







在网上找了很多攻略,安装完总是出现各种问题,耗时两天终于解决了,安装方法如下。
一.打开Anaconda promopt
# 打开Anaconda promopt后进入你要安装的虚拟环境,<your env>替换为你的环境名
# 我的环境名为ml,那么我的命令就是conda activate ml
conda activate <your env>
# 安装nltk,注意这里安装的nltk资源并不完全
pip install nltk
# 可以在vscode中尝试导入这些包,但是你会发现直接导入并不能使用,因为这些还没下载
'''
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk.corpora import stopwords
'''
二.打开GitHub官网,下载压缩包
链接如下(需要使用科学上网,下载速度很快):nltk/nltk_data: NLTK Data (github.com) https://github.com/nltk/nltk_data
https://github.com/nltk/nltk_data
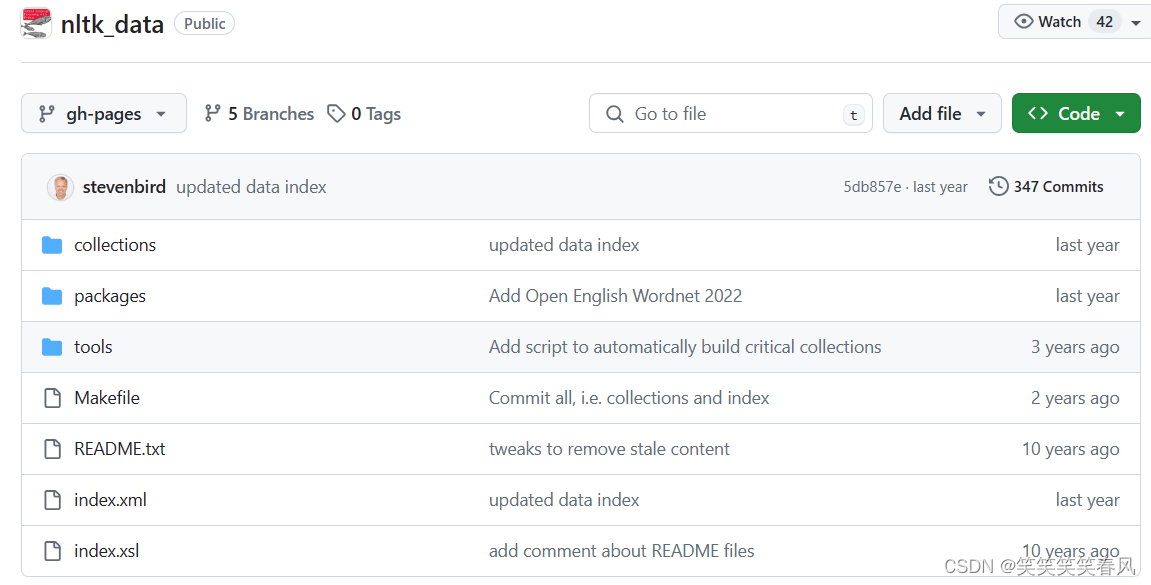
点击Code右边的倒三角
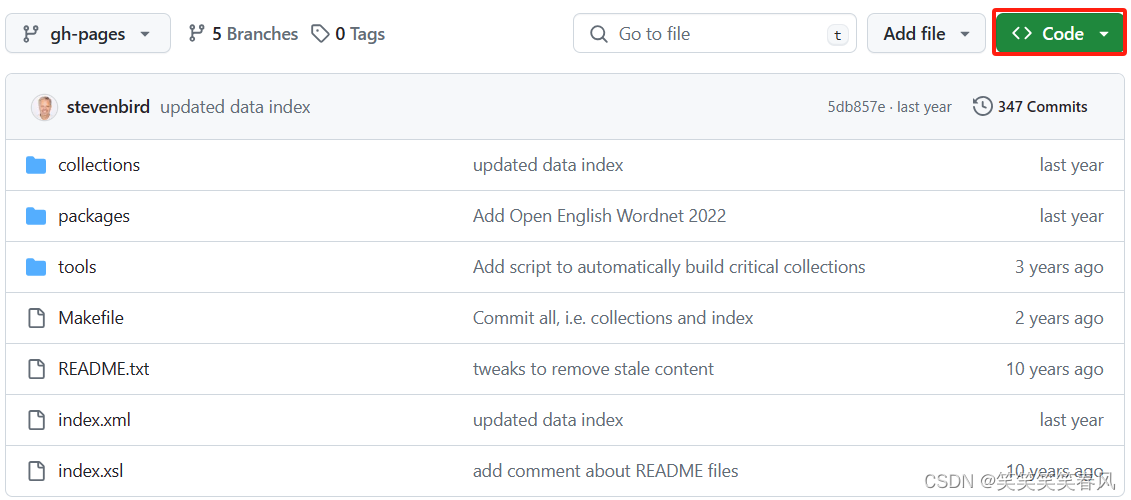
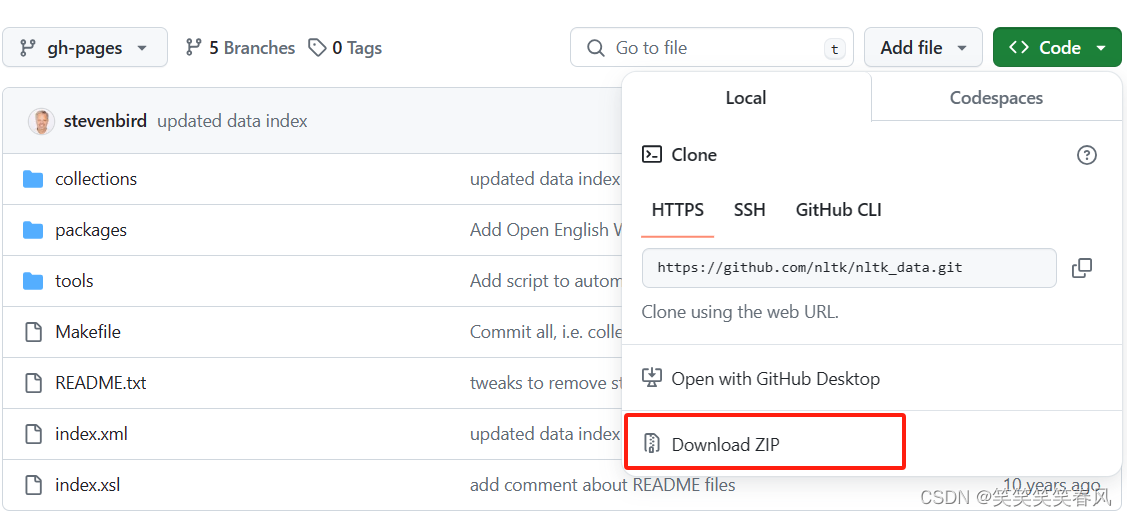
点击Download ZIP进行下载,大小约为700MB

下载完成后将压缩包剪切到需要存放的conda虚拟环境中
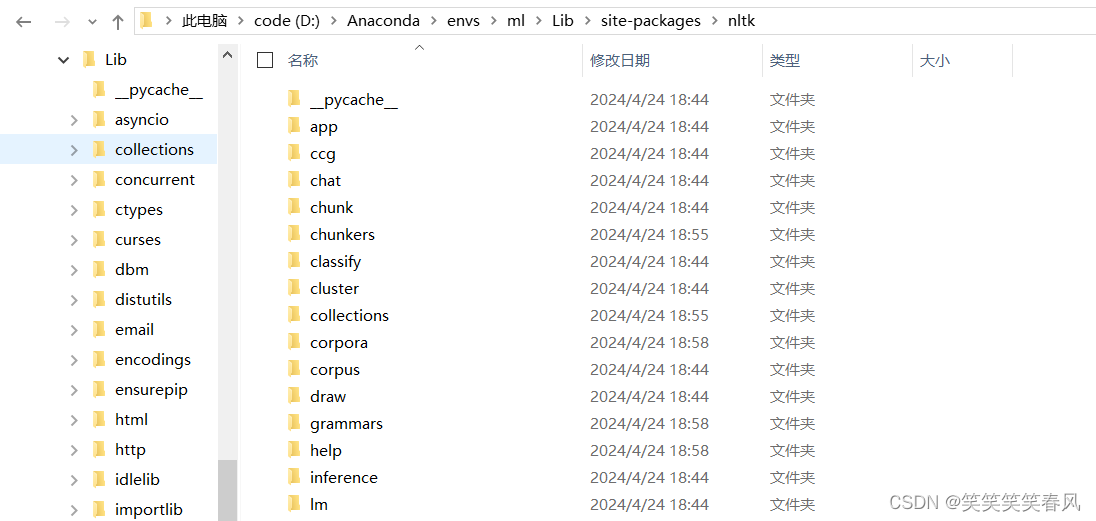
我的Anaconda安装在D盘,环境名叫做ml,大家也进入自己相应的路径即可,如果第一步顺利完成了,就能找到nltk文件夹。由于我nltk的资源已经全都安装好了,所以我这里文件比较多,正常来说这里文件夹不是很多。
三.解压至当前文件夹
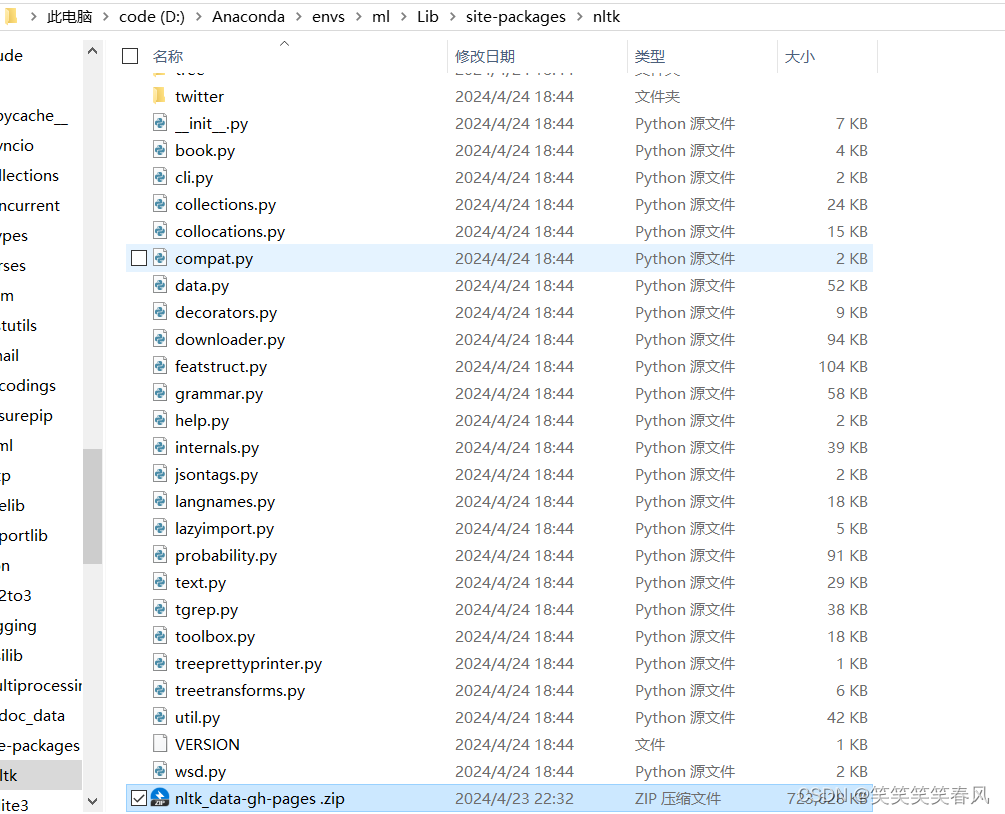
找到解压后的文件夹,双击进入
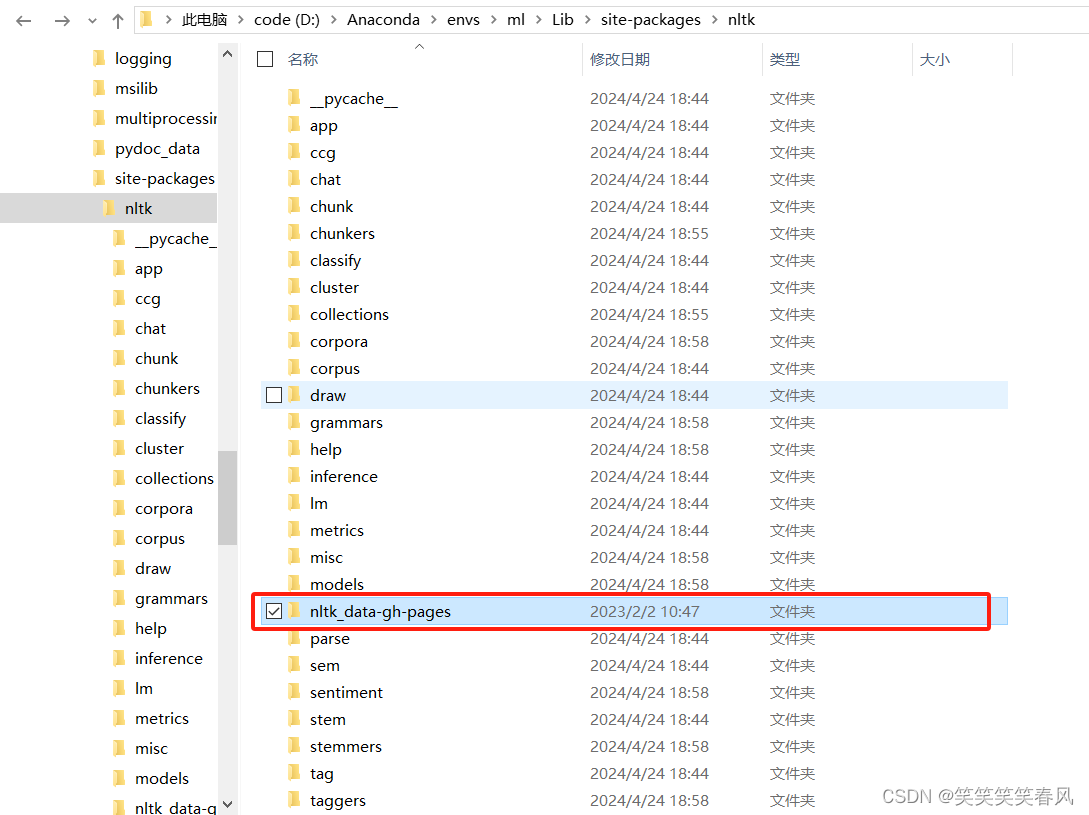
点开packages

此时packages文件夹中还有很多文件夹,依次进入每个文件夹,并解压其中的所有压缩包

这里以chunkers为例,解压


当所有压缩包解压完后,回到packages文件夹中
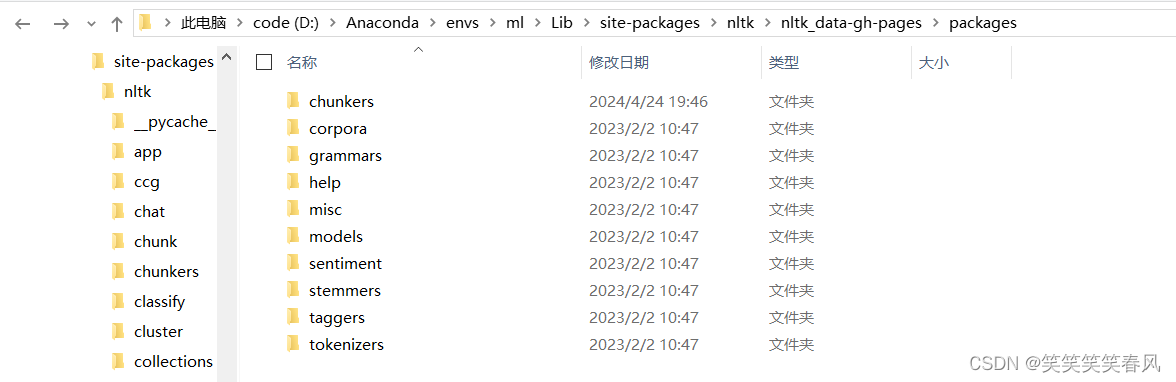
选中所有文件夹,进行Ctrl+C,复制
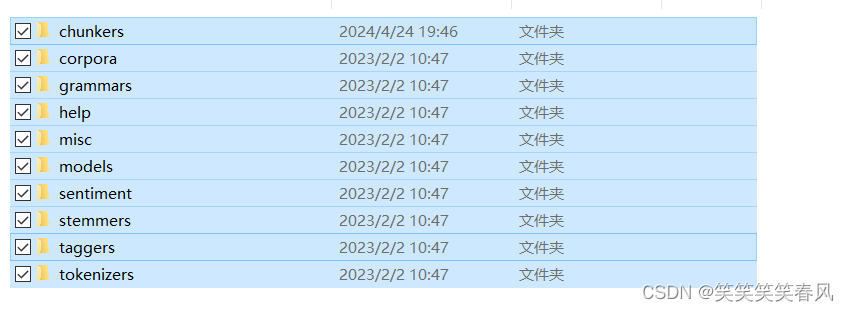
复制完后回到nltk文件夹中粘贴
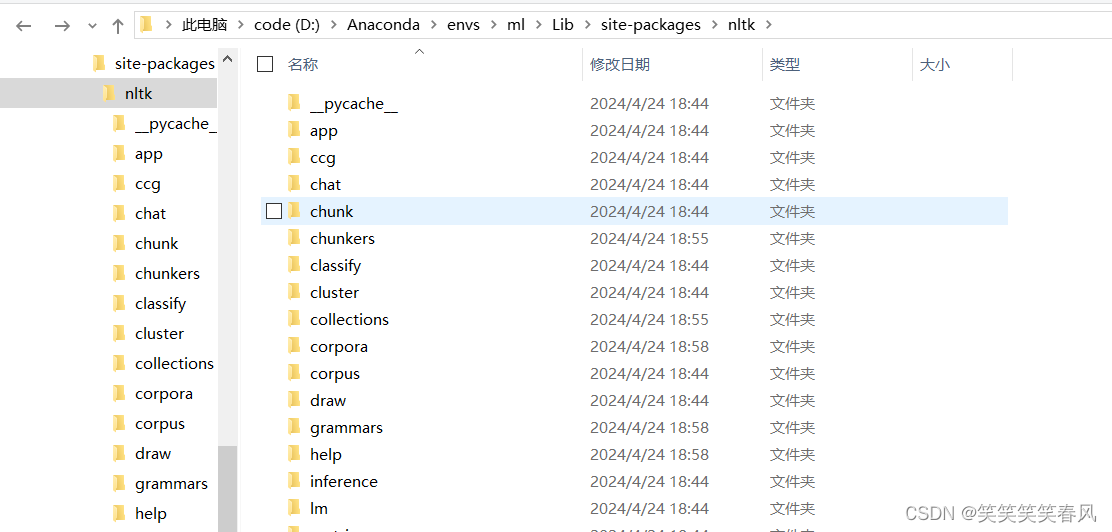
粘贴完你的文件夹就应该和我一样多了,然后找到nltk_data-gh-pages,Ctrl+D直接删除掉。
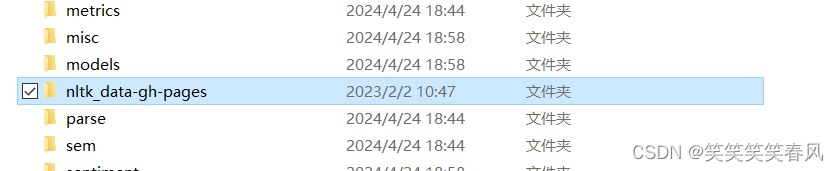
确保corpora,chunk等文件夹都是在nltk中
四.注意
虽然下载的压缩包名字叫做nltk_data-gh-pages,也有很多攻略中文件夹的名字叫做nltk_data而不是nltk,但是我试过这样都会报错,如No module named 'nltk',No module named 'nltk.corpora'等,文件的路径一定要放对位置,不然编译器会找不到!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









