






为什么要使用链式存储结构?
之前在使用顺序存储结构时,它是有缺点的。最大的缺点就是插入和删除时需要移动大量元素,需要耗费大量时间。
为了解决这个问题,就要使用到链式存储结构,简称链表。
链表定义
在以前的顺序结构中,每个数据元素只需要存储数据元素信息就可以了。现在的链式结构中,除了要存储数据元素信息外,还要存储它的后继元素的存储地址。
比如链表中有两个数据元素ai与ai+1,对于数据ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继位置的域称为指针域。指针域中存储的信息称为指针或链,这两个数据元素称为节点,n个结点链结成一个链表.
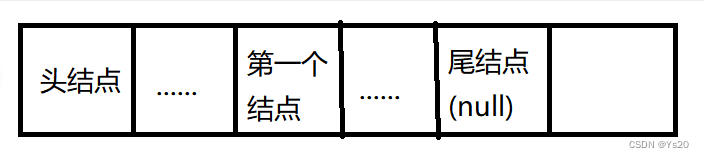
头指针:链表的第一个结点为头指针
头结点:链表的第一个结点前设一个结点,,可以不存放任何数据,称为头结点
规定最后一个结点指针设置为空
头指针与头结点的异同
| 头指针 | 头结点 |
|---|---|
| 链表的第一个结点为头指针,如果有头结点则指向头结点 | 为了操作统一和方便设立,其数据域毫无意义(也可以存放链表的长度) |
| 头指针具有标志作用,一般常用头指针作为链表的名字 | 有了头结点,操作第一结点前,与其他结点的操作就统一了 |
| 无论链表是否为空,头指针都不为空,头指针是链表的必要元素 | 头结点不一定是链表的必须要素 |
链表的基本使用
1.创建结构体
typedef struct Node{
int data;
struct Node *next;
}Node; 2.定义结构体指针
Node* head=NULL,*end=NULL,*p=NULL; 3.头插法
void addHead(int a) //头插法
{
p=(Node*)malloc(sizeof(Node));
p->data=a;
p->next=head->next;
head->next=p;
}4.尾插法
void addData(int a){
//动态申请一个节点空间
p=(Node*)malloc(sizeof(Node));
p->data=a;
p->next=NULL;
end->next=p;
end=p;
}5.遍历链表
void printList()
{
struct Node *temp =head->next; //定义一个临时变量来指向头结点
while (temp !=NULL)
{
printf("%d\n",temp->data);
temp = temp->next; //temp指向下一个的地址 即实现++操作
}
}6.查找指定元素的结点
Node* findNode(int data)
{
Node* temp=head->next;//定义一个临时变量来指向头结点
while(temp!=NULL)
{
if(temp->data==data)
{
return temp;
}else{
temp=temp->next;
}
}
return NULL;
}














 2742
2742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









