









-
启动hdfs
cd /usr/local/hadoop
./sbin/start-dfs.sh -
启动zookeeper
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties -
启动kakfa服务
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties -
创建Topic 名为 fiction_ratings
cd /usr/local/kafka
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic fiction_ratings -
查看是否创建成功
./bin/kafka-topics.sh --list --zookeeper localhost:2181 -
启动监控端,监控是否有数据发送到该主题
cd /usr/local/kafka
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic fiction_ratings -
书写生产者代码
import java.io.{File, RandomAccessFile}
import java.nio.charset.StandardCharsets
import scala.io.Source
object KafkaWordProducer2 {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("用法: KafkaWordProducer <metadataBrokerList> <topic> <linesPerSec>")
System.exit(1)
}
val Array(brokers, topic, linesPerSec) = args
// Kafka生产者属性
val props = new java.util.HashMap[String, Object]()
props.put(org.apache.kafka.clients.producer.ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(org.apache.kafka.clients.producer.ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(org.apache.kafka.clients.producer.ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new org.apache.kafka.clients.producer.KafkaProducer[String, String](props)
// 文件路径
val filePath = "/usr/local/bigdatacase/dataset/fiction.csv" // 假设数据文件名为 part2.txt
// 记录已发送的行数
var sentLines = 0
while (true) {
val file = new File(filePath)
val bufferedSource = Source.fromFile(file)
val linesIterator = bufferedSource.getLines().drop(sentLines)
val linesToSendPerSec = linesPerSec.toInt
val sleepTime = (1000.0 / linesToSendPerSec).toLong
while (linesIterator.hasNext) {
val line = linesIterator.next()
val message = new org.apache.kafka.clients.producer.ProducerRecord[String, String](topic, null, line)
producer.send(message)
Thread.sleep(sleepTime)
sentLines += 1
}
bufferedSource.close()
// 等待一段时间再次检查文件是否有新内容
Thread.sleep(5000)
}
// 不会执行到这里,因为循环会一直运行
producer.close()
}
}
-
启动生产者,查看监控终端
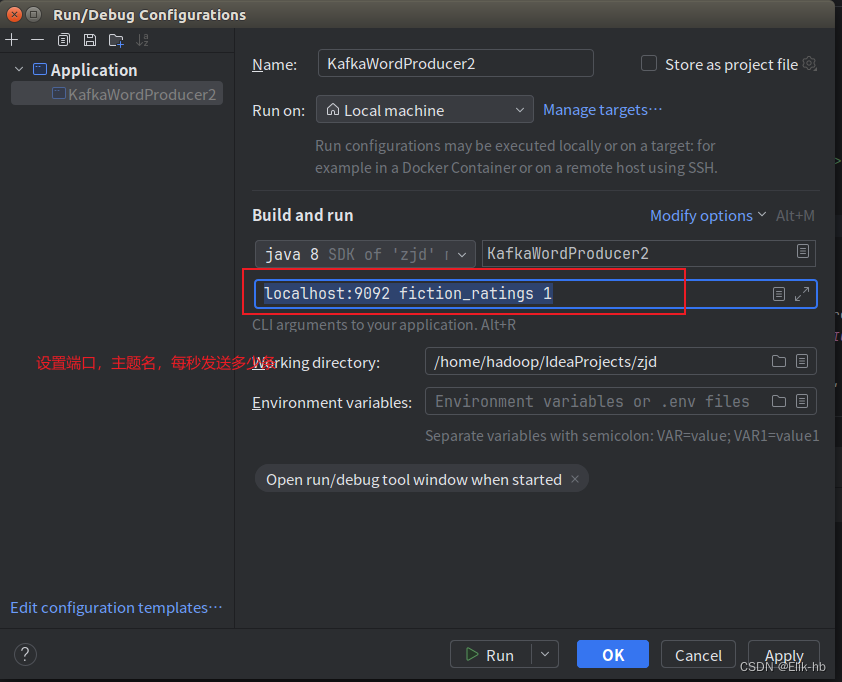
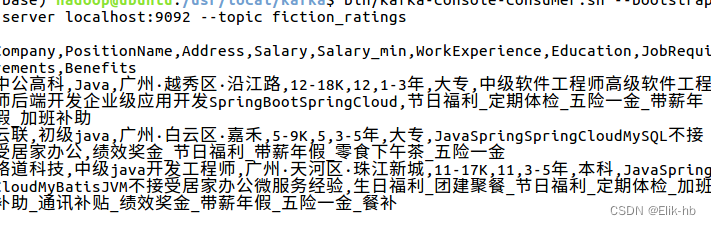
可以看出,数据已经读取成功,并且可以每秒输出一条 -
书写消费者代码
package edu.cn
import java.util
import org.apache.kafka.clients.consumer.{ConsumerConfig, KafkaConsumer}
import scala.collection.JavaConverters._
object KafkaWordCount {
def main(args: Array[String]): Unit = {
if (args.length < 2) {
System.err.println("用法: KafkaWordConsumer <bootstrapServers> <topic>")
System.exit(1)
}
val Array(bootstrapServers, topic) = args
val props = new util.Properties()
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers)
props.put(ConsumerConfig.GROUP_ID_CONFIG, "word-consumer")
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
val consumer = new KafkaConsumer[String, String](props)
consumer.subscribe(util.Collections.singletonList(topic))
val wordCounts = scala.collection.mutable.Map[String, Int]()
try {
while (true) {
val records = consumer.poll(java.time.Duration.ofMillis(1000))
for (record <- records.asScala) {
val value = record.value()
val words = value.split(",") // 假设数据使用逗号分隔
if (words.length >= 2) { // 确保第二列存在
val word = words(1).trim // 获取第二列并去除首尾空格
wordCounts(word) = wordCounts.getOrElse(word, 0) + 1
}
}
// 打印统计结果
println("第二列不同类型出现的次数:")
wordCounts.foreach { case (word, count) =>
println(s"$word: $count")
}
}
} finally {
consumer.close()
}
}
}
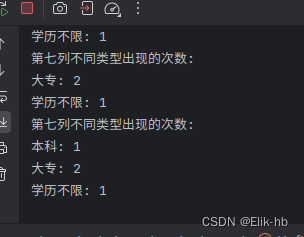
在生产者运行的情况下执行消费者代码,查看输出
注意这里也要指定号端口,主题目
可以看出数据成功读取并且分析统计
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>WordCount</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<properties>
<spark.version>3.4.0</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- Spark Streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- Spark Streaming Kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- Kafka Clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
谢谢大家
















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











