









题意
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
难度
简单
示例
例 1
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
例 2
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
分析 1
对于这道题,我们很容易想到 Java字符串的indexOf()方法,我在二哥的 Java 进阶之路上也帮大家讲过这个方法的实现。
#String 类的 indexOf 方法
indexOf 方法用于查找一个子字符串在原字符串中第一次出现的位置,并返回该位置的索引。来看该方法的源码:
/*
* 查找字符数组 target 在字符数组 source 中第一次出现的位置。
* sourceOffset 和 sourceCount 参数指定 source 数组中要搜索的范围,
* targetOffset 和 targetCount 参数指定 target 数组中要搜索的范围,
* fromIndex 参数指定开始搜索的位置。
* 如果找到了 target 数组,则返回它在 source 数组中的位置索引(从0开始),
* 否则返回-1。
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 如果开始搜索的位置已经超出 source 数组的范围,则直接返回-1(如果 target 数组为空,则返回 sourceCount)
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
// 如果开始搜索的位置小于0,则从0开始搜索
if (fromIndex < 0) {
fromIndex = 0;
}
// 如果 target 数组为空,则直接返回开始搜索的位置
if (targetCount == 0) {
return fromIndex;
}
// 查找 target 数组的第一个字符在 source 数组中的位置
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
// 循环查找 target 数组在 source 数组中的位置
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
// 如果 source 数组中当前位置的字符不是 target 数组的第一个字符,则在 source 数组中继续查找 target 数组的第一个字符
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
// 如果在 source 数组中找到了 target 数组的第一个字符,则继续查找 target 数组的剩余部分是否匹配
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
// 如果 target 数组全部匹配,则返回在 source 数组中的位置索引
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
// 没有找到 target 数组,则返回-1
return -1;
}
那不就可以用此来解题了啊。
class Solution {
public int strStr(String haystack, String needle) {
int index = haystack.indexOf(needle);
return index;
}
}来看效率:
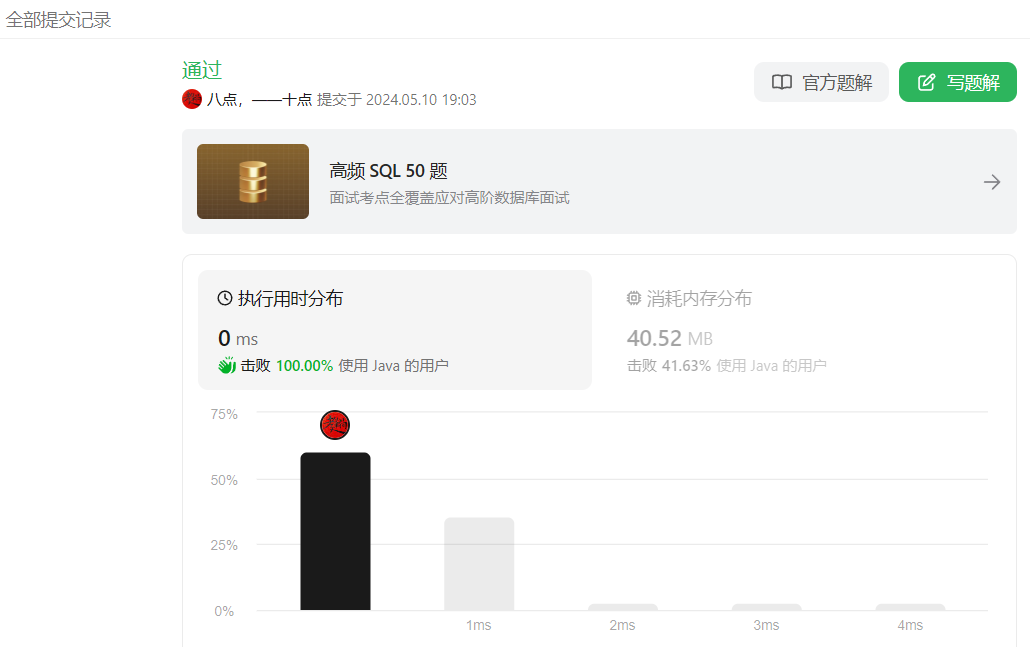
JDK8 版本的方法签名是:
staticintindexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex)
先来看参数:
- source:主字符串的字符数组。
- sourceOffset:主字符串的起始偏移量。
- sourceCount:主字符串中字符的总数。
- target:要查找的子字符串的字符数组。
- targetOffset:子字符串的起始偏移量。
- targetCount:子字符串中字符的总数。
- fromIndex:开始搜索的索引位置。
源码:
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
再来看逻辑流程:
- 首先,检查fromIndex是否大于或等于sourceCount。如果是,且targetCount为 0,则返回sourceCount;否则返回-1。
- 如果fromIndex小于 0,它被设置为 0。
- 如果targetCount为 0,则直接返回fromIndex,因为空字符串被认为存在于任何位置。
- 然后,计算最大搜索索引max,这是为了确保搜索时target能够完全位于source中。
- 接下来,遍历source数组,从sourceOffset + fromIndex开始,直到max,查找与target数组中第一个字符匹配的字符。
- 一旦找到第一个匹配的字符,就在source中从这个位置开始,尝试匹配整个target数组。
- 如果所有后续字符都匹配,就返回当前的索引(调整过的,即i - sourceOffset),因为这表示找到了完整的子字符串。
- 如果遍历完成后未找到匹配的子字符串,则返回-1。
这种实现方式在处理大字符串时效率不如KMP(Knuth-Morris-Pratt)算法,但 JDK 选择了这种更易于理解和实现的方法,足以处理大多数常见的情况。
所以,我们可以按照这个思路来实现我们的strStr()方法。
class Solution {
public int strStr(String haystack, String needle) {
// 获取主字符串和子字符串的长度
int sourceCount = haystack.length();
int targetCount = needle.length();
// 如果子字符串为空,则根据题目要求返回0
if (targetCount == 0) {
return 0;
}
// 获取子字符串的第一个字符,用于后续匹配的起点
char first = needle.charAt(0);
// 计算搜索的最大起始位置,确保子字符串能够完全位于主字符串中
int max = sourceCount - targetCount;
// 遍历主字符串
for (int i = 0; i <= max; i++) {
// 寻找与子字符串第一个字符匹配的字符
if (haystack.charAt(i) != first) {
// 如果当前字符不匹配,继续向后搜索直到找到匹配的字符或达到最大索引
while (++i <= max && haystack.charAt(i) != first);
}
// 找到第一个字符后,检查剩余的部分是否也匹配
if (i <= max) {
int j = i + 1; // 设置匹配的下一个字符的索引
int end = j + targetCount - 1; // 计算子字符串在主字符串中的结束位置
for (int k = 1; j < end && haystack.charAt(j) == needle.charAt(k); j++, k++);
// 如果整个子字符串都匹配了,返回其在主字符串中的起始索引
if (j == end) {
return i;
}
}
}
// 如果遍历完成后没有找到匹配的子字符串,返回-1
return -1;
}
}
如果觉得上面的代码有点复杂,我们可以稍微简化一下:
class Solution {
public int strStr(String haystack, String needle) {
// 如果 needle 是空字符串,则按照题目要求返回 0
if (needle.isEmpty()) {
return 0;
}
// 获取两个字符串的长度
int n = haystack.length();
int m = needle.length();
// 遍历 haystack 字符串
for (int i = 0; i <= n - m; i++) {
// 从 haystack 的第 i 个字符开始,取一个长度为 m 的子字符串
String subStr = haystack.substring(i, i + m);
// 比较这个子字符串与 needle 是否相等
if (subStr.equals(needle)) {
return i; // 如果相等,则返回当前的起始位置
}
}
return -1; // 如果遍历结束都没有找到匹配的位置,则返回 -1
}
}这个方法就非常好懂了,对吧,我们只需要遍历主字符串,然后取出一个长度为子字符串的子串,然后比较两个子串是否相等,如果相等,就返回当前的起始位置。
利用了字符串的 substring() 方法和 equals() 方法,来看一下题解效率:
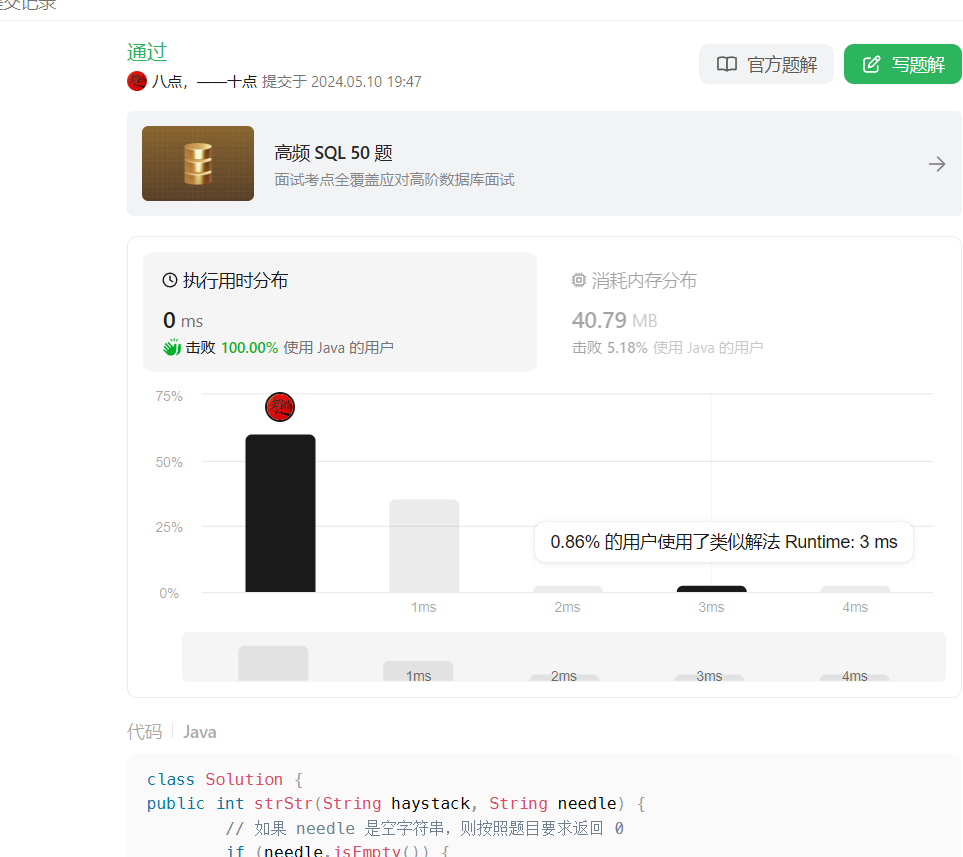















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









