






这是Datawhale暑期AI夏令营的第四期,这一期共有四个方向,该方向为大模型微调方向(Datawhale网站:Docs)。基于讯飞开发者大赛,以星火大模型驱动阅读理解题库构建挑战赛为内容。(竞赛官网:2024 iFLYTEK A.I.开发者大赛-讯飞开放平台 (xfyun.cn))
该赛题的任务要求参赛者基于大模型微调技术,微调适用于高考语文现代文阅读和英语阅读的QAG的大模型,完成输入文章输出问题与答案的任务。大赛将为参赛团队提供免费的模型微调服务平台(讯飞大模型定制训练平台( 大模型定制训练平台 ))。大赛提供了近几年的高考语文现代阅读和英语阅读的数据集(包含原文,题目,答案)用于训练和测试,并且要求必须使用spark-13b模型进行微调。

一、微调步骤
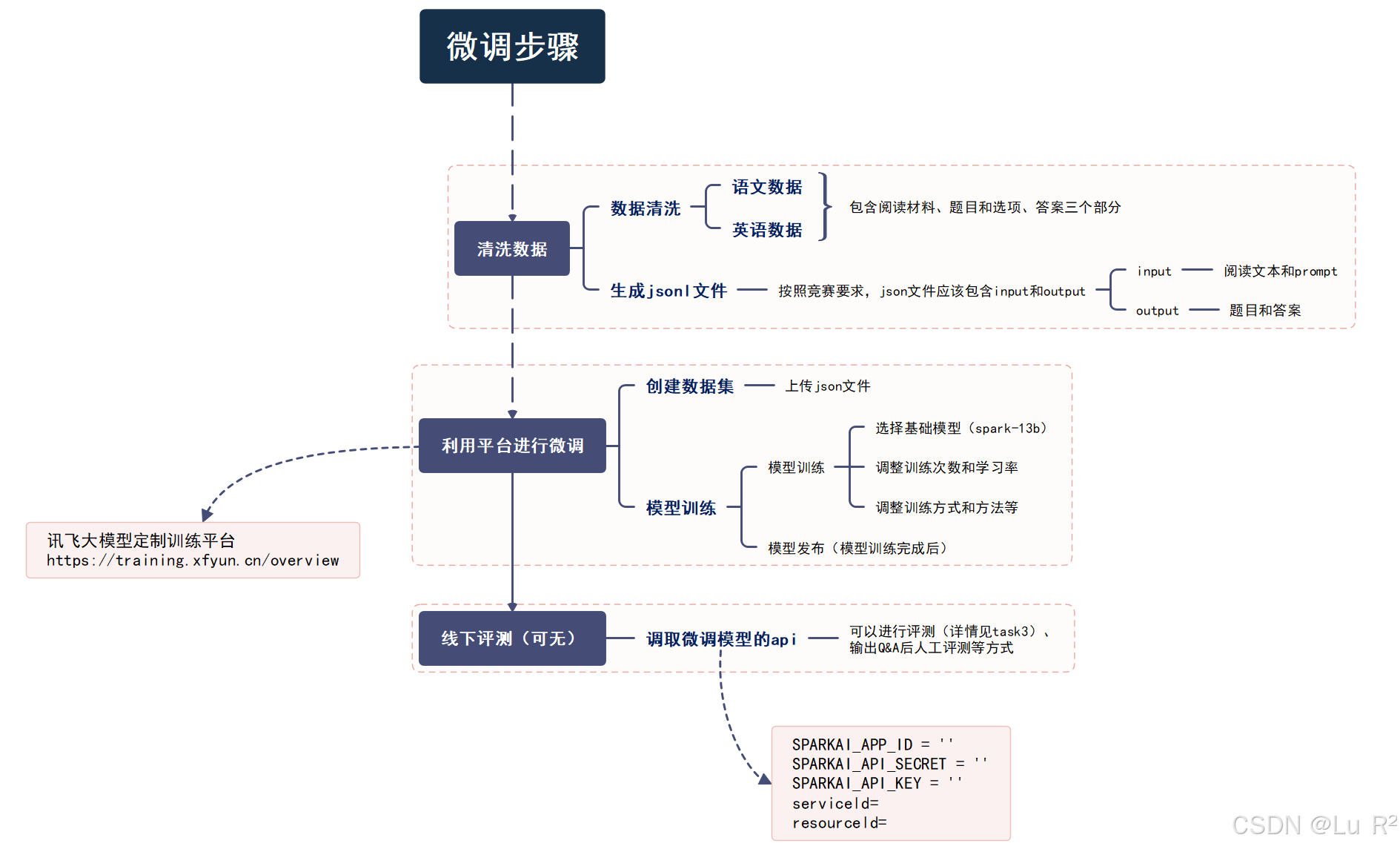
整体步骤虽然看起来复杂,但实际上也就两个大步骤,一个是对于数据的清洗(生成微调需要的json文件),另外一个是利用讯飞提供的线上平台进行微调的工作,之后可以再进行线下的评测。将线下评测结果好的模型上传竞赛网站。
二、代码分析
baseline代码见https://aistudio.baidu.com/projectdetail/8236744
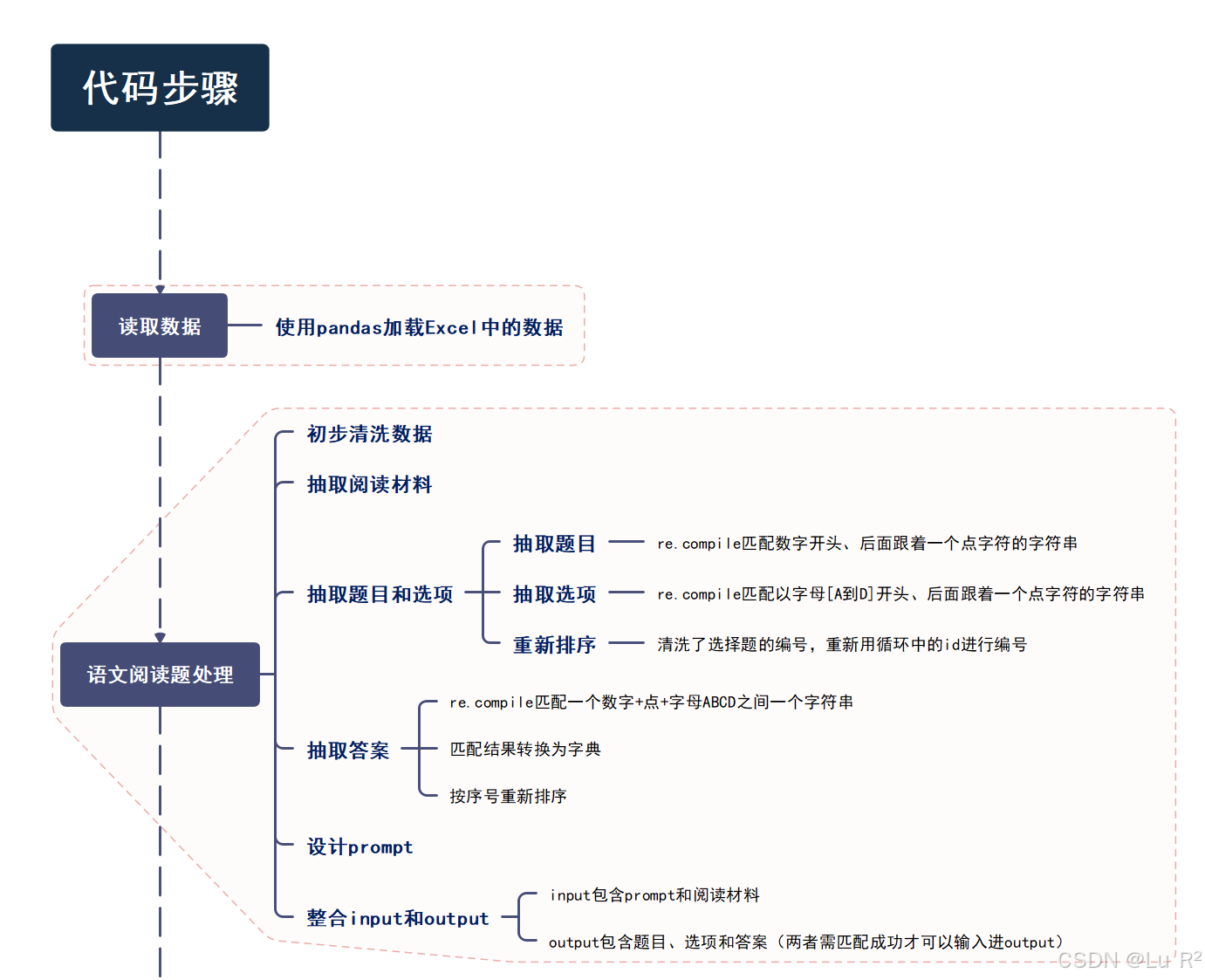
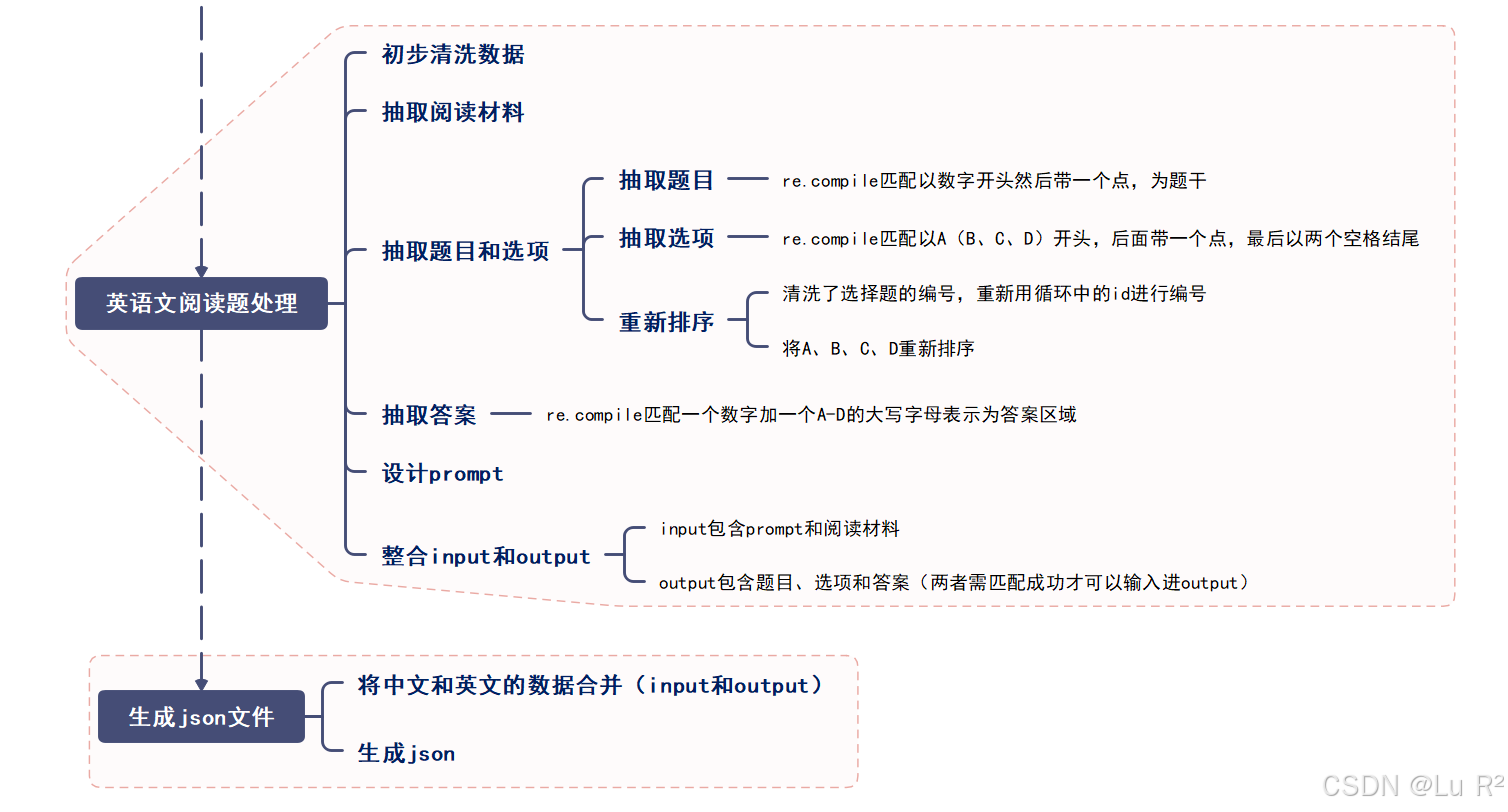
通过思维导图的整理,代码部分分析已经比较有条理,不再进行进一步的详细解读与分析。
三、上分思路
上分思路整体来说有两大思路,一个是数据集,另外一个是优化prompt。
1.数据集优化
1.1深度清洗
对于数据集的优化,可以对赛题组织提供的数据集进行深入清洗,因为数据集问题较大,数据十分混乱,存在长文本无故换行,题号顺序错误以及和答案不匹配,选项之间有的有空格、有的紧贴、还有的有点符号,并无统一的规范等诸多问题。因此,对数据进行深入清洗是十分有必要的,可以采取人工清洗(因为数据集实在太混乱,数据量也不大,人工清洗能快速解决问题)和自动清洗双管齐下的策略。
1.2扩充数据集(真实的题目)
原始数据只包含高考阅读题真题,语文英语数据各只有60余个,而能用的数据就只有五十多个了,如此少量的数据很难起到足够的微调效果,因为,我认为可以选取一定的其他的优质题作为数据补充,这一块可以选取其他省份的合适的高考真题(原始数据都是全国卷的高考题),也可以选取足够优质的模拟题(一模、二模、联考等)。我在这里扩充数据到了各100个。
1.3扩充数据集(使用大模型生成)
原始数据中的很多阅读题都不到四个,所以我们可以通过大模型补充生成四个Q&A,用来丰富数据集,修改后的部分代码如下(这里还是使用了spark星火大模型来生成新的Q&A):
cankao_content = '''
1. 以下哪个选项是“具身认知”的定义?
A. 认知在功能上的独立性、离身性构成了两种理论的基础。
B. 认知在很大程度上是依赖于身体的。
C. 认知的本质就是计算。
D. 认知和心智根本就不存在。
答案:B
2. 以下哪个实验支持了“具身认知”的假设?
A. 一个关于耳机舒适度的测试。
B. 一个关于眼睛疲劳程度的测试。
C. 一个关于人类感知能力的实验。
D. 一个关于人类记忆力的实验。
答案:A
3. 以下哪个选项是“离身认知”的教育观的特点?
A. 教育仅仅是心智能力的培养和训练,思维、记忆和学习等心智过程同身体无关。
B. 教育观认为身体仅仅是一个“容器”,是一个把心智带到课堂的“载体”。
C. 教育观认为知识经验的获得在很大程度上依赖于我们身体的体验性。
D. 教育观认为知识经验的获得在很大程度上依赖于我们大脑的记忆能力。
答案:A
4. 以下哪个选项是“具身认知”带来的教育理念和学习理念的变化?
A. 更强调全身心投入的主动体验式学习。
B. 更注重操作性的体验课堂,在教学过程中将学生的身体充分调动起来,这在教授抽象的概念知识时尤为重要。
C. 更强调教师的教学方法和学生的学习方法。
D. 更注重教师的教学技巧和学生的学习技巧。
答案:A'''
def get_adddata_prompt_rebuild(reading, cankao_content, output):
prompt = f'''
你是一个高考语文阅读题出题专家,请阅读材料,需要参考参考内容 按照要求将题目、选项、答案对其补充完整。
###阅读材料
{reading}
###要求
1.如果选择题目不足四个需要根据参考内容出选择题补充。
2.补充内容格式按照问题、ABCD四个选项顺序、答案的结构组合,按照参考内容格式输出。
3.如果选择题目数量不够四个请根据阅读材料及出题思路再生成题目,总题目达到四个,如果够四个则不做多余补充。
4.题目中不能出现任何不合理的词汇、语法错误。
###参考内容
{cankao_content}
###题目与答案
{output}
'''
return prompt
# 打开并读取JSON Lines文件
list_data = []
with open('output_data_search_prompt.jsonl', 'r') as file:
for line in file:
# 去除行末的换行符
line = line.strip()
# 解析JSON行
data = json.loads(line)
list_data.append(data)
# break
input = []
output_new = []
for data in list_data:
# 处理解析后的数据
inp = data.get('input')
outp = data.get('output')
prompt = get_adddata_prompt_rebuild(reading,cankao_content,outp)
rebuild_output = call_sparkai(prompt)
output_new = [outp + rebuild_output]
input.append(inp)
output_new.append(inp)这部分代码是我经由baseline修改后的,之后将新的output(即output_new,加入了新生成的Q&A)存入新的json文件即可,这样就完成了补全四个Q&A的过程。
但是需要注意的是星火大模型存在很多问题,我在这里就遇到了如下的问题,部分高考阅读材料甚至涉嫌违规。。。。无法生成。所以这里还是建议调用别的大模型的api。

2.prompt优化
我在这里参考了2019年普通高等学校招生全国统一考试大纲来修改prompt。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









