






实现顺序表部分功能
//定义顺序表类型
//创建顺序表
//判满
//判空
//顺序表添加元素
//遍历顺序表
//任意位置插入元素
//按值进行查找元素
//将顺序表排序,选择排序
//求最值操作
//顺序表逆置
seqlist.h
#ifndef _SEQLIST_H_
#define _SEQLIST_H_
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<assert.h>
#define MAX 40
typedef int datatype;
//定义顺序表类型
typedef struct
{
datatype data[MAX];
int size;
}seqList, *seqList_ptr;
//创建顺序表
seqList_ptr list_create();
//判满
int list_full(seqList_ptr SL);
//判空
int list_empty(seqList_ptr SL);
//顺序表添加元素
int list_add(seqList_ptr SL, datatype element);
//遍历顺序表
int list_traverse(seqList_ptr SL);
//任意位置插入元素
int list_insert(seqList_ptr SL, datatype element, int pos);
//按值进行查找元素
int list_search_value(seqList_ptr SL, datatype element);
//将顺序表排序,选择排序
void list_sort(seqList_ptr SL, int flag);
//求最值操作
datatype list_limit_value(seqList_ptr SL, int flag);
//顺序表逆置
void lis_inverse(seqList_ptr SL);
#endif
seqlist.c
#include"seqlist.h"
//创建顺序表
seqList_ptr list_create()
{
//在堆区申请一个顺序表的空间大小
seqList_ptr SL = (seqList_ptr)malloc(sizeof(seqList));
//判断是否申请成功
assert(SL);
//创建成功后,清空数组和置零
memset(SL->data, 0, sizeof(SL->data));
SL->size = 0;
printf("顺序表创建成功\n");
return SL;
}
//判满
int list_full(seqList_ptr SL)
{
return SL->size == MAX;
}
//判空
int list_empty(seqList_ptr SL)
{
return SL->size == 0;
}
//顺序表添加函数
int list_add(seqList_ptr SL, datatype element)
{
if(list_full(SL))
{
printf("添加失败\n");
return 0;
}
SL->data[SL->size] = element;
SL->size++;
printf("添加成功\n");
return 1;
}
//遍历顺序表
int list_traverse(seqList_ptr SL)
{
assert(SL);
if(list_empty(SL))
{
printf("添加失败\n");
return 0;
}
printf("当前顺序表的元素为:");
for(int i=0; i<SL->size; i++)
{
printf("%d ", SL->data[i]);
}
putchar(10);
}
//任意位置插入元素
int list_insert(seqList_ptr SL, datatype element, int pos)
{
assert(SL);
if(list_full(SL) || pos<0 || pos>SL->size)
{
printf("插入失败\n");
return 0;
}
//从pos位置全体向后移
for(int i=SL->size; i>pos; i--)
{
SL->data[i] = SL->data[i-1];
}
SL->data[pos] = element;
SL->size++;
printf("插入成功\n");
return 1;
}
//按值进行查找元素
int list_search_value(seqList_ptr SL, datatype element)
{
assert(SL);
for(int i=0; i<SL->size; i++)
{
if(element == SL->data[i])
{
printf("该值存在,其位置是数组中的第%d位\n", i);
return 1;
}
}
printf("该值不存在\n");
return 0;
}
//将顺序表排序,选择排序
void list_sort(seqList_ptr SL, int flag)
{
assert(SL);
//flag==0降序
if(flag == 0)
{
for(int i=0; i<SL->size-1; i++)
{
int max = i;
for(int j=i; j<SL->size; j++)
{
if(SL->data[max] < SL->data[j])
{
max = j;
}
}
datatype temp = SL->data[i];
SL->data[i] = SL->data[max];
SL->data[max] = temp;
}
}
//flag==1升序
if(flag == 1)
{
for(int i=0; i<SL->size-1; i++)
{
int min = i;
for(int j=i; j<SL->size; j++)
{
if(SL->data[min] > SL->data[j])
{
min = j;
}
}
datatype temp = SL->data[i];
SL->data[i] = SL->data[min];
SL->data[min] = temp;
}
}
}
//求最值操作
datatype list_limit_value(seqList_ptr SL, int flag)
{
assert(SL);
//flag==0求最小值
if(flag == 0)
{
datatype max = SL->data[0];
for(int i=1; i<SL->size; i++)
{
if(max < SL->data[i])
{
max = SL->data[i];
}
}
return max;
}
//flag==1求最大值
if(flag == 1)
{
datatype min = SL->data[0];
for(int i=1; i<SL->size; i++)
{
if(min < SL->data[i])
{
min = SL->data[i];
}
}
return min;
}
}
//顺序表逆置
void lis_inverse(seqList_ptr SL)
{
assert(SL);
for(int i=0; i<SL->size-1; i++)
{
for(int j=0; j<SL->size-i-1; j++)
{
datatype temp = SL->data[j];
SL->data[j] = SL->data[j+1];
SL->data[j+1] = temp;
}
}
}
main.c
#include"seqlist.h"
int main(int argc, const char *argv[])
{
seqList_ptr SL = list_create();
//检测申请的指针空间是否合法,为空直接结束程序
assert(SL);
//调用添加函数
list_add(SL, 12);
list_add(SL, 45);
list_add(SL, 43);
list_add(SL, 8);
//遍历顺序表
list_traverse(SL);
//插入元素75
list_insert(SL, 75, 3);
//遍历顺序表
list_traverse(SL);
//按值进行查找元素
list_search_value(SL, 12);
list_search_value(SL, 13);
//将顺序表排序
int flag;
printf("将顺序表排序0降序,1升序:");
scanf("%d", &flag);
list_sort(SL, flag);
//遍历顺序表
list_traverse(SL);
//求最值操作
printf("顺序表求最大值输入1,求最小值输出0:");
scanf("%d", &flag);
datatype num = list_limit_value(SL, flag);
printf("最值为%d\n", num);
//逆置顺序表
printf("如果需要逆置顺序表输入1,否则输入0:");
scanf("%d", &flag);
if(flag == 1)
{
lis_inverse(SL);
list_traverse(SL);
}
return 0;
}
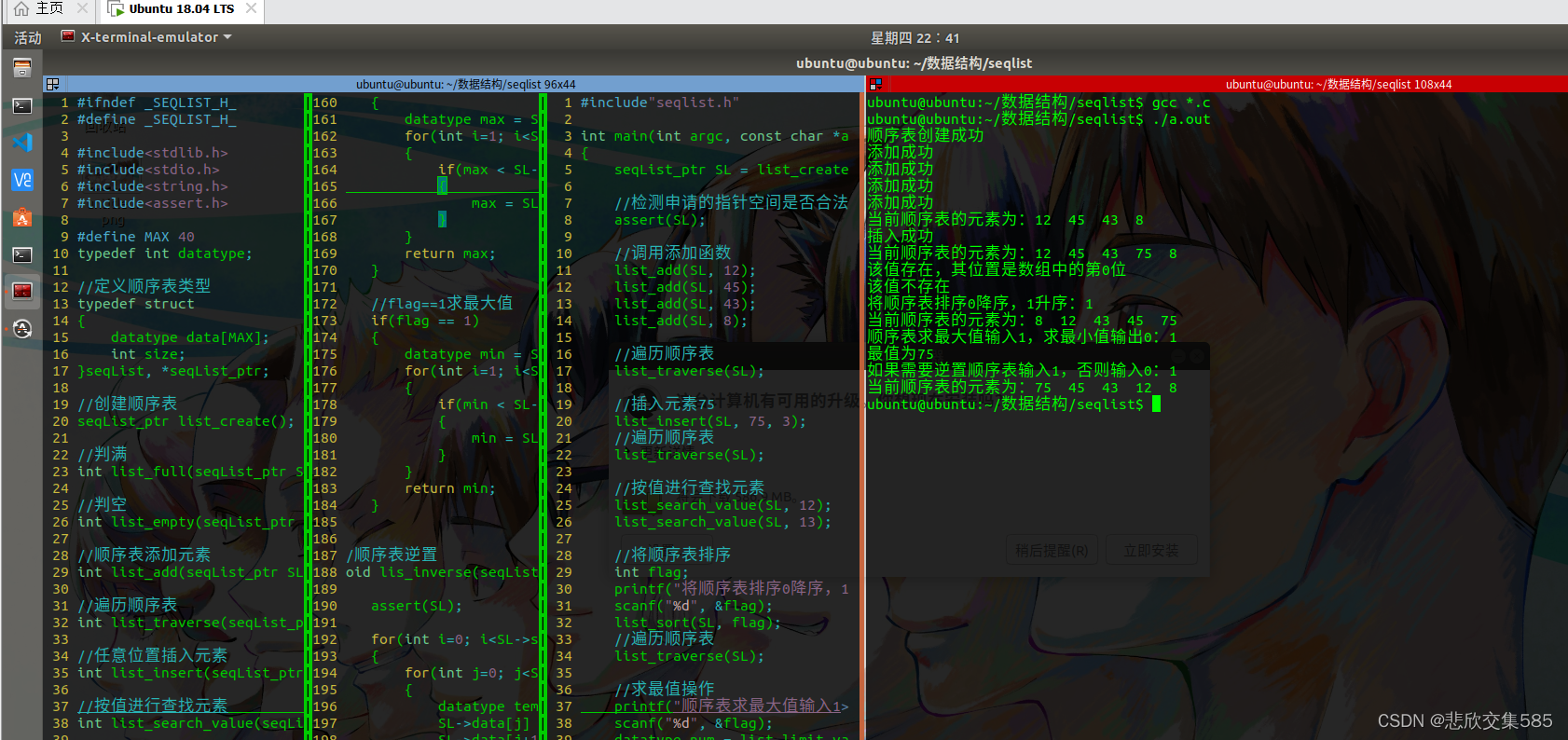
输出结果
C语言中const的用法
在C语言中,const关键字用于定义常量。常量是在程序执行期间不可修改的值。const关键字可以用于变量、函数参数、函数返回类型等。
-
用于变量:
const int NUM = 5; // 定义一个常量NUM,并初始化为5 int main() { const int YEAR = 2022; // 定义一个常量YEAR,并初始化为2022 int var = 10; const int* ptr = &var; // ptr是一个指向常量的指针,指针所指向的值不能通过ptr修改 *ptr = 20; // 错误,不能修改指针所指向的值 var = 20; // 可以修改var的值 return 0; } -
用于函数参数:
void printArray(const int arr[], int size) { // arr是一个指向常量的指针,不能通过arr修改数组的值 for (int i = 0; i < size; i++) { printf("%d ", arr[i]); } } int main() { int arr[] = {1, 2, 3, 4, 5}; printArray(arr, 5); return 0; } -
用于函数返回类型:
const int* getMax(const int* arr, int size) { // 返回一个指向常量的指针,指针所指向的值不能通过指针修改 const int* max = arr; for (int i = 1; i < size; i++) { if (arr[i] > *max) { max = &arr[i]; } } return max; } int main() { int arr[] = {1, 2, 3, 4, 5}; const int* maxPtr = getMax(arr, 5); printf("Max value: %d\n", *maxPtr); return 0; }
总结:const关键字用于定义常量,可以用于变量、函数参数、函数返回类型等。它用来指示编译器该值在程序执行期间不可被修改。
C语言中extern的用法
在C语言中,extern关键字用于声明一个变量或函数,表明该变量或函数是在其他地方定义的。它的主要用途有两个:
-
声明全局变量:当在一个源文件中定义全局变量,而在其他源文件中也需要使用该变量时,可以使用
extern关键字进行声明。这样,在其他源文件中就可以直接使用该全局变量而不需要重新定义它。// File1.c int globalVariable; // 定义全局变量 // File2.c extern int globalVariable; // 声明全局变量在上面的例子中,
File1.c定义了全局变量globalVariable,而File2.c通过extern关键字声明了该全局变量,表示该变量在其他地方定义。这样,File2.c就可以直接使用globalVariable变量了。 -
声明外部函数:当在一个源文件中定义了一个函数,而其他源文件需要调用该函数时,可以使用
extern关键字进行声明。这样,在其他源文件中就可以直接调用该函数而不需要重新定义它。// File1.c void externalFunction(); // 定义外部函数 // File2.c extern void externalFunction(); // 声明外部函数在上面的例子中,
File1.c定义了外部函数externalFunction,而File2.c通过extern关键字声明了该外部函数,表示该函数在其他地方定义。这样,File2.c就可以直接调用externalFunction函数了。
需要注意的是,使用extern关键字声明的变量或函数必须在其他地方定义,否则会导致链接错误。此外,extern关键字只是用于声明,不会分配内存空间,真正的变量或函数定义需要在其他地方进行。
C语言中static的用法
在C语言中,static关键字有多种用法和含义。
-
在函数内部使用static关键字:
- 在函数内部使用static关键字声明的局部变量具有静态存储期,即在函数调用结束后仍然保持其值,而不是被销毁。该变量的作用域仅限于声明它的函数内部。
- 在函数内部使用static关键字声明的静态局部变量只会被初始化一次,在函数调用时不会重新初始化,每次调用都会保留上一次调用的值。
-
在全局作用域使用static关键字:
- 在全局作用域使用static关键字声明的全局变量具有内部链接,即只能在当前源文件内访问,其他源文件无法访问。
- 在全局作用域使用static关键字声明的静态全局变量具有静态存储期,即在程序运行期间一直存在,而不是被销毁。
-
在函数声明中使用static关键字:
- 在函数声明中使用static关键字可以将函数的链接属性设置为内部链接,即只能在当前源文件内访问,其他源文件无法调用该函数。
-
在函数定义中使用static关键字:
- 在函数定义中使用static关键字可以将函数的作用域限制在当前源文件内,其他源文件无法调用该函数。
总的来说,static关键字在C语言中的用法主要有两个方面:静态存储期和链接属性控制。
数据结构的存储结构是什么,分别有哪些
数据结构的存储结构是指数据在计算机内存中的组织方式。常见的数据结构存储结构有以下几种:
- 数组(Array):连续存储结构,数据元素在内存中按照一定的顺序排列。通过下标可以直接访问元素,查找速度快,但插入和删除元素时需要移动其他元素,效率较低。
- 链表(Linked List):离散存储结构,数据元素在内存中通过指针链接起来。插入和删除元素时只需改变指针指向,效率较高,但查找元素时需要遍历链表。
- 栈(Stack):一种特殊的线性表,采用后进先出(LIFO)的存储方式。栈可以用数组或链表实现。
- 队列(Queue):一种特殊的线性表,采用先进先出(FIFO)的存储方式。队列可以用数组或链表实现。
- 树(Tree):非线性数据结构,通过节点和边组成。常见的树结构有二叉树、平衡树、红黑树等。
- 图(Graph):非线性数据结构,由节点和边组成的集合。图可以分为有向图和无向图,常见的图结构有邻接矩阵和邻接表等。
- 哈希表(Hash Table):根据关键字直接访问数据的存储结构。通过哈希函数将关键字映射到哈希表的索引位置,实现快速的查找和插入操作。
除了以上常见的存储结构,还有一些特殊的存储结构,如堆(Heap)、优先队列(Priority Queue)、字典树(Trie)等。不同的存储结构适用于不同的应用场景,选择合适的存储结构可以提高数据操作的效率。
宏函数与函数的区别
宏函数与函数的主要区别如下:
-
执行方式:宏函数是在预处理阶段展开并替换,而函数是在运行时执行。
-
参数传递方式:宏函数的参数传递是通过文本替换实现的,没有参数类型检查和强制转换,而函数的参数传递是通过栈或寄存器传递的,有类型检查和强制转换。
-
可变参数:宏函数可以接受可变数量的参数,而函数需要使用可变参数函数库(如stdarg.h)来实现可变数量的参数。
-
错误检查:函数可以对输入参数进行错误检查和处理,而宏函数没有错误检查机制。
-
作用域:宏函数的作用域是全局的,可以在程序的任何地方使用,而函数的作用域可以根据需要进行限制。
-
可重用性:函数可以在多个地方调用,提高代码的重用性,而宏函数只能在定义的地方展开,不具备重用性。
-
调试:函数可以通过调试工具进行单步调试和查看变量的值,而宏函数在预处理阶段展开,不能进行调试。
综上所述,宏函数和函数在执行方式、参数传递、可变参数、错误检查、作用域、可重用性和调试等方面存在显著的区别。选择使用哪种方式取决于具体的需求和场景。
宏定义与typedef的区别
宏定义和typedef都是C语言中用于定义标识符的关键字,但它们有以下区别:
-
宏定义是在预处理阶段进行处理的,而typedef是在编译阶段进行处理的。宏定义是通过简单的文本替换来定义标识符,而typedef是通过给已有类型起别名来定义标识符。
-
宏定义可以用于定义常量、函数、数据类型等,而typedef只能用于定义数据类型的别名。
-
宏定义可以使用参数,而typedef不能使用参数。
-
宏定义没有作用域的限制,可以在任何地方使用,而typedef的作用域受限于它所在的代码块。
-
宏定义在预处理阶段就会展开,而typedef在编译阶段才会起作用。
总的来说,宏定义更加灵活,可以用于定义常量、函数等,而typedef则更加专注于定义数据类型的别名。在使用时,根据具体的需求和场景选择合适的关键字。














 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









