







目录
数组和链表的区别
数组是一个相同数据类型的元素的集合,它的存储区间是连续的, 在使用前需要提前申请所占内存的大小,如果提前不知道需要的空间大小时,预先申请就可能会浪费内存空间,即数组的空间利用率较低。 因为数组的内存是连续的,想要访问那个元素,直接从数组的首地址向后偏移就可以访问到了,所以,数组的随机访问效率很高,时间复杂度可以达到O(1)。但是,向数组插入数据时,待插入位置的元素和他后面的所有元素都需要向后搬移,删除数据时,待删除位置后面的所有元素都需要向前搬移,所以数组的插入和删除的效率较低,时间复杂度为O(n)。
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。它由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成,它所占用的大小和位置是不需要提前分配的。链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置,因此,在链表中查询一个元素的效率较低,时间复杂度为O(n)。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了,时间复杂度为O(1)。
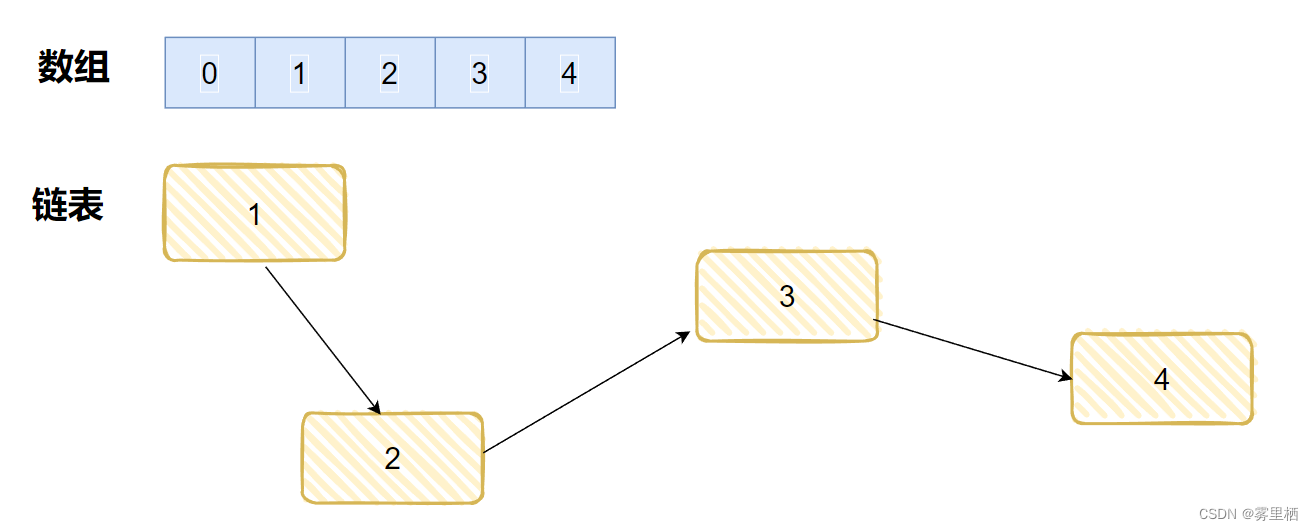
链表的组成
链表是由数据域和指针域两部分组成的,它的组成结构如下:

单向链表
单向链表是最简单的链表,它包含两个域,一个数据域和一个指针域,指针域用于指向下一个节点,而最后一个节点则指向一个空值
单链表的遍历方向单一,只能从链头一直遍历到链尾。它的缺点是当要查询某一个节点的前一个节点时,只能再次从头进行遍历查询,因此效率比较低。
单向链表的节点
class LinkNode
{
public:
LinkNode(int d = -1, LinkNode* ptr = nullptr):val(d),next(ptr)
{
}
int val;
LinkNode* next;
};创建链表时,通常引入一个虚拟头结点。虚拟头节点是一个在链表头部添加的额外节点,它不存储任何实际的数据,只是作为辅助。虚拟头节点的引入可以简化链表操作的逻辑,并解决一些特殊情况下的边界问题。比如,删除头结点等。
class LinkList {
public:
LinkList()
{
dummy = new LinkNode;
}
~LinkList()
{
LinkNode* cur = dummy;
LinkNode* tmp = nullptr;
while (cur != nullptr)
{
tmp = cur;
cur = cur->next;
delete tmp;
}
}
private:
LinkNode* dummy;
};添加节点
在头部添加节点
void LinkList::addToHead(int val)
{
LinkNode* cur = new LinkNode(val, dummy->next);
dummy->next = cur;
}如果想要在尾部添加添加节点,可通过在设置一个tail指针指向最后一个节点来实现。
在链表的指定位置n添加节点
void LinkList::addToList(int val, int n)
{
if (n <= 1)
{
addToHead(val);
return;
}
LinkNode* cur = dummy;
for (int i = 0; i < n - 1 && cur->next != nullptr; i++)
{
cur = cur->next;
}
LinkNode* newnode = new LinkNode(val,cur->next);
cur->next = newnode;
return;
}在第3个位置添加元素100
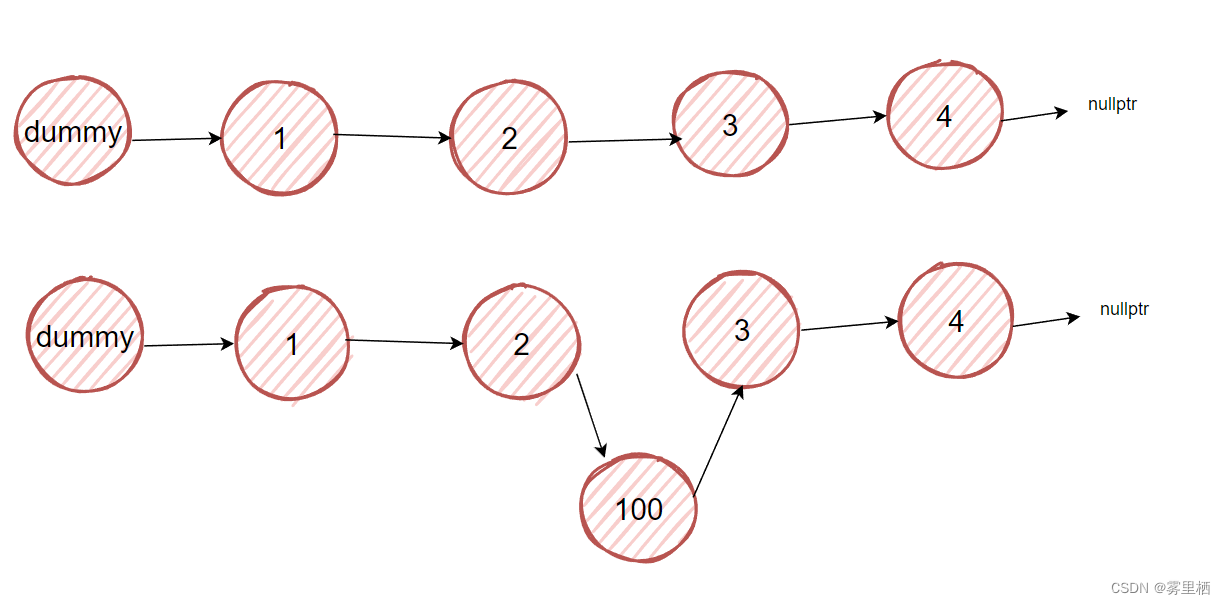
删除节点
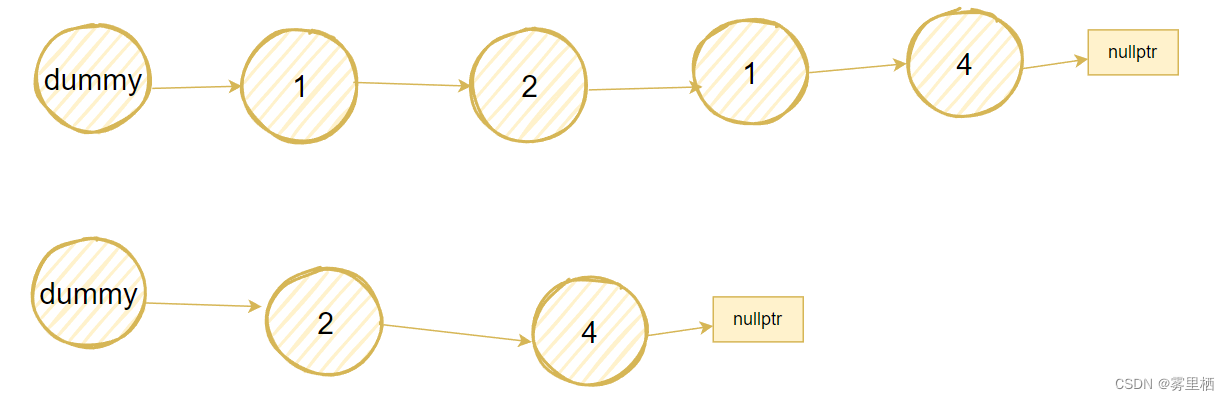
删除链表中元素为x的所有节点
void LinkList::deleteByValue(int v)
{
LinkNode* cur = dummy->next;
LinkNode* pre = dummy;
while (cur != nullptr)
{
if (cur->val == v)
{
LinkNode* tmp = cur;
cur = cur->next;
pre->next = cur;
delete tmp;
continue;
}
cur = cur->next;
pre = pre->next;
}
}
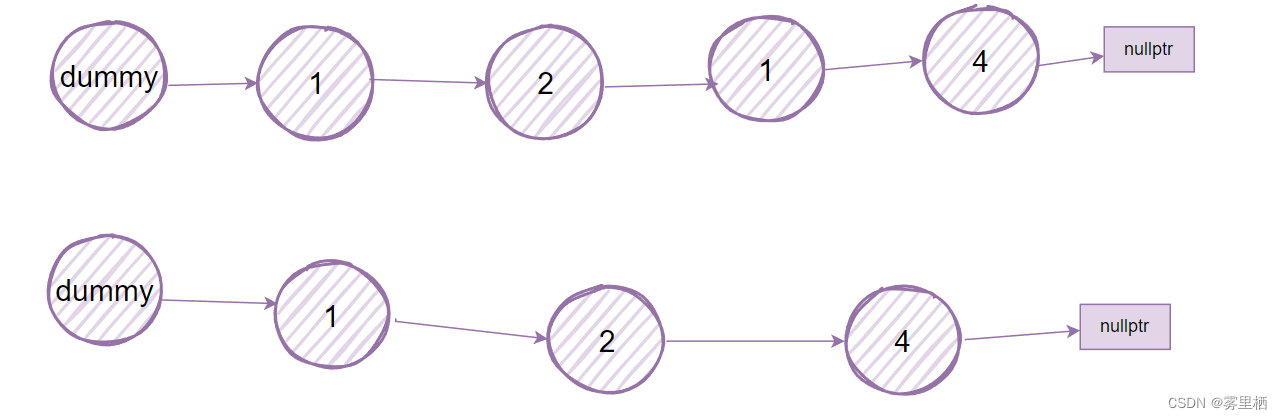
删除第n个节点
void LinkList::deleteByIndex(int n)
{
LinkNode* cur = dummy;
for (int i = 0; i < n - 1&&cur!=nullptr; i++)
{
cur = cur->next;
}
if (cur == nullptr) return;
LinkNode* tmp = cur->next;
cur->next = tmp->next;
delete tmp;
}
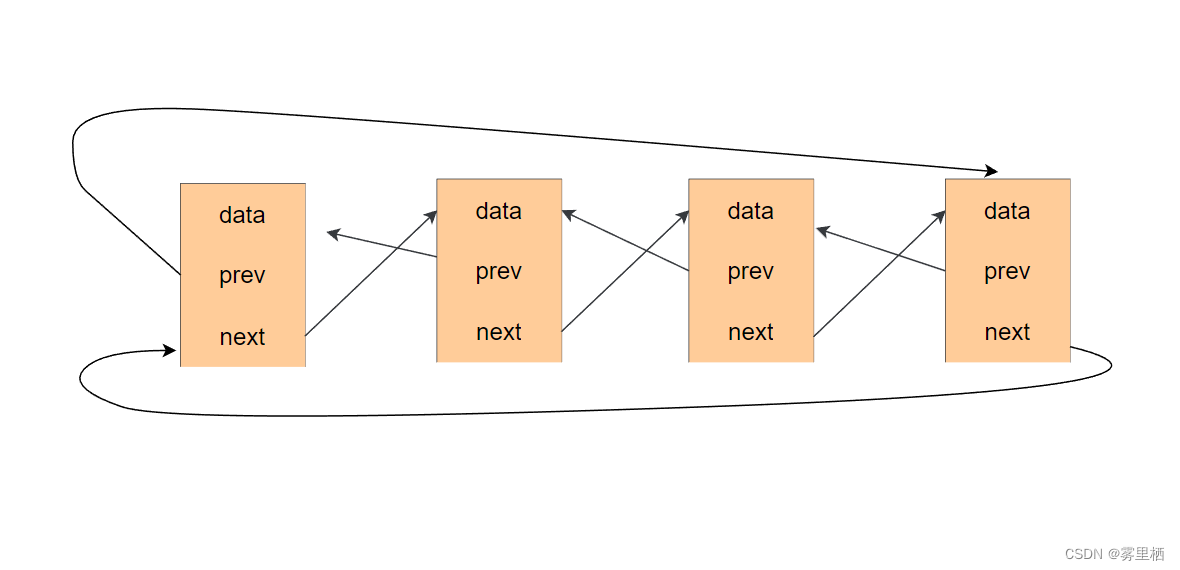
双向链表

双向链表与单链表基本相似,但是最大的区别在于双向链表在节点中除了指向下一节点的next指针外,还有指向前一节点的prev指针,这使得双向链表在可以在任意节点从头尾两个方向进行遍历,是“双向”的。
和单链表相比,双向链表在删除和查询等方面明显在操作上更具有灵活性,但是会消耗更多的内存。
class LinkNode
{
public:
LinkNode(int d = -1,LinkNode* p=nullptr, LinkNode* n = nullptr):val(d),prev(p),next(n)
{
}
int val;
LinkNode* prev;
LinkNode* next;
};双向循环链表
它是在双向链表的基础上,将双向链表的首节点指向尾节点,尾节点指向首节点。使得各个节点之间通过指针连接成环。















 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









