







目录
Hadoop作为大数据计算框架,核心关键点就是分布式集群的搭建,基于集群环境,大规模的数据处理任务成为可能,可以说是提供大数据计算的关键性技术支持。Hadoop集群的搭建,分布式文件系统HDFS提供了基础存储支持,需要存储的数据被HDFS切割成块分布到集群环境当中进行存储,具有高容错、高可靠性、高可扩展性、高获得性、高吞吐率。本文就如何搭建hadoop展开。
搭建前提:VMware Workstation Pro、CentOS 7 安装成功。

1.用户权限修改
在后期配置集群的时候,会经常用到root权限,我们在此对用户权限进行修改和免密切换。
(1)使用“su -”命令切换为root用户,然后执行以下命令,修改文件sudoers:
$ vi /etc/sudoers //进入sudoers文件
(2)在文本root ALL=(ALL) ALL的下方加入以下代码,使hadoop用户可以使用sudo指令并免密切换:
hadoop01 ALL=(ALL) ALL
hadoop01 ALL=(ALL) NOPASSWD:ALL

(3)执行exit命令回到hadoop用户,此时使用root权限的命令只需要在命令前面加入sudo即可,无需输入密码。例如以下命令:
$ sudo cat /etc/sudoers
2.关闭防火墙
集群通常都是内网搭建的,如果内网开启防火墙,内网集群通讯则会受到防火墙的干扰,因此需要关闭集群中所有节点的防火墙。
(1)执行以下命令关闭防火墙:
$ sudo systemctl stop firewalld.service
(2)执行以下命令,禁止防火墙开机启动:
$ sudo systemctl disable firewalld.service
(3)若需要查看防火墙是否已经关闭,可以执行以下命令,查看防火墙的状态:
$ sudo firewall-cmd --state
3.设置固定IP
(1)在系统终端命令行窗口执行以下命令,修改文件ifcfg-ens33:
$ sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33具体内容如下:
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=cd0d7046-b038-47c1-babe-6442444e9fa9
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.45.128
NETMASK=255.255.255.0
GATEWAY=192.168.45.255
DNS1=192.168.45.1
DNS2=114.114.114.114
查看自己的IP地址:ifconfig

查看自己DNS:在window系统中打开cmd,输入ipconfig

(2)修改完成后执行以下命令,重启网络服务,使修改生效:
$ sudo service network restart
重启完成后,可以通过ifconfig命令或者以下命令,查看改动后的IP: $ ip addr 在输出的信息中,若网卡ens33对应的IP地址已显示为设置的地址,说明IP修改成功。
在本地Windows系统打开cmd命令行窗口,使用ping命令访问虚拟机中操作系统的IP地址: $ ping 192.168.45.128 若能成功返回数据,说明从本地Windows可以成功访问虚拟机中的操作系统,便于后续从本地系统进行远程操作。
4.修改主机名。
在分布式集群中,主机名用于区分不同的节点,方便节点之间相互访问,因此需要修改主机的主机名。
具体步骤如下:
(1)使用hadoop用户登录系统,进入系统的终端命令行,输入以下命令,查看主机名:
$ hostname当前主机的默认主机名为localhost.localdomain。
(2)执行以下命令,设置主机名为centos01:
$ sudo hostname centos01此时系统的主机名已修改为centos01,但是重启系统后修改将失效,要想永久改变主机名,需要修改/etc/hostname文件。 执行以下命令,修改hostname文件,将其中的默认主机名改为centos01:
$ sudo vi /etc/hostname(3)执行reboot命令,重启系统使修改生效。 需要注意的是,修改主机名后需要重启操作系统才能生效。
$ sudo vi /etc/hostname
5.新建资源目录
在目录/opt下创建两个文件夹softwares和modules,分别用于存放软件安装包和软件安装后的程序文件,命令如下:
$ sudo mkdir /opt/softwares
$ sudo mkdir /opt/modules将目录/opt及其子目录中所有文件的所有者和组更改为用户hadoop01和组hadoop01,命令如下:
$ sudo chown -R hadoop:hadoop /opt/*查看目录权限是否修改成功,命令如下:
$ ll
也可以通过图形界面如下:



6.安装JDK
(1)卸载系统自带的JDK
卸载系统自带的JDK,执行以下命令,查询系统已安装的JDK:
$ rpm -qa|grep java
执行以下命令,卸载以上查询出的系统自带的JDK:
$ sudo rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
$ sudo rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch
$ sudo rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
$ sudo rpm -e --nodeps tzdata-java-2016g-2.el7.noarch
$ sudo rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch
$ sudo rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
$ sudo rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
(2)安装JDK
通过Xftp或者Xshell上传JDK安装包jdk1.8.0_162-linux-x64.tar.gz到目录/opt/softwares中,然后进入该目录,解压jdk1.8.0_162-linux-x64.tar.gz到目录/opt/modules中,解压命令如下:
$ tar -zxf jdk1.8.0_162-linux-x64.tar.gz -C /opt/modules/执行以下命令,修改文件/etc/profile,配置JDK系统环境变量:
$ sudo vi /etc/profile在文件末尾加入以下内容:
export JAVA_HOME=/opt/modules/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin执行以下命令,刷新profile文件,使修改生效。
$ source /etc/profile执行java -version命令,若能成功输出JDK版本信息,说明安装成功.
7.克隆虚拟机
克隆centos01节点到centos02

在弹出的【克隆虚拟机向导】窗口中直接单击【下一步】按钮即可,如图

在弹出的【克隆源】窗口中,选择【虚拟机中的当前状态】选项,然后单击【下一步】按钮,如图

在弹出的【克隆类型】窗口中,选择【创建完整克隆】选项,然后单击【下一步】按钮,如图
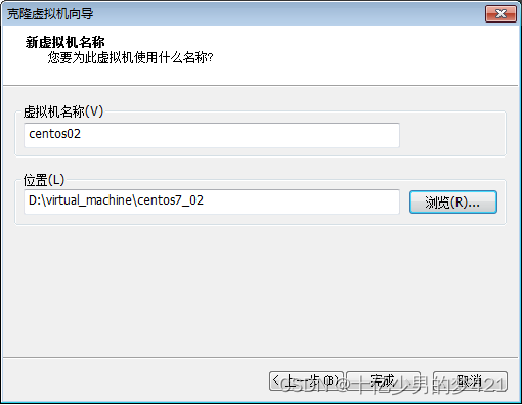
 在弹出的新窗口中,【虚拟机名称】一栏填写为“centos02”,并单击【浏览】按钮,修改新虚拟机的存储位置,然后单击【完成】,开始进行克隆,如图
在弹出的新窗口中,【虚拟机名称】一栏填写为“centos02”,并单击【浏览】按钮,修改新虚拟机的存储位置,然后单击【完成】,开始进行克隆,如图
同样的操作克隆centos01节点到centos03
修改节点主机名与IP
由于节点centos02与centos03是从centos01克隆而来,主机名和IP与centos01完全一样,因此需要修改这两个节点的主机名与IP。
本例中,分别将节点centos02和centos03的主机名修改为“centos02”和“centos03”,IP修改为固定IP 192.168.45.129和192.168.45.130。
8.配置主机映射
通过修改各节点的主机IP映射,可以方便的使用主机名访问集群中的其它主机,而不需要输入IP地址。这就好比我们通过域名访问网站一样,方便快捷。
(1)依次启动三个节点:centos01、centos02、centos03。
(2)使用ifconfig命令查看三个节点的IP,博主三个节点的IP分别为: 192.168.45.128 192.168.45.129 192.168.45.130
(3)在各个节点上分别执行以下命令,修改hosts文件:
$ sudo vi /etc/hosts在hosts文件末尾追加以下内容:
192.168.45.128 centos01
192.168.45.129 centos02
192.168.45.130 centos03需要注意的是,主机名后面不要有空格,且每个节点的hosts文件中都要加入同样的内容,这样可以保证每个节点都可以通过主机名访问到其它节点,防止后续的集群节点间通信产生问题。
(4)配置完后,在各节点使用ping命令检查是否配置成功,如下:
$ ping centos01
$ ping centos02
$ ping centos03 (5)配置一下本地Windows系统的主机IP映射,以便后续可以在本地通过主机名直接访问集群节点资源。编辑Windows操作系统的C:\Windows\System32\drivers\etc\hosts文件,在文件末尾加入以下内容即可:
192.168.45.128 centos01
192.168.45.129 centos02
192.168.45.130 centos039.配置集群各节点SSH无密钥登录
ssh-copy-id命令可以把本地主机的公钥复制并追加到远程主机的authorized_keys文件中,该命令也会给远程主机的用户主目录(home)、~/.ssh目录和~/.ssh/authorized_keys设置合适的权限。 (1)分别在三个节点中执行以下命令,生成密钥文件:
$ ssh localhost
$ cd ~/.ssh/
$ ssh-keygen -t rsa # 生成密钥文件,会有提示输入加密信息,都按回车即可(2)分别在三个节点中执行以下命令,将公钥信息拷贝并追加到对方节点的授权文件authorized_keys中:
$ ssh-copy-id centos01
$ ssh-copy-id centos02
$ ssh-copy-id centos03命令执行过程中需要输入当前用户的密码。
(3)测试SSH无密钥登录。 仍然使用ssh命令进行测试登录即可。
10.搭建Hadoop3.x集群分布
博主的搭建思路是,在节点centos01中安装Hadoop并修改配置文件,然后将配置好的Hadoop安装文件远程拷贝到集群中的其它节点。集群各节点的角色分配如表

(1)使用Xfpt或Xshell上传Hadoop并解压 在centos01节点中,将Hadoop安装文件hadoop-3.3.0.tar.gz上传到/opt/softwares/目录,然后进入该目录,解压安装文件到/opt/modules/,命令如下:
$ cd /opt/softwares/ $ tar -zxf hadoop-3.3.0.tar.gz -C /opt/modules/(2) 配置系统环境变量
为了可以方便的在任意目录下执行Hadoop命令,而不需要进入到Hadoop安装目录,需要配置Hadoop系统环境变量。此处只需要配置centos01节点即可。 执行以下命令,修改文件/etc/profile:
$ sudo vi /etc/profile在文件末尾加入以下内容:
export HADOOP_HOME=/opt/modules/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin执行以下命令,刷新profile文件,使修改生效。
$ source /etc/profile执行Hadoop version命令,若能成功输出返回Hadoop版本信息,说明系统变量配置成功。
(3). 配置Hadoop环境变量 Hadoop所有的配置文件都存在于安装目录下的etc/hadoop中,进入该目录,修改以下配置文件:
hadoop-env.sh
mapred-env.sh
yarn-env.sh三个文件分别加入JAVA_HOME环境变量,如下:
export JAVA_HOME=/opt/modules/jdk1.8.0_162(4) 配置HDFS
修改配置文件core-site.xml,加入以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/modules/hadoop-3.3.0/tmp</value>
</property>
</configuration>修改配置文件hdfs-site.xml,加入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property><!--不检查用户权限-->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/hadoop-3.3.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/hadoop-3.3.0/tmp/dfs/data</value>
</property>
</configuration>
修改workers文件,配置DataNode节点。 workers文件原本无任何内容,需要将所有DataNode节点的主机名都添加进去,每个主机名占一整行(注意不要有空格)。博主的DataNode为三个节点,配置信息如下:
centos01
centos02
centos03修改mapred-site.xml文件,添加以下内容,指定MapReduce任务执行框架为YARN,并配置MapReduce任务的环境变量。
<!--指定MapReduce任务执行框架为YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--为MapReduce应用程序主进程添加环境变量-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/modules/hadoop-3.3.0</value>
</property>
<!--为MapReduce Map任务添加环境变量-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/modules/hadoop-3.3.0</value>
</property>
<!--为MapReduce Reduce任务添加环境变量-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/modules/hadoop-3.3.0</value>
</property>
</configuration>修改yarn-site.xml文件,添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(5)拷贝Hadoop安装文件到其它主机
在centos01节点上,将配置好的整个Hadoop安装目录拷贝到其它节点(centos02和centos03),命令如下:
$ scp -r hadoop-3.3.0/ hadoop01@centos02:/opt/modules/
$ scp -r hadoop-3.3.0/ hadoop01@centos03:/opt/modules/(6).格式化NameNode
启动Hadoop之前,需要先格式化NameNode。格式化NameNode可以初始化HDFS文件系统的一些目录和文件,在centos01节点上执行以下命令,进行格式化操作:
$ hdfs namenode -format格式化成功后,会在当前节点的Hadoop安装目录中生成tmp/dfs/name/current目录,该目录中则生成了用于存储HDFS文件系统元数据信息的文件fsimage。

(7)在centos01节点上执行以下命令,启动Hadoop集群:
$ start-all.sh也可以执行start-dfs.sh和start-yarn.sh分别启动HDFS集群和YARN集群。
(8)查看各节点启动进程
集群启动成功后,分别在各个节点上执行jps命令,查看启动的Java进程。
可以看到,各节点的Java进程如下:
centos01节点的进程: $ jps
13524 SecondaryNameNode
13813 NodeManager
13351 DataNode
13208 NameNode
13688 ResourceManager
14091 Jpscentos02节点的进程: $ jps
7585 NodeManager
7477 DataNode
7789 Jpscentos03节点的进程: $ jps
8308 Jps
8104 NodeManager
7996 DataNode如果结点少文件的话检查一下配置文件是否正确。
11.Hadoop集群初体验--文章单词统计
打开集群,输入在浏览器上输入http://centos01:9870 打开如图所示的网页

打开 HDFS 的 UI,选择Utilities→Browse the file system查看分布式文件系统里的数据文件,可以看到新建的HDFS上没有任何数据文件。

输入以下命令,并对文件内容进行编辑
$ sudo vi /opt/modules/word.txt
输入以下命令创建input目录,并将word.txt文件上传至input 目录下
$ hadoop fs -mkdir -p /wordcount/input
$ hadoop fs -put /opt/modules/word.txt /wordcount/input在此打开HDFS的UI界面你会发现/wordcount/input 目录创建成功并上传了指定的文件word.txt

进入mapreduce目录下,使用ll指令查看文件夹的内容,我们使用mapreduce自带的jar文件进行单词统计

执行如下指令:
$ hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output执行后,可以通过UI查看,如图

执行结果如下:

总结
在hadoop搭建的时候会出现非常多的错误,如在修改配置文件时文件里原本会有一对<configuration></configuration>,要记得删除,或者在修改cenos02、centos02结点上的主机名时记得在文件中也要修改,或者格式化的的时候执行了两遍等都会使程序不能正常运行,在我们搭建的过程中,遇见问题要学会查看日志,找到问题,出现问题才是你真正学习的时候。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











