







目录
引入
单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。它只能从头开始遍历链表,直到找到我们需要找的元素。因此查找效率很低,平均时间复杂度很高O(n)。
数组可以通过二分查找来进行查询操作,时间复杂度为O(logn)。为了让链表也能支持二分查找,在有序链表的基础上加上一层目录,即一层索引链表,以支持快速的删除、插入和查找操作的数据结构,插入、删除和查找的时间复杂度都为O(lgn)。
因此,跳表是可以实现二分查找的有序链表。
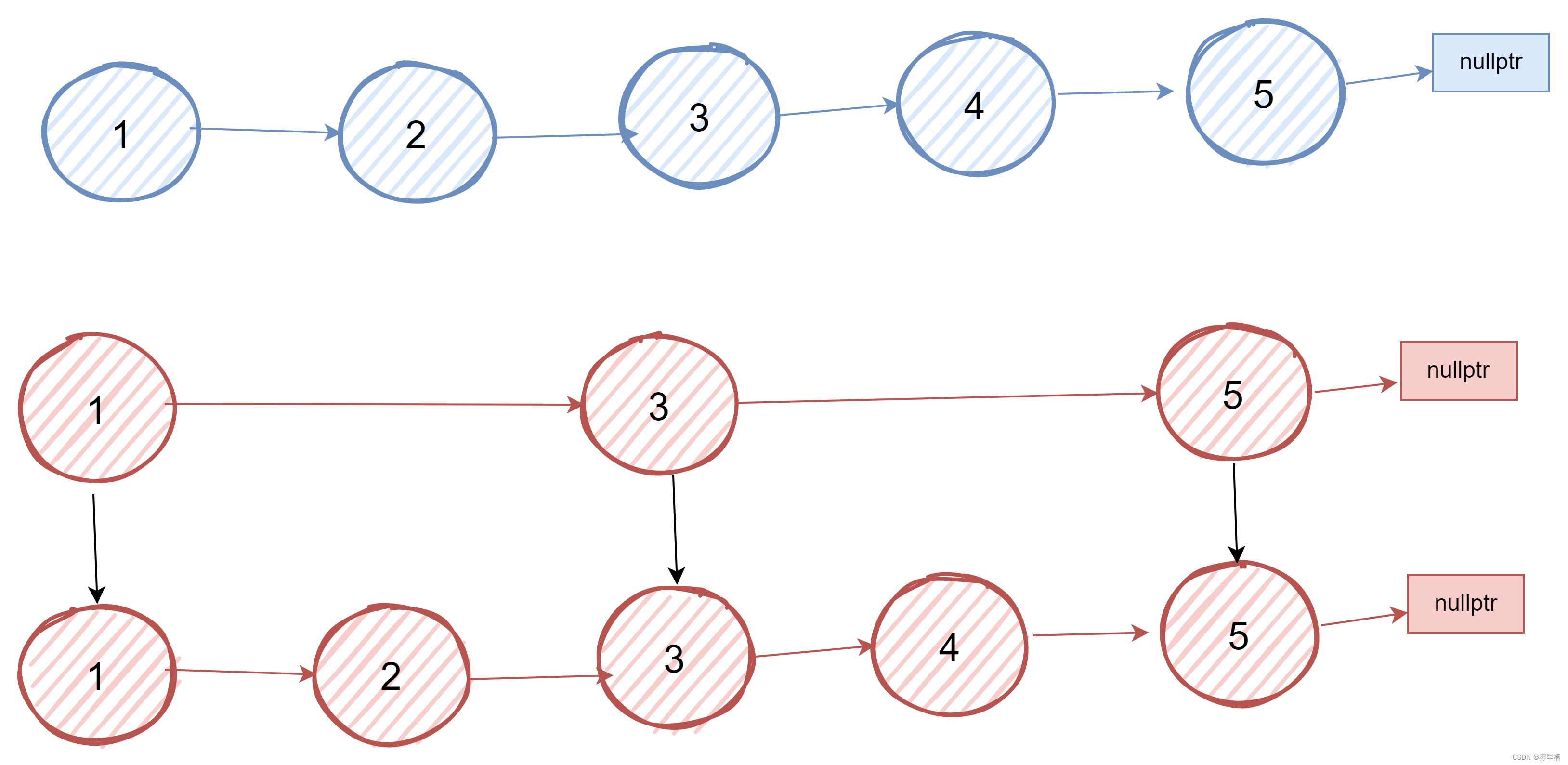
当数据量很大的情况下,一层索引查询复杂度无法满足O(logn)时,可以基于原始链表的第1层索引,抽出第二层/第三层更为稀疏的索引,结点数量是上一层的一半:
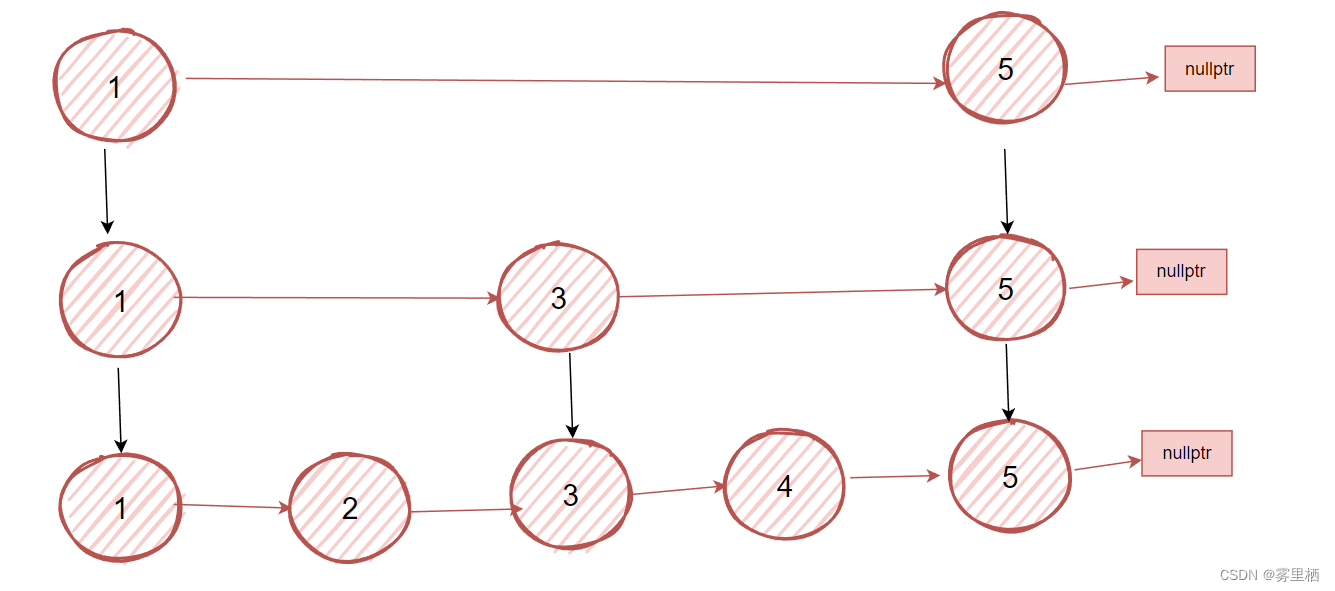
跳表与红黑树
跳表的搜索、插入和删除操作的时间复杂度与红黑树相同,都为O(logN)。
区别:
- 实现复杂度:跳表实现相对简单,它由多层链表组成,每一层都是底层的子集,不需要进行频繁的旋转和颜色调整等操作来维持结构的平衡来保持平衡。红黑树实现较为复杂,在插入和删除操作后需要进行旋转和变色的操作来维持树的平衡。
- 性能稳定性:跳表在插入和删除操作中,性能相对稳定,因为只会影响链表中的相邻节点。红黑树虽然操作也是对数时间复杂度,但在最坏情况下,如连续插入有序元素,可能需要多次旋转和颜色变换来重新平衡树。
- 空间效率:跳表需要存储多级索引,需要消耗更多的存储空间。红黑树每个节点只需要存储其子节点的指针和颜色信息,因此在空间使用上通常比跳表更高效。
- 区间查找效率:跳表在区间查找操作上可能比红黑树更高效。平衡树需要以中序遍历的顺序继续寻找其它不超过区间最大值的节点。而跳表进行范围查找非常简单,只需要在找到区间最小值之后,对第1层链表进行若干步的遍历就可以实现。
跳表的层数
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
当我们插入或者删除一个节点后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系,如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n),带来额外的维护开销。
跳表设计时为了避免这种问题,在插入一个节点的时候,随机生成每个节点的层数,并不需要严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 p,那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于p结束,最终确定该节点的层数。这样的做法,相当于每增加一层的概率不超过 p,层数越高,概率越低。
跳表通常需要有一个最大层数maxlevel,以及一个概率p,即新增加一层的概率。通常只要数据量足够大,相邻两层之间的节点数量就会呈现出一定的比率。p越大,平均层数越多,时间效率就越快,但太大可能导致空间浪费,故一般都会限制最大层数。当p设置的小,层数就会低一点。通常将p设置为0.25。redis将maxlevel设置为32。
#include<random>
const float SkipUp=0.25;
const int MaxLevel=8;
int SkipList::generateLevel()
{
int level = 1;
static default_random_engine e;
static uniform_real_distribution<double> u(0, 1.0);
while (u(e) > SkipUp && level < MaxLevel)
{
level++;
}
return level;
}定义跳表节点
class SkipNode{
public:
SkipNode(int v,int l=1):val(v),level(l),forward(l,nullptr)
{
}
~SkipNode()
{
}
int val;
int level;
vector<SkipNode*> forward;
};寻找某个值前驱节点
给定一个target,寻找每个层小于target的最大值
void findPre(int val,vector<SkipNode*>& pre)
{
SkipNode* tmp=dummy;
for(int i=maxlevel-1;i>=0;i--)
{
while(tmp->forward[i]!=nullptr&&tmp->forward[i]->val<val)
{
tmp=tmp->forward[i];
}
pre[i]=tmp;
}
}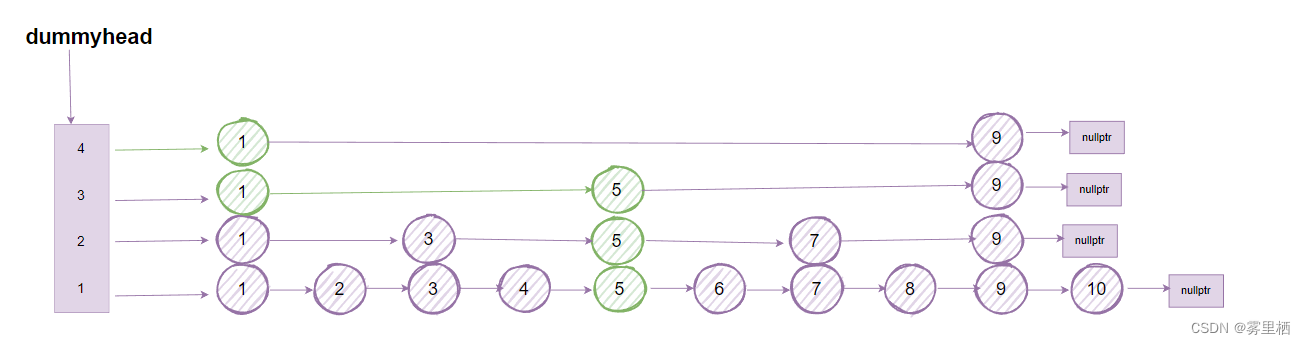
当我们要找值为6的前驱节点时,从最高层开始,如果当前节点的value小于target时,跳表就会访问该层上的下一个节点。如果当前节点为空或者value大于target时,说明前一个节点为target在该层的前驱节点,将前驱节点保存在pre数组中。
节点的插入
需要插入一个value时,找到value的前驱节点,然后随机生成一个level作为新节点的层数,将新节点的下一个节点设置为前驱节点的next节点,然后将前驱节点的next节点指向新节点
void add(int num)
{
vector<SkipNode*> pre(maxlevel,nullptr);
findPre(num,pre);
int level=generateLevel();
SkipNode* tmp=new SkipNode(num,level);
for(int i=0;i<level;i++)
{
tmp->forward[i]=pre[i]->forward[i];
pre[i]->forward[i]=tmp;
}
}节点的查询
查询某个value时,找到value的前驱节点。因为底层节点包含所有的节点,在底层节点都查询不到该value时,说明value不存在于该数据结构中。如果底层前驱节点的下一个节点的value==value,说明存在,否在不存在。
bool search(int target) {
vector<SkipNode*> pre(maxlevel,nullptr);
findPre(target,pre);
SkipNode* tmp=pre[0]->forward[0];
if(tmp&&target==tmp->val)
{
return true;
}
return false;
}节点的删除
查询是否存在该值,不存在则返回false。存在则找到该值的前驱节点,修改当前节点的所有层数上的前驱节点的next指针。
bool erase(int num)
{
if(!search(num)) return false;
vector<SkipNode*> pre(maxlevel,nullptr);
findPre(num,pre);
SkipNode* tmp = pre[0]->forward[0];
for(int i=0;i<tmp->level&&pre[i]->forward[i]==tmp;i++)
{
pre[i]->forward[i]=tmp->forward[i];
}
delete tmp;
return true;
}跳表的应用场景
Redis的有序集合的内部使用哈希表和跳表来存储数据,使用哈希表存放成员到score的映射,使用跳表来存放按score排序的所有的数据成员。使用跳跃表的结构可以在代码实现简单的基础上获得比较高的查找效率。















 7319
7319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









