








目录
认识聚类算法
聚类算法是一种无监督的机器学习算法。 它将一组数据分成若干个不同的群组,使得每个群组内部的数据点相似度高,而不同群组之间的数据点相似度低。常用的相似度计算方法有欧式距离法。
聚类算法在现实生活中的应用
- 用户画像,广告推荐,搜索引擎的流量推荐,恶意流量识别,图像分割,降维,识别
离群点检测。
栗子:按照颗粒度分类
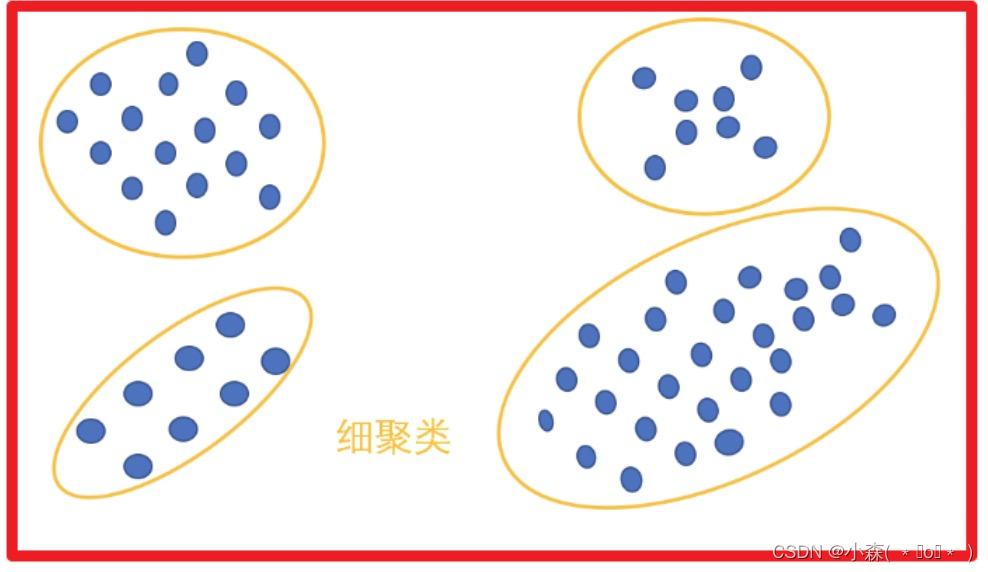 聚类算法分类
聚类算法分类
- K-means聚类:按照质心分类
- 层次聚类:是一种将数据集分层次分割的聚类算法
- DBSCAN聚类是一种基于密度的聚类算法
- 谱聚类是一种基于图论的聚类算法
聚类算法与分类算法最大的区别:
- 聚类算法是无监督的学习算法
- 分类算法属于监督的学习算法
聚类算法API的使用
sklearn.cluster.KMeans(n_clusters=8)
- n_clusters:开始的聚类中心数量整型,缺省值=8,生成的聚类数
- estimator.fit(x)
estimator.predict(x)
estimator.fit_predict(x)
使用KMeans模型数据探索聚类:
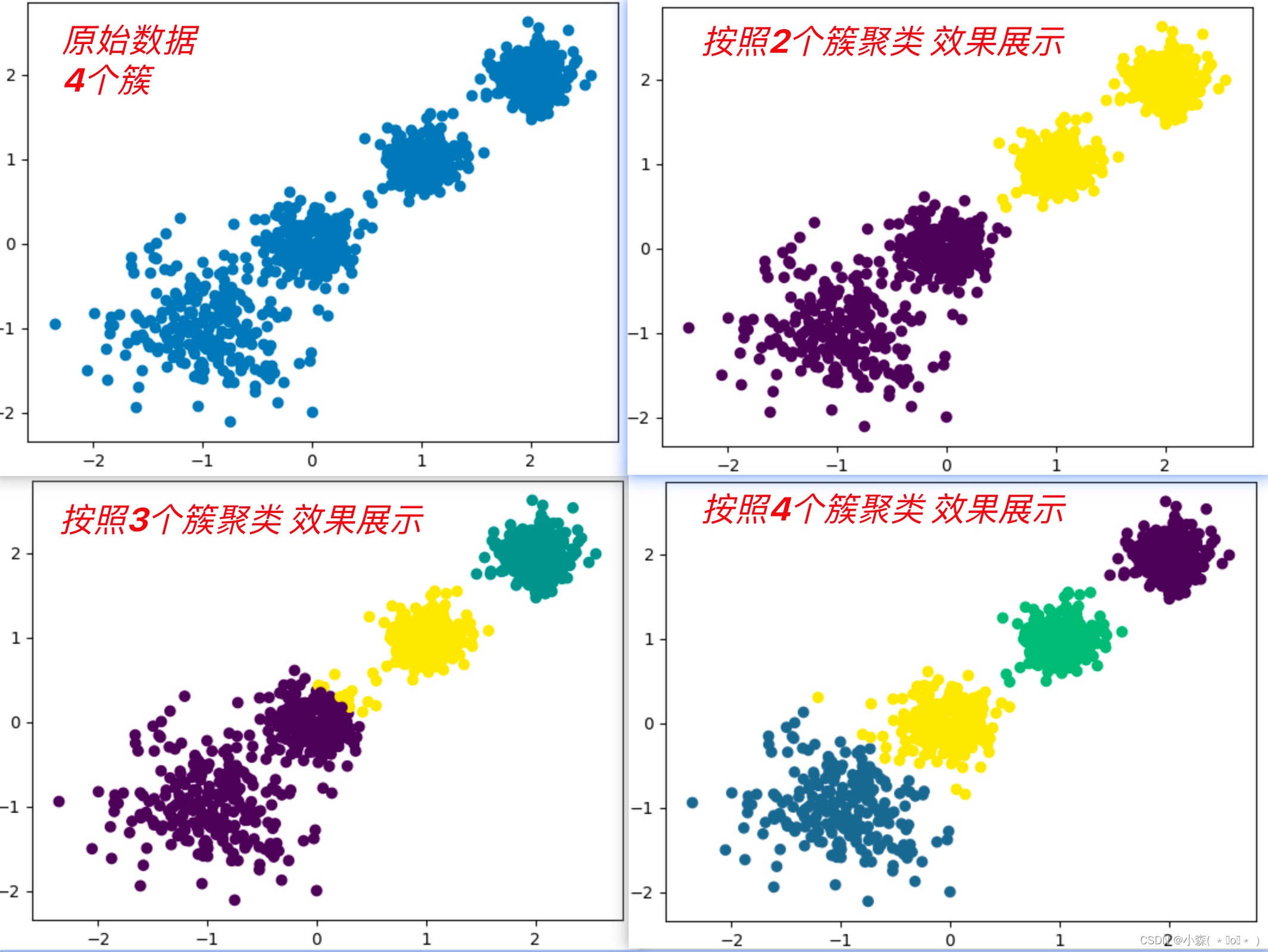
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score
def dm04_kmeans():
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]],
cluster_std = [0.4, 0.2, 0.2, 0.2], random_state=22)
plt.figure()
plt.scatter(x[:, 0], x[:, 1], marker='o')
plt.show()
y_pred = KMeans(n_clusters=2, random_state=22, init='k-means++').fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
print(calinski_harabasz_score(x, y_pred))聚类算法实现流程
- 随机选择 K 个样本点作为初始聚类中心
- 计算每个样本到 K 个中心的距离,选择最近的聚类中心点作为标记类别
- 根据每个类别中的样本点,重新计算出新的聚类中心点(平均值)


- 计算每个样本到质心的距离;离哪个近,就分成什么类别。
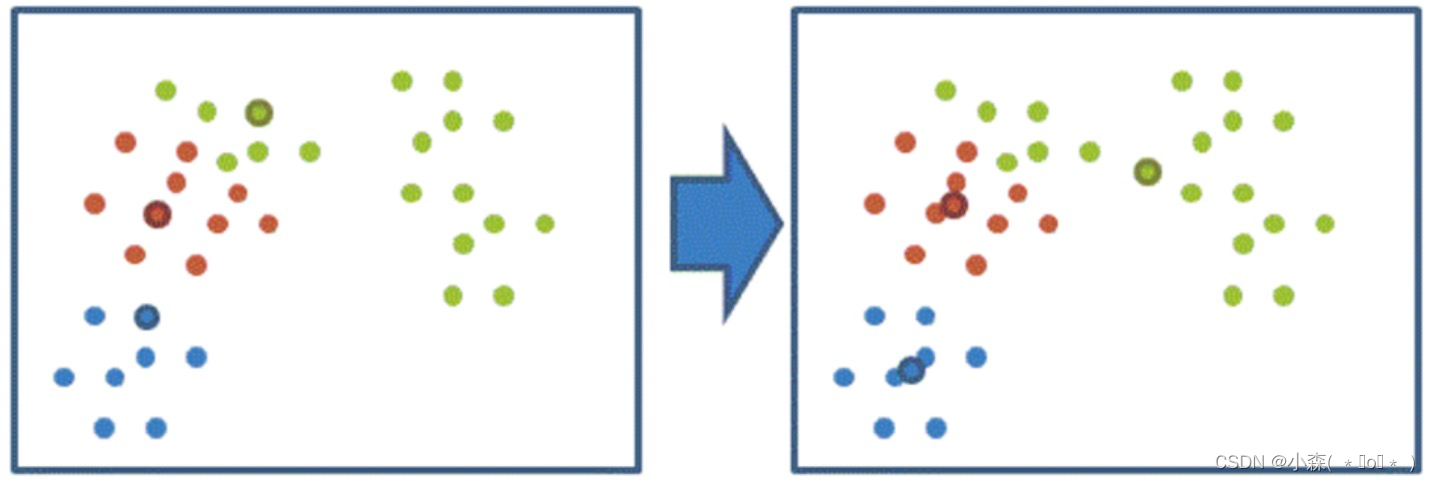 根据每个类别中的样本点,计算出三个质心; 重新计算每个样本到质心的距离,直到质心不在变化
根据每个类别中的样本点,计算出三个质心; 重新计算每个样本到质心的距离,直到质心不在变化
当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入
一直选质心的过程。
聚类算法模型评估
聚类效果评估 – 误差平方和SSE (The sum of squares due to error)
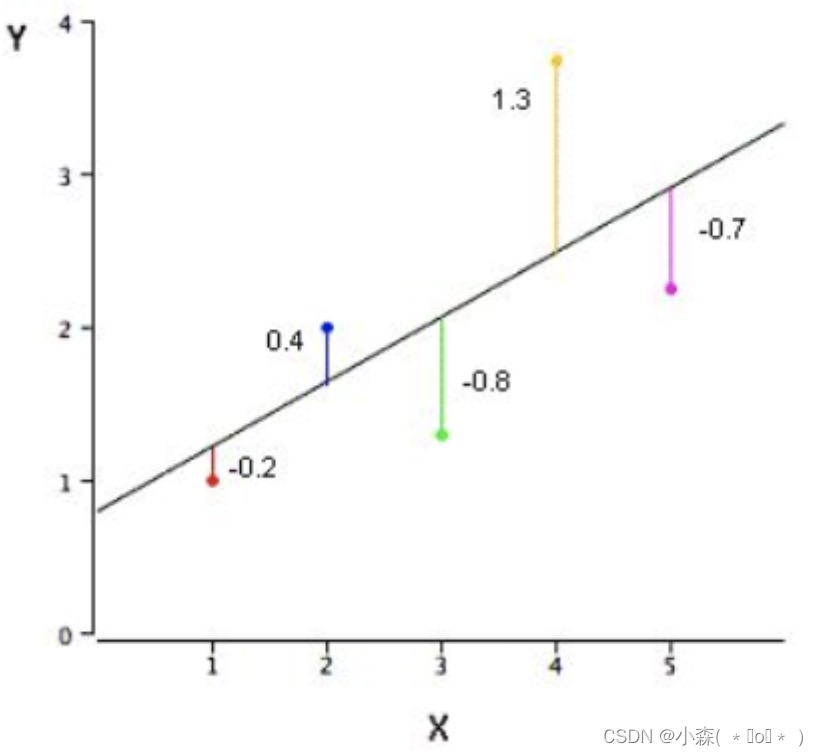
质心的选择会影响图的松散程度:SSE = (−0.2) 2 + (0.4) 2 + (−0.8) 2 + (1.3) 2+ (−0.7) 2 = 3.02
- SSE随着聚类迭代,其值会越来越小,直到最后趋于稳定。
- 如果质心的初始值选择不好,SSE只会达到一个不怎么好的局部最优解
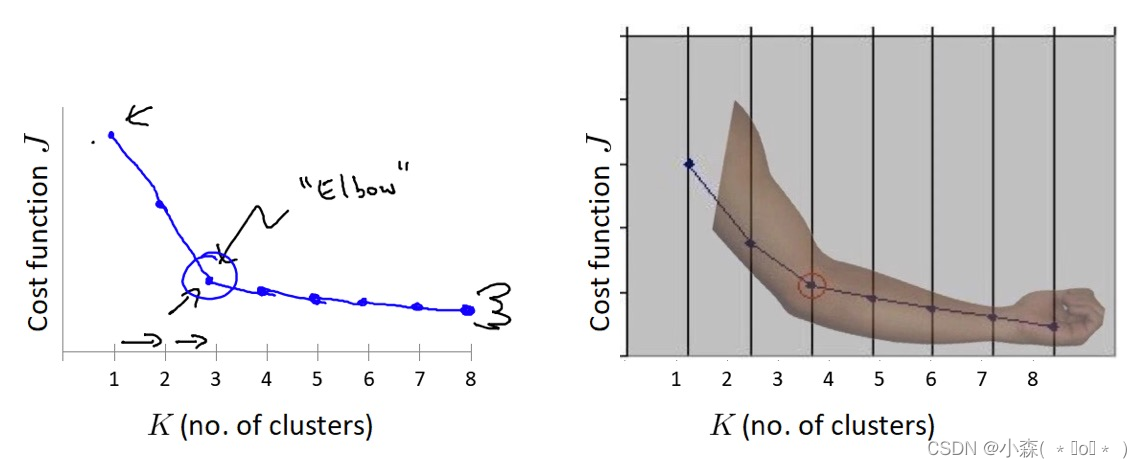
聚类效果评估 – “肘”方法 (Elbow method) - K值确定
- "肘" 方法通过 SSE 确定 n_clusters 的值
对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE,SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
 聚类效果评估 – SC轮廓系数法(Silhouette Coefficient)
聚类效果评估 – SC轮廓系数法(Silhouette Coefficient)
轮廓系数是一种用于评价聚类效果好坏的指标,它结合了聚类的内聚度和分离度。
- 内聚度:反映了一个样本点与其所在簇内其他元素的紧密程度。内聚度是通过计算样本点到同簇其他样本的平均距离来衡量的,这个平均距离称为簇内不相似度。
- 分离度:反映了一个样本点与不属于其簇的其他元素之间的紧密程度。分离度是通过计算样本点到其他簇中所有样本的平均距离中最小的那个值来衡量的,这个最小平均距离称为簇间不相似度。
对计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大。
计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
- 内部距离最小化,外部距离最大化
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











