






声明:本笔记全部图片均来自B站UP主二次元的Datawhale,视频链接:【【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集】https://www.bilibili.com/video/BV1Mh411e7VU?p=3&vd_source=75bd1e93279e61f02a4580ce77d01f4b
决策树现在主要应用在集成学习(西瓜书第八章)里,用多颗决策树构成随机森林模型。西瓜书此章节非常详细(4.1、4.2),因此我们今天主要学习所用理论并认识下以下三类决策树。
一、算法原理
逻辑上讲,决策树是非常符合普通思维(直觉)的一种模型,核心就是选择判断条件。

几何上讲就是划分特征空间,核心是找阈值并用算法量化。

二、ID3决策树
首先我们来了解信息论中的几个概念:
信息熵就是自信息的期望,用来度量随机变量X的不确定性,之前已经学习过

可以用其所代表的不确定性来理解集合内样本的纯度

条件熵就是在已知一个标记的划分后另一个标记的不确定性,可以用来我们对特征空间进行划分后再研究子集的划分阈值

故我们可以用纯度的提升去考量算法的优劣,也就是利用信息增益,ID3决策树就是以信息增益为准则来选择划分属性的决策树。在实际第一次迭代中我们可以先遍历特征空间中的每一种特征,再看信息增益的大小,从而选出最优的划分方式。

三、C4.5决策树
ID3决策树模型在某种属性取值数目明显超出其他属性时可能存在漏洞,即那个取值里所包含的样本数量太少时存在偶然性,或者说不具备代表性,会发生过拟合。因此我们用某个特征划分的信息熵来限制下信息增益,即通过信息增益率来判断模型的好坏,这样就出现了C4.5决策树的雏形,实际上就是ID3决策树的改进。不过这样就出现了新的问题,可取值数目多信息熵一般会增大,所以增益率又对可取值数目少的特征有所偏好。

因此,C4.5决策树是先通过信息增益得到一些高于平均水平的属性,然后再选择这里面增益率最高的那一个,当然,实际操作时可根据直觉灵活应用。

四、CART决策树(二叉树)
利用基尼值来度量纯度
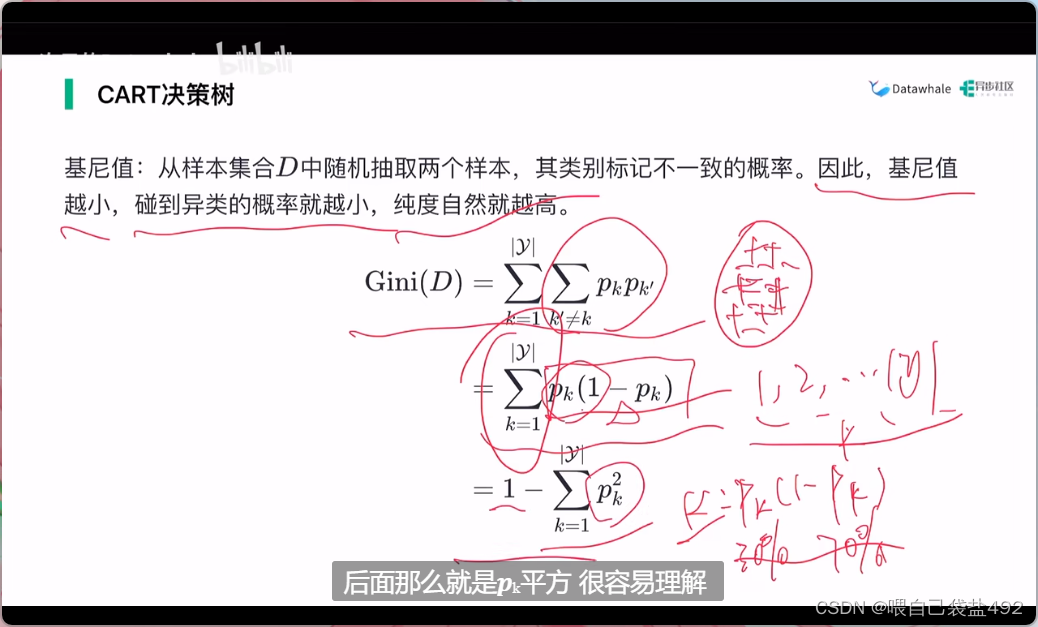
基尼指数:已知某个特征划分之后再按照该特征不同的值的子集求基尼指数,并最终加权相加。
CART决策树就是遍历各个特征划分后从中选取基尼指数最小的属性作为最优划分属性。而选择划分点时我们只能根据某特征等于某个值和不等于某个值分为两类,遍历所有取值后得到该特征的最优划分点与基尼指数。
















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









