






一、简介
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,操作接口采用类SQL语法,提供快速开发的能力, 避免了去写MapReduce,减少开发人员的学习成本, 功能扩展很方便。
用于解决海量结构化日志的数据统计。本质是:将 HQL 转化成 MapReduce 程序
二、启动方式
需要先启动hdfs和yarn,hive数据最终保存在hdfs,
启动hive 在hive下运行 : nohup bin/hiveserver2 & 和 hive --service metastore 1>/dev/null 2>&1 & , 然后查看 查看 netstat -tunl 是否启动成功;
三、基本的操作命令
1.查看数据库: show databases ; 查看表: show tables;
2.创建数据库:create database 数据库名;
3.删除数据库: DROP DATABASE IF EXISTS 数据库名(不建议操作)
4.使用数据:use 数据库名;
5.建表
create table if not exists user(
id string,
name string
) row format delimited fields terminated by ",";
6.修改表
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
7.删除表
DROP TABLE [IF EXISTS] table_name;
8.导入数据
load data local inpath "data" into table compute_stats();
9.创建视图
CREATE VIEW emp_30000 AS SELECT * FROM table> WHERE score>70;
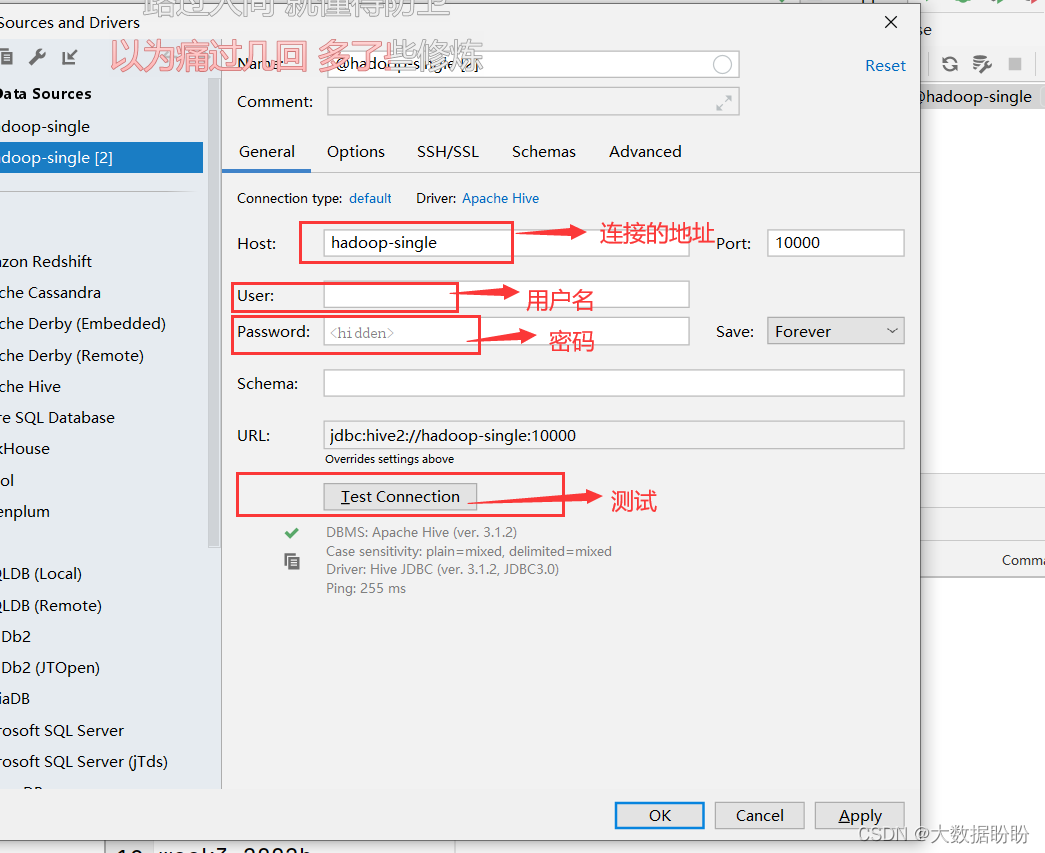
四、IDEA 连接hive















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









