








梯度下降算法
🔥我们来看一下神经网络中的梯度下降算法🔥
梯度下降法是一种优化算法,用于寻找目标函数的最小值。梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处变化最快的方向。在数学上,梯度就是关于输入的偏导数。

🌟η是学习率,如果学习率设置得太小,可能会导致收敛速度过慢;如果学习率太大,那就有可能直接跳过最优解,导致算法在最小值附近震荡甚至发散。所以,学习率也需要随着训练的进行而变化。
在实际应用中,梯度下降法的初始点是随机选择的,这意味着最终找到的最小值可能取决于初始点的选择。有时候可能需要多次尝试,或者使用不同的初始点来尝试找到更好的最小值。
🌊在进行模型训练时,Epoch、Batch 和 Iteration 是三个基础且重要的概念。🌊
- Epoch 指的是整个数据集通过神经网络的次数。换句话说,当网络看完数据集中的所有图片、文本或其他数据类型一次,就算是完成了一个Epoch。
- Batch 是指将大规模数据划分成小批次数据的过程。每个Batch中包含多个样本,模型会对这些样本进行前向传播和反向传播,计算出参数的梯度并进行更新。Batch的大小,也称为Batch size,决定了每次迭代更新参数的样本数量,对模型收敛速度和效果有一定影响。
- Iteration 指的是模型在一个Batch中更新一次参数的过程。在一个Epoch中,可能需要多个Iteration来遍历完所有的数据。
梯度下降的几种方式:
批量梯度下降(BGD)在每次迭代时使用整个数据集来计算梯度,这意味着它每次更新都考虑了所有样本的信息。这种方法可以更准确地沿着优化方向前进,但是计算速度较慢,且对于大规模数据集来说可能不太实用。
随机梯度下降(SGD)是在每次迭代中随机选择一个样本来计算梯度并更新参数。这种策略使得SGD比BGD快很多,并且可以处理非常大的数据集。然而,由于它是基于单个样本的,所以可能会引入很多噪声,导致优化过程出现波动。
小批量梯度下降(MBGD)是一种折中的方法,它在每次迭代中使用一小部分随机选取的样本来计算梯度。这种方法既利用了一些样本的信息,又保持了较快的计算速度。
实际上,梯度下降的几种方式的根本区别就在于 Batch Size不同
| 梯度下降方式 | 训练次数 | Batch Size | Number of Batches |
| BGD | N | N | 1 |
| SGD | N | 1 | N |
| Mini - Batch | N | B | N / B + 1 |
假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
每个 Epoch 要训练的图片数量:50000 训练集具有的 Batch 个数:50000/256+1=196 每个 Epoch 具有的 Iteration 个数:196 10个 Epoch 具有的 Iteration 个数:1960
import numpy as np
def gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
J_history = np.zeros(num_iters)
for i in range(num_iters):
h = np.dot(X, theta)
loss = h - y
gradient = np.dot(X.T, loss) / m
theta = theta - alpha * gradient
J_history[i] = np.sum(loss ** 2) / (2 * m)
return theta, J_history
# 示例数据
X = np.array([[1, 2], [1, 3], [1, 4], [1, 5]])
y = np.array([3, 4, 5, 6])
theta = np.array([0, 0])
alpha = 0.01
num_iters = 1000
# 调用梯度下降函数
theta, J_history = gradient_descent(X, y, theta, alpha, num_iters)
print("Theta:", theta)
print("Loss history:", J_history)前向和反向传播
利用反向传播算法对神经网络进行训练。与梯度下降算法相结合,对网络中所有权重(w,b)计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。
前向传播是神经网络中用于计算预测输出的过程。在训练过程中,输入数据被送入网络,然后通过每一层进行传递,直到得到最终的预测输出。
最后一层神经元的输出作为网络的预测结果。 前向传播的目的是计算给定输入数据时网络的预测输出,以便在后续的训练过程中与实际目标值进行比较,并计算损失。
链式法则是微积分中一个重要的概念,用于计算复合函数的导数。在神经网络中,链式法则用于反向传播算法(Backpropagation),该算法用于计算损失函数相对于网络权重的梯度。
反向传播算法是利用链式法则进行梯度求解及权重更新的。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。
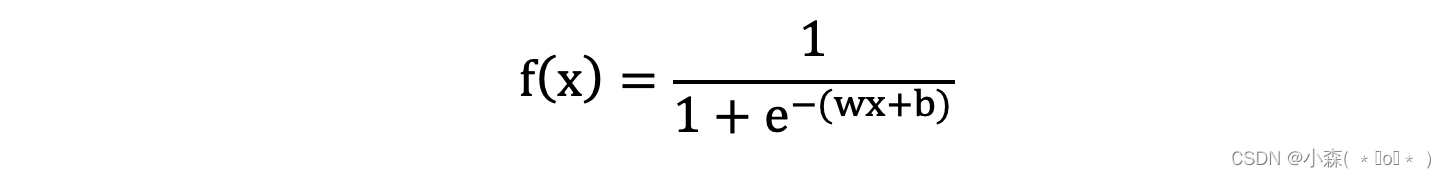
具体来说,链式法则允许我们将损失函数相对于网络输出的导数分解为多个部分,每个部分对应于网络中的一层。其参数为权重 w、b。我们需要求关于 w 和 b 的偏导,然后应用梯度下降公式就可以更新参数。
以w为例,当 𝑥 = 1, 𝑤 = 0, 𝑏 = 0 时,可以得到f(𝑥 ) = 0.25
sigmoid函数的导数计算:
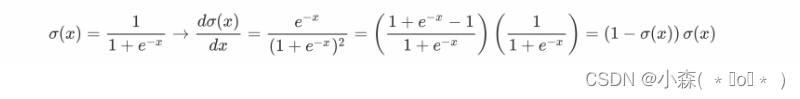















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











