






redis(第二期)
之前我们介绍了redis的基本使用方法和有关的redis的两种数据类型,现在我们在来看有关redis的第三种数据类型Set集合
首先向redis中添加Set,命令如下:
sadd <key> <element1> <element2> <element3>...
查看集合中有多少值,命令如下:
scard <key>
判断是否包含特定的值
sismember <key> <value>
上面如果找到了特定的值就会返回1,如果没有找到特定的值就会返回0
查看一个键对应的所有值:
smemebers <key>
集合之间可以进行差集操作
sdiff <key1> <key2> #看key1中有哪些元素是key2没有的
交集
sinter <key1> <key2> #看那些元素是key1和key2共有的元素
并集
sunion a b
移动集合中的元素到另一个集合中去
smove <key1> <key2> value
移除方法:
# 随机移除
spop <key>
# 指定移除
srem <key> <value> <value> <value>.....
当然我们了解到,set集合并不能按照指定顺序进行排序,如何按照指定顺序来进行集合排序呢?我们可以运用添加分数的方式来解决。我们的set集合从而也进化成为了sortset集合,那么如何对sortlset集合进行操作呢。
向sortset集合中添加元素
zadd <key> [score] <value> ##score就是有关集合中的先后顺序的
在这里推荐将sortset与set分成主观形式上不同的数据类型,只有这样我们在理解对不同数据类型进行操作的时候,才能有效的把指令区分开防止混淆。
查询有多少个值
zcard <key> ##查看sortset集合中有多少个值
查看值,切记在sortset中我们添加了分数以控制它们的索引值,我们调用如下
zrange <key> [index1] [index2]
当然了,如果我们想要在输出所有集合元素的时候,还想得到其每个元素对应的分数值,那么我们可以在上方指令之后添加上withscores,即如下所示:
zrange <key> [index1] [index2] withscores
当然了,我们还可以通过分数段来进行查询指定的集合值:
zrangebyscore <key> [起始分数] [终止分数]
当然了,我们以这样的方式也可以查看带分数的排列方式:
zrangebyscore <key> [起始分数] [终止分数] withscore
我们还可以像mysql数据库中的那样的方式给排列出来的值进行页限制:
zrangebyscore <key> [起始分数] [终止分数] limit [起始索引] [跨越值]
我们可以统计某个分数段的相关集合值有多少个,输入下面的指令:
zcount <key> [起始分数] [终止分数]
我们可以根据指定集合值获得一个相关的排名(获取索引值):
zrank <key> <value>
好的,以上就是set和zset两种数据类型的命令。
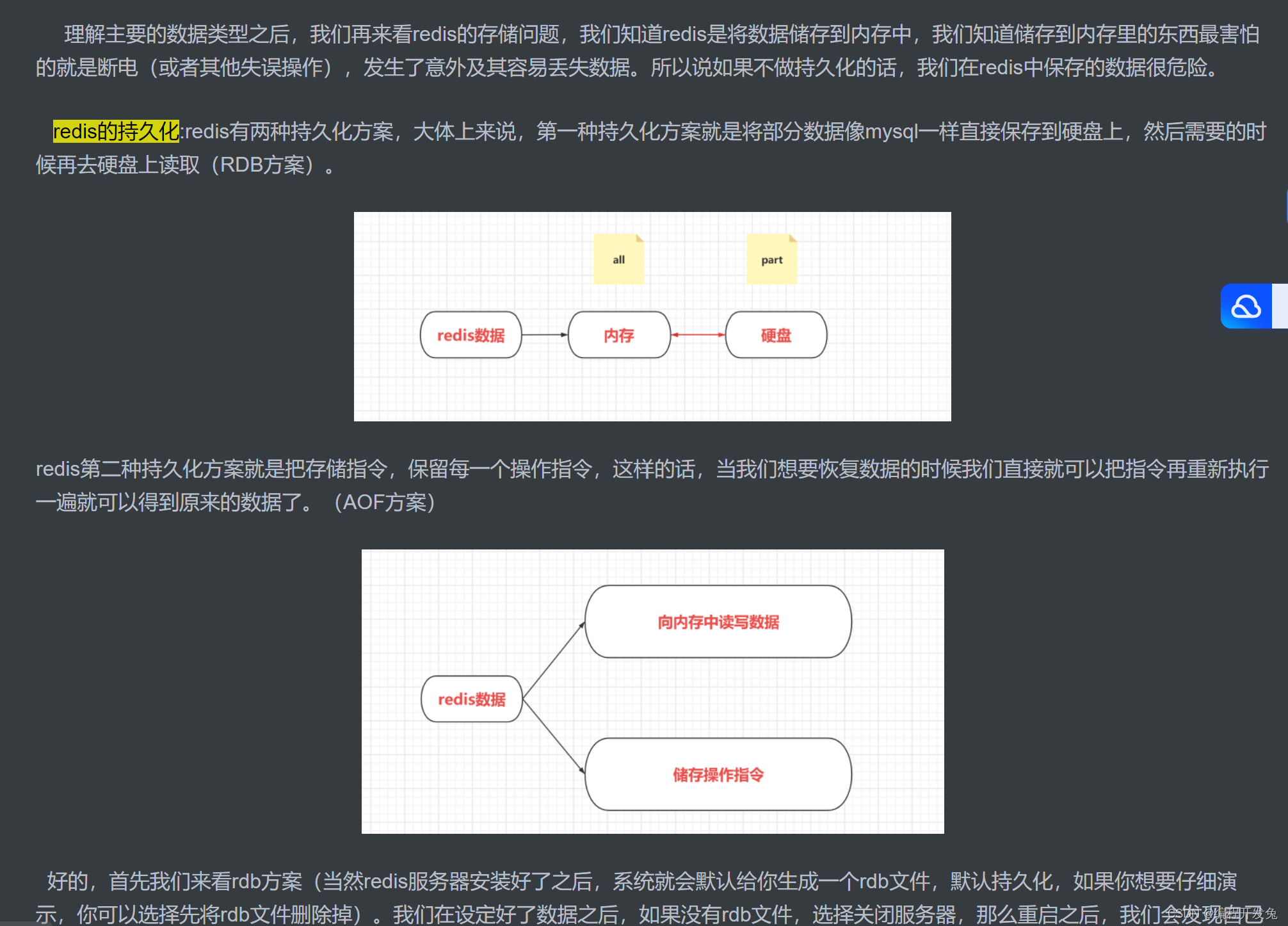
理解主要的数据类型之后,我们再来看redis的存储问题,我们知道redis是将数据储存到内存中,我们知道储存到内存里的东西最害怕的就是断电(或者其他失误操作),发生了意外及其容易丢失数据。所以说如果不做持久化的话,我们在redis中保存的数据很危险。
redis的持久化:redis有两种持久化方案,大体上来说,第一种持久化方案就是将部分数据像mysql一样直接保存到硬盘上,然后需要的时候再去硬盘上读取(RDB方案)。
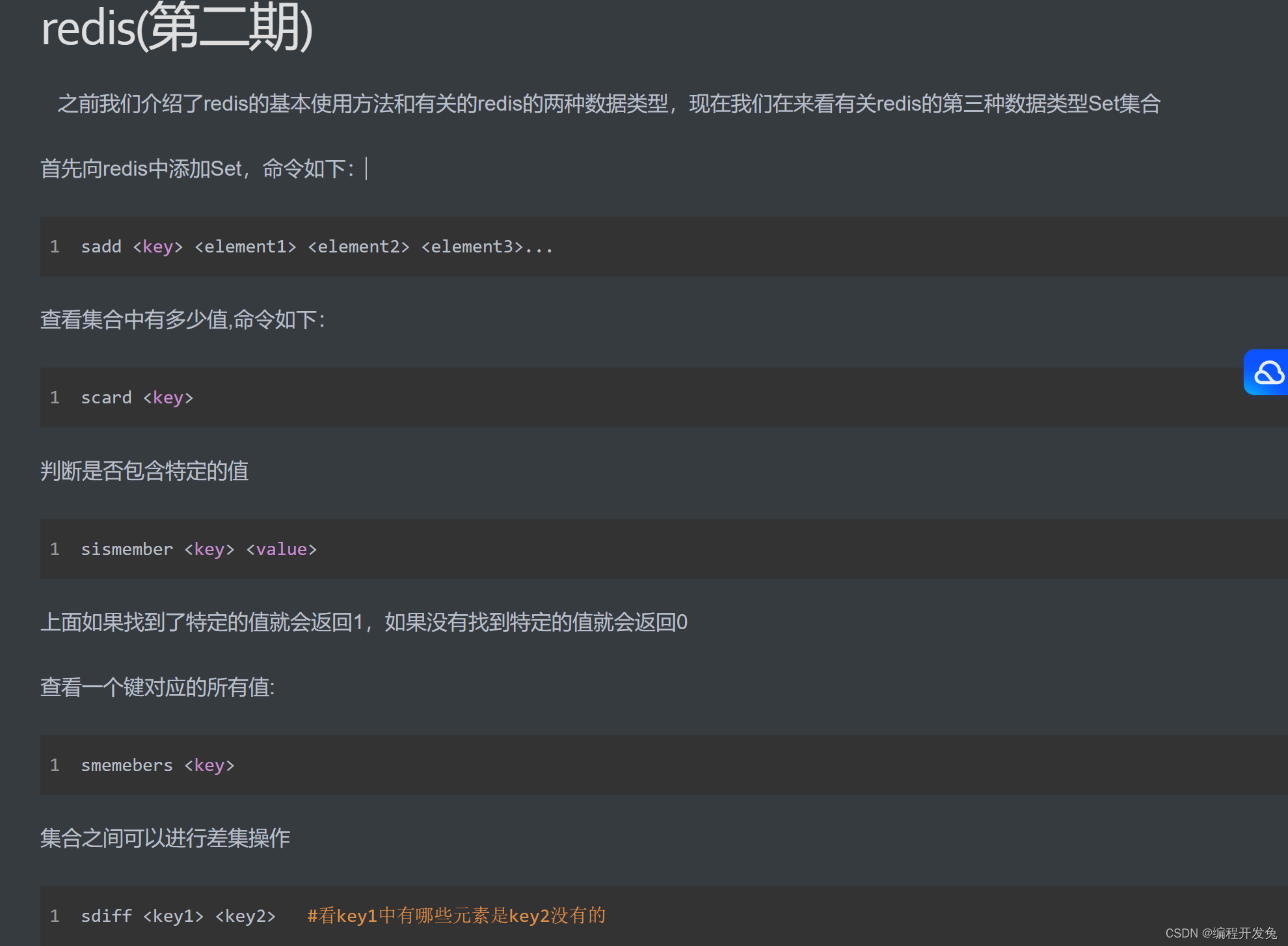
redis第二种持久化方案就是把存储指令,保留每一个操作指令,这样的话,当我们想要恢复数据的时候我们直接就可以把指令再重新执行一遍就可以得到原来的数据了。(AOF方案)
好的,首先我们来看rdb方案(当然redis服务器安装好了之后,系统就会默认给你生成一个rdb文件,默认持久化,如果你想要仔细演示,你可以选择先将rdb文件删除掉)。我们在设定好了数据之后,如果没有rdb文件,选择关闭服务器,那么重启之后,我们会发现自己看不到原来的数据(即原来的数据被删除了)。我们可以选择执行如下命令来保存数据:
save
执行上述命令系统就会给我们生成一个rdb文件,用于保存我们当前的数据,当我们下次在重启服务器的时候,你会发现之前执行命令保存的数据还在服务器上(就是因为save命令将创造出来的数据以rdb文件的方式保存到了硬盘上,当重启服务器的时候,就会从硬盘中读取数据再一次保存到内存上面)。
save命令是主进程,它占用会消耗一定的时间和空间,因此如果需要保存的数据量太大,那么save会占据很长的时间,而且大家都操作不了。为了解决这个问题,我们通常会fork一个子进程,使用如下命令:
bgsave
这样的话,保存数据的操作就是以子进程的方式来进行,就不会占用我们的主进程的使用了。
虽然rdb文件可以保存数据,当时这样也出现了一个问题,万一我们需要保存的数据量很大,那么复制一次就会占用大量时间。因此,我们通常是每隔一段时间就会进行自动保存的操作。而且如果遇到的是基本都是读操作,写操作很少的话,那么没有必要去浪费时间保存很多次,我们只需要偶尔保存一两次即可。有关redis的配置中已经给我们写好了保存操作的有关配置(当然它是通过bgsave的方式去保存的)。
接下来,我们来看AOF操作,AOF就是以日志的方式将执行的命令进行保存。服务器重启时会将命令依次执行,这样就可以解决存储问题。 那么AOF会多久保存一次数据呢,有三种保存策略。Always—每写一次命令就会执行一次保存操作,everysrc----每秒保存一次日志,no----看操作系统的心情来进行保存。
redis一开始默认的是rdb文件的保存方案,我们想要用aof保存方案,需要在配置文件中重新配置:
appendonly yes
aof有关配置的相关策略表示方式如下:
appendfsync always #每写一次指令,就添加一次操作
appendfsync eyerysec #每秒就添加一次操作
appendfsync no #把操作权交给操作系统
当然了,AOF的缺点也很明显,它比BOF还要费事,因为每次需要将指令重写。在启动服务器的时候,需要将所有指令都重新执行一遍,相比BOF更加耗时,并且随着数据与指令的不断写入,我们的AOF文件也会不断增大。因此,Redis就在原来的AOF文件基础上添加了一些优化,即将多个指令合并成一个指令,完成对AOF文件的压缩处理。对指令进行合并操作,就是对AOF文件进行重写操作,我们甚至可以手动对AOF文件进行重写操作,也可以在配置文件中配置自动重写(比如说达到多少字节就进行自动重写)。















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









