






hashmap底层实现原理
简介:
HashMap是Java集合框架中非常核心的一部分,其底层实现原理主要基于哈希表,通过哈希函数将键映射到数组的索引位置,以实现快速的插入和查找操作。
数据结构:
HashMap内部维护一个数组,数组中的每个元素都是一个链表或者红黑树。当哈希值相同时,会产生哈希冲突,此时HashMap通过链表或红黑树来存储多个键值对。在JDK 1.8及以后的版本中,当链表长度超过一定阈值(默认为8)时,链表会被转换为红黑树以提高查找效率。当红黑树的节点数少于一定数量(默认为6)时,红黑树会退化为链表以节省内存。
哈希函数:
当向HashMap中插入键值对时,首先通过键的hashCode()方法计算哈希值,然后通过哈希函数将哈希值转换为数组的索引位置。哈希函数的目标是尽可能均匀地分布键值对,以减少哈希冲突的发生。
哈希冲突处理:
如果计算出的索引位置已经有键值对存在,HashMap会通过遍历链表或红黑树来查找是否存在相同的键。如果键已存在,则更新对应的值;如果不存在,则将新的键值对添加到链表或红黑树的末尾。
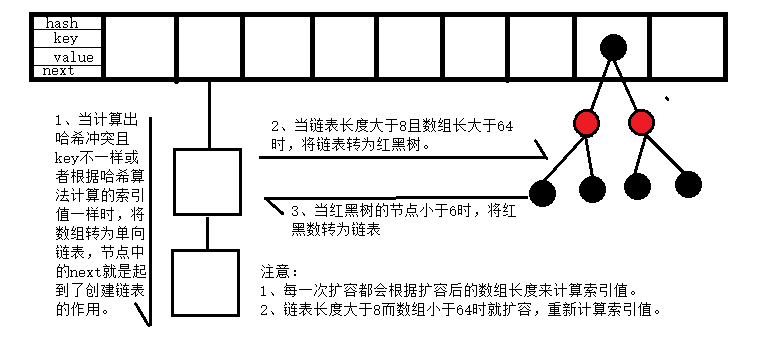
扩容机制:
初始化容量(构造方法中可修改)是:16
当HashMap中的元素数量超过数组的负载因子,默认为0.75,
HashMap会自动进行扩容。扩容时,HashMap会创建一个新的数组,其长度是原数组的两倍,并将原有的键值对重新计算哈希值并映射到新的数组中。
最大容量:2的30次幂
红黑树节点小于6时转为链表
数组大于64且链表值大于阈值时将链表转为红黑树
负载因子大小的利与弊?
- 负载因子过大:负载因子过大,虽然数组的空间利用率会提升,但会数组比较拥挤,碰撞率会变高,导致产生较多的链表甚至红黑树结构,最终导致HashMap的效率低下。
- 负载因子过小:负载因子过小,即数组的使用都还没到总容量的75%时就扩容,碰撞率低且链表变短,数组的空间利用率低,扩容又开辟的内存而浪费资源,而且扩容操作同时也影响运行效率。
实际工程的负载因子确定?
- 负载因子0.75是经过开发者大量的测试得到的一个最佳值,实际中如果没有什么特别的需要可以不改变。
- 负载因子尽可能小:需求链表尽可能少,不考虑内存消耗的问题。
-
- 负载因子尽可能大:需求减少扩容次数,尽量使用完数组内存。
无序性和线程不安全性:
HashMap不保证元素存储的顺序,且在多线程环境下是非线程安全的。如果需要线程安全的HashMap,可以考虑使用Collections.synchronizedMap()方法包装HashMap,或者使用ConcurrentHashMap。
















 4053
4053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











