







目录
1.1 执行环境(Execution Environment)
1.2.2 三种读取数据的方法(从集合中读取数据、从文件读取数据、从元素读取数据)
1.3.4 物理分区(Physical Partitioning)
一、 DataStream API(基础篇)


1.1 执行环境(Execution Environment)
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交 到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时, 首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境 上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
1.1.1 创建执行环境
编写Flink程序的第一步,就是创建执行环境。我们要获取的执行环境 , 是StreamExecutionEnvironment 类的对象,这是所有 Flink 程序的基础。在代码中创建执行环境的 方式,就是调用这个类的静态方法,具体有以下三种。


1.1.2 执行模式(Execution Mode)



当然,在后面的示例代码中,即使是有界的数据源,我们也会统一用 STREAMING 模式 处理。这是因为我们的主要目标还是构建实时处理流数据的程序,有界数据源也只是我们用来 测试的手段。
1.1.3 触发程序执行

代码写完以后一定要加上execute方法才会触发真正的计算
1.2 源算子(Source)
1.2.1 准备工作

package com.me.chapter05;
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event(){
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}这里需要注意,我们定义的 Event,有这样几个特点:
⚫ 类是公有(public)的
⚫ 有一个无参的构造方法
⚫ 所有属性都是公有(public)的
⚫ 所有属性的类型都是可以序列化的 Flink 会把这样的类作为一种特殊的 POJO 数据类型来对待,方便数据的解析和序列化。 另外我们在类中还重写了 toString 方法,主要是为了测试输出显示更清晰。关于 Flink 支持的 数据类型,我们会在后面章节做详细说明。
我们这里自定义的 Event POJO 类会在后面的代码中频繁使用,所以在后面的代码中碰到
Event,把这里的 POJO 类导入就好了。
注:Java 编程比较好的实践是重写每一个类的 toString 方法
1.2.2 三种读取数据的方法(从集合中读取数据、从文件读取数据、从元素读取数据)
package com.me.chapter05;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
public class SourceTest {
public static void main(String[] args) throws Exception{
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1、从文件中读取数据(最常见)
DataStreamSource<String> stream1 = env.readTextFile("input/clicks.txt");
//2、从集合中读取数据
ArrayList<Integer> nums = new ArrayList<>();
nums.add(2);
nums.add(5);
DataStream<Integer> numStream = env.fromCollection(nums);
ArrayList<Event> events = new ArrayList<>();
events.add(new Event("Mary","./home",1000L));
events.add(new Event("Bob","./cart",2000L));
DataStream<Event> stream2= env.fromCollection(events);
//3、从元素读取数据
DataStream<Event> stream3= env.fromElements(
new Event("Mary","./home",1000L),
new Event("Bob","./cart",2000L)
);
stream1.print("1");
numStream.print("nums");
stream2.print("2");
stream3.print("3");
env.execute();
}
}这三种方法都是对有界流的处理
1.2.3 从 Socket 读取数据

1.2.4 从 Kafka 读取数据


<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class SourceKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>(
"clicks",
new SimpleStringSchema(),
properties
));
stream.print("Kafka");
env.execute();
}
}

1.2.6 自定义Source

package com.me.chapter05;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Calendar;
import java.util.Random;
public class ClickSource implements SourceFunction<Event> {
//声明一个标志位
private Boolean running=true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔 1 秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
}
package com.me.chapter05;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.Random;
public class SourceCustomTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//这种简单的自定义Source方法只可以指定并行度为1
//DataStreamSource<Event> customStream=env.addSource(new ClickSource());
DataStreamSource<Integer> customStream = env.addSource(new ParallelCustomSource()).setParallelism(2);
customStream.print();
env.execute();
}
//实现自定义的并行SourceFunction,这样可以指定更高的并行度(这里直接用静态类完成,不去重新新建一个类了)
public static class ParallelCustomSource implements ParallelSourceFunction<Integer>{
private Boolean running=true;
private Random random=new Random();
@Override
public void run(SourceContext<Integer> ctx) throws Exception {
while(running){
ctx.collect(random.nextInt());
}
}
@Override
public void cancel() {
}
}
}1.2.7 Flink 支持的数据类型
我们已经了解了 Flink 怎样从不同的来源读取数据。在之前的代码中,我们的数据都是定 义好的 UserBehavior 类型,而且在之前小节中特意说明了对这个类的要求。那还有没有其他 更灵活的类型可以用呢?Flink 支持的数据类型到底有哪些?




1.3 转换算子(Transformation)
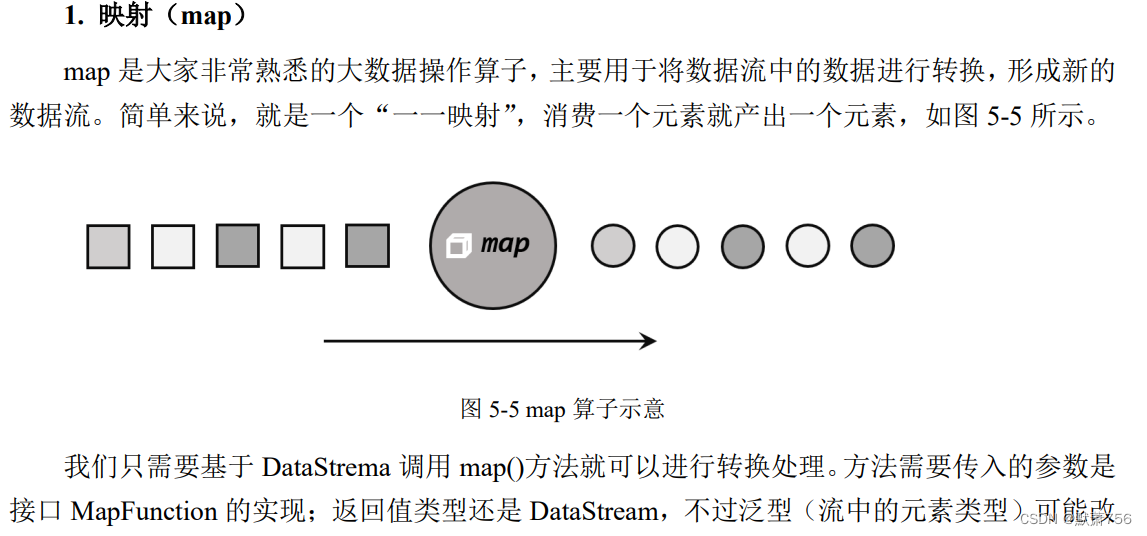
1.3.1 基本转换算子

package com.me.chapter05;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformMapTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
// 传入匿名类,实现 MapFunction
stream.map(new MapFunction<Event, String>() {
@Override
public String map(Event e) throws Exception {
return e.user;
}
});
// 传入 MapFunction 的实现类
stream.map(new UserExtractor()).print();
env.execute();
}
//单独定义的一个静态类
public static class UserExtractor implements MapFunction<Event, String> {
@Override
public String map(Event e) throws Exception {
return e.user;
}
}
}上面代码中,MapFunction 实现类的泛型类型,与输入数据类型和输出数据的类型有关。 在实现 MapFunction 接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还 需要重写一个 map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。
另外,细心的读者通过查看 Flink 源码可以发现,基于 DataStream 调用 map 方法,返回 的其实是一个 SingleOutputStreamOperator。
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper){}
这表示 map 是一个用户可以自定义的转换(transformation)算子,它作用于一条数据流上,转换处理的结果是一个确定的输出类型。当然,SingleOutputStreamOperator 类本身也继承自DataStream 类,所以说 map 是将一个 DataStream 转换成另一个 DataStream 是完全正确的。
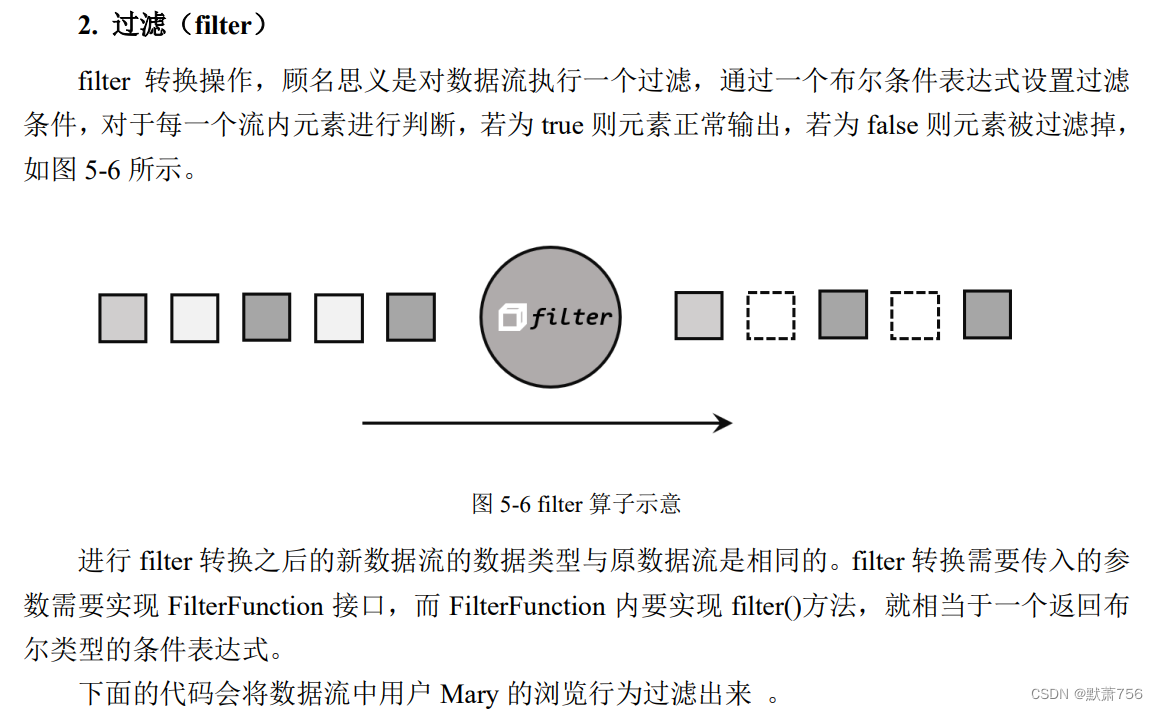
package com.me.chapter05;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformFilterTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
// 传入匿名类实现 FilterFunction
stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
});
// 传入 FilterFunction 实现类
stream.filter(new UserFilter()).print();
env.execute();
}
public static class UserFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
}
}
package com.me.chapter05;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransformFlatMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
stream.flatMap(new MyFlatMap()).print();
env.execute();
}
public static class MyFlatMap implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event value, Collector<String> out) throws Exception
{
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}
}
}1.3.2 聚合算子(Aggregation)

package com.me.chapter05;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformSimpleTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
// 使用 Lambda 表达式
KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);
// 使用匿名类实现 KeySelector
KeyedStream<Event, String> keyedStream1 = stream.keyBy(new KeySelector<Event, String>() {
@Override
public String getKey(Event e) throws Exception {
return e.user;
}
});
env.execute();
}
}

例如,下面就是对元组数据流进行聚合的测试:
package com.me.chapter05;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransTupleAggreationTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 3),
Tuple2.of("b", 3),
Tuple2.of("b", 4)
);
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
env.execute();
}
}而如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
package com.me.chapter05;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransPojoAggregationTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
stream.keyBy(e -> e.user).max("timestamp").print(); // 指定字段名称
env.execute();
}
}


package com.me.chapter05;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 这里的 ClickSource()使用了之前自定义数据源小节中的 ClickSource()
env.addSource(new ClickSource())
// 将 Event 数据类型转换成元组类型
.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event e) throws Exception {
return Tuple2.of(e.user, 1L);
}
})
.keyBy(r -> r.f0) // 使用用户名来进行分流
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1,
Tuple2<String, Long> value2) throws Exception {
// 每到一条数据,用户 pv 的统计值加 1
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
.keyBy(r -> true) // 为每一条数据分配同一个 key,将聚合结果发送到一条流中 去
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1,
Tuple2<String, Long> value2) throws Exception {
// 将累加器更新为当前最大的 pv 统计值,然后向下游发送累加器的值
return value1.f1 > value2.f1 ? value1 : value2;
}
}).print();
env.execute();
}
}
reduce 同简单聚合算子一样,也要针对每一个 key 保存状态。因为状态不会清空,所以我 们需要将 reduce 算子作用在一个有限 key 的流上。
1.3.3 用户自定义函数(UDF)


import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFunctionUDFTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
93
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
DataStream<Event> stream = clicks.filter(new FlinkFilter());
stream.print();
env.execute();
}
public static class FlinkFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event value) throws Exception {
return value.url.contains("home");
}
}
}







import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L)
);
// 将点击事件转换成长整型的时间戳输出
clicks.map(new RichMapFunction<Event, Long>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println(" 索 引 为 " +
getRuntimeContext().getIndexOfThisSubtask() + " 的任务开始");
}
@Override
public Long map(Event value) throws Exception {
return value.timestamp;
98
}
@Override
public void close() throws Exception {
super.close();
System.out.println(" 索 引 为 " +
getRuntimeContext().getIndexOfThisSubtask() + " 的任务结束");
}
})
.print();
env.execute();
}
}

public class MyFlatMap extends RichFlatMapFunction<IN, OUT>> {
@Override
public void open(Configuration configuration) {
// 做一些初始化工作
// 例如建立一个和 MySQL 的连接
}
@Override
public void flatMap(IN in, Collector<OUT out) {
// 对数据库进行读写
}
@Override
public void close() {
// 清理工作,关闭和 MySQL 数据库的连接。
99
}
} 另外,富函数类提供了 getRuntimeContext()方法(我们在本节的第一个例子中使用了一 下),可以获取到运行时上下文的一些信息,例如程序执行的并行度,任务名称,以及状态 (state)。这使得我们可以大大扩展程序的功能,特别是对于状态的操作,使得 Flink 中的算子 具备了处理复杂业务的能力。关于 Flink 中的状态管理和状态编程,我们会在后续章节逐渐展 开。
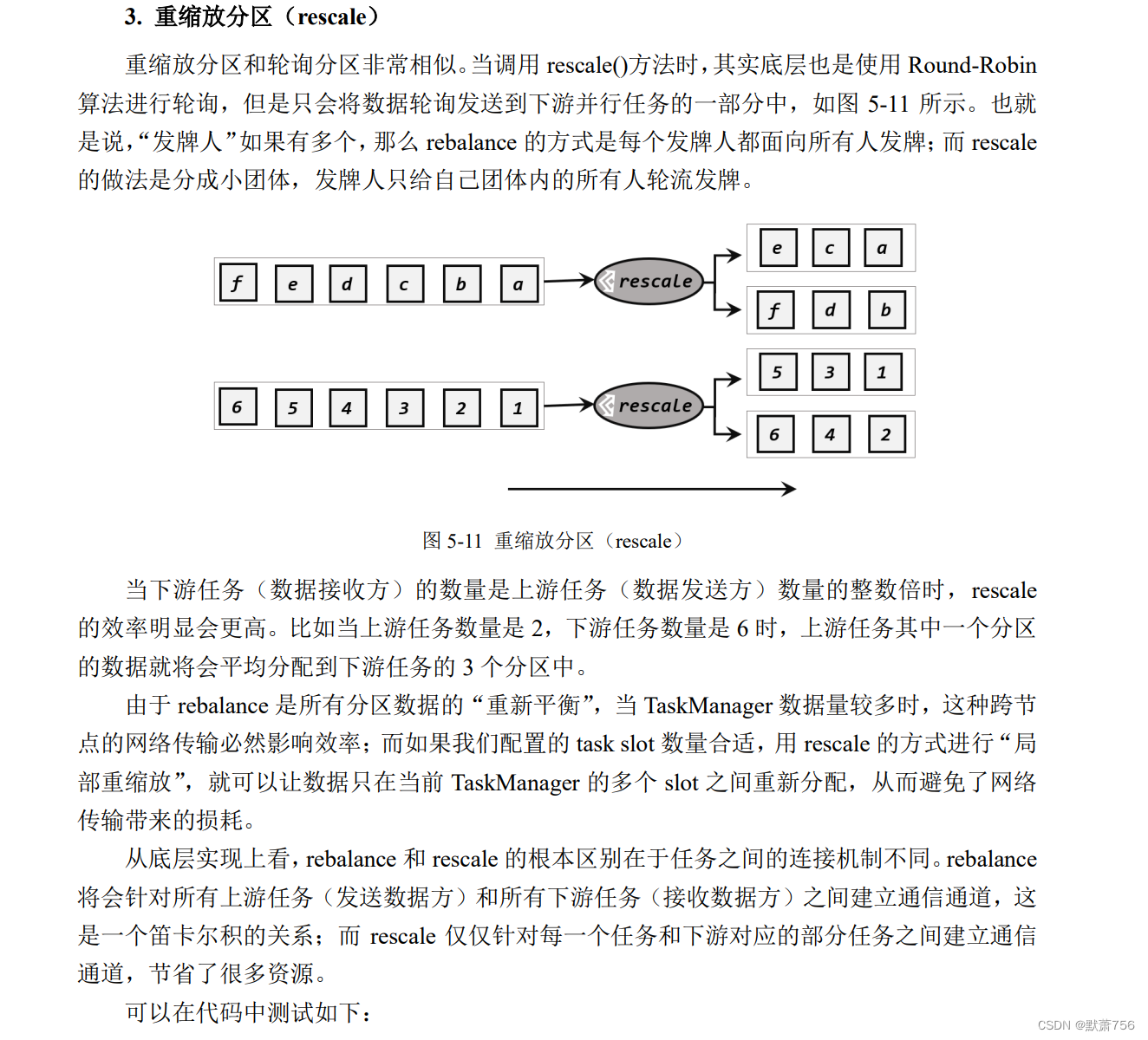
1.3.4 物理分区(Physical Partitioning)

import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class ShuffleTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 经洗牌后打印输出,并行度为 4
stream.shuffle().print("shuffle").setParallelism(4);
env.execute();
}
}
可以得到如下形式的输出结果:
shuffle:1> Event{user='Bob', url='./cart', timestamp=...}
shuffle:4> Event{user='Cary', url='./home', timestamp=...}
shuffle:3> Event{user='Alice', url='./fav', timestamp=...}
shuffle:4> Event{user='Cary', url='./cart', timestamp=...}
shuffle:3> Event{user='Cary', url='./fav', timestamp=...}
shuffle:1> Event{user='Cary', url='./home', timestamp=...}
shuffle:2> Event{user='Mary', url='./home', timestamp=...}
shuffle:1> Event{user='Bob', url='./fav', timestamp=...}
shuffle:2> Event{user='Mary', url='./home', timestamp=...}
... 
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RebalanceTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 经轮询重分区后打印输出,并行度为 4
stream.rebalance().print("rebalance").setParallelism(4);
env.execute();
}
}

import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class RescaleTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 这里使用了并行数据源的富函数版本
// 这样可以调用 getRuntimeContext 方法来获取运行时上下文的一些信息
env
.addSource(new RichParallelSourceFunction<Integer>() {
@Override
public void run(SourceContext<Integer> sourceContext) throws
Exception {
for (int i = 0; i < 8; i++) {
// 将奇数发送到索引为 1 的并行子任务
// 将偶数发送到索引为 0 的并行子任务
if ((i + 1) % 2 ==
getRuntimeContext().getIndexOfThisSubtask()) {
sourceContext.collect(i + 1);
}
}
}
@Override
public void cancel() {
}
})
.setParallelism(2)
.rescale()
.print().setParallelism(4);
env.execute();
}
} 这里使用 rescale 方法,来做数据的分区,输出结果是:
4> 3
3> 1
1> 2
1> 6
3> 5
4> 7
2> 4
2> 8 
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class BroadcastTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 经广播后打印输出,并行度为 4
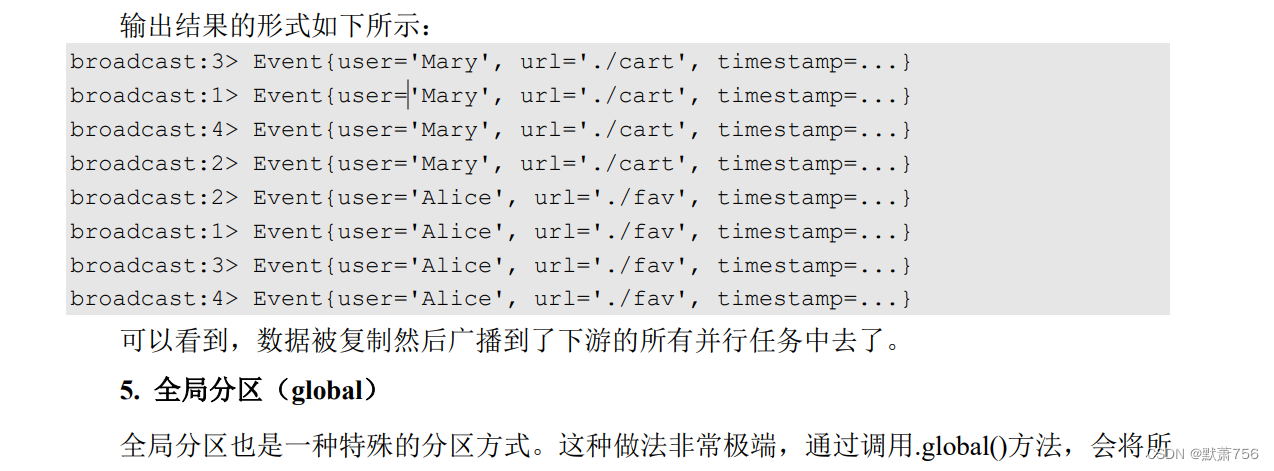
stream. broadcast().print("broadcast").setParallelism(4);
env.execute();
}
}

import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class CustomPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
})
.print().setParallelism(2);
env.execute();
}
}
1.4 输出算子(Sink)
1.4.1 连接到外部系统


1.4.2 输出到文件

import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import
org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.Defa
ultRollingPolicy;
import java.util.concurrent.TimeUnit;
public class SinkToFileTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
109
env.setParallelism(4);
DataStreamSource<Event> stream = env.fromElements(new Event("Mary",
"./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
StreamingFileSink<String> fileSink = StreamingFileSink
.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15)
)
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5
))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
// 将 Event 转换成 String 写入文件
stream.map(Event::toString).addSink(fileSink);
env.execute();
}
}

1.4.3 输出到Kafka
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为 Flink 的输入数据源和输出系统。

import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class SinkToKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");
stream
.addSink(new FlinkKafkaProducer<String>(
"clicks",
new SimpleStringSchema(),
properties
));
env.execute();
}
}

1.4.4 输出到Redis

import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
112
import
org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfi
g;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import
org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescrip
tion;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
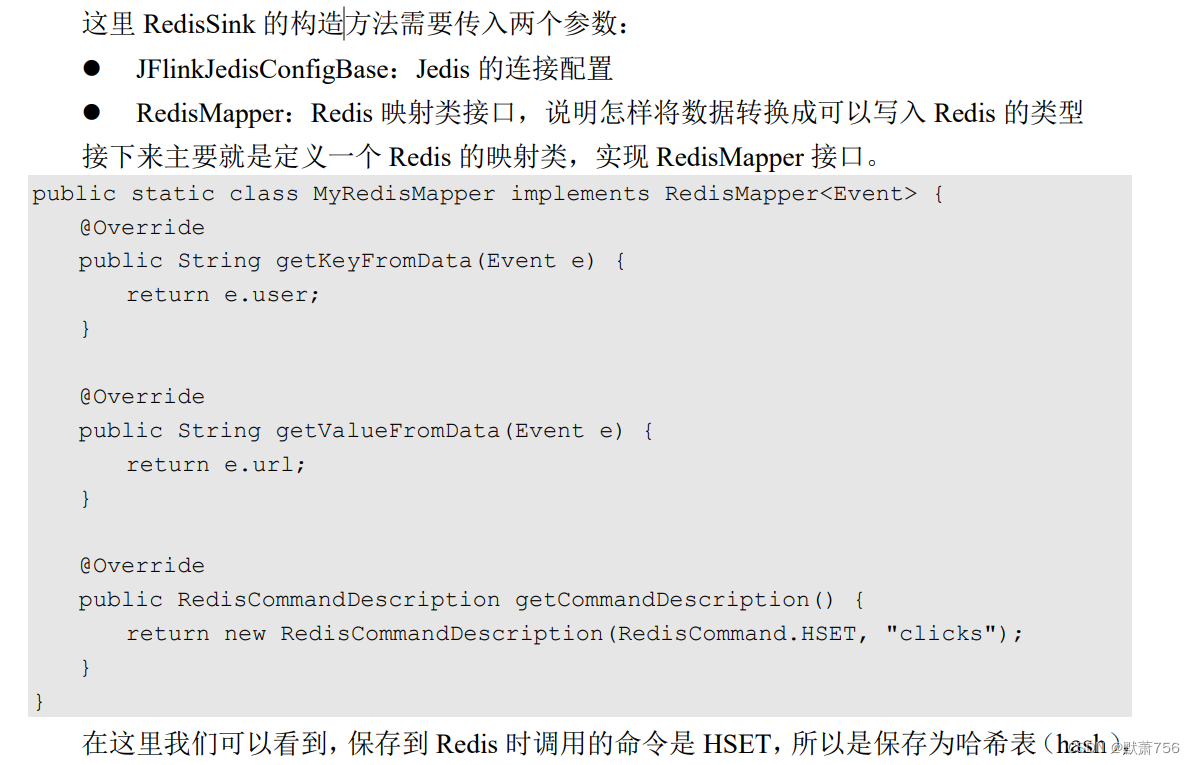
public class SinkToRedisTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 创建一个到 redis 连接的配置
FlinkJedisPoolConfig conf = new
FlinkJedisPoolConfig.Builder().setHost("hadoop102").build();
env.addSource(new ClickSource())
.addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
env.execute();
}
} 

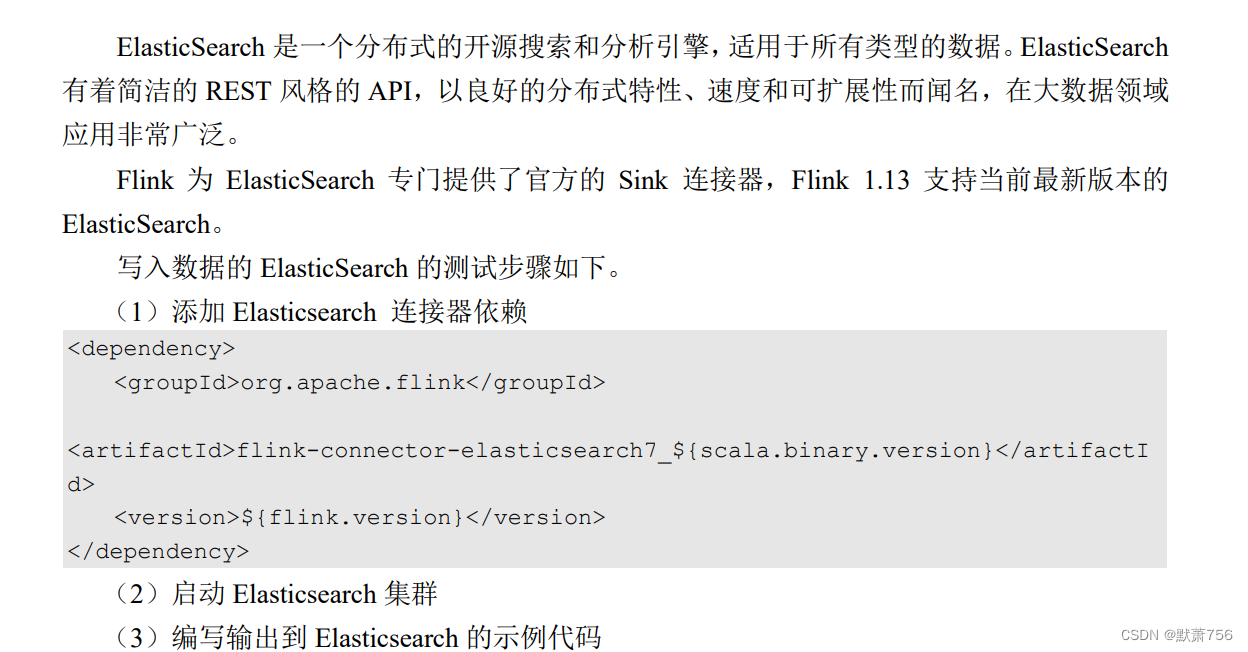
1.3.4 输出到 Elasticsearch
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import
org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction
;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.HashMap;
public class SinkToEsTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
// 创建一个 ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new
ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer
indexer) {
HashMap<String, String> data = new HashMap<>();
data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type") // Es 6 必须定义 type
.source(data);
indexer.add(request);
}
};
stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts,
elasticsearchSinkFunction).build());
env.execute();
}
}

1.4.6 输出到 MySQL(JDBC)

package com.me.chapter05;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinkToMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/userbehavior")
// 对于 MySQL 5.7,用"com.mysql.jdbc.Driver"
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("username")
.withPassword("password")
.build()
)
);
env.execute();
}
}
1.4.7 自定义 Sink 输出

import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import java.nio.charset.StandardCharsets;
public class SinkCustomtoHBase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration
configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径
导入
public Connection connection; // 管理 Hbase 连接
119
@Override
public void open(Configuration parameters) throws
Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102:2181");
connection =
ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws
Exception {
Table table =
connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new
Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写
入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写
入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
}
}
这里要加上Hbase的版本,文档里没有自己要进行相应更改
1.5 本章总结















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









