







1.链表
1.1链表的概念
1.2链表的分类
链表可通过以下组合分类为八种
1.单向或双向


2.带头或不带头

3.循环或非循环
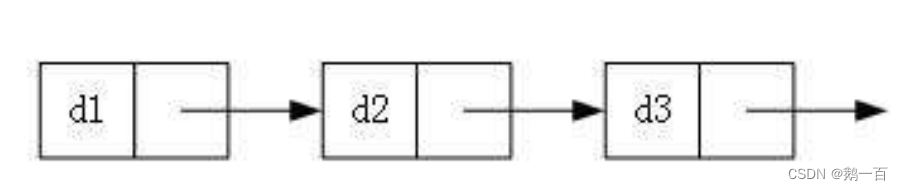
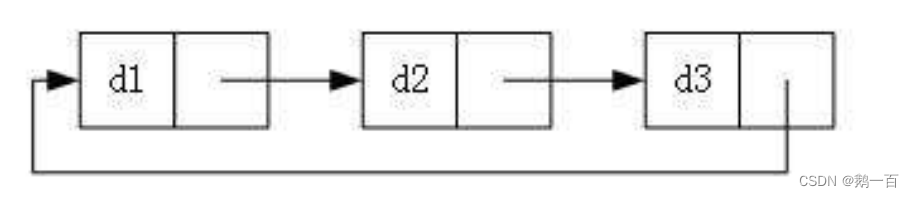
而在我们实际中最常用的有两种:
无头单向非循环链表
带头双向循环链表
2.单链表
2.1单链表的结构
单链表有两个储存区,第一个区域储存该节点的元素,第二个区域储存下一个节点的地址
//单链表的结构
struct SListNode
{
SLDatatype data;//该节点的元素
struct SListNode* next;//通过指针指向下一个节点的地址
}2.2单链表的基本操作
2.2.1 动态申请一个列表节点
在单链表中,无论是在哪一个位置插入数据,都需要新开辟一块空间来存储该节点,而不是像顺序表里数组预留了空间来存储数据。故我们可以先通过一个函数来实现开辟这一操作,避免往后多次重复一段代码。
//新开辟一个节点
SListNode* BuySListNode(SLTDateType x)
{
SListNode* tmp = (SListNode*)malloc(sizeof(SListNode));//开辟节点
if (tmp == NULL)
{
perror("malloc fail");
return;
}//检查节点是否开辟成功
tmp->data = x;
tmp->next = NULL;//初始化节点
return tmp;
}2.2.2 单链表的打印
打印单链表只需遍历每一个节点,然后在遍历中打印出每一个节点的数据即可。
而单链表的遍历,我们需要学会使用while循环
//我们假设plist是单链表首个节点的地址
while(plist)
{
plist=plist->next;
}这个循环的意思是,当plist为NULL,即表达式为假,退出循环。而若plist不为NULL,plist等于plist指针域指向的下一个元素,即将plist移向下一个节点
// 单链表打印
void SListPrint(SListNode* plist)
{
while (plist)
{
printf("%d->", plist->data);//打印该节点的元素
plist = plist->next;//plist指向下一个节点
}
printf("NULL\n");
}2.2.3单链表的头插
对于单链表的插入,我们首先要检查链表是否为空,如果不为空,则只需要让新节点的next指向头节点,然后plist指向新节点即可。而若为空,则新节点next无法指向plist,因为plist并不是一个结构体而只是一个指针,所以这个时候我们需要让plist直接指向新节点。
// 单链表的头插(错误)
void SListPushFront(SListNode* pplist, SLTDateType x)
{
SListNode* NewNode = BuySListNode(x);
if (pplist == NULL)
{
pplist = NewNode;
}
else
{
NewNode->next = pplist;
pplist = NewNode;
}
}而这个时候我们尝试向空链表依次头插1,2,3,4这几个元素,但是结果出来链表仍未空,为什么?
因为这涉及到C语言的一个知识点:指针的传参。
当我们需要改变一个指针变量时,我们不能单单只传入一个一级指针,因为指针变量传一级指针,在函数中其仍未一个局部变量,所以我们需要传入二级指针才可以修改指针的地址。
修改后的正确代码:
// 单链表的头插(正确)
void SListPushFront(SListNode** pplist, SLTDateType x)
//传入二级指针以修改指针的地址
{
SListNode* NewNode = BuySListNode(x);
if (*pplist == NULL)
{
*pplist = NewNode;
}
else
{
NewNode->next = *pplist;
*pplist = NewNode;
}
}2.2.4单链表的尾插
和单链表的头插同理,我们只需遍历整个链表找到尾结点,然后将尾结点的next修改为新节点即可
(注:1.我们可不可以直接使用*pplist进行遍历?
不行!!!
因为如果用*pplist进行遍历,则会修改头指针plist的地址使其指向尾结点,从而无法再找到头结点。
2.我们怎么判断应该遍历到哪一个节点?
)
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
SListNode* NewNode = BuySListNode(x);
SListNode* Lhead = *pplist;
//用一个新的形参来进行遍历
if (*pplist == NULL)
{
*pplist = NewNode;
}
else
{
while (Lhead->next)//遍历到尾结点
{
Lhead = Lhead->next;
}
Lhead->next = NewNode;
}
}2.2.5单链表的头删
和顺序表一样,单链表的头删也必须要判断单链表不为空,否则可能会产生越界。
而删除节点和顺序表不同的是,顺序表不需要考虑删除的元素空间,而链表需要free掉删除的空间,否则会发生内存泄漏
// 单链表头删
void SListPopFront(SListNode** pplist)
{
assert(*pplist);
SListNode* phead = *pplist;
*pplist = phead->next;
free(phead);
}2.2.6单链表的尾删
对于单链表的尾删,我们需要遍历到尾结点的前一个结点(具体详见2.2.4的链接)
而此时便会产生一个新的问题:单链表只有一个节点应该怎么办?
对于特殊极端情况,我们不得不用if语句分类来判断
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{
assert(*pplist);
//链表为空的情况
SListNode* phead = *pplist;
if (phead->next == NULL)
{
*pplist = NULL;
}
//只有一个节点的情况
else
{
while (phead->next->next)
{
phead = phead->next;
}
free(phead->next);
phead->next = NULL;
}
//其它情况
}通过以上代码我们不难发现,对于一个函数接口一定需要将所有情况全部考虑进去,这也是我们在以后的调试中需要经常注意的地方。
2.2.7单链表的查找
遍历整个链表,在遍历的过程中对比每一个元素,如果相同则返回元素的节点,如果遍历结束也没有相同便返回空指针
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x)
{
while (plist)
{
if (plist->data == x)
{
return plist;
}
plist = plist->next;
}
return NULL;
}2.2.8单链表在任一位置之后的插入
为什么不在任意位置之前插入?
因为如果在任意位置之前插入,我们不方便寻找上一个节点,也就不方便使上一个节点的next指向新节点,故我们通常采用更方便的任意位置之后插入(在C++库函数中也使用任意位置时候插入)
void SListInsertAfter(SListNode* pos, SLTDateType x)
{
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}2.2.9单链表删除任意位置之后的节点
同插入,我们更方便去寻找下一个节点,故通常采用任意位置后节点的删除而非当前位置节点的删除
void SListEraseAfter(SListNode* pos)
{
assert(pos)
assert(pos->next)
SListNode* erase = pos->next;
pos->next = pos->next->next;
free(erase);
}2.2.10单链表的销毁
我们只需遍历整个链表,释放每一个节点的空间,然后将头指针指向空即可
// 单链表的销毁
void SListDestroy(SListNode* plist)
{
while (plist)
{
struct SListNode* destroy = plist;
plist = plist->next;
free(destroy);
}
}3.带头双向循环链表
3.1带头双向循环链表的结构
与单链表相比,带头双向循环链表是另一种极端的结构,它每一个节点储存三个信息:该节点的元素,上一个节点的地址,下一个节点的地址
//带头双向循环链表的结构定义
typedef struct ListNode
{
LTDataType data;//该节点的元素
struct ListNode* next;//下一个节点的地址
struct ListNode* prev;//上一个节点的地址
}ListNode;3.2带头双向循环链表的基本操作
3.2.1带头双向循环链表的创建
因为该链表的结构有哨兵节点,所以我们需要通过创建来作为带头双向循环链表的头结点,头结点不存储有效数据,仅仅只存储上下节点的地址,且无法删除头结点
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode* newhead = (ListNode*)malloc(sizeof(ListNode));
newhead->data = -1;//-1代表不为有效数据
newhead->next = newhead;
newhead->prev = newhead;
return newhead;
}3.2.2带头双向循环链表的头插尾插头删尾删
在插入和删除方面,带头双向循环链表便显得方便不少。
对于单链表,插入和删除需要遍历整个链表才可以访问到尾部节点
而对于带头双向循环链表,只需要访问头结点的上一个节点便可以访问到尾结点,效率极高
(我们仅仅以尾插为例来说明,其它操作同理)
在进行带头双向循环链表的尾插时,我们不妨画一个结构图来更便于我们理解

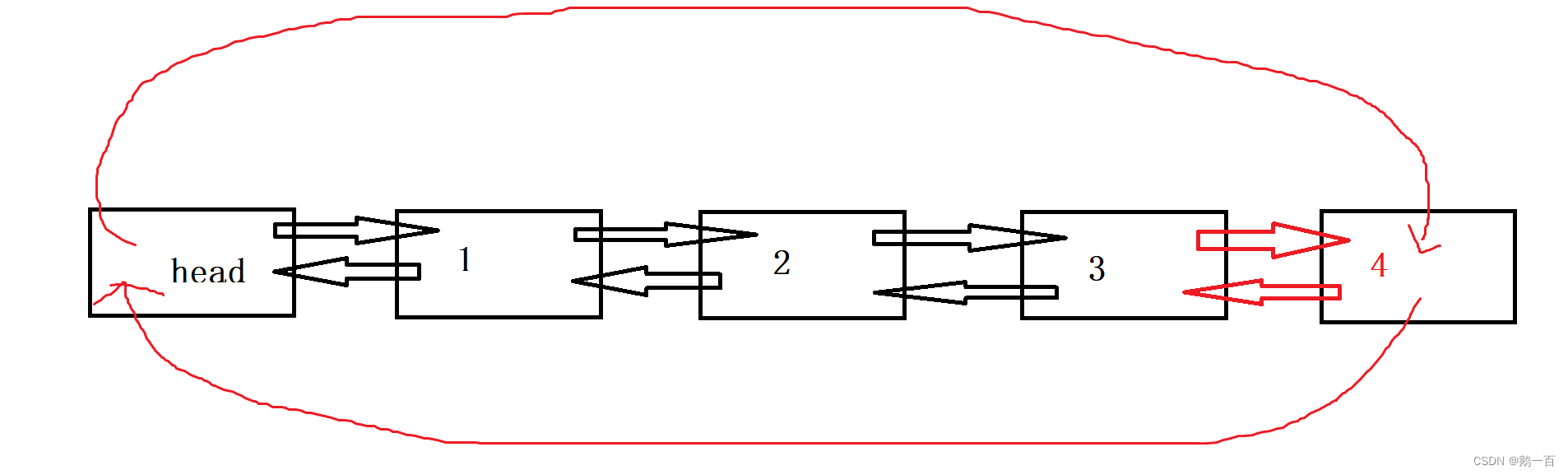
如图,我们只需改变图像中红色的箭头便可
以文字来表示:
需要改变的节点有head,尾结点和新尾结点
改变的方式:
- head的上一个节点指向新尾结点;
- 新尾结点的上一个节点指向旧尾结点;
- 新尾结点的下一个节点指向head;
- 旧尾结点的下一个节点指向新尾结点;
同时,我们最好通过新建变量的方式来对节点进行操作,否则可读性很差
在链表中不要害怕多使用变量,可读性强才是王道
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* tail = pHead->prev;
ListNode* newnode = BuyListNode(x);
tail->next = newnode;
pHead->prev = newnode;
newnode->next = pHead;
newnode->prev = tail;
}
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(pHead->next!=pHead);
ListNode* tail = pHead->prev;
ListNode* tailprev = tail->prev;
pHead->prev = tailprev;
tailprev->next = pHead;
free(tail);
}
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newnode = BuyListNode(x);
ListNode* first = pHead->next;
newnode->next = first;
newnode->prev = pHead;
pHead->next = newnode;
first->prev = newnode;
}
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(pHead->next != pHead);
ListNode* first = pHead->next;
ListNode* second = first->next;
pHead->next = second;
second->prev = pHead;
free(first);
}3.2.3带头双向循环链表的查找
与单链表的查找不同,单链表只需遍历到尾结点,即尾结点的next为空,便可以判断遍历完成,停止遍历,而带头双向循环链表怎么判断遍历到尾结点呢?
因为其循环的性质,我们可以判定尾结点独有的特征:下一个节点是头结点
所以我们可以以cur指向头结点为循环结束条件,即cur完整遍历了一周
不过我们需要cur定义为head->next,否则若定义为cur,无法进入循环
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}













 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









