






1.什么是数据结构?
是指计算机存储和组织数据的一种方式,相互之间存在一种或多种特定关系的数据集合
数据结构 包括:逻辑结构 和 存储结构
1.1逻辑结构:
1.集合结构
就是许多毫不相干的点,集中在一起。
每个点之间都是相互独立的,没有任何联系。
2.线性结构
即一段数据,每个数据都有唯一前驱和唯一后继,除了第一个元素没有前驱,最后一个元素没有后继。
关系:一对一
3.树形结构
只有唯一的根节点,根节点下可以有许多的子节点。除了根节点之外,子节点也可以变成子树的根节点。即一对多的关系,每个结点可以有多个后继,但只能有一个前驱,注意根节点没有前驱。
关系:一对多
4.图形结构
比如,目前有 a b c d e 五个点,a到e点,可以从a直接到e,也可以先从a到b,b再到e,也可以可以a到c,c到d,d在到e。其他点也有类似关系。即在一个区域内的任意两点,可能存在某种联系。
关系:多对多
1.2 存储结构
主要是 顺序存储 和 链式存储
顺序存储:
顾名思义,就是按照一定的顺序进行存储。即使用一段连续的地址进行存储。
比如之前常用的数组就是一种顺序存储。
链式存储:
类似链条一样,一环扣一环的进行存储。在链式存储中,前面说的环称为结点。所以链式存储不要求存储数据的地址是连续的,但是相邻的两个地址之间存在联系。即上一个结点,需要能找到下一个结点的位置。
注意:算法的实现往往需要依赖于存储结构
链式存储 与 顺序存储 的 区别:
1.链式存储 对 存储空间没有特别要求。但是顺序存储要求存储空间是一段连续的空间。
2.链式存储要求 上一个结点 保存 下一个结点 的地址,而 顺序存储对此不做要求。
2.线性表
线性表: 逻辑结构是:线性结构,
存储结构:可以是链式存储,也可以是顺序存储。
线性表要求每个元素有 唯一前驱 和 唯一后继。第一个元素 没有前驱,最后一个元素 没有后继。
1.顺序表
存储方式:顺序存储,逻辑结构还是线性存储
1.顺序表的创建:
方法1:(个人觉得比较简单,好理解,直接使用数组来存储)
struct queue{
数据类型 数组名[大小];
int num;//统计顺序表中的元素个数
};
方法2:(与方法1相比,方法2的数组大小可以自己选择,比较灵活,可以避免空间浪费)
struct queue{
数据类型 *指针变量名;//因为数组名表示的就是整个数组的地址,单独的一个指针存放的也是地址,指针的数据类型 * n,等价于申请大小为n的数组
int size;//控制数组大小
int num;//统计连续空间中元素个数
};
增加元素:
需要注意的是,在 初始化结构体 时,方法2 除了要申请结构体的空间外,还需要额外申请数组的大小(指针的数据类型*size)
2.添加元素
顺序表增加元素与普通数组添加元素使用的方法基本一致,通过数组下标进行访问,即增加新元素
例:
p->数组名[要插入的元素下标]
3.删除元素
找到要删除的下标,让之后的元素都往前移动一个位置
例:
p->数组名[pos]=p->数组名[pos+1];
修改元素和查找元素 与 普通数组 方法基本上类似,都是通过遍历数组,来实现修改和查找功能
2.链式表
存储结构:链式存储
1.链表的创建
struct Node {
struct Node *next;
数据类型 变量名;
};
2.链表的初始化
注意在链表中,总是存在一个 头结点 ,头结点中不存放值,只存放下一个结点的地址,所以在头结点用于存储下一个结点的地址,通常被称为头指针
struct Node * init(struct Node)
{
struct Node *p=malloc(sizeof(struct Node))
p->next=0;
}
3.链表的增加
可以在头指针之后进行插入,也可以在链表尾进行插入
3.1 头结点之后进行插入:
代码
void insert_tail(struct Node *p,int data)
{
struct Node *q=p;//定义一个指针存放头结点,
struct Node *s=malloc(sizeof(struct Node));//创立新结点去保存data的数据
s->data=data;
s->next=q->next;
q->next=s;
}
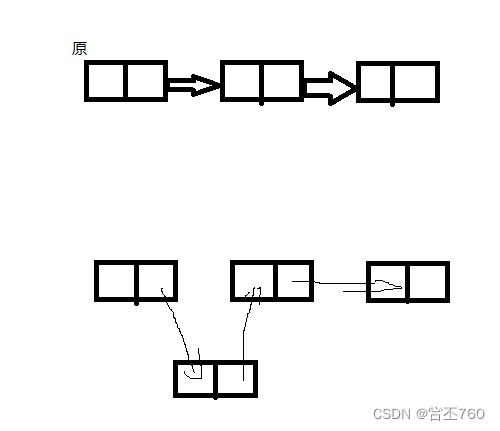
3.2在队尾进行插入:
代码:
void insert_tail(struct Node *p,int data)
{
struct Node *q=p;//定义一个指针存放头结点,然后遍历链表,使指针找到队尾结点
while(q->next != 0)q=q->next;
struct Node *s=malloc(sizeof(struct Node));//创立新结点去保存data的数据
s->data=data;
s->next=q->next;
q->next=s;
}
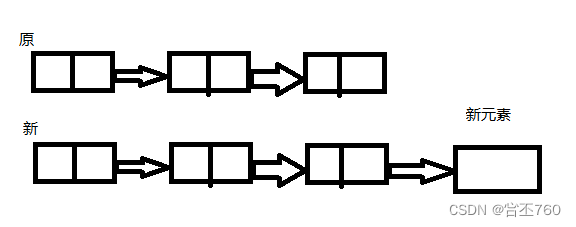
在对头插入 和 在队尾插入的区别:
1.在对头插入 不用 寻找 队尾结点,直接在头结点之后进行插入,注意,要先保存 头指针 指向
的下一个地址 给新结点的指针,保证插入进去的新结点不会断开。
3.改 和 查
两者方法类似,都是遍历 链表,即判断 下一个结点 是不是 为 空(NULL)。
3.栈
是一种 特殊的 线性表。
特点:先进后出,并且只能在 栈顶 进行 增加 和 删除 ,栈底不能修改
例:
把 1 2 3 4 5 ,5个数一次性存入栈中,输出结果:5 4 3 2 1
1.顺序栈
逻辑结构是:栈(线性结构)
存储结构:顺序存储
1.栈的 定义 和 初始化
//方法1,通过直接申请数组进行操作
struct stack_Que{
数据类型 数组名[大小];
int top;//栈顶
int buttom;//栈底
};
struct Node * creat_Que()
{
struct Node * q= malloc(sizeof(struct Node));
q->top=0;
q->buttom=0;
return q;
}
方法2 通过指针申请空间,间接使用
struct stack_seq
{
指针要存储的数据类型 * 指针变量名;
int top;
int buttom;
};
struct stack_seq * creat_seq(int len)
{
struct stack_seq *p=malloc(sizeof(struct stack_seq));
p->指针变量名=malloc(sizeof(指针存储的数据类型)*len);
p->top=0;
p->buttom=0;
reurn p;
}
注意点: 如果栈顶初始化为0,top的值 表示当前位置为即将插入的位置
如果栈顶初始化为-1,top的值 表示在当前位置插入。
两者在删除时有明显区别。前者,需要先将 top的值自减,才能删除。后者 直接就可以删除
2.栈的增加
void insert_satck(struct stack_seq *p,int data)
{
if(p->top > 数组大小)
{
break;//表示当前栈已经满了
}
p->数组名[p->top]=data;
p->top++;
}
注意:需要判断 top的值 小于 数组大小
3.求栈的大小
int len(struct stack_seq *q)
{
return q->top-q->buttom;
}
4.栈的删除
由于栈这种线性表限制了 只能在 栈顶进行删除,所以将栈顶元素赋值为0,在将栈顶元素-1就可以了
注意:这里需要判断 栈是否为空
void del_satck(struct stack_seq *p)
{
if( p->top = = 0)
{
break;
}
p->数组名[p->top]=0;
p->top--;
}
5.修改和查找
这两部分和普通顺序表基本一样,只要遍历顺序栈就可以了。
2.链式栈
逻辑结构:栈(特殊线性表)
存储结构:链式存储
由于 栈 是特殊线性表,只能在 通顶 进行插入和删除操作,并且要满足 先进后出 的特点,所以链式栈的通顶 通常为 头结点。
1.链式栈的 创建 和 初始化
struct Node_sta{
数据类型 变量名;
struct Node_sta * top;
};
struct Node_sta * creat_No()
{
struct Node_sta * p=malloc(sizeof(struct Node_sta ));
p->top=0;
return p;
}
2.链式栈的增加操作
void insert_No(struct Node_sta * p,与结构体相同的数据类型 变量名)
{
struct Node_sta *head=p;
struct Node_sta *q=malloc(sizeof(struct Node_sta));
q->变量(结构体的成员变量)=变量名(形参);
q->top=head ->top;
head->top=q;
}
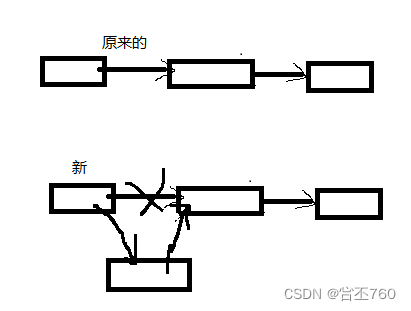
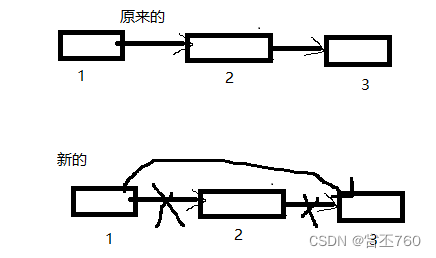
3.链表的删除
注意: 这里 需要 判断 链式栈 是否 为空
void del_No(struct Node_sta * p,与结构体相同的数据类型 变量名)
{
if(p->top == 0)//表示栈顶指针存储的下一个地址为空
{
break;
}
struct Node_sta q=p->top;
p->top=q->top;
free(q);
}
4.查找和 修改
要遍历单向链表,在遍历前,需要判断链表是否为空
4.队列
也是一种 特殊 的线性表,对头只能进行删除,队尾只能进行插入
特点:先进先出
1.顺序队列
存储结构:顺序存储
逻辑结构:队列
特点:队尾插入,对头删除
补充:使用连续空间进行存储时,由于每次删除,对头都要向队尾方向移动,造成了对头前面的空间浪费。所有在使用顺序队列时,都选择了循环队列。这避免了空间的浪费
1.循环队列的创建 和 初始化
补充:在创建循环队列时,因为 数组名 表示的 就是 数组首地址,即可以用指针来表示。所有创建时,也可以使用指针来创建。
struct queue{
数组类型 数组名[大小];
int front;//对头,进行删除
int rear;//队尾,进行新增
};
struct queue * creat_que()
{
struct queue * p=malloc(sizeof(struct queue));
p->rear=0;
p->front =0;
return p;
}
注意点:因为在使用循环队列时,为空时,判断对尾指针 和 队头 是否相等,但是判断队列满时,需要预留一位进行判断,即队尾元素 +1 是否等于对头。所有对于 循环队列,实际长度大小 为 0~ 数组大小-1 内;
2.循环队列的新增
需要判断队列是否满了
只能在队尾进行新增
void insert_que(struct queue *p,数据类型(与结构体中数组的数据类型相同) 变量名 )
{
if((p->rear+1)% (数组大小-1)== p->front)//这样做,避免越界问题,还减少了空间的浪费,重复使用
{
break;
}
p->数组[p->rear]=变量名;
p->rear=( p->rear+1)% (数组大小-1);
}
3.删除循环队列元素
删除时,需要注意队列是否为空
只能在对头进行删除
void del_que(struct queue *p)
{
if(p->front == p->rear)//表示队列为空
break;
p->数组名[p->front]=0;
p->front=(p->front+1)%(数组大小-1);
}
4.循环队列的修改和查找
只有遍历循环队列即可。注意先要要判断是否为空
遍历代码
int i=p->front;
int j=p->rear;
while(i!= j)
{
i++;
}
注意点:遍历时,需要用参数赋值为 front 和 rear,如果直接使用front 和 rear 会改变 原先 front 和 rear 的值。
2.链式队列
存储结构:链式存储
需要满足队尾插入 ,对头删除
即头指针对头,
1.创建链式队列
struct Node_que{
数据类型 变量名(存放的数据);
struct Node_que *front;
struct Node_que *rear;
};
struct Node_que *creat_que()
{
struct Node_que * p=malloc(sizeof(struct Node_que));
p->rear=NULL;
p->front =p->rear;
return p;
}
2.链式队列的新增
因为只能在队尾元素新增
void insert_que(struct Node_que *q,数据类型 变量名)
{
while(q->rear !=NULL) q=q->rear;
struct Node_que *p=malloc(sizeof(struct Node_que));
p->数据=变量名;
p->rear=q->rear;;
q->rear=p;
}
注意点:要保证rear在链式表的最后一个元素
3.链式队列的删除
只能在对头删除,即对头的位置都在头指针
void del_que(struct Node_que *q)
{
if(p->front == NULL)//表示链表为空
break;
struct Node_que *p=q->rear;
q->front=p->front;
free(p);
}
5.树
由一个根往后引申出多个子结点 ,并且每个子结点 又可以看成是一个新树的根节点。
关系:一对多。即每个子结点 只 对应 一个根节点 ,但是一个根节点 可以有 多个子结点
结点的度:
是指根结点拥有子树的个数(拥有分支的数目)
树的度:
把整颗树度的最大值,称为树的度
叶子结点(终端结点):
指度为0的结点,称为 叶子 结点
孩子结点:
是指结点的子树的根节点,就称为该结点的孩子
双亲结点(父结点):
指结点的根结点,称为孩子结点的双亲
兄弟结点:
是指同一个双亲的孩子,就称为兄弟
树的深度(高度):
树中结点的最大层次(层数)称为数的深度
1.二叉树
每个根 所拥有的 子结点数 都为 2
1.二叉树的性质
1.在二叉树中,第k层上,最多有2^(k-1)个结点
2.在深度为k的二叉树中,最多有2^k-1个结点
3.对于任意二叉树,如果叶子结点数为n0,度为2的结点数为n2,
存在 n0=n2+1
两种特殊的二叉树
1.满二叉树
表示在一个 深度 为 k 的二叉树中。这棵树所有节点数 正好是 2^k-1 个结点。这样的二叉树,被称为满二叉树。
2.完全二叉树
表示在 一个 深度 为 k的 二叉树中。从第一层到第k-1层,所有结点数,加起来 满足 2^(k-1)-1这个。但是在第k层,可以不要求结点数是该层的最大值,但是要求 必须 满足 从左到右 每两个结点 都是相邻的
总结:完全二叉树是一种特殊的满二叉树。特殊点在于对第k层的数量无过多要求,但对相邻位置有要求。
2.二叉树的存储
1.链式存储
使用一段连续空间来存储二叉树中的关系。
注意点:如果根的下标是 1,那么左孩子 用 2i表示 ,(i表示 父节点的下标),右孩子 用 2i+1 表示
如果根的下标是0,那么左孩子 用 2i+1 表示 ,右孩子 用 2(i+1) 表示
缺点:存在大量的空间浪费
2.链式存储
struct Tree{
数据类型 数据;
struct Tree * L_chrild,R_chrild;
};
操作灵活,遍历耗时大。
3.二叉树的遍历
1.先序遍历 ----根 左 右
先遍历根,然后是左子树,最后是右子树
2.中序遍历 ---- 左 根 右
先遍历左子树,然后是右子树,最后是右子树
3.后序遍历 ---- 左 右 根
先遍历左子树,然后是右子树,最后是根
4.层次遍历
即一层一层的进行遍历,每一层从左往右依次遍历。
注意:对于任意的二叉树,知道前序,中序,后序中任意两种,就可以得到这个二叉树。
6.图
1.图的概念和相关知识
两个集合表示,一个集合表示图中的顶点,另一个表示边之间的关系。
无向边:顶点之间的关系是相互的
有向边:顶点之间的关系是单向的,也叫做弧(弧头:起点,弧尾:终点)
路径:两个顶点之间,存在一条可以到达的关系
连通图:任意两个顶点之间都存在路径
连通分量:在图中,部分顶点之间是连通的就叫做图的连通分量
2.图的存储
1.邻接矩阵(使用二维数组存储)
行:表示有多少个顶点数
列:表示每个顶点与其他顶点之间的关系
有关系用1表示,没有关系用0表示。
2.邻接表:
顺序表和链表的结合表示
顺序表中存放顶点,并用一个指针存放与该顶点有关系的顶点(用链表 表示)
7.算法
1.查找
1.1直接查找
就是遍历,从开始位置,遍历到结束。满足条件就结束遍历。
1.2折半查找
每次只找一半,并设置中间值。如果中间值小于要查找的数,则说明要找的数在上半部分,修改中间值。反过来,则在下半部分。重复过程。

注意:如果low小于high 则说明这个是不存在。
2.排序
1.冒泡排序
思想,每次找到最大值就放到后面
int main()
{
int a[10]={21,32,42,34,12,3,43,75,23,2};
for(int i=0;i<10;i++)
{
for(int j=0;j<9-i;j++)
{
if(a[j]>a[j+1])
{
int c=a[j];
a[j]=a[j+1];
a[j+1]=c;
}
}
}
for(int i=0;i<10;i++)
printf("%d-->",a[i]);
printf("\n");
}
}2.直接排序(选择排序)
int main()
{
int a[10]={21,32,42,34,12,3,43,75,23,2};
for(int i=0;i<10;i++)
{
int min=i;
for(int j=i+1;j<10;j++)
{
if(a[min]>a[j])
{
min=i;
}
}
int c=a[i];
a[i]=a[min];
a[min]=c;
}
for(int i=0;i<10;i++)
printf("%d-->",a[i]);
printf("\n");
}
}















 4190
4190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









