






文章目录
前言
最近学校开始上Hadoop的课程,为了上课书包更轻,于是决定在mac上部署完全分布式集群。
一、环境说明
| 物理机 | MacOS M2 |
| 虚拟机 | Parallels Desktop |
| 操作系统 | CentOS 9 |
| SSH工具 | Finalshell |
| JDK | jdk-8u321-linux-aarch64.tar.gz |
| Hadoop | hadoop-3.3.1-aarch64.tar.gz |
二、具体配置
1.下载虚拟机及centos
Parallels Desktop 可以让 macOS 与 Windows 应用程序之间共享文件和文件夹,支持不同平台间直接复制粘贴文本或图像,也可以用鼠标在不同系统之间拖放文件,但是这个软件比较贵,建议…嗯。
虚拟机操作系统我选择的是centos9(mac m芯片选择ARM64):点击下载,比较大有9个G。

安装centos网上优秀教程众多,不再单独说明,参考教程:
(超详细)Parallels Desktop安装Centos 7.7 https://www.jianshu.com/p/5f66c7e5d364
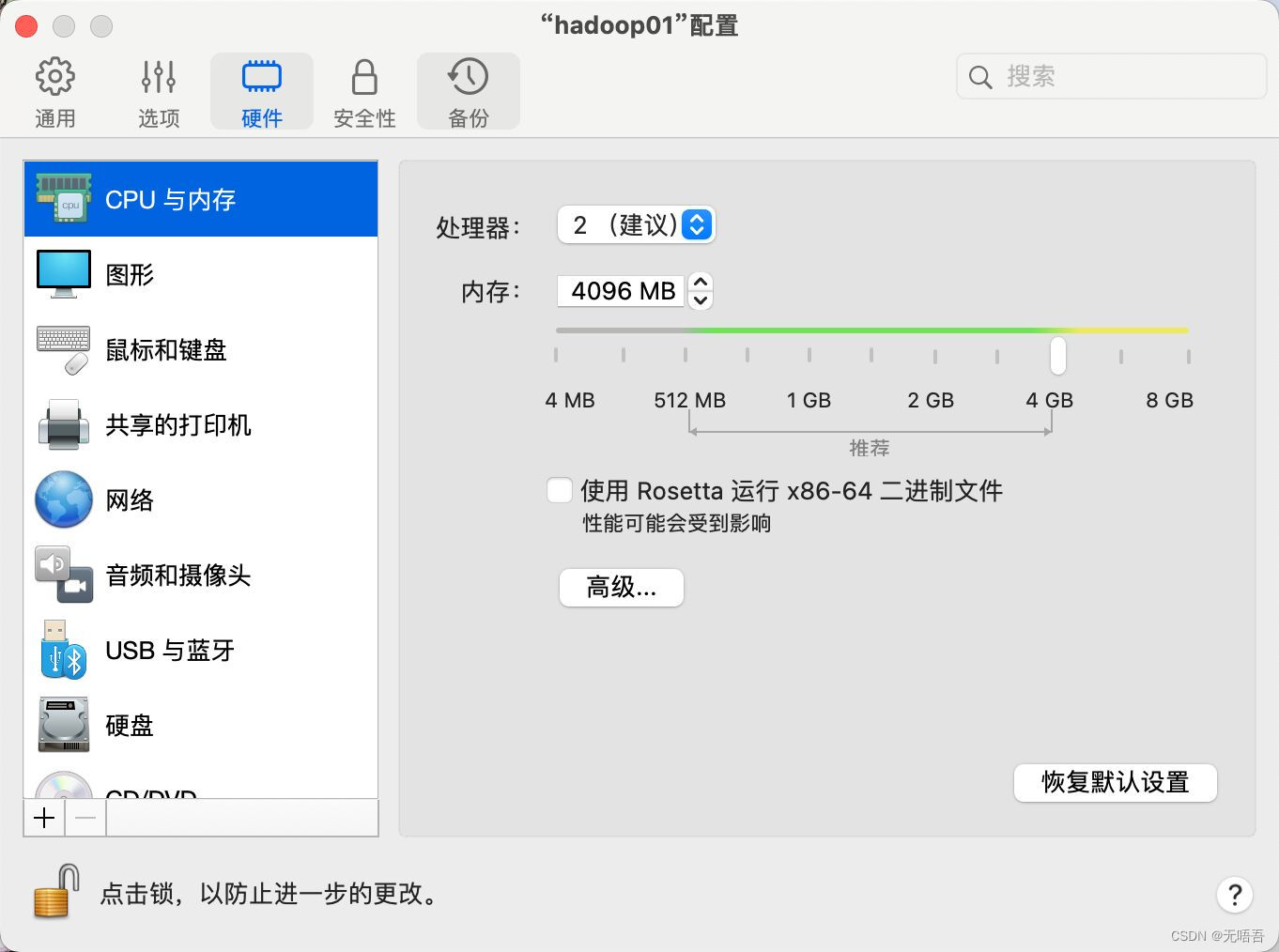
需要提一下的是,如果后续要进行持续的大数据的学习,内存至少选4G,只是学习hadoop选择至少2G
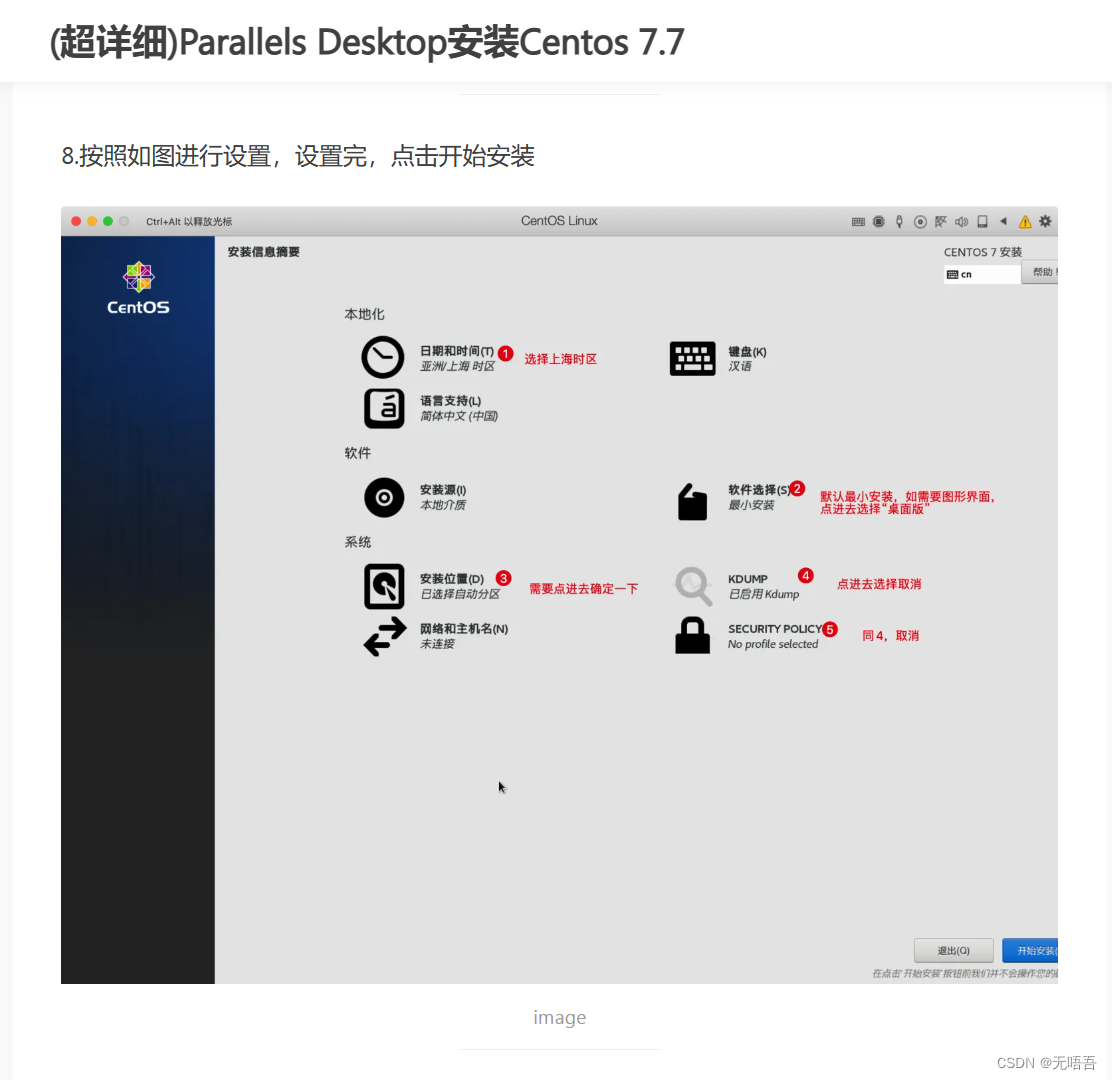
软件安装哪里不推荐选择minimal install,里面很多东西都需要自己装,建议选择server,需要图形界面就选server with GUI
然后ip修改这里,你可以在安装centos中,点击网络和主机名(上图),事先配置好,而不用向下图一样配置比较麻烦
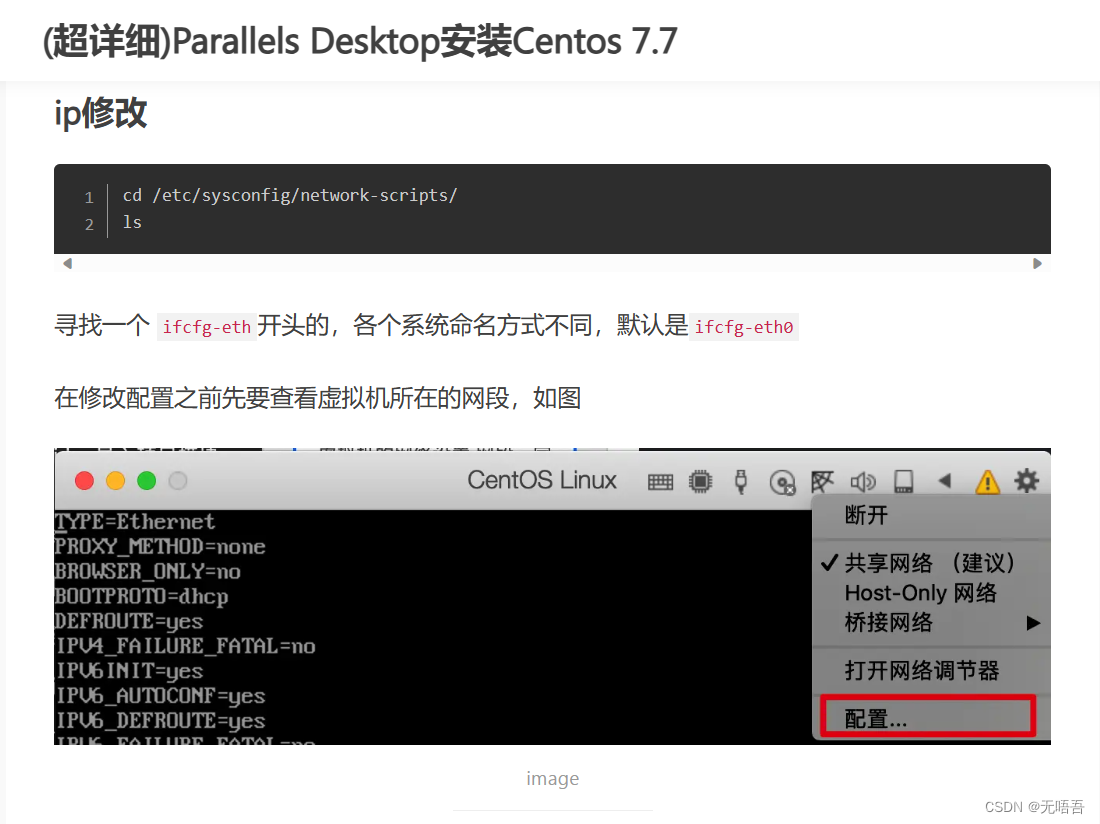
讲一下怎么配置,点击网络和主机名,会进入到如下界面,下面的以太网旁边的按钮先不要开启,(开启了也没关系),页面左下角的是你的主机名配置即hostname,你可以在这里设置好,也可以后面通过命令配置。然后点击界面右下角的配置,进去之后,因为我们后续会使用Finalshell远程连接虚拟机,所有这里不能选择自动DHCP,点击ipv4,然后选择手动,点击add,输入给这台虚拟机设定的ip,这个ip需要和你的mac一个网段,否则后面可能无法上网,或者无法远程连接
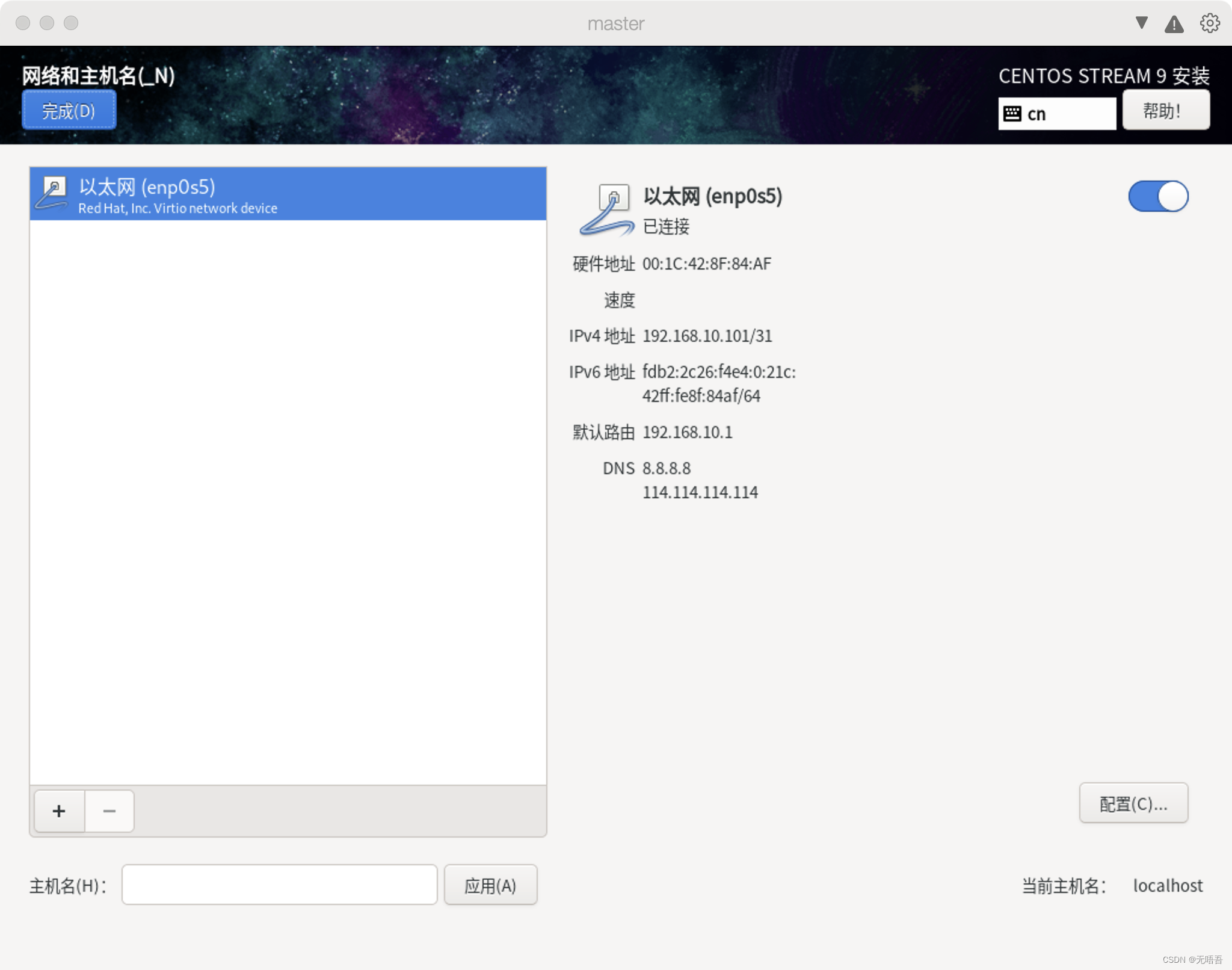
怎么确定mac所在的网段呢,打开Parallels Desktop,mac右上角会有个图标

点击这个图标,选择偏好设置
这里显示的就是你mac所在的网段
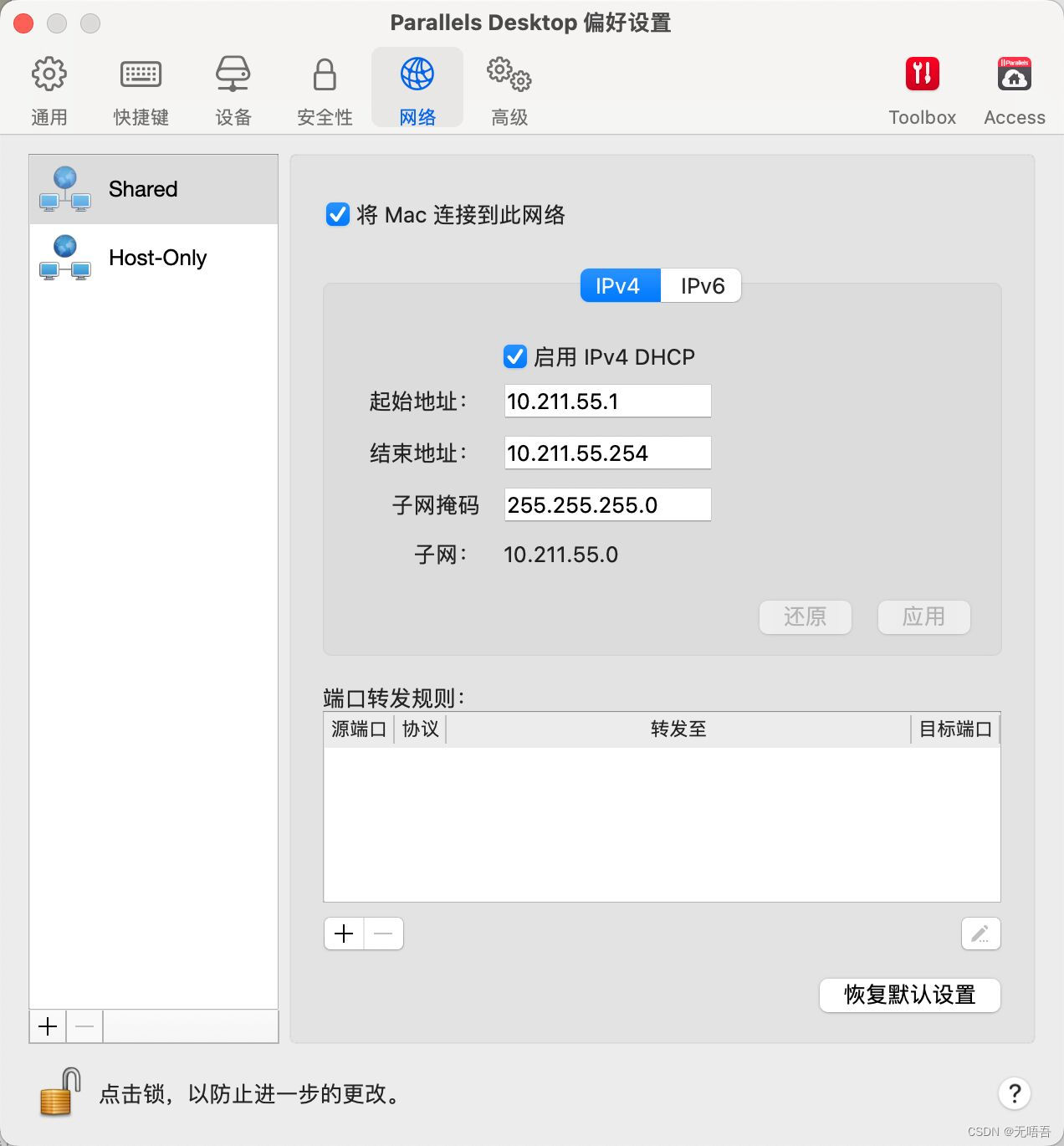
你只需要在这个ip范围内选择一个可用的ip分配给虚拟机即可,将ip,子网掩码和网关填入刚刚的配置,DNS服务器可以填8.8.8.8,114.114.114.114 都填好之后,点击保存,这个时候在开启以太网旁边的蓝色按钮,显示已连接即配置成功,然后点击完成,点击继续,等待一段时间centos安装完毕,点击重启系统。
安装好虚拟机后,如果还想修改ip地址,可以重新配置网卡的配置文件,centos9的配置文件不在
/etc/sysconfig/network-script 而在 /etc/NetworkManager/system-connections/ 中,输入命令:
vim /etc/NetworkManager/system-connections/
后面的修改跟上面给的参考教程是一样的,设置完成保存退出之后,别忘了重启网卡
nmcli c reload
nmcli c up enp0s5
ip设置好之后可以ping www.baidu.com 验证
2.下载Finalshell
Download
http://www.hostbuf.com/downloads/finalshell_install.pkg
安装使用教程参照:
超级详细的 FinalShell 安装 及使用教程
3.下载JDK和Hadoop
jdk下载需要oracle的账号,自己注册一个就行比较简单,如果懒,可以下载我提供的软件包
链接:https://pan.quark.cn/s/518015a237e9
提取码:qz2z
4.远程连接虚拟机
先修改主机名,因为安装centos时,hadoop01的静态ip已经配置好了,这里就不用再配置了
hostnamectl set-hostname 主机名 #取名比如hadoop01
#查看主机名
hostname
然后关闭防火墙
[root@hadoop01 ~]# systemctl stop firewalld
[root@hadoop01 ~]# systemctl disable firewalld
打开Finalshell按照上面的使用教程连接好虚拟机,如果一直显示连接操作超时,一般是虚拟机的ip设置不对,按照上面讲的重新配置。如果是不断跳出弹窗要求输入密码,可以先检查一下虚拟机有没有ssh(一般centos都是自带ssh的)
ssh version
如果没有就下载(不是root用户,命令前加sudo)
#下载
yum install openssh-server
#开启ssh
sudo systemctl start sshd
sudo systemctl enable sshd
如果有还是不断弹出来,检查一下你的用户密码ip填写是否正确,都正确,在虚拟机输入
vim /etc/ssh/sshd_config
取消PermitRootLogin 的注释,并将后面的内容修改为yes

重启ssh
service sshd restart
再回Finalshell连接显示连接成功,创建一个目录
mkdir /root/softwares
将下载好的hadoop和jdk压缩包放进去,放好之后关闭节点hadoop01
poweroff
5.虚拟机克隆
克隆两台虚拟机
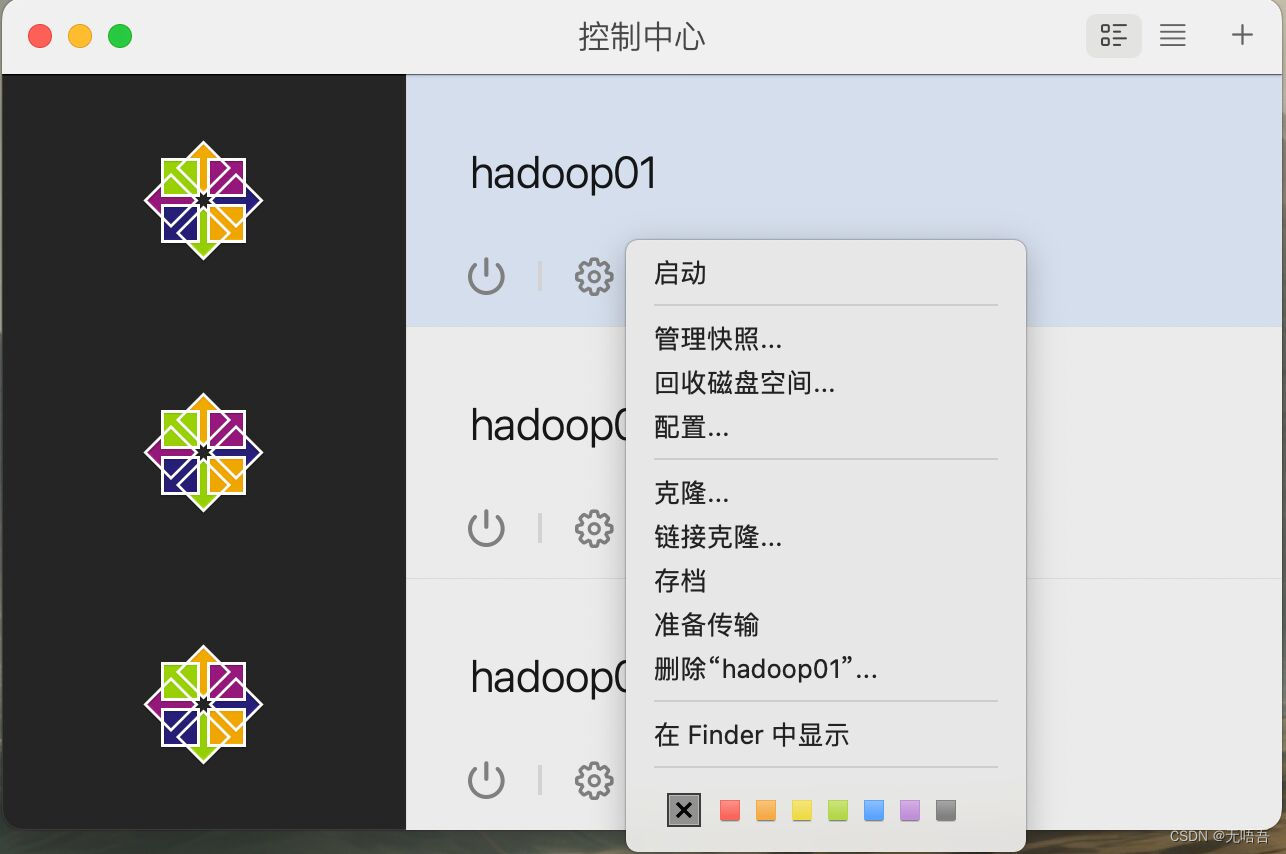
克隆好之后先不要打开hadoop01,先点击hadoop02的设置,点击网络,选择高级,选择重新生成mac地址
然后将hadoop02开机,修改主机名:
hostnamectl set-hostname 主机名 #取名比如hadoop02
#查看主机名
hostname
vim /etc/NetworkManager/system-connections/
将ipv4下的address1后的ip值改为跟hadoop01不一样的ip值
eg:198.110.11.101 --> 198.110.11.102
设置完成保存退出之后,别忘了重启网卡
nmcli c reload
nmcli c up enp0s5
可以ping www.baidu.com 验证,然后hadoop03同理,都完成后将hadoop01也开机用finalshell远程连接三台虚拟机
6.ssh免密登录
再次确认三台虚拟机的防火墙的状态
systemctl status firewalld
#若为running,则需关闭
systemctl stop firewalld
systemctl disable firewalld
主机映射(三台虚拟机都需要做主机映射,这里以hadoop01为例)
[root@hadoop01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 hadoop01 #添加本机的静态IP和本机的主机名之间的映射关系
192.168.10.102 hadoop02 #前面的ip都填自己之前手动设置的静态ip
192.168.10.103 hadoop03 #后面的主机名是三台虚拟机的hostname
开始配置免密登录
#生成公钥和私钥,一直按enter即可
[root@hadoop01 ~]# ssh-keygen -t rsa
# 拷贝给自己和其他节点
[root@hadoop01 .ssh]# ssh-copy-id hadoop01
[root@hadoop01 .ssh]# ssh-copy-id hadoop02
[root@hadoop01 .ssh]# ssh-copy-id hadoop03
#这是以hadoop01为例,另外两个节点也要输入这些命令
7.时间同步
[root@hadoop01 ~]# crontab -e
#输入下面的内容然后保存退出,也是三个节点都要做时间同步
* * * * * /usr/sbin/ntpdate -u ntp.aliyun.com > /var/null 2>&1
8.配置Hadoop
为了方便,我们只在hadoop01上配置,配置好后直接分发给hadoop02,hadoop03,所以下面的操作都在hadoop01上即可。
将hadoop和jdk都解压在/usr/local/ 下
cd softwares
tar -zxvf jdk-8u321-linux-aarch64.tar.gz -C /usr/local/
tar -zxvf hadoop-3.3.1-aarch64.tar.gz -C /usr/local/
vim /etc/profile
#在末尾添加
export JAVA_HOME=/usr/local/jdk1.8.0_321
export HADOOP_HOME=/usr/local/hadoop-3.3.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#保存后退出
source /etc/profile
之后我们开始配置Hadoop的配置文件,Hadoop的配置文件在/usr/local/hadoop-3.3.1/etc/hadoop/ 下
vim core-site.xml
#添加以下内容到configuration中
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9820</value>
<!-- hadoop01替换成自己的主节点 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.1/tmp</value>
</property>
vim hdfs-site.xml
#添加以下内容到configuration中
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
<!-- hadoop02替换成自己的从节点 -->
</property>
vim hadoop-env.sh
#添加以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_321
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Hadoop3后,slaves文件更名为workers文件
vim workers
#删掉里面的localhost,添加自己的三个节点的主机名,
hadoop01
hadoop02
hadoop03
vim mapred-site.xml
#添加以下内容到configuration中
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
vim yarn-site.xml
#添加以下内容到configuration中
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
<!-- hadoop01替换成自己的主节点 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
都配置好后,将hadoop01的配置文件拷贝到hadoop02和hadoop03
[root@hadoop01 ~]# cd /usr/local
[root@hadoop01 local]# scp -r jdk1.8.0_321/ hadoop02:$PWD
[root@hadoop01 local]# scp -r jdk1.8.0_321/ hadoop03:$PWD
[root@hadoop01 local]# scp -r hadoop-3.3.1/ hadoop02:$PWD
[root@hadoop01 local]# scp -r hadoop-3.3.1/ hadoop03:$PWD
[root@hadoop01 local]# scp /etc/profile hadoop02:/etc/
[root@hadoop01 local]# scp /etc/profile hadoop02:/etc/
#记得要分别进入hadoop02和hadoop03输入命令source /etc/profile
然后格式化集群
hdfs namenode -format
9.启动Hadoop集群
我们的配置已经全部做好了,接下来启动集群
start-dfs.sh
start-yarn.sh
打开mac的浏览器输入网址hadoop01的ip:9870

输入hadoop01的ip:8088
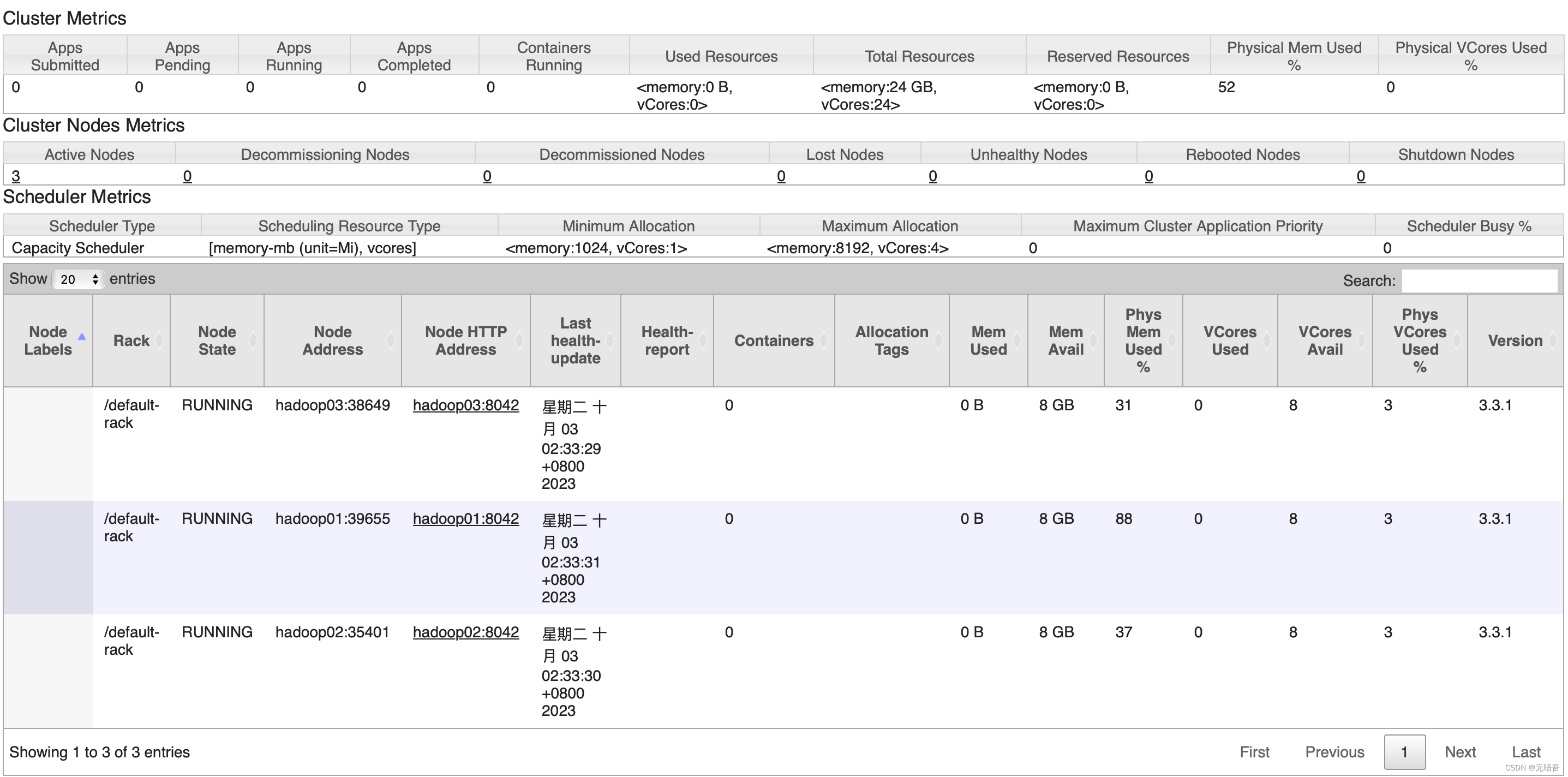
除了web界面外,使用jps 命令也可以查看当前节点的进程。如果要退出集群输入:
stop-dfs.sh
stop-yarn.sh
至此我们已经成功在mac上搭建了完全分布式集群。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









