






乱码产生的常见原因有三种:
- 二进制数据不完整;如字节流读取中文,假设使用文件是UTF-8编码(中文占3个字节),使用read()只返回一个字节,直接解码将导致乱码,因为数据不完整.
- 编码和解码的方式不一致
- 编、解码方式一致,但这种格式的字符集不包含中文(ASCII、ISO-8859-1)
小白建议全文阅读,有基础的可以直接跳到分析过程
基础知识
编码:字符转换为字节的过程
byte[] bytes = "邱".getBytes("UTF-8");解码:字节转换为字符的过程
String s=new String(bytes2,"UTF-8");利用IO的思路来理解:字符"邱"存在一个txt文件里,使用字节流读取获得的字节数组就是字符编码后的结果,我们按照编码的格式解码,将得到正确的字符"邱"
回到标题,此时将产生矛盾,明显的编、解码方式不一致,还可以解决乱码?
new String(str.getBytes("ISO-8859-1"), "UTF-8");
//按ISO-8859-1格式编码,以UTF-8解码首先解释这个字符串str,分析它是如何产生的?
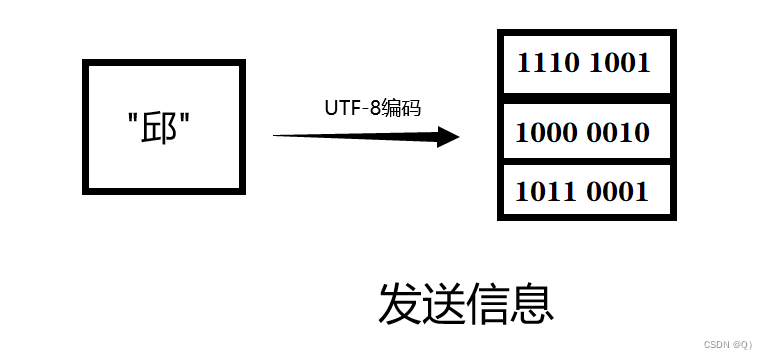
假设一个网络编程的场景,分为服务器端和客户端,规定服务器端使用ISO-8859-1编码格式接送信息,模拟发送消息。
//客户端发送信息
OutputStream out = xxx.getOutputStream();
out.write("邱".getBytes("UTF-8"));
//服务器端接收信息
BufferedReader in = new BufferedReader(new InputStreamReader(xxx.getInputStream(), "ISO-8859-1"));
String message=in.readLine();
这样肯定是乱码的,原因就是编、解码不同。那把编、解码设置一致呢?也没用,因为ISO-8859-1码中不包含中文。
//对IO知识不太了解的,做一个解读
//以上代码,和下面代码一个意思
byte[] bytes = "邱".getBytes("UTF-8");//客户端将bytes传给服务器
String message=new String(bytes,"ISO-8859-1");
//服务器接收bytes数组,使用iso8859-1格式解码那服务器使用ISO-8859-1编码格式接收数据就无法使用中文了吗?肯定不是的。看以下操作
//客户端发送信息
OutputStream out = socket.getOutputStream();
out.write("邱".getBytes("UTF-8"));
//服务端接收信息
BufferedReader in = new BufferedReader(new InputStreamReader(xxx.getInputStream(), "ISO-8859-1"));
String str=in.readLine();
//正确的信息
String message=new String(str.getBytes("ISO-8859-1"), "UTF-8");
我们看到了一行熟悉的代码
new String(str.getBytes("ISO-8859-1"), "UTF-8");由此可以得出字符串str的产生,其实就是服务器端接收的一串字符串(注意:str可不是最后的message哦!)
//客户端将bytes传给服务器
byte[] bytes = "邱".getBytes("UTF-8");
//服务器接收bytes数组,使用iso8859-1格式解码
String str=new String(bytes,"ISO-8859-1");
所以,字符串str只是一个不同编、解码的结果(乱码),并不是一个有具体意义的字符串。
好了,知道了字符串str的由来,正片开始!
分析
new String(str.getBytes("ISO-8859-1"), "UTF-8");
我们可以将以上过程来一个分解
byte[] bytes = "邱".getBytes("UTF-8");
String str=new String(bytes,"iso8859-1");//字符串str
byte[] bytes2=str.getBytes("iso8859-1");
String message=new String(bytes2,"UTF-8");//正确结果将字节数组、字符串都打印出来
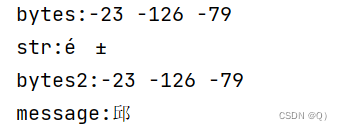
整个过程,如图所示
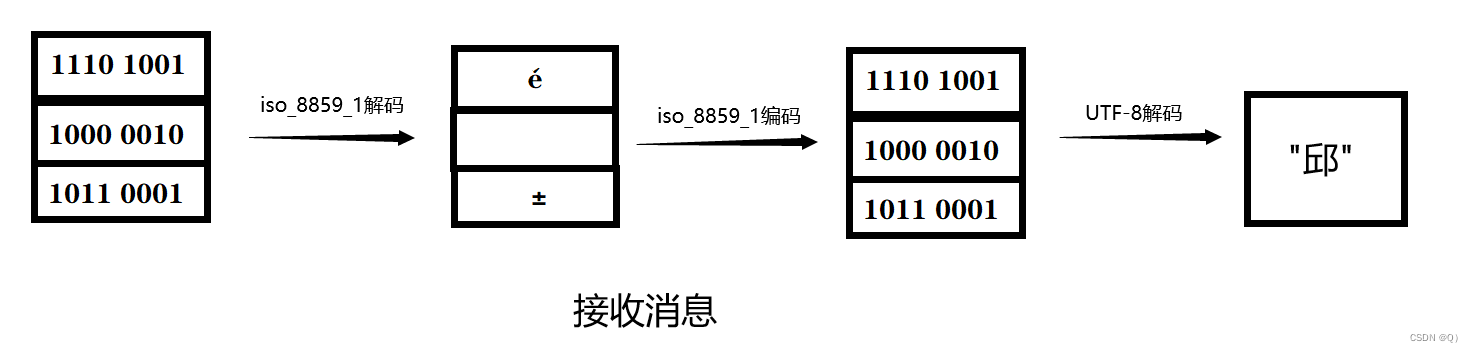
整个过程的关键就是,通过ISO-8859-1的解、编码,原本的UTF-8编码得到了还原,促使最后使用UTF-8解码成功。
其实这得益于ISO-8859-1编码的特性,它是单字节编码,即一个字节对应一个字符,即使解码成乱码,但也是正确结果的乱码。
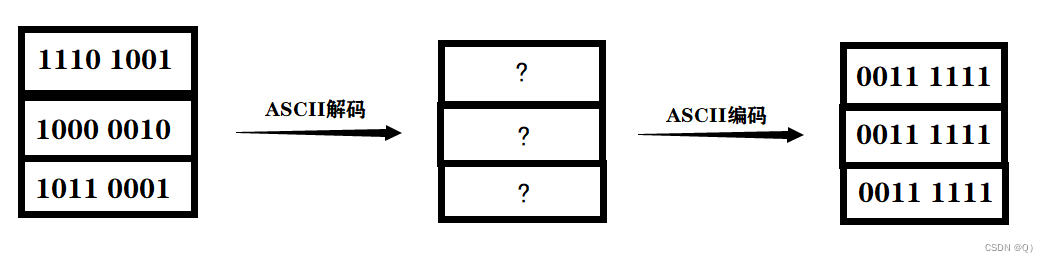
如果是ASCII码就会得到错误的乱码,因为ASCII码只支持7位(bit)的二进制,解码8位时,发现没有对应字符就会解码成"?"字符,编码出来的二进制就是"?"的二进制,自然与之前的二进制不一样了,其他编码方式也是一样道理。
总结
new String(str.getBytes("ISO-8859-1"), "UTF-8");
字符串str是一段正确乱码,没具体含义;getBytes("ISO-8859-1")将原编码还原,用原编码UTF-8解码,得到正确结果。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









