






import os
import math
import torch
import torch.nn as nn
# hugging face的分词器,github地址:https://github.com/huggingface/tokenizers
from tokenizers import Tokenizer
# 用于构建词典
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch.nn.functional import pad, log_softmax
from pathlib import Path
from tqdm import tqdm
# 工作目录,缓存文件盒模型会放在该目录下
work_dir = Path("./dataset")
# 训练好的模型会放在该目录下
model_dir = Path("Seq2Seq/model")
# 上次运行到的地方,如果是第一次运行,为None,如果中途暂停了,下次运行时,指定目前最新的模型即可。
model_checkpoint = None # 'model_10000.pt'
# 如果工作目录不存在,则创建一个
if not os.path.exists(work_dir):
os.makedirs(work_dir)
# 如果工作目录不存在,则创建一个
if not os.path.exists(model_dir):
os.makedirs(model_dir)
# 英文句子的文件路径
en_filepath = './dataset/train.en'
# 中文句子的文件路径
zh_filepath = './dataset/train.zh'
# 定义一个获取文件行数的方法。
def get_row_count(filepath):
count = 0
for _ in open(filepath, encoding='utf-8'):
count += 1
return count
# 英文句子数量
en_row_count = get_row_count(en_filepath)
# 中文句子数量
zh_row_count = get_row_count(zh_filepath)
assert en_row_count == zh_row_count, "英文和中文文件行数不一致!"
# 句子数量,主要用于后面显示进度。
row_count = en_row_count
# 定义句子最大长度,如果句子不够这个长度,则填充,若超出该长度,则裁剪
max_length = 72
print("句子数量为:", en_row_count)
print("句子最大长度为:", max_length)
# 定义英文和中文词典,都为Vocab类对象,后面会对其初始化
en_vocab = None
zh_vocab = None
# 定义batch_size,由于是训练文本,占用内存较小,可以适当大一些
batch_size = 96
# epochs数量,不用太大,因为句子数量较多
epochs = 10
# 多少步保存一次模型,防止程序崩溃导致模型丢失。
save_after_step = 5000
# 是否使用缓存,由于文件较大,初始化动作较慢,所以将初始化好的文件持久化
use_cache = True
# 定义训练设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("batch_size:", batch_size)
print("每{}步保存一次模型".format(save_after_step))
print("Device:", device)
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def en_tokenizer(line):
return tokenizer.convert_ids_to_tokens(tokenizer.encode(line, add_special_tokens=False))
print(en_tokenizer("I'm a English tokenizer."))
def yield_en_tokens():
"""
每次yield一个分词后的英文句子,之所以yield方式是为了节省内存。
如果先分好词再构造词典,那么将会有大量文本驻留内存,造成内存溢出。
"""
file = open(en_filepath, encoding='utf-8')
print("-------开始构建英文词典-----------")
for line in tqdm(file, desc="构建英文词典", total=row_count):
yield en_tokenizer(line)
file.close()
# 指定英文词典缓存文件路径
en_vocab_file = work_dir / "vocab_en.pt"
# 如果使用缓存,且缓存文件存在,则加载缓存文件
if use_cache and os.path.exists(en_vocab_file):
en_vocab = torch.load(en_vocab_file, map_location="cpu")
# 否则就从0开始构造词典
else:
# 构造词典
en_vocab = build_vocab_from_iterator(
# 传入一个可迭代的token列表。例如[['i', 'am', ...], ['machine', 'learning', ...], ...]
yield_en_tokens(),
# 最小频率为2,即一个单词最少出现两次才会被收录到词典
min_freq=2,
# 在词典的最开始加上这些特殊token
specials=["<s>", "</s>", "<pad>", "<unk>"],
)
# 设置词典的默认index,后面文本转index时,如果找不到,就会用该index填充
en_vocab.set_default_index(en_vocab["<unk>"])
# 保存缓存文件
if use_cache:
torch.save(en_vocab, en_vocab_file)
# 打印一下看一下效果
print("英文词典大小:", len(en_vocab))
print(dict((i, en_vocab.lookup_token(i)) for i in range(10)))
def zh_tokenizer(line):
"""
定义中文分词器
:param line: 中文句子,例如:机器学习
:return: 分词结果,例如['机','器','学','习']
"""
return list(line.strip().replace(" ", ""))
def yield_zh_tokens():
file = open(zh_filepath, encoding='utf-8')
for line in tqdm(file, desc="构建中文词典", total=row_count):
yield zh_tokenizer(line)
file.close()
zh_vocab_file = work_dir / "vocab_zh.pt"
if use_cache and os.path.exists(zh_vocab_file):
zh_vocab = torch.load(zh_vocab_file, map_location="cpu")
else:
zh_vocab = build_vocab_from_iterator(
yield_zh_tokens(),
min_freq=1,
specials=["<s>", "</s>", "<pad>", "<unk>"],
)
zh_vocab.set_default_index(zh_vocab["<unk>"])
torch.save(zh_vocab, zh_vocab_file)
# 打印看一下效果
print("中文词典大小:", len(zh_vocab))
print(dict((i, zh_vocab.lookup_token(i)) for i in range(10)))
class TranslationDataset(Dataset):
def __init__(self):
# 加载英文tokens
self.en_tokens = self.load_tokens(en_filepath, en_tokenizer, en_vocab, "构建英文tokens", 'en')
# 加载中文tokens
self.zh_tokens = self.load_tokens(zh_filepath, zh_tokenizer, zh_vocab, "构建中文tokens", 'zh')
def __getitem__(self, index):
return self.en_tokens[index], self.zh_tokens[index]
def __len__(self):
return row_count
def load_tokens(self, file, tokenizer, vocab, desc, lang):
"""
加载tokens,即将文本句子们转换成index们。
:param file: 文件路径,例如"./dataset/train.en"
:param tokenizer: 分词器,例如en_tokenizer函数
:param vocab: 词典, Vocab类对象。例如 en_vocab
:param desc: 用于进度显示的描述,例如:构建英文tokens
:param lang: 语言。用于构造缓存文件时进行区分。例如:’en‘
:return: 返回构造好的tokens。例如:[[6, 8, 93, 12, ..], [62, 891, ...], ...]
"""
# 定义缓存文件存储路径
cache_file = work_dir / "tokens_list.{}.pt".format(lang)
# 如果使用缓存,且缓存文件存在,则直接加载
if use_cache and os.path.exists(cache_file):
print(f"正在加载缓存文件{cache_file}, 请稍后...")
return torch.load(cache_file, map_location="cpu")
# 从0开始构建,定义tokens_list用于存储结果
tokens_list = []
# 打开文件
with open(file, encoding='utf-8') as file:
# 逐行读取
for line in tqdm(file, desc=desc, total=row_count):
# 进行分词
tokens = tokenizer(line)
# 将文本分词结果通过词典转成index
tokens = vocab(tokens)
# append到结果中
tokens_list.append(tokens)
# 保存缓存文件
if use_cache:
torch.save(tokens_list, cache_file)
return tokens_list
dataset = TranslationDataset()
print(dataset.__getitem__(0))
def collate_fn(batch):
"""
将dataset的数据进一步处理,并组成一个batch。
:param batch: 一个batch的数据,例如:
[([6, 8, 93, 12, ..], [62, 891, ...]),
....
...]
:return: 填充后的且等长的数据,包括src, tgt, tgt_y, n_tokens
其中src为原句子,即要被翻译的句子
tgt为目标句子:翻译后的句子,但不包含最后一个token
tgt_y为label:翻译后的句子,但不包含第一个token,即<bos>
n_tokens:tgt_y中的token数,<pad>不计算在内。
"""
# 定义'<bos>'的index,在词典中为0,所以这里也是0
bs_id = torch.tensor([0])
# 定义'<eos>'的index
eos_id = torch.tensor([1])
# 定义<pad>的index
pad_id = 2
# 用于存储处理后的src和tgt
src_list, tgt_list = [], []
# 循环遍历句子对儿
for (_src, _tgt) in batch:
"""
_src: 英语句子,例如:`I love you`对应的index
_tgt: 中文句子,例如:`我 爱 你`对应的index
"""
processed_src = torch.cat(
# 将<bos>,句子index和<eos>拼到一块
[
bs_id,
torch.tensor(
_src,
dtype=torch.int64,
),
eos_id,
],
0,
)
processed_tgt = torch.cat(
[
bs_id,
torch.tensor(
_tgt,
dtype=torch.int64,
),
eos_id,
],
0,
)
"""
将长度不足的句子进行填充到max_padding的长度的,然后增添到list中
pad:假设processed_src为[0, 1136, 2468, 1349, 1]
第二个参数为: (0, 72-5)
第三个参数为:2
则pad的意思表示,给processed_src左边填充0个2,右边填充67个2。
最终结果为:[0, 1136, 2468, 1349, 1, 2, 2, 2, ..., 2]
"""
src_list.append(
pad(
processed_src,
(0, max_length - len(processed_src),),
value=pad_id,
)
)
tgt_list.append(
pad(
processed_tgt,
(0, max_length - len(processed_tgt),),
value=pad_id,
)
)
# 将多个src句子堆叠到一起
src = torch.stack(src_list)
tgt = torch.stack(tgt_list)
# tgt_y是目标句子去掉第一个token,即去掉<bos>
tgt_y = tgt[:, 1:]
# # tgt是目标句子去掉最后一个token
tgt = tgt[:, :-1]
# 计算本次batch要预测的token数
n_tokens = (tgt_y != 2).sum()
# 返回batch后的结果
return src, tgt,tgt_y, n_tokens
train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
src, tgt, tgt_y, n_tokens = next(iter(train_loader))
src, tgt, tgt_y = src.to(device), tgt.to(device), tgt_y.to(device)
print("src.size:", src.size())
print("tgt.size:", tgt.size())
print("tgt_y.size:", tgt_y.size())
print(tgt_y)
print("n_tokens:", n_tokens)
class Seq2SeqEncoder(nn.Module):
def __init__(self, embedding_dim, hidden_size, source_vocab_size):
super(Seq2SeqEncoder, self).__init__()
self.lstm_layer = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
batch_first=True)
self.embedding_table = nn.Embedding(source_vocab_size, embedding_dim)
def forward(self, input_ids):
input_sequence = self.embedding_table(input_ids)
# print(input_sequence.size())
output_states, (final_h, final_c) = self.lstm_layer(input_sequence)
return output_states, final_h
import torch.nn.functional as F
class Seq2SeqAttentionMechanism(nn.Module):
def __init__(self):
super(Seq2SeqAttentionMechanism, self).__init__()
def forward(self, decoder_state_t,encoder_states):
bs, source_length, hidden_size = encoder_states.shape
decoder_state_t = decoder_state_t.unsqueeze(1)
decoder_state_t = torch.tile(decoder_state_t,dims=(1,source_length,1))
score = torch.sum(decoder_state_t *encoder_states, dim=-1)
attn_prob = F.softmax(score, dim=-1)
# print(attn_prob.size())
context = torch.sum(attn_prob.unsqueeze(-1)*encoder_states,1)
# print(context.size())
return attn_prob, context
class Seq2SeqDecoder(nn.Module):
def __init__(self, embedding_dim, hidden_size, num_classes, target_vocab_size, start_id, end_id):
super(Seq2SeqDecoder, self).__init__()
self.lstm_cell = torch.nn.LSTMCell(embedding_dim, hidden_size)
self.proj_layer = nn.Linear(hidden_size * 2, num_classes)
self.attention_mechanism = Seq2SeqAttentionMechanism()
self.num_classes = num_classes
self.embedding_table = torch.nn.Embedding(target_vocab_size, embedding_dim) # 移除多余的等号
self.start_id = start_id
self.end_id = end_id
def forward(self, shifted_target_ids, encoder_states):
shifted_target = self.embedding_table(shifted_target_ids)
bs, target_length, embedding_dim = shifted_target.shape
bs, source_length, hidden_size = encoder_states.shape
logits = torch.zeros(bs, target_length, self.num_classes)
probs = torch.zeros(bs, target_length, source_length)
for t in range(target_length):
decoder_input_t = shifted_target[:, t, :]
if t==0:
h_t, c_t = self.lstm_cell(decoder_input_t)
else:
h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t))
attn_prob, context = self.attention_mechanism(h_t, encoder_states)
decoder_output = torch.cat((context, h_t), -1)
logits[:, t, :] = self.proj_layer(decoder_output)
probs[:, t, :] = attn_prob
return probs, logits
def inference(self, encoder_states):
target_id = self.start_id
h_t, c_t = None, None
result = []
while True:
decoder_input_t = self.embedding_table(target_id)
if h_t is None:
h_t, c_t = self.lstm_cell(decoder_input_t, (torch.zeros_like(decoder_input_t), torch.zeros_like(decoder_input_t)))
else:
h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t))
attn_prob, context = self.attention_mechanism(h_t, encoder_states)
decoder_output = torch.cat((context, h_t), -1)
logits = self.proj_layer(decoder_output)
target_id = torch.argmax(logits, -1)
result.append(target_id) # 确保添加的是标量
if torch.any(target_id == self.end_id): # 修复括号错误
print('Stop decoding')
break
predicted_ids = torch.stack(result, dim=0)
return predicted_ids
class Model(nn.Module):
def __init__(self, embedding_dim, hidden_size, num_classes,
source_vocab_size, target_vocab_size, start_id, end_id):
super(Model, self).__init__()
self.encoder = Seq2SeqEncoder(embedding_dim, hidden_size, source_vocab_size)
self.decoder = Seq2SeqDecoder(embedding_dim, hidden_size, num_classes,
target_vocab_size, start_id, end_id)
def forward(self, input_sequence_ids, shifted_target_ids):
# Corrected variable names here
encoder_states, final_h = self.encoder(input_sequence_ids)
probs, logits = self.decoder(shifted_target_ids, encoder_states) # Corrected variable name
return probs, logits
def infer(self, input_sequence_ids, max_decode_steps, device):
pass
import torch.optim as optim
# 定义超参数
embedding_dim = 256
hidden_size = 512
num_classes = len(zh_vocab)
source_vocab_size = len(en_vocab)
target_vocab_size = len(zh_vocab)
start_id = zh_vocab["<s>"]
end_id = zh_vocab["</s>"]
# 实例化模型
model = Model(embedding_dim, hidden_size, num_classes, source_vocab_size, target_vocab_size, start_id, end_id).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=zh_vocab["<pad>"])
optimizer = optim.Adam(model.parameters(), lr=0.001)
torch.cuda.empty_cache()
# TensorBoard Summary Writer
writer = SummaryWriter(log_dir='./logs')
def train_epoch(model, data_loader, optimizer, criterion, device, epoch):
model.train()
total_loss = 0
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for batch_idx, (src, tgt, tgt_y, n_tokens) in enumerate(data_loader):
src, tgt, tgt_y = src.to(device), tgt.to(device), tgt_y.to(device)
print(next(model.parameters()).device)
optimizer.zero_grad()
probs, logits = model(src, tgt)
logits=logits.to(device)
probs=probs.to(device)
loss = criterion(logits.view(-1, logits.size(-1)), tgt_y.view(-1))
print(loss.device)
loss.backward()
optimizer.step()
total_loss += loss.item()
loop.set_description("Epoch {}/{}".format(epoch, epochs))
loop.set_postfix(loss=loss.item())
loop.update(1)
del src
del tgt
del tgt_y
if (batch_idx + 1) % save_after_step == 0:
checkpoint_path = model_dir / f'model_epoch{epoch}_step{batch_idx+1}.pt'
torch.save(model.state_dict(), checkpoint_path)
print(f"Model saved at {checkpoint_path}")
writer.add_scalar('Loss/Train', loss.item(), epoch * len(data_loader) + batch_idx)
return total_loss / len(data_loader)
# 开始训练和验证循环
for epoch in range(epochs):
train_loss = train_epoch(model, train_loader, optimizer, criterion, device, epoch)
print(f"Epoch {epoch+1}, Train Loss: {train_loss:.4f}")
# 保存每个epoch结束后的模型
checkpoint_path = model_dir / f'model_epoch{epoch+1}.pt'
torch.save(model.state_dict(), checkpoint_path)
print(f"Model saved at {checkpoint_path}")
writer.close()
#运行结果
运行结果: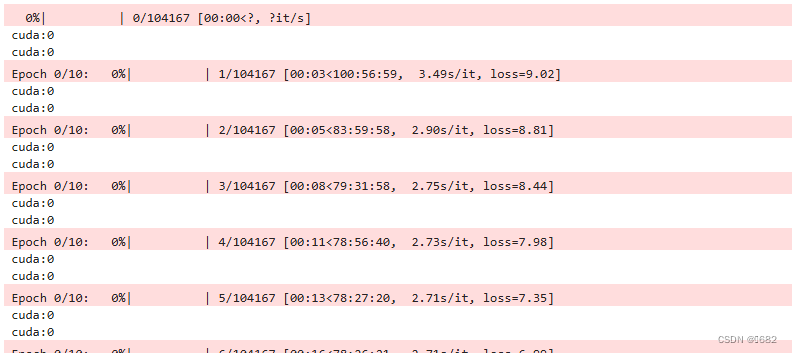
模型的部署在GPU,LOSS输出也在GPU,但是运算不在,还有其中必须要有logits=logits.to(device)才能运行,因为没有的话在第一次运行后模型输出的数据会在CPU上,模型的输入数据也在GPU上,但是运算时gpu利用率不到%2,cpu满载荷运行
求大佬在指点一下















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









