






一、项目要求
根据电商日志文件,分析:
-
统计页面浏览量(每行记录就是一次浏览)
-
统计各个省份的浏览量 (需要解析IP)
-
日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
二、创建Maven项目编写e-commerce-practice程序

- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
编写LogParser.java类将数据文件中的属性进行分割
package com.Log2;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.Map;
public class LogParser {
private final Logger logger = LoggerFactory.getLogger(LogParser.class);
public Map<String, String> parse2(String log) {
Map<String, String> logInfo = new HashMap<String,String>();
IPParser ipParse = IPParser.getInstance();
if(StringUtils.isNotBlank(log)) {
String[] splits = log.split("\t");
String ip = splits[0];
String url = splits[1];
String sessionId = splits[2];
String time = splits[3];
String country = splits[4];
String province = splits[5];
String city = splits[6];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("sessionId",sessionId);
logInfo.put("time",time);
logInfo.put("country",country);
logInfo.put("province",province);
logInfo.put("city",city);
} else{
logger.error("日志记录的格式不正确:" + log);
}
return logInfo;
}
public Map<String, String> parse(String log) {
Map<String, String> logInfo = new HashMap<String,String>();
IPParser ipParse = IPParser.getInstance();
if(StringUtils.isNotBlank(log)) {
String[] splits = log.split("\001");
String ip = splits[13];
String url = splits[1];
String sessionId = splits[10];
String time = splits[17];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("sessionId",sessionId);
logInfo.put("time",time);
IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip);
logInfo.put("country",regionInfo.getCountry());
logInfo.put("province",regionInfo.getProvince());
logInfo.put("city",regionInfo.getCity());
} else{
logger.error("日志记录的格式不正确:" + log);
}
return logInfo;
}
}编写GetPageId.java解析出pageId(topicId对应的页面Id)
package com.Log3;
import org.apache.commons.lang.StringUtils;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetPageId {
public static String getPageId(String url) {
String pageId = "";
if (StringUtils.isBlank(url)) {
return pageId;
}
Pattern pat = Pattern.compile("topicId=[0-9]+");
Matcher matcher = pat.matcher(url);
if (matcher.find()) {
pageId = matcher.group().split("topicId=")[1];
}
return pageId;
}
public static void main(String[] args) {
System.out.println(getPageId("http://www.yihaodian.com/cms/view.do?topicId=14572"));
System.out.println(getPageId("http://www.yihaodian.com/cms/view.do?topicId=22372&merchant=1"));
}
}
编写LogETLDriver.java
package com.Log3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogETLDriver {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: LogETLDriver <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Log ETL");
job.setJarByClass(LogETLDriver.class);
job.setMapperClass(LogETLMapper.class);
job.setCombinerClass(LogETLReducer.class);
job.setReducerClass(LogETLReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
编写 mapper 和 reducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Map;
public class LogETLMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private final Text outputKey = new Text();
private final LogParser logParser = new LogParser();
private final Logger logger = LoggerFactory.getLogger(LogETLMapper.class);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 解析日志记录
Map<String, String> logInfo = logParser.parse(value.toString());
if (logInfo == null) {
logger.error("日志记录的格式不正确或解析失败:" + value);
return;
}
// 获取需要的字段
String ip = logInfo.get("ip");
String url = logInfo.get("url");
String country = logInfo.get("country");
String province = logInfo.get("province");
String city = logInfo.get("city");
// 调用 GetPageId 获取 topicId
String topicId = GetPageId.getPageId(url);
logInfo.put("topicId", topicId);
// 检查所有字段是否全部为空
if (ip != null || url != null || topicId != null || country != null || province != null || city != null) {
StringBuilder sb = new StringBuilder();
if (ip != null && !ip.isEmpty()) sb.append("IP: ").append(ip).append(", ");
if (url != null && !url.isEmpty()) sb.append("URL: ").append(url).append(", ");
if (topicId != null && !topicId.isEmpty()) sb.append("PageId: ").append(topicId).append(", ");
if (country != null && !country.isEmpty()) sb.append("Country: ").append(country).append(", ");
if (province != null && !province.isEmpty()) sb.append("Province: ").append(province).append(", ");
if (city != null && !city.isEmpty()) sb.append("City: ").append(city);
// 移除末尾的逗号和空格
String outputString = sb.toString().replaceAll(", $", "");
outputKey.set(outputString);
context.write(outputKey, one);
} else {
logger.error("所有字段为空,日志记录:" + value);
}
}
}import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogETLReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}三、将编写的MapReduce程序打包并上传至,启动集群的Linux系统中
(1)Idea中打包 java程序:
File --> Project Structure --> Artifacts --> + -->JAR --> From modules with dependencies
随后在Main Class中选择 Log3,随后点击OK
点击ok后,选择: Build --> Build Artifacts --> Build
在左侧会自动生成一个out的文件Log3.jar
(2)运行程序
在运行程序之前,需要启动Hadoop,命令如下:
cd /usr/local/hadoop //hadoop目录
./sbin/start-dfs.sh在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r etcinput
./bin/hdfs dfs -rm -r etcoutput然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir etcinput然后,把之前的文件trackinfo_20130721.txt上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put ./trackinfo_20130721.txt etcinput
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop
./bin/hadoop jar ./Log3.jar etcinput etcoutput上面命令执行以后,当运行顺利结束时,HDFS中output目录下出现以下文件证明成功:

结果如下(展示部分):
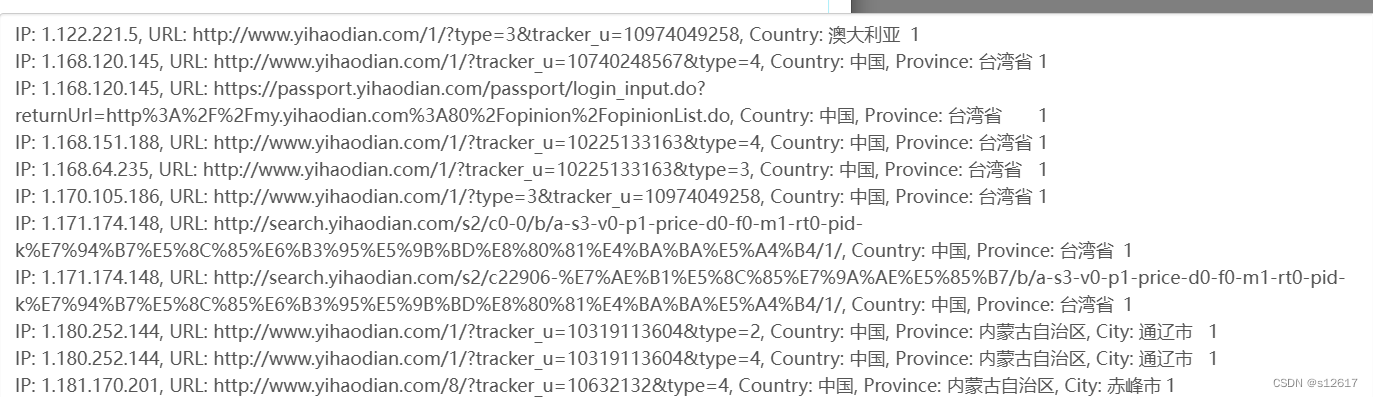
含有topicId的某条记录: ![]()















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









