






思路;
首先这道题教会了我不能再去随便使用string这个类了, 我们在存储字符串的时候最好是使用char类型的数组去存储, 因为string我们在创建的时候如果不指点类的大小的话很容易出现内存的越界访问吗,这样容易造成答案的错误, 所以以后存储字符串一定要开char数组进行存储。
国际乒联11分制的规则是:在一局比赛中, 先得11分的一方是胜方;10平后, 先多得2分的一方为胜方。
同样21分制的规则是:在一局比赛中, 先得21分的一方是胜方, 20平后,先多的两分的一方是胜方。
我们知道了这两个规则后就可以知道如何去写了 :
if((win >= 11 || fail >= 11) && abs(win - fail) >= 2)
这句代码的含义就是先得11分的为胜方, 10平后先多得两分的一方为胜方!
(如果有一个分数达到了11分并且两者的分差大于等于2)
代码:
#include <iostream>
#include <cmath>
#define int long long
using namespace std ;
signed main()
{
char a[100010] ;
int cnt = 0 ;
char c ;
cin >> c ;
while((c != 'E') )
{
if(c == 'W' || c == 'L')
{
a[cnt++] = c ;
}
cin >> c ;
}
int win = 0 , fail = 0 ;
for(int i = 0 ; i < cnt ; i ++ )
{
if(a[i] == 'W' ) win ++ ;
if(a[i] == 'L' ) fail ++ ;
if((win >= 11 || fail >= 11) && abs(win - fail) >= 2)
{
cout << win << ":" << fail << endl ;
win = fail = 0 ;
}
}
cout << win << ":" << fail << endl ;
cout << endl ;
win = 0 , fail = 0 ;
for(int i = 0 ; i < cnt ; i ++ )
{
if(a[i] == 'W' ) win ++ ;
if(a[i] == 'L' ) fail ++ ;
if((win >= 21 || fail >= 21) && abs(win - fail) >= 2)
{
cout << win << ":" << fail << endl ;
win = fail = 0 ;
}
}
cout << win << ":" << fail << endl ;
return 0 ;
}
题意
思路:
这个题我们可以正向求解, 直接统计一个sum值去求解,不知道你为什么没有想起来
看代码吧。
#include <iostream>
using namespace std ;
typedef long long LL ;
int dig(int n )
{
int res = 0 ;
while(n )
{
res ++ ;
n /= 10 ;
}
return res ;
}
int main()
{
int n , i = 0 , sum = 0 ;
cin >> n ;
while(sum < n )
{
i++ ;
sum += dig(i) ;
}
while(sum != n )
{
i /= 10 ;
sum -- ;
}
cout << i % 10 ;
return 0 ;
}
这个题我们可以时候String类的封装函数去写, 首先我们要去将每一个模式串中的大写去转化为小写, 这个可以完美解决题中的大小写问题。
1. size_t find (constchar* s, size_t pos = 0) const;
//在当前字符串的pos索引位置开始,查找子串s,返回找到的位置索引,
-1表示查找不到子串
2. size_t find (charc, size_t pos = 0) const;
//在当前字符串的pos索引位置开始,查找字符c,返回找到的位置索引,
-1表示查找不到字符
3. size_t rfind (constchar* s, size_t pos = npos) const;
//在当前字符串的pos索引位置开始,反向查找子串s,返回找到的位置索引,
-1表示查找不到子串
4. size_t rfind (charc, size_t pos = npos) const;
//在当前字符串的pos索引位置开始,反向查找字符c,返回找到的位置索引,-1表示查找不到字符
5. size_tfind_first_of (const char* s, size_t pos = 0) const;
//在当前字符串的pos索引位置开始,查找子串s的字符,返回找到的位置索引,-1表示查找不到字符
6. size_tfind_first_not_of (const char* s, size_t pos = 0) const;
//在当前字符串的pos索引位置开始,查找第一个不位于子串s的字符,返回找到的位置索引,-1表示查找不到字符
7. size_t find_last_of(const char* s, size_t pos = npos) const;
//在当前字符串的pos索引位置开始,查找最后一个位于子串s的字符,返回找到的位置索引,-1表示查找不到字符
8. size_tfind_last_not_of (const char* s, size_t pos = npos) const;
//在当前字符串的pos索引位置开始,查找最后一个不位于子串s的字符,返回找到的位置索引,-1表示查找不到子串
代码
#include <iostream>
using namespace std ;
int main()
{
int t ;
cin >> t ;
string b = "alan" ;
int cnt = 0 ;
while(t -- )
{
string a ;
cin >> a ;
for(int i = 0 ; i < a.size() ; i ++ )
{
if(a[i] >= 'A' && a[i] <= 'Z' )
{
a[i] = a[i] + 32 ;
}
}
if(a.find(b) != -1 ) cnt ++ ;
}
cout << cnt ;
return 0 ;
}
知识点:我们可以使用getline函数对一行上的含有空格的字符串进行一个读入 , 之后利用string类的find函数进行一个对子串的寻找。还有一个 tolower() 函数的使用注意一下。
一些比较难办的bug : 注意在读入的时候我们不能这样写:
cin >> t ;
getline(cin , s )
因为虽然cin在读入的时候会自动忽略空格, 但当我们读入完第一行的东西后,位于缓冲区之前的是一个回车键, 这样就不太行了, 因为getline函数的定义就是大佬解释
总结一下就是getline函数的前面需要去先getchar()一下。 防止发生错误。
AC代码:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string t,s;
getline(cin,t);
getline(cin,s);
for(int i=0;i<t.length();i++)
{
t[i]=tolower(t[i]);
}
for(int i=0;i<s.length();i++)
{
s[i]=tolower(s[i]);
}
t=' '+t+' ';
s=' '+s+' ';
int times=0;
//int posi;
int a=0;
while(s.find(t,a) != string::npos)
{
a=s.find(t,a)+t.size()-1;
times++;
}
if(times == 0) printf("-1");
else cout<<times<<" "<<s.find(t);
}
易错点:我们在进行那个数字的转化的时候,就是这个
while(len -- )
{
str[cnt++] = x % 10 ;
x /= 10 ;
}
int dig = 0 ;
for(int i = cnt - 1 ; i >= 0 ; i -- )
{
dig = dig * 10 + str[i] ;
}
需要注意的是while循环当中是将高位的放在了后面, 我们将其转化为10进制的数字时记得要从最后一个位置开始!!!
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010 ;
int arr[N] ;
int n , q ;
bool check(int x , int len , int y ) // x的后len位是否跟y相同。
{
if(x < y ) return false ;
int str[20] , cnt = 0 ;
memset(str , 0 , sizeof str ) ;
while(len -- )
{
str[cnt++] = x % 10 ;
x /= 10 ;
}
int dig = 0 ;
for(int i = cnt - 1 ; i >= 0 ; i -- )
{
dig = dig * 10 + str[i] ;
}
if(dig == y ) return true ;
return false ;
}
int main()
{
cin >> n >> q ;
for(int i = 0 ; i < n ; i ++ )
{
cin >> arr[i] ;
}
sort(arr , arr + n ) ;
while(q -- )
{
int len = 0 , dig = 0 ;
cin >> len >> dig ;
int target = -1 ;
for(int i = 0 ; i < n ; i ++ )
{
if(arr[i] < dig ) continue ;
else {
if(check(arr[i] , len , dig ) )
{
target = arr[i] ;
break ;
}
}
}
cout << target << endl ;
}
return 0 ;
}
脑残级错误:
题意
这个题可以直接使用高精加去写,但有一个特别坑的bug就是题中的impossible中的后面的那个“!” ,这个!是你直接复制单词复制不过来的!!!! 。 卡了我两个小时(我是傻逼) 。
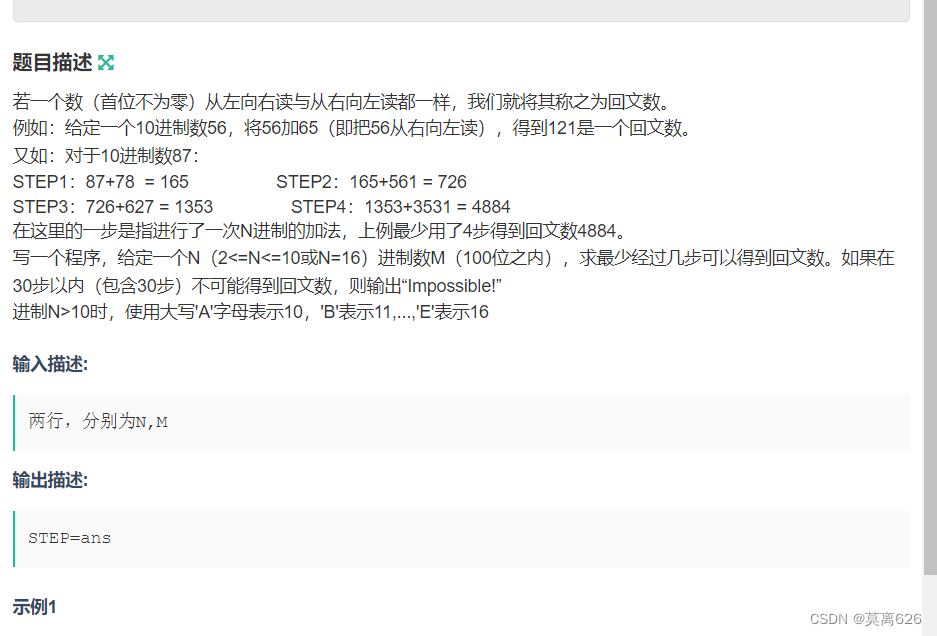
AC 代码:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std ;
int p ;
vector<int> add(vector<int> A , vector<int> B )
{
int t = 0 ;
vector<int> C ;
for(int i = 0 ; i < A.size() ; i ++ )
{
t += A[i] + B[i] ;
C.push_back(t % p ) ;
t /= p ;
}
while(t)
{
C.push_back(t % p ) ;
t /= p ;
}
return C ;
}
bool check(vector<int> C ) // 判断是否是回文串。
{
for(int i = 0 ; i < C.size() / 2 ; i ++ )
{
if(C[i] != C[C.size() - 1 - i ] ) return false ;
}
return true ;
}
int main()
{
cin >> p ;
string a , b ;
cin >> a ;
vector<int> A , B , C ;
b = a ;
int cnt = 0 ;
bool flag = false ;
for(int i = a.size() - 1 ; i >= 0 ; i -- )
{
if(a[i] >= 'A' && a[i] <= 'F' )A.push_back( a[i] - 'A' + 10 ) ;
else A.push_back(a[i] - '0' ) ;
}
for(int i = 0 ; i < b.size() ; i ++ )
{
if(b[i] >= 'A' && b[i] <= 'F' ) B.push_back( b[i] - 'A' + 10 ) ;
else B.push_back(b[i] - '0' ) ;
}
for(int i = 1 ; i <= 30 ; i ++ )
{
C = add( A , B ) ;
if(check(C) )
{
cnt = i ;
flag = true ;
break ;
}
A = C ;
B = C ;
reverse(B.begin() , B.end() ) ;
}
if(flag )
{
printf("STEP=%d" , cnt ) ;
}
else puts("Impossible!") ;
return 0 ;
}
没想到的模拟方式:
题意
主要看这一段代码:
for(int i = 2 ; i < cnt ; i ++ )
{
if(prime[i - 2 ] + prime[i] == 2 * prime[i - 1] )
{
int d = prime[i] - prime[ i - 1 ] , j ;
printf("%d " , prime[i - 2 ] ) ;
for(j = i - 1 ; prime[j ] - prime[j - 1] == d ; j ++ ) printf("%d " , prime[j] ) ;
i = j + 1 ;
printf("\n") ;
}
实现了对等差数列的输出。
语言描叙:我们需要滑动的先确定一个最少的等差数列也就是这一行。
if(prime[i - 2 ] + prime[i] == 2 * prime[i - 1] )
之后我们考虑这个等差数列的长度是多少,我们用d来表示此等差数列的公差,先输出这个等差数列的首元素, 之后从中间元素开始遍历, 一旦满足
prime[j ] - prime[j - 1] == d
这个条件我们先输出 p r i m e [ j ] prime[j] prime[j] , 代表位于同一个等差数列, 之后再j++ ,判断下一个, 假如退出循环之后,我们要将i = j + 1 , 之后再经历最外层的循环的自增, i 就变成了 j + 2 了。就相当于开始了进行了下一个等差序列的判断。
AC代码:
#include <iostream>
using namespace std ;
const int N = 1e5 + 10 ;
int prime[N] ,cnt ;
bool is_prime(int x ) {
for(int i = 2; i <= x / i ; i ++ )
{
if(x % i == 0 ) return false ;
}
return true ;
}
int main()
{
int a , b ;
cin >> a >> b ;
for(int i = a ; i <= b ; i ++ )
{
if(is_prime(i) ) prime[cnt++] = i ;
}
// 这一段模拟确实牛逼
for(int i = 2 ; i < cnt ; i ++ )
{
if(prime[i - 2 ] + prime[i] == 2 * prime[i - 1] )
{
int d = prime[i] - prime[ i - 1 ] , j ;
printf("%d " , prime[i - 2 ] ) ;
for(j = i - 1 ; prime[j ] - prime[j - 1] == d ; j ++ ) printf("%d " , prime[j] ) ;
i = j + 1 ;
printf("\n") ;
}
}
return 0 ;
}
tip : 小技巧 , 对浮点数进行一个四舍五入的
假如这个浮点数是3.13456 如何进行一个四舍五入呢?
可以这样写
#include <iostream>
using namespace std ;
int main()
{
double t = 3.13456 ;
t = (t * 10 + 5 ) / 10 ;
cout << "直接输出浮点数:\n" << t << endl ;
t = (int)t ;
cout << "强转int类型再输出浮点数\n" << t << endl ;
return 0 ;
}
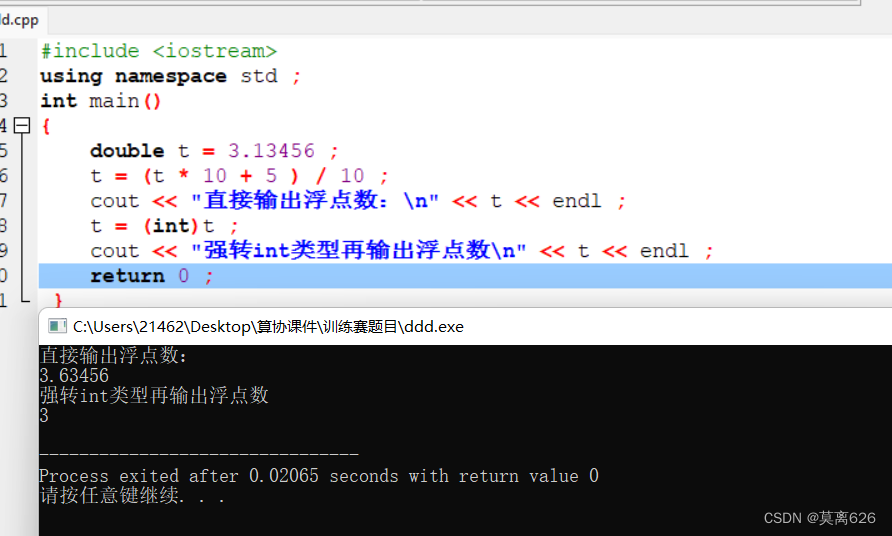
这样的小技巧非常实用!!!。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









