







任务描述
使用勒索软件数据集训练一个随机森林模型,以分析文件特征并识别勒索软件。通过学习已知恶意和正常文件的特征,模型将能够准确分类未知文件,从而有效检测勒索软件的存在。 该数据集中包含138047条数据,每条数据包含56个特征以及一个名为“legitimate”的标签,用于指示是否为合法(legitimate)的样本(其中1为合法,0为非法)。
相关知识
- 随机森林:
随机森林(Random Forest)是一种集成(ensemble)学习方法,用于解决分类和回归问题。它组合了多个决策树来进行预测,并通过一定的机制来提高模型的稳定性和泛化能力。同类方法还包括Adaboost,XGBoost等。
- 混淆矩阵:
混淆矩阵是在分类问题中用于衡量模型性能的工具。它将模型的预测结果与实际情况进行比较,将样本分为四种不同的情况:真正例、假正例、真反例、假反例。通过混淆矩阵,可以计算出一系列分类指标,如准确率、召回率、精确率等,来评估模型的性能和误差。
- 特征重要性:
特征重要性是用于了解在机器学习模型中哪些特征对预测结果产生了最大的影响,有助于特征选择、特征工程和模型的解释性。随机森林方法可以用于评估各特征的重要性。
编码提示
在获取结果的混淆矩阵时,可以直接调用sklearn中封装好的confusion_matrix,而不需要自己求取。
编程要求
根据代码提示,补全需要的代码:
- 观察数据集中前5项数据
预期的结果为:
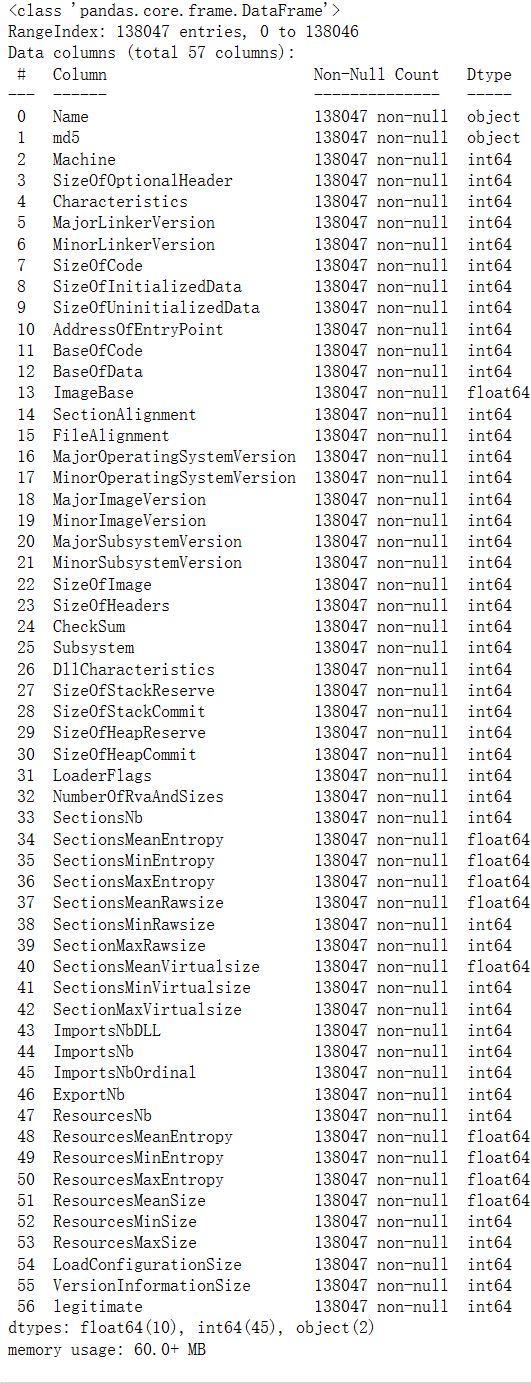
- 观察数据集中各列的特征名称以及数据信息
预期的结果为: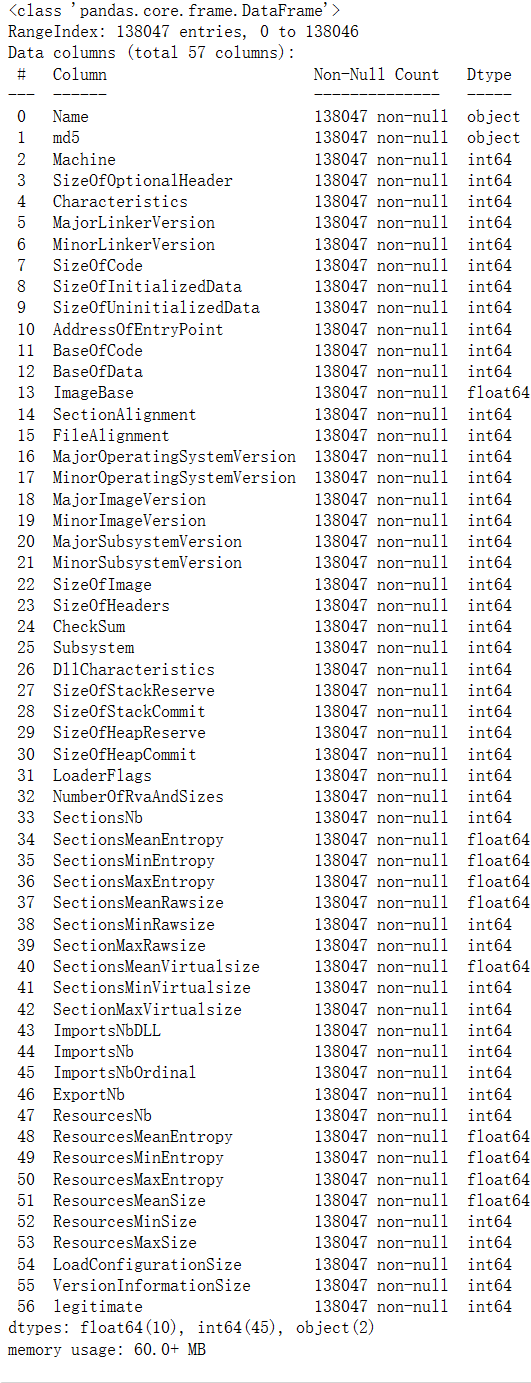
- 统计legitimate中0,1的数量
预期的结果为: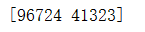
- 利用饼状图绘制数据集中legitimate的分布情况
预期的结果为: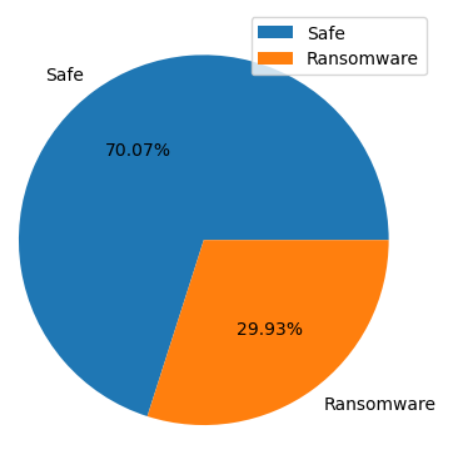
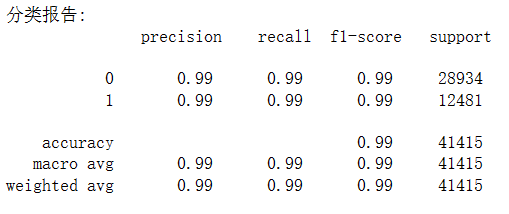
- 创建随机森林模型并训练,输出测试集上的分类报告
预期的结果为: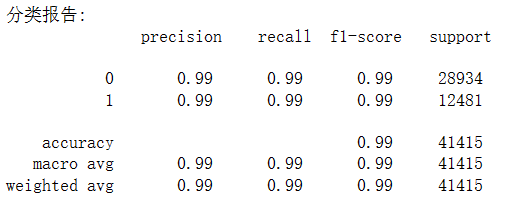
- 绘制混淆矩阵热力图
预期的结果为: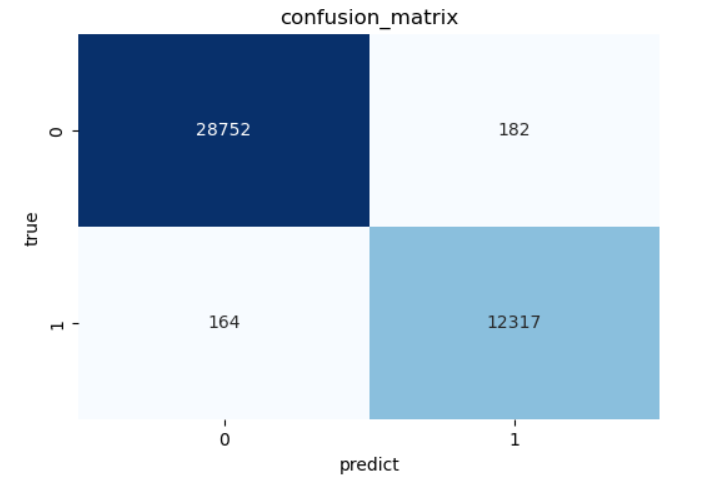
- 绘制特征重要性分布图
预期的结果为: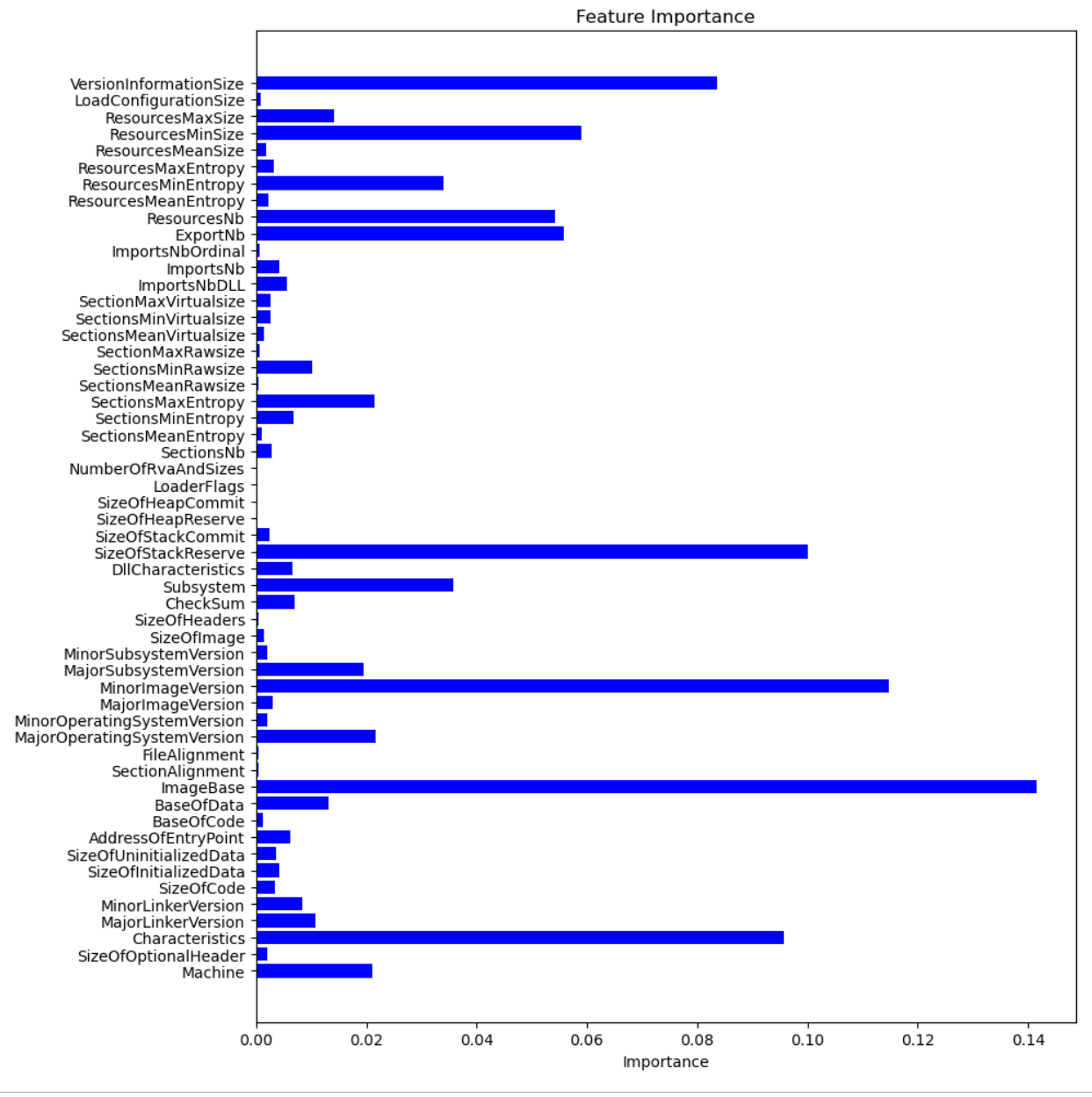
测试说明
平台将根据最后的运行结果进行评测。 注意: (1)评测前,请注释题目未要求的所有print()语句,保留题目明确要求“打印”的语句; (2)请点击Jupyter的“保存”按钮,保存代码。 预期的结果为:
![]()
实验内容
# -*-encoding:utf-8 -*-
# import package.
# 导入必要的包
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from sklearn.feature_selection import mutual_info_classif
import warnings
warnings.filterwarnings('ignore')
df=pd.read_csv("/data/bigfiles/Ransomware.csv",sep='|')
# 利用head()函数观察数据集中前5项数据
df.head(5)
# 利用info()函数观察数据集中各列的特征名称以及数据信息
df.info()
# 统计legitimate中0,1的数量,并存储至legitimate_values,利用.value_counts().values实现
legitimate_values = df.legitimate.value_counts().values
# print(df.legitimate.value_counts()) values形成数组
print(legitimate_values)
plt.pie(legitimate_values.tolist(), labels=['Ransomware','Safe'], autopct='%.2f%%')
plt.legend()
plt.show()
# 所有特征全部选择(去除name以及MD5)
X = df.iloc[:,2:56]
y = df.iloc[:,56]
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 利用RandomForestClassifier创建随机森林模型,其中参数设置为n_estimators=48, max_depth=9, criterion='gini'
rfc = RandomForestClassifier(n_estimators=48, max_depth=9, criterion='gini')
# 训练rfc
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
# 输出分类报告
class_report = classification_report(y_test, y_pred)
print("分类报告:\n", class_report)
# 利用confusion_matrix()函数求y_test与y_pred之间的混淆矩阵
confusion = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵热图
plt.figure(figsize=(6, 4))
sns.heatmap(confusion, annot=True, fmt="d", cmap="Blues", cbar=False)
plt.xlabel('predict')
plt.ylabel('true')
plt.title('confusion_matrix')
plt.show()
# 利用随机森林中封装好的feature_importances_方法获取模型训练完成后的特征重要性
feature_importances = rfc.feature_importances_
feature_names = X.columns
# 创建一个条形图
plt.figure(figsize=(10, 10))
plt.barh(feature_names, feature_importances, color='blue')
# 添加标题和标签
plt.title('Feature Importance')
plt.xlabel('Importance')
# 显示图表
plt.tight_layout()
plt.show()















 4764
4764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









