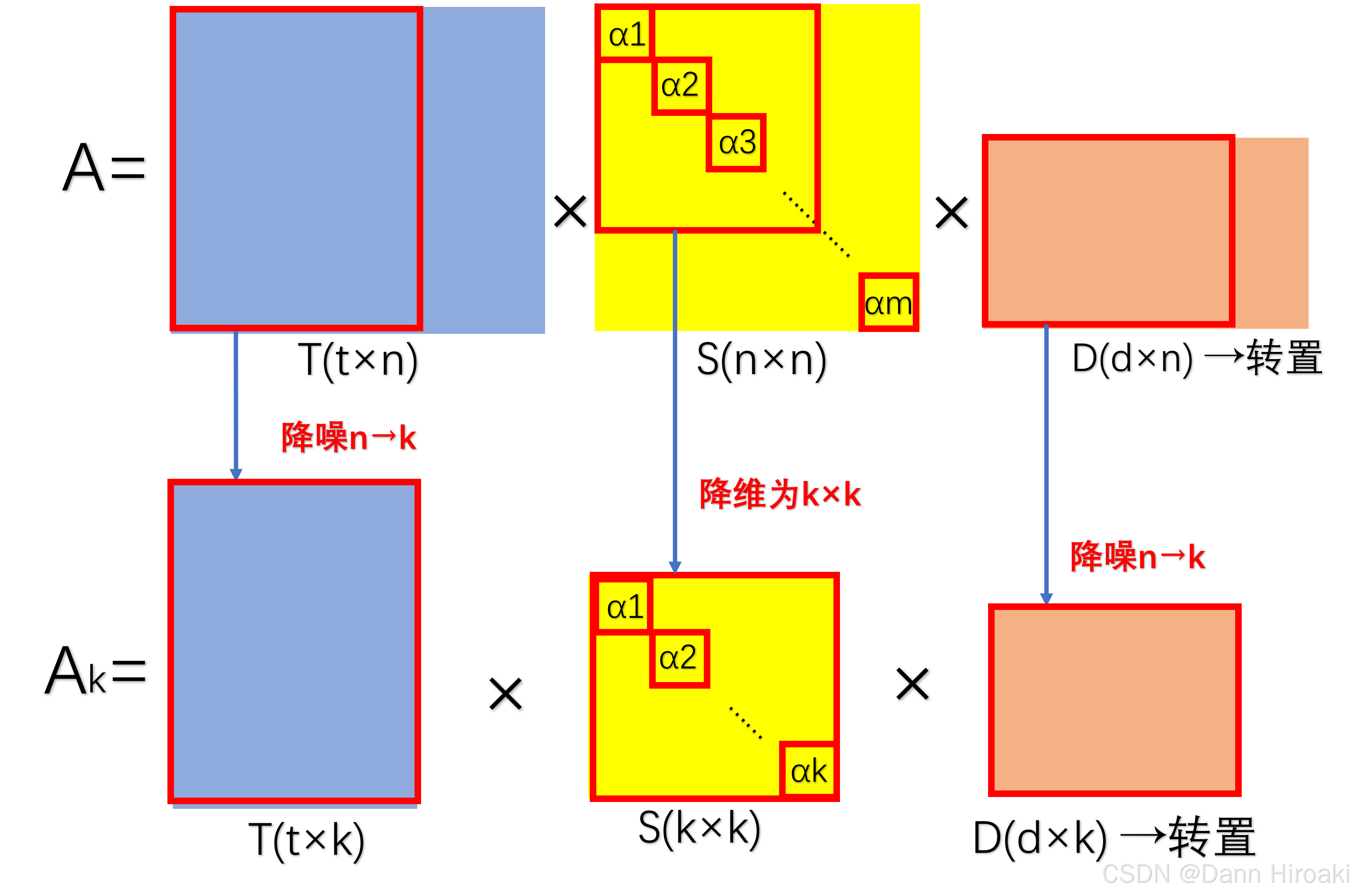
- 降维: S n × n → 只保留前 k 个最大的奇异值 S k × k S_{n\text{×}n}\xrightarrow{只保留前k个最大的奇异值}S_{k\text{×}k} Sn×n只保留前k个最大的奇异值Sk×k,其中 k k k又称为预期主题数
- 降噪: A t × d = T t × n S n × n D d × n T → S n × n 降维 A t × d = T t × k S k × k D d × k T A_{t\text{×}d}\text{=}T_{t\text{×}n}S_{n\text{×}n}D_{d\text{×}n}^{T}\text{}\xrightarrow{S_{n\text{×}n}降维}A_{t\text{×}d}\text{=}T_{t\text{×}k}S_{k\text{×}k}D_{d\text{×}k}^{T}\text{} At×d=Tt×nSn×nDd×nTSn×n降维At×d=Tt×kSk×kDd×kT,滤掉不重要的主题
3️⃣文档与词汇的表示
- 词汇: T t × k S k × k T_{t\text{×}k}S_{k\text{×}k} Tt×kSk×k的行向量,且 w ^ n = u n × S \hat{w}_n=u_n\text{×}\textbf{S} w^n=un×S
- 文档: D d × k S k × k D_{d\text{×}k}S_{k\text{×}k} Dd×kSk×k的行向量( S k × k D d × k T S_{k\text{×}k}D_{d\text{×}k}^T Sk×kDd×kT的列向量),且 d ^ m = S × v m T \hat{d}_m\text{=}\textbf{S}\text{×}v_{m}^{T} d^m=S×vmT
5.1.2. MNF \textbf{5.1.2. MNF} 5.1.2. MNF建模
1️⃣建模过程
- 对 V \textbf{V} V寻找非负矩阵 HW \textbf{HW} HW使 V ≈ WH \textbf{V}\text{≈}\textbf{WH} V≈WH
- 使得代价函数 ∥ V − W H ∥ = ∑ i , j ( V i , j − ( W H ) i , j ) 2 \displaystyle{}\|V-W H\|\text{=}\sqrt{\sum_{i, j}\left(V_{i, j}-(W H)_{i, j}\right)^2} ∥V−WH∥=i,j∑(Vi,j−(WH)i,j)2 尽可能小
2️⃣建模的意义
- 非负:使分解结果更有意义
- 示例:文档-单词 → NMF \xrightarrow{\text{NMF}} NMF文档-主题 × \text{×} ×主题-单词
5.2. \textbf{5.2. } 5.2. 基于概率的模型
5.2.0. \textbf{5.2.0. } 5.2.0. 概率模型概述
1️⃣符号:其中 K K K为话题数, K ≪ M K\text{≪}M K≪M且为预先定义的超参数
集合 含义 随机变量 文本集 D = { d 1 , d 2 , . . . d N } D\text{=}\{d_1,d_2,...d_N\} D={d1,d2,...dN} 包含所有文本, N N N为文本总数 d d d(观测变量) 话题集 Z = { z 1 , z 2 , . . . z K } Z\text{=}\{z_1,z_2,...z_K\} Z={z1,z2,...zK} 包含所有可能的话题, K K K为预设话题总数 z z z(隐藏变量) 词汇集 W = { w 1 , w 2 , . . . w M } W\text{=}\{w_1,w_2,...w_M\} W={w1,w2,...wM} 所有可能的单词, M M M为单词总数 w w w(观测变量) 2️⃣三类分布: P ( d ) P(d) P(d)为可观测参数,如何估计 P ( z ∣ d ) P(z|d) P(z∣d)和 P ( w ∣ z ) P(w|z) P(w∣z)两参数派生了 pLAS \text{pLAS} pLAS和 LDA \text{LDA} LDA方法
分布 表示 含义 文档分布 P ( d ) ∼ P(d)\sim{} P(d)∼多项分布 生成文本 d d d的概率 主题分布 P ( z ∣ d ) ∼ P(z\mid{}d)\sim{} P(z∣d)∼多项分布 文本 d d d生成话题 z z z的概率,每个文本都有其主题分布 单词分布 P ( w ∣ z ) ∼ P(w\mid{}z)\sim{} P(w∣z)∼多项分布 话题 z z z生成单词 w w w的概率,每个主题都有其单词分布 3️⃣观测表征
- 观测数据:文本-单词共现矩阵,其中 n ( n( n(单词 i , i, i, 文本 j ) j) j)表示单词 i i i在文本 j j j中出现的次数
共现矩阵 T T T 文 d 1 d_1 d1 文 d 2 d_2 d2 ... \text{...} ... 文 d N d_N dN 词 w 1 w_1 w1 n ( n( n(词 w 1 , w_1, w1, 文 d 1 ) d_1) d1) n ( n( n(词 w 1 , w_1, w1, 文 d 2 ) d_2) d2) ... \text{...} ... n ( n( n(词 w 1 , w_1, w1, 文 d N ) d_N) dN) 词 w 2 w_2 w2 n ( n( n(词 w 2 , w_2, w2, 文 d 1 ) d_1) d1) n ( n( n(词 w 2 , w_2, w2, 文 d 2 ) d_2) d2) ... \text{...} ... n ( n( n(词 w 2 , w_2, w2, 文 d N ) d_N) dN) ... \text{...} ... ... \text{...} ... ... \text{...} ... ... \text{...} ... 词 w M w_M wM n ( n( n(词 w M , w_M, wM, 文 d 1 ) d_1) d1) n ( n( n(词 w M , w_M, wM, 文 d 2 ) d_2) d2) ... \text{...} ... n ( n( n(词 w M , w_M, wM, 文 d N ) d_N) dN) - 生成概率:假设每个单词分布独立,则有 P ( T ) = ∏ ( w , d ) P ( w , d ) n ( w , d ) \displaystyle{}P(T)\text{=}\prod_{(w, d)} P(w, d)^{n(w, d)} P(T)=(w,d)∏P(w,d)n(w,d)
4️⃣ LDA \text{LDA} LDA与 pLSA \text{pLSA} pLSA
模型 思想 对于两 P ( z ∣ d ) P(z\mid{}d) P(z∣d)和 P ( w ∣ z ) P(w\mid{}z) P(w∣z)待估参数 pLSA \text{pLSA} pLSA 频率学 视作固定值(即均匀分布),用最大似然估计解出来 LDA \text{LDA} LDA 贝叶斯 视作服从 Dirichlet \text{Dirichlet} Dirichlet分布的随机变量,先验分布 → 修正 \xrightarrow{修正} 修正最终分布 5.2.1 pLSA \textbf{5.2.1 pLSA} 5.2.1 pLSA模型
1️⃣生成模型:
- 定义:对生成概率 P ( w , d ) = P ( d ) ∑ z P ( z ∣ d ) P ( w ∣ z ) \displaystyle{}P(w, d)\text{=}P(d) \sum_z P(z | d) P(w | z) P(w,d)=P(d)z∑P(z∣d)P(w∣z)形式的拆解
- 概率依赖:文本 → \text{→} →话题 → \text{→} →单词
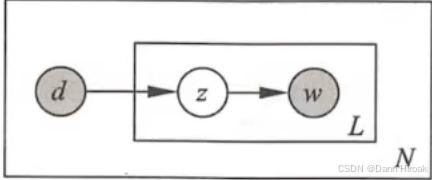
选择 描述 备注 文本 从 D D D中,按 P ( d ) P(d) P(d)选择文本 d → 重复 N 次 d\xrightarrow{重复N次} d重复N次生成 N N N个文本 N N N为文本数量 话题 对每个文本,按 P ( z ∣ d ) P(z\mid{}d) P(z∣d)选择话题 z → 重复 L 次 z\xrightarrow{重复L次} z重复L次生成 L L L个话题 L L L为文本(定/变)长 单词 对每个话题,按 P ( w ∣ z ) P(w\mid{}z) P(w∣z)选择一单词 N/A \text{N/A} N/A 2️⃣共现模型:
- 定义:对生成概率 P ( w , d ) = ∑ z ∈ Z P ( z ) P ( w ∣ z ) P ( d ∣ z ) \displaystyle{}P(w, d)\text{=}\sum_{z \text{∈} Z} P(z) P(w | z) P(d | z) P(w,d)=z∈Z∑P(z)P(w∣z)P(d∣z)形式的拆解
- 概率依赖:话题 → \text{→} →单词,话题 → \text{→} →文本
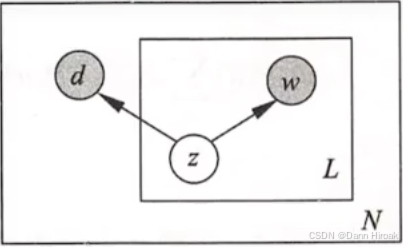
选择 描述 备注 话题 从 Z Z Z中,按 P ( z ) P(z) P(z)选择话题 z → 重复 L 次 z\xrightarrow{重复L次} z重复L次生成 L L L个话题 L L L为文本(定/变)长 单词 对每个话题,按 P ( w ∣ z ) P(w\mid{}z) P(w∣z)选择一单词 单词/文本的选择独立 文本 从 D D D中,按 P ( d ∣ z ) P(d\mid{}z) P(d∣z)选择文本 d → 重复 N 次 d\xrightarrow{重复N次} d重复N次生成 N N N个文本 N N N为文本数量 5.2.2. LDA \textbf{5.2.2. LDA} 5.2.2. LDA模型简述
💢别看 PPT \text{PPT} PPT了那就是一坨屎,以下内容来自维基百科
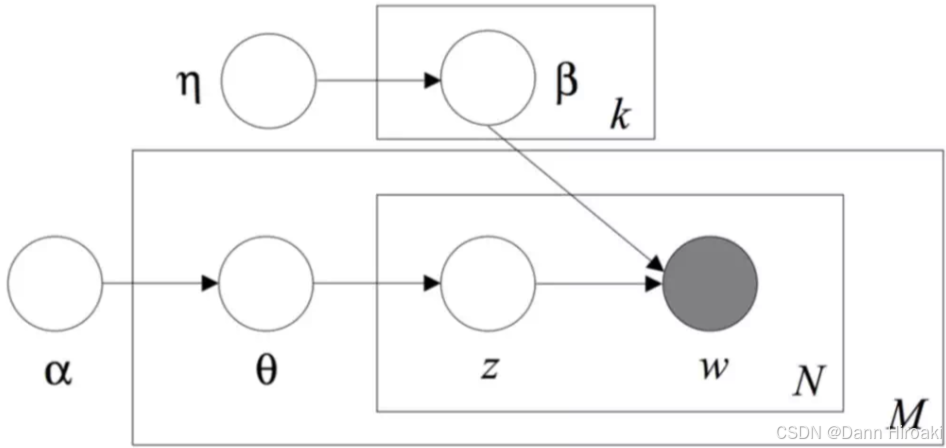
1️⃣ LDA \text{LDA} LDA模型要素
- 三种分布:
分布 维度 元素 隐藏/观测 主题分布 Θ \Theta Θ 文档数 × \text{×} ×主题数 θ i , j \theta_{i,j} θi,j为文档 i i i中主题 j j j的比例 隐藏 词汇分布 β \beta β 主题数 × \text{×} ×词汇数 β i , j \beta_{i,j} βi,j为主题 i i i中词汇 j j j的频次 隐藏 主题分布 w \text{w} w 文档数 × \text{×} ×词汇数 w i , j \text{w}_{i,j} wi,j为文档 i i i中词汇 j j j的频次 观测 - 两种超参数:
超参数 描述 功能 α \alpha α 文档集级参数, Dirichlet \text{Dirichlet} Dirichlet分布参数 生成文档的主题 Θ \Theta Θ η \eta η 文档集级参数, Dirichlet \text{Dirichlet} Dirichlet分布参数 生成每个主题的 β \beta β 2️⃣ LDA \text{LDA} LDA的生成:分布 p ( w i , z i , θ i , Φ ∣ α , β ) = ∏ j = 1 N p ( θ i ∣ α ) p ( z i , j ∣ θ i ) p ( Φ ∣ β ) p ( w i , j ∣ ϕ z i , j ) \displaystyle{}p\left(w_i, z_i, \theta_i, \Phi \mid \alpha, \beta\right)=\prod_{j=1}^N p\left(\theta_i \mid \alpha\right) p\left(z_{i, j} \mid \theta_i\right) p(\Phi \mid \beta) p\left(w_{i, j} \mid \phi_{z_{i, j}}\right) p(wi,zi,θi,Φ∣α,β)=j=1∏Np(θi∣α)p(zi,j∣θi)p(Φ∣β)p(wi,j∣ϕzi,j)
- 第一部分:
- 从先验 Dirichlet \text{Dirichlet} Dirichlet分布 α \alpha α中抽样 → \text{→} →生成某一文档 i i i的主题(多项式)分布 θ i \theta_i θi
- 从 θ i \theta_i θi分布中抽样 → \text{→} →生成某一文档 i i i的某一主题 z i , j z_{i,j} zi,j
- 第二部分:
- 从先验 Dirichlet \text{Dirichlet} Dirichlet分布 η \eta η中抽样 → \text{→} →生成主题 z i , j z_{i,j} zi,j的词语分布 β z i , j \beta_{z_{i,j}} βzi,j
- 从 β z i , j \beta_{z_{i,j}} βzi,j分布中抽样 → \text{→} →生成词语 w i , j w_{i,j} wi,j
4️⃣ LDA \text{LDA} LDA的求解(训练):我也不信考试会考这 B \text{B} B玩意儿
- EM \text{EM} EM算法( Old-Fashioned \text{Old-Fashioned} Old-Fashioned)
- Gibbs \text{Gibbs} Gibbs采, MCMC(Markov Chain Monte Carlo) \text{MCMC(Markov Chain Monte Carlo)} MCMC(Markov Chain Monte Carlo)算法
5.2.3. \textbf{5.2.3. } 5.2.3. 番外: pLSA \textbf{pLSA} pLSA的 EM \textbf{EM} EM求解
0️⃣总体思路
- 极大似然估计:找到时 P ( T ) P(T) P(T)最大的参数
- EM \text{EM} EM算法:直接最大化对数似然函数非常困难,从而通过 EM \text{EM} EM迭代的方式实现
1️⃣极大似然函数
- 似然函数推导
- 给定共现数据 T = { n ( w i , d j ) } → \textbf{T}=\{n(w_i,d_j)\}\text{→} T={n(wi,dj)}→要让 P ( T ) = ∏ i , j P ( w i , d j ) n ( w i , d j ) \displaystyle{}P(T)\text{=}\prod_{i,j}P(w_i,d_j)^{n(w_i,d_j)} P(T)=i,j∏P(wi,dj)n(wi,dj)最大
- 取对数 + + +引入隐含变量:
log P ( T ) = ∑ i = 1 M ∑ j = 1 N n ( w i , d j ) × log P ( w i , d j ) ⇓ 引入隐含变量: p ( d j ) ∑ z p ( z k ∣ d j ) p ( w i ∣ z k ) log P ( T ) = ∑ i = 1 M ∑ j = 1 N ( n ( w i , d j ) × ( log p ( d j ) + log ( ∑ z p ( z k ∣ d j ) p ( w i ∣ z k ) ) ) ) \begin{aligned} &\displaystyle{}\log{P(T)}\text{=}\sum_{i=1}^{M}\sum_{j=1}^{N}n(w_i,d_j)\text{×}\log{P(w_i,d_j)}&\\ & \Bigg\Downarrow {\\引入隐含变量\text{: }\small\displaystyle{}p\left(d_j\right) \sum_z p\left(z_k | d_j\right) p\left(w_i | z_k\right)\\} &\\ &\displaystyle{}\log{P(T)}\text{=}\sum_{i=1}^{M}\sum_{j=1}^{N}\left(n(w_i,d_j)\text{×}\left( \log{p(d_j)} \text{+} \log\left(\sum_z p(z_k | d_j) p(w_i | z_k)\right) \right)\right) & \end{aligned} logP(T)=i=1∑Mj=1∑Nn(wi,dj)×logP(wi,dj)⇓ ‖引入隐含变量: p(dj)z∑p(zk∣dj)p(wi∣zk)logP(T)=i=1∑Mj=1∑N(n(wi,dj)×(logp(dj)+log(z∑p(zk∣dj)p(wi∣zk))))- 似然函数分析:
- 已知值: n ( w i , d j ) n(w_i,d_j) n(wi,dj)在 T \textbf{T} T向量中就有之, p ( d j ) p(d_j) p(dj)可由真实大量文本集得到
- 参数值: log ( ∑ z p ( z k ∣ d j ) p ( w i ∣ z k ) ) \displaystyle{}\log\left(\sum_z p(z_k | d_j) p(w_i | z_k)\right) log(z∑p(zk∣dj)p(wi∣zk)),其中 log ∑ \displaystyle{}\log\sum log∑形式适合用 EM \text{EM} EM算法解决
2️⃣极大似然函数的下界
- Jensen \text{Jensen} Jensen不等式
情况 E ( f ( x ) ) E(f(x)) E(f(x))与 f ( E ( x ) ) f(E(x)) f(E(x)) f ( x ) f(x) f(x)为凸函数 E ( f ( x ) ) ≥ f ( E ( x ) ) E(f(x))\geq{}f(E(x)) E(f(x))≥f(E(x)) f ( x ) f(x) f(x)为凹函数 E ( f ( x ) ) ≤ f ( E ( x ) ) E(f(x))\leq{}f(E(x)) E(f(x))≤f(E(x)) x = C x\text{=}C x=C E ( f ( x ) ) = f ( E ( x ) ) E(f(x))=f(E(x)) E(f(x))=f(E(x)) - log ( ∑ z p ( z k ∣ d j ) p ( w i ∣ z k ) ) \displaystyle{}\log\left(\sum_z p(z_k | d_j) p(w_i | z_k)\right) log(z∑p(zk∣dj)p(wi∣zk))的处理:构建方差 + + +应用 Jensen \text{Jensen} Jensen不等式
- ∑ z p ( z k ∣ d j ) p ( w i ∣ z k ) → z 的分布 Q ( z ) ∑ z Q ( z ) p ( z k ∣ d j ) p ( w i ∣ z k ) Q ( z ) → X = p ( z k ∣ d j ) p ( w i ∣ z k ) Q ( z ) E ( X ) \displaystyle{}\sum_z p(z_k | d_j) p(w_i | z_k)\xrightarrow{z的分布Q(z)}\sum_z {Q(z)}\cfrac{p(z_k | d_j) p(w_i | z_k)}{Q(z)}\xrightarrow{\small{}X\text{=}\cfrac{p(z_k | d_j) p(w_i | z_k)}{Q(z)}}E(X) z∑p(zk∣dj)p(wi∣zk)z的分布Q(z)z∑Q(z)Q(z)p(zk∣dj)p(wi∣zk)X=Q(z)p(zk∣dj)p(wi∣zk)E(X)
- 原式 = log ( E ( X ) ) → Jensen不等式 log ( x ) 为凹函数 ≥ E ( log ( X ) ) = ∑ z ( log p ( z k ∣ d j ) p ( w i ∣ z k ) Q ( z ) ) Q ( z ) \text{=}\log(E(X))\xrightarrow[\text{Jensen不等式}]{\log(x)为凹函数}\text{≥}E(\log(X))\text{=}\displaystyle{}\sum_z\left(\log{}\cfrac{p(z_k | d_j) p(w_i | z_k)}{Q(z)}\right)Q(z) =log(E(X))log(x)为凹函数Jensen不等式≥E(log(X))=z∑(logQ(z)p(zk∣dj)p(wi∣zk))Q(z)
- 下界与极大似然:提升下界 ∑ z ( log p ( z k ∣ d j ) p ( w i ∣ z k ) Q ( z ) ) Q ( z ) \displaystyle{}\sum_z\left(\log{}\cfrac{p(z_k | d_j) p(w_i | z_k)}{Q(z)}\right)Q(z) z∑(logQ(z)p(zk∣dj)p(wi∣zk))Q(z)的最大值 → \text{→} →最大化似然函数
3️⃣ EM \text{EM} EM算法:详细步骤就不写了,我不信考试会考这 B \text{B} B玩意儿
- E \text{E} E步:确定 Q Q Q函数 → \text{→} →表示当前参数估计下完全数据(观测数据 + + +隐含变量)的对数似然的期望
- 此处 Q = Q ( z ) = p ( z k ∣ w i , d j ) Q\text{=}Q(z)\text{=}p(z_k|w_i,d_j) Q=Q(z)=p(zk∣wi,dj)
- M \text{M} M步:迭代 Q Q Q函数,不断更新参数 → \to →使当前参数估计靠近最优值
- 此处需要更新的参数为文档-主题分布 P ( z ∣ d ) P(z|d) P(z∣d),主题-词汇分布 P ( w ∣ z ) P(w|z) P(w∣z)
- 最终使 ∑ z ( log p ( z k ∣ d j ) p ( w i ∣ z k ) Q ( z ) ) Q ( z ) \displaystyle{}\sum_z\left(\log{}\cfrac{p(z_k | d_j) p(w_i | z_k)}{Q(z)}\right)Q(z) z∑(logQ(z)p(zk∣dj)p(wi∣zk))Q(z)最大,从而使 P ( T ) P(T) P(T)最大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









