







临近毕业季,又想起了做过的简易聊天机器人chartbot毕业设计,因为算是自己第一次接触这个智能问答领域吧,所以到现在还觉得特别有意思且难忘。我是个行动派,觉得有意思的东西,肯定就要记录下来了。下面我会简要叙述当时我的一些思路以及注意事项,希望对大家有所启示。
1. 解决的实际问题
本项目类似于知识问答系统,就是用户任意输入一段话,我们的系统会自动生成回复内容,并在界面中展示出来。废话不多说,先上图吧!

可以看到简单的对话功能是实现了,和Siri语音对话助手差不多,当然了,功能没那么强大哈!这个不能吹牛b。
2. 工作环境配置
配置环境是你写代码的第一步,也是最基础的一步。很多人会在配置环境这一块崩溃掉,绝对不包括我哈哈哈哈哈。
1) Python3.6 (虽然现在都到了3.7了,但我仍是觉得3.6是目前比较稳定的一个版本,2.7版本都要舍弃了,所以大家不要再使用这个版本了)
2) Pytorch1.4 (建议先装好Anaconda环境,再在pytorch官网用conda命令安装1.4版本的pytorch. 用pip安装总是报bug,亲身经历哈!最后,安装的时候如果网速奇差,反正我每次都是这样,建议直接下载.whl安装包,然后用pip命令在安装包目录下安装,不然你可能会崩溃掉的,相信我,10k的网速你不会同意的)
3) jieba (这是个分词包,版本没限制,好像没出什么问题)
4) torchnet (这个包也是一样的恶心,直接用pip或conda命令在dos界面安装的话,多半是安装到一半给你希望然后直接崩溃报错的,凡是碰到此类状况,听我的,什么也不要做,砸电脑就是了。哈哈哈哈哈哈开个玩笑哈,直接在网上搜torchnet安装包吧,离线下载了只能)
5) fire (这个包没什么限制,正常装上去即可)
最后,我还是想提下,pytorch版本分为CPU版和GPU版。CPU版就是普通的,只在你笔记本上跑,你也不用管什么。有钱的科研大佬自然就懂GPU版本的,比如像我咳咳咳,不要脸又来了哈哈哈。有条件的还是下载GPU版本的Pytorch吧,否则后面训练预料的话电脑基本上会卡住,当然想偷懒只下CPU版本的也行,我会提供一个训练好的模型给大家。
3. 数据预处理
由于我做的是中文聊天机器人,所以选用的训练语料也是中文的。中文的预料集也有很多种类的,大的语料集能有几个G以上的,迷你型的10M左右吧。大的语料集我说过你要是没有GPU这类的硬件支持的话,那别做梦了。当时我也是这样惨兮兮的一员,所以就选取了只有10M的青云预料。当然你也可以选用如小黄鸭这类相当的预料,同样很小,只是内容风格不一样,所以最后问答的内容也会有差异。
得到语料后,我们要做的就是将其分词了,只有分词了才能表示成词向量。有些小白可能会问词向量是什么,百度去!反正就是像计算机只认0和1二进制数字一样,我们的神经网络模型也只认词向量,懂了吧。
我先贴出我项目的结构图吧!
数据提取命令为:
python datapreprocess.py
得到提取好的词向量之后,我们才可以训练模型了。
4. 训练模型
本系统所采用的的神经网络模型主要是基于Seq2Seq模型和Attention注意力机制的。因为机器人聊天系统实际上也相当于机器翻译功能,用户输入给定的语句,然后通过模型生成另一种合适的语句。通常情况下,采用LSTM长短时记忆网络来解决该问题。此处,我们是采用了LSTM模型的进阶版Seq2Seq序列到序列模型。
Seq2Seq模型主要包括Encoder和Decoder两个基本块,其中,encoder负责将输入序列压缩成指定长度的向量,其中的网络结构为两层双向GRU模型;而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,采用了双层单向GRU模型。又因为在Seq2seq模型中,原始编解码模型的encode过程会生成一个中间向量C,用于保存原序列的语义信息。但是这个向量长度是固定的,当输入原序列的长度比较长时,向量C无法保存全部的语义信息,上下文语义信息受到了限制,这也限制了模型的理解能力。所以使用Attention机制来打破这种原始编解码模型对固定向量的限制。Attention机制通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。
代码如下:
class EncoderRNN(nn.Module):
def __init__(self, opt, voc_length):
super(EncoderRNN, self).__init__()
self.num_layers = opt.num_layers
self.hidden_size = opt.hidden_size
# nn.Embedding输入向量维度是字典长度,输出向量维度是词向量维度
self.embedding = nn.Embedding(voc_length, opt.embedding_dim)
# 双向GRU作为Encoder
self.gru = nn.GRU(opt.embedding_dim, self.hidden_size, self.num_layers,
dropout=(0 if opt.num_layers == 1 else opt.dropout), bidirectional=opt.bidirectional)
def forward(self, input_seq, input_lengths, hidden=None):
embedded = self.embedding(input_seq)
packed = torch.nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
outputs, hidden = self.gru(packed, hidden)
outputs, _ = torch.nn.utils.rnn.pad_packed_sequence(outputs)
outputs = outputs[:, :, :self.hidden_size] + outputs[:, :, self.hidden_size:]
return outputs, hidden
class Attn(torch.nn.Module):
def __init__(self, attn_method, hidden_size):
super(Attn, self).__init__()
self.method = attn_method # attention方法
self.hidden_size = hidden_size
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
if self.method == 'general':
self.attn = torch.nn.Linear(self.hidden_size, self.hidden_size)
elif self.method == 'concat':
self.attn = torch.nn.Linear(self.hidden_size * 2, self.hidden_size)
self.v = torch.nn.Parameter(torch.FloatTensor(self.hidden_size))
def dot_score(self, hidden, encoder_outputs):
return torch.sum(hidden * encoder_outputs, dim=2)
def general_score(self, hidden, encoder_outputs):
energy = self.attn(encoder_outputs)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_outputs):
energy = self.attn(torch.cat((hidden.expand(encoder_outputs.size(0), -1, -1),
encoder_outputs), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# 得到score,shape为[max_seq_len, batch_size],然后转置为[batch_size, max_seq_len]
attn_energies = attn_energies.t()
# 对dim=1进行softmax,然后插入维度[batch_size, 1, max_seq_len]
return F.softmax(attn_energies, dim=1).unsqueeze(1)
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, opt, voc_length):
super(LuongAttnDecoderRNN, self).__init__()
self.attn_method = opt.method
self.hidden_size = opt.hidden_size
self.output_size = voc_length
self.num_layers = opt.num_layers
self.dropout = opt.dropout
self.embedding = nn.Embedding(voc_length, opt.embedding_dim)
self.embedding_dropout = nn.Dropout(self.dropout)
self.gru = nn.GRU(opt.embedding_dim, self.hidden_size, self.num_layers,
dropout=(0 if self.num_layers == 1 else self.dropout))
self.concat = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
self.attn = Attn(self.attn_method, self.hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
rnn_output, hidden = self.gru(embedded, last_hidden)
attn_weights = self.attn(rnn_output, encoder_outputs)
# bmm批量矩阵相乘,
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
output = self.out(concat_output)
output = F.softmax(output, dim=1)
return output, hidden好了,模型也巴拉巴拉一大堆了,真的累。虽然大部分是从网上借鉴学习过来的,但是也累啊!大家可别学我啊。模型训练2000次,最终得到训练好的模型参数,并保存至checkpoints文件夹下面。执行语句如下所示:
python train_eval.py train
5. 测试模型
得到了训练好的模型过后,最后一步就是测试模型啦。也是我们最最最期待的一刻啦,终于能和机器人交互了,是不是有点小激动了呢?不激动也得给劳资配合起来哈哈哈哈哈。对了,差点还忘了,我们这个系统还是加了知识库选项的。知识库是什么呢?你让我组织下,简单来说,就是像你考试做小抄一样,提前准备好一些固定的答案,考试时不会做你肯定就是先看小抄吧,小抄上没有你才会想着去偷瞄别人的或者自己啃笔头来计算。不过我们的知识库也是用的小型的,就一百多个问题对吧,有跟没有没多大的差别。
5.1 加入知识库的对话测试
使用知识库时, 需要传入参数use_QA_first=True。此时,对于输入的字符串,首先在知识库中匹配最佳的问题和答案,并返回。找不到时,才调用聊天机器人自动生成回复。这里的知识库是爬取整理的腾讯云官方文档中的常见问题和答案,100条,仅用于测试!
执行命令为:python main.py chat --use_QA_first=True.
效果如下:

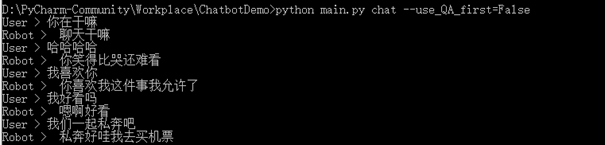
5.2 不加知识库的对话测试
调用聊天机器人自动生成回复
执行命令为:python main.py chat --use_QA_first=False.
效果如下:
6. 小结
上面就是我毕设的简要介绍了,其实很感慨,因为当时碰到了无数恶心的bug,由于没有人指导,完全是自己一个人扛。就这种感受,不知道你有没有感受,可能能把人急哭的那种。没有服务器跑,自己花钱买了一个月的过来用,搜集各种语料集做比较,有的是国外的语料集,由于国内限速,还得去找国外的朋友帮我下下来然后发给我。害,感谢的人也有很多吧,真的很感谢一路过来帮助过我的人,没有你们,我到达不了现在的地步,谢谢,后面煽情了,大家可自行忽略,不骗眼泪。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











