







特征缩放
因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度下降算法中,代价函数为最小平方误差函数,所以在使用梯度下降算法的时候,算法会明显的偏向于第二个特征,因为它的取值范围更大。在比如,k近邻算法,它使用的是欧式距离,也会导致其偏向于第二个特征。对于决策树和随机森林以及XGboost算法而言,特征缩放对于它们没有什么影响。
常用的特征缩放算法有两种,归一化(normalization)和标准化(standardization)。归一化算法是通过特征的最大最小值将特征缩放到[0,1]区间范围
归一化(Normalization)
归一化是利用特征的最大最小值,为了方便数据处理,将特征的值缩放到[0,1]区间,对于每一列的特征使用min-max函数进行缩放,可以使处理过程更加便捷、快速,计算。
特征归一化的优势
- 提升收敛速度 :对于线性model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
造成图像的等高线为类似椭圆形状,最优解的寻优过程图像如下:
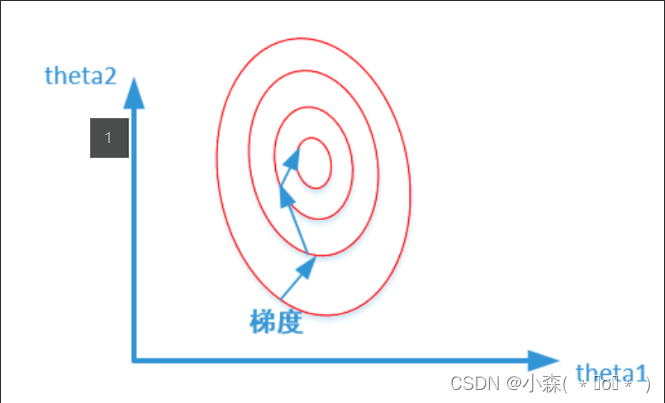
两个特征区别相差特别大。所形成的等高线比较尖锐。当时用梯度下降法时,很可能要垂直等高线走,需要很多次迭代才能收敛。
而数据归一化之后,损失函数的表达式可以表示为:
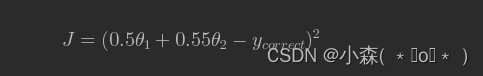
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程图像如下:
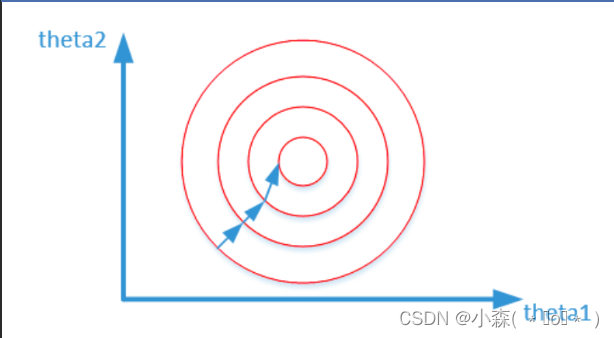
-
对两个原始特征进行了归一化处理,其对应的等高线相对来说比较圆,在梯度下降时,可以较快的收敛。 - 提升模型精度:如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。 从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
特征归一化方法MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
min_max_scaler = MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(x)#归一化后的结果
X_train_minmax
# 它默认将每种特征的值都归一化到[0,1]之间MinMaxScaler的实现
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min这是向量化的表达方式,说明X是矩阵,其中
- X_std:将X归一化到[0,1]之间
- X.min(axis=0)表示列最小值
- max,min表示MinMaxScaler的参数feature_range参数。即最终结果的大小范围
以下例说明计算过程(max=1,min=0)
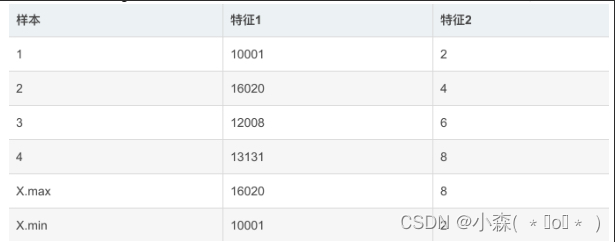
S11=(10001-10001)/(16020-10001)=0
S21=(16020-10001)/(16020-10001)=1
S31=(12008-10001)/(16020-10001)=0.333444
S41=(13131-10001)/(16020-10001)=0.52002
S12=(2-2)/(8-2)=0
S22=(4-2)/(8-2)=0.33
S32=(6-2)/(8-2)=0.6667
S42=(8-2)/(8-2)=1数据的标准化
和0-1标准化不同,Z-score标准化利用原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。同样是逐列进行操作,每一条数据都减去当前列的均值再除以当前列的标准差,在这种标准化操作下,如果原数据服从正态分布,处理之后的数据服从标准正态分布。Z-Score标准化计算公式如下:

我们也可通过如下方式对张量进行Z-Score标准化处理。
from sklearn.preprocessing import StandardScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
ss = StandardScaler()
X_train = ss.fit_transform(x)
X_train
array([[-1.2817325 , -1.34164079],
[ 1.48440157, -0.4472136 ],
[-0.35938143, 0.4472136 ],
[ 0.15671236, 1.34164079]])和0-1标准化不同,Z-Score标准化并不会将数据放缩在0-1之间,而是均匀地分布在0的两侧
特征编码
我们拿到的数据通常比较脏乱,特征变量除了数值外可能还会包括带有各种非数字特殊符号等特征值,比如中文。但一般的机器学习模型一般都是处理数值型的特征值,因此需要将一些非数值的特殊特征值转为为数值,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我们都需要对其进行相应的编码,也是量化的过程,这就要用到特征编码。
编码方法
- LabelEncoder :适合处理字符型数据或label类,一般先用此方法将字符型数据转换为数值型,然后再用以下两种方法编码;
- get_dummies :pandas 方法,处理DataFrame 数据更便捷
- OneHotEncoder :更普遍的编码方法
LabelEncoder🏖️
label-encoding就是用标签进行编码的意思,即我们给特征变量自定义数字标签,量化特征。
将离散的数值或字符串,转化为连续的数值型数据。n个类别就用0到n-1个数表示。没有扩维,多用于标签列的编码(如果用于特征的编码,那编码后还要用get_dummies或OneHotEncoder进行再编码,才能实现扩维)。
import pandas as pd
Class=['大一','大二','大三','大四']
df = pd.DataFrame({'Class':Class})
classMap = {'大一':1,'大二':2,'大三':3,'大四':4}
df['Class'] = df['Class'].map(classMap)
上面就将Class特征进行相应的编码。其实,Label encoding并没有任何限制,你也可以将Class定义为10,20,30,40,只不过1,2,3,4看起来比较方便。因此总结概括,Label encoding就是将原始特征值编码为自定义的数字标签完成量化编码过程。
get_dummies🏖️
pandas编码工具,直接将数据扩维
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)import pandas as pd
# 创建一个包含分类变量的 DataFrame
data = {'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']}
df = pd.DataFrame(data)
print("原始 DataFrame:")
print(df)
# 使用 get_dummies 进行独热编码
df_dummies = pd.get_dummies(df)
print("\n独热编码后的 DataFrame:")
print(df_dummies)
原始 DataFrame:
Color
0 Red
1 Blue
2 Green
3 Red
4 Blue
独热编码后的 DataFrame:
Color_Blue Color_Green Color_Red
0 0 0 1
1 1 0 0
2 0 1 0
3 0 0 1
4 1 0 0
同时在pandas可以指定 columns参数,pd.get_dummies(df,columns=[“length”,“size”])指定被编码的列,返回被编码的列和不被编码的列
df_4 =pd.get_dummies(df,columns=["length","size"])OneHotEncoder🏖️
当然,除了自然顺序编码外,常见的对离散变量的编码方式还有独热编码,独热编码的过程如下
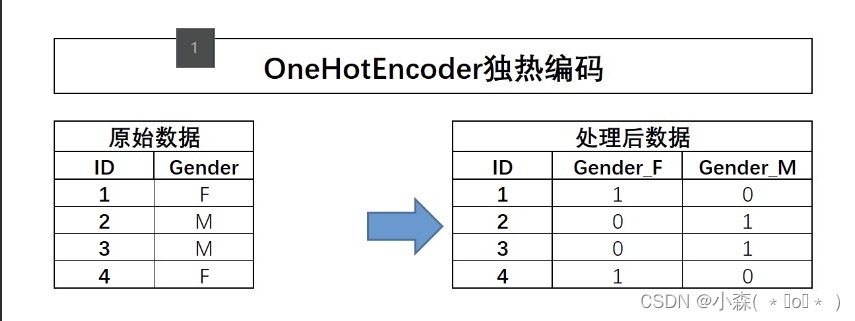
不难发现,独热编码过程其实和我们此前介绍的哑变量创建过程一致(至少在sklearn中并无差别)。对于独热编码的过程,我们可以通过pd.get_dummies函数实现,也可以通过sklearn中OneHotEncoder评估器(转化器)来实现。
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# 假设我们有一些分类数据
categories = np.array(['cat', 'dog', 'fish', 'cat', 'dog', 'bird']).reshape(-1, 1)
# 创建 OneHotEncoder 实例
encoder = OneHotEncoder(sparse=False)
# 使用数据拟合编码器并转换数据
onehot = encoder.fit_transform(categories)
# 输出独热编码的结果
print(onehot)
# 输出编码器的类别
print(encoder.categories_)
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
[0. 0. 0.]]
[array(['bird', 'cat', 'dog', 'fish'], dtype=object)]
对于独热编码的使用,有一点是额外需要注意的,那就是对于二分类离散变量来说,独热编码往往是没有实际作用的。例如对于上述极简数据集而言,Gender的取值是能是M或者F,独热编码转化后,某行Gender_F取值为1、则Gender_M取值必然为0,反之亦然。因此很多时候我们在进行独热编码转化的时候会考虑只对多分类离散变量进行转化,而保留二分类离散变量的原始取值。此时就需要将OneHotEncoder中drop参数调整为’if_binary’,以表示跳过二分类离散变量列
sklearn中逻辑回归的参数解释
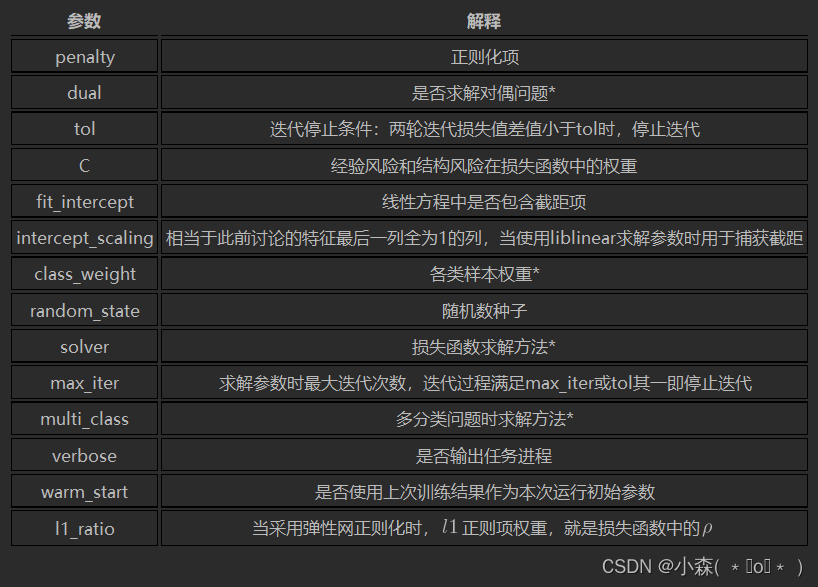
- C 惩罚系数
- penalty 正则化项
相比原始损失函数,正则化后的损失函数有两处发生了变化,其一是在原损失函数基础上乘以了系数C,其二则是加入了正则化项。其中系数C也是超参数,需要人工输入,用于调整经验风险部分和结构风险部分的权重,C越大,经验风险部分权重越大,反之结构风险部分权重越大。此外,在L2正则化时,采用的表达式,其实相当于是各参数的平方和除以2,在求最小值时本质上和w的2-范数起到的作用相同,省去开平方是为了简化运算,而除以2则是为了方便后续求导运算,和2次方结果相消。
其实除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,而选择损失函数的参数,就是solver参数。
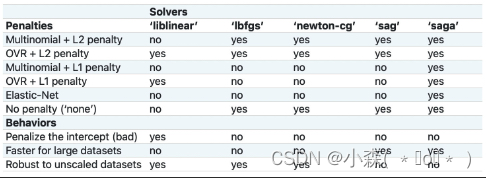
逻辑回归可选的优化方法包括:
- liblinear,这是一种坐标轴下降法,并且该软件包中大多数算法都有C++编写,运行速度很快,支持OVR+L1或OVR+L2;
- lbfgs,全称是L-BFGS,牛顿法的一种改进算法(一种拟牛顿法),适用于小型数据集,并且支持MVM+L2、OVR+L2以及不带惩罚项的情况;
- newton-cg,同样也是一种拟牛顿法,和lbfgs适用情况相同;
- sag,随机平均梯度下降,随机梯度下降的改进版,类似动量法,会在下一轮随机梯度下降开始之前保留一些上一轮的梯度,从而为整个迭代过程增加惯性,除了不支持L1正则化的损失函数求解以外(包括弹性网正则化)其他所有损失函数的求解;
- saga,sag的改进版,修改了梯度惯性的计算方法,使得其支持所有情况下逻辑回归的损失函数求解;
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
data = pd.read_csv("creditcard2.csv")
from sklearn.preprocessing import MinMaxScaler
data['normAmount'] = MinMaxScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
X = data.iloc[:, data.columns != 'Class'].values
y = data.iloc[:, data.columns == 'Class']['Class'].values
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 114)
def kflod_scores(X,y):
fold = KFold(5,shuffle=False)
c_param_range = [0.01, 0.1, 1]
show_result = pd.DataFrame()
recalls = []
cv = KFold(n_splits=5, shuffle=True, random_state=114)
for c_param in c_param_range:
lr_model = LogisticRegression(C=c_param, penalty="l2")
print('-------------------------------------------')
print('正则化惩罚力度: ', c_param)
print('-------------------------------------------')
print('')
result = cross_validate(
lr_model
, X
, y
, cv=cv
, scoring="recall"
, verbose=True
, n_jobs=-1
)
print(result["test_score"])
recalls.append(np.mean(result["test_score"]))
show_result["c_param"] = list(c_param_range)
show_result["recall"] = recalls
return show_result
kflod_scores(X_train,y_train)刚刚进行的建模存在一些问题:
(1).过程不够严谨,诸如测试集中测试结果不能指导建模、参数选取及搜索区间选取没有理论依据等问题仍然存在;
(2).执行效率太低,如果面对更多的参数(这是更一般的情况),手动执行过程效率太低,无法进行超大规模的参数挑选;
(3).结果不够精确,一次建模结果本身可信度其实并不高,我们很难证明上述挑选出来的参数就一定在未来数据预测中拥有较高准确率。
网格搜索
sklearn中最常用的搜索策略就是使用GridSearchCV进行全搜索,即对参数空间内的所有参数进行搜索.
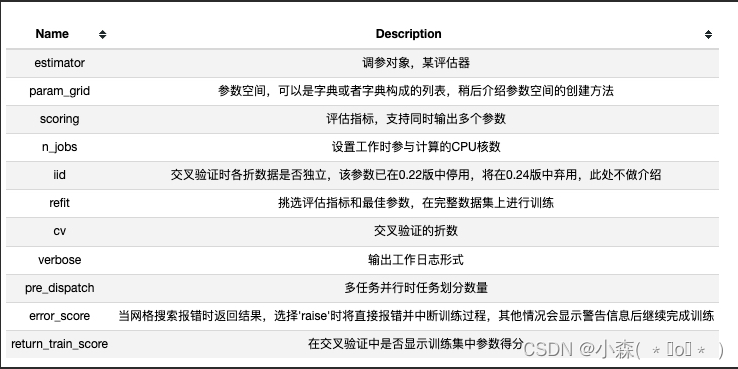
from sklearn.model_selection import GridSearchCVGridSearchCV它的参数主要如下
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=114)
param_grid_simple = {'penalty': ['l1', 'l2'],
'C': [1, 0.5, 0.1, 0.05, 0.01]}
search = GridSearchCV(estimator=lgr,
param_grid=param_grid_simple)
search.fit(X_train, y_train)
search.best_estimator_
# 训练完成后的最佳评估器
search.best_estimator_.coef_
# 逻辑回归评估器的所有属性
search.best_score_
# 0.9727272727272727
在默认情况下(未修改网格搜索评估器中评估指标参数时),此处的score就是准确率。此处有两点需要注意:
- 其一:该指标和训练集上整体准确率不同,该指标是交叉验证时验证集准确率的平均值,而不是所有数据的准确率;
- 其二:该指标是网格搜索在进行参数挑选时的参照依据。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











