







目录
① 层次模型(Hierarchical Model)——————↘
② 网状模型(Network Model)————————↗
④ 面向对象数据模型(Object Oriented Data Model)——————↘
⑤ 对象关系数据模型(Object Relational Data Model)—————↗
⑥ 半结构化数据模型(Semi - struture Data Model)—— 如 XML
(1)网状数据库系统采用网状结构来表示各类实体以及实体间的联系
1. 数据模型的概念
• 数据模型是对现实世界数据特征的抽象
• 通俗地讲数据模型就是说现实世界的模拟
数据模型应该满足三方面要求:
• 能比较真实地模拟现实世界
• 容易为人所理解
• 便于在计算机上实现
数据模型是数据库系统的核心和基础
2. 两类数据模型
(1)数据模型分为两类(两个不同的层次)
① 概念模型,也称为信息模型
• 它是按用户的观点来对数据信息建模,用于数据库设计
② 逻辑模型和物理模型
• 逻辑模型主要包括网状模型、层次模型、关系模型、面相对象数据模型、对象关系数据模 型、半结构化数据模型等
按计算机系统的观点对数据建模,用于DBMS实现
• 物理模型是对数据最底层的抽象
描述数据在系统内(磁盘上)的表示方式和存取方法
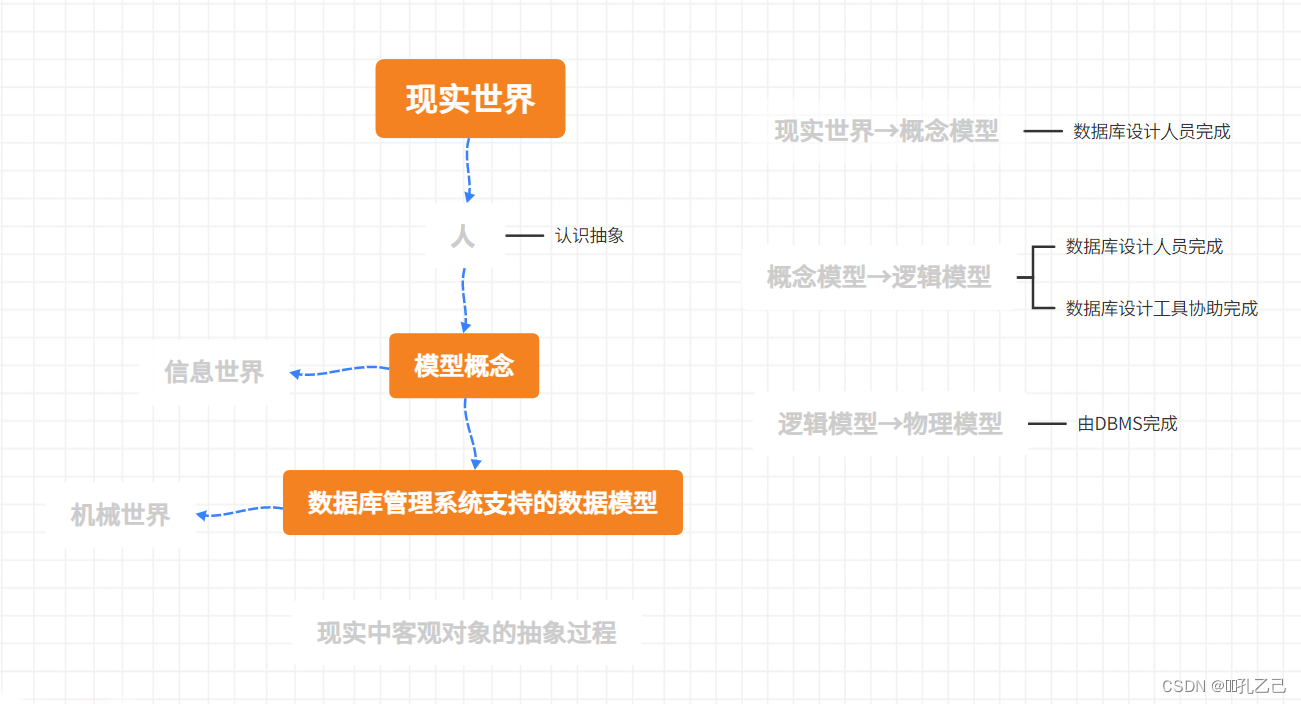
(2)客观对象的抽象过程—两步抽象
• 现实世界中的客观对象抽象为 概念模型
• 把 概念模型 转换为某一DBMS支持的 数据模型
3. 概念模型
(1)用途与基本要求
① 概念模型的用途
• 概念模型用于信息世界的建模
• 是现实世界到机械世界的一个中间层次
• 是数据库设计的有力工具
• 数据库设计人员和用户之间进行交流的语言
② 对概念模型的基本要求
• 较强的语义表达能力
• 简单、清晰、易于用户理解
(2)信息世界中的基本概念
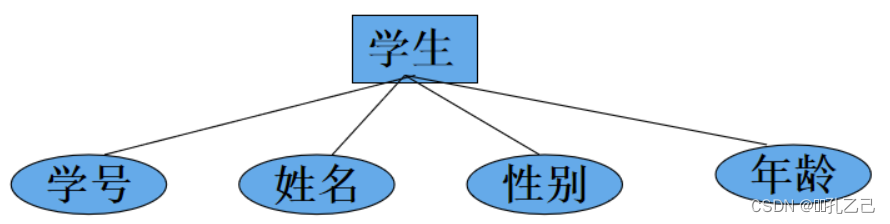
① 实体(Entity)
• 客观存在并相互区别的事物称为 实体
可以是具体的人、事、物或抽象的概念

② 属性(Attribute)
• 实体所具有的的某一特性称为 属性
一个实体可以由若干个属性拉刻画
③ 码(Key)
• 唯一标识实体的属性集称为 码
④ 实体型(Entity Type)
• 用实体名及其属性名集合来抽象和刻画同类实体称为 实体型
⑤ 实体集(Entity Set)
• 同一类型实体的集合称为 实体集
⑥ 联系(Relationship)
• 现实世界中事物内部以及事物之间的联系在信息世界中反映为 实体(型)内部的联系和实现 (型)之间的联系
• 实体内部的联系:是指组成实体的各属性之间的联系
• 实体之间的联系:通常是由不同实体集之间的联系
实体之间 的联系有 一对一(1:1)、一对多(1:m)、多对多(m:n)
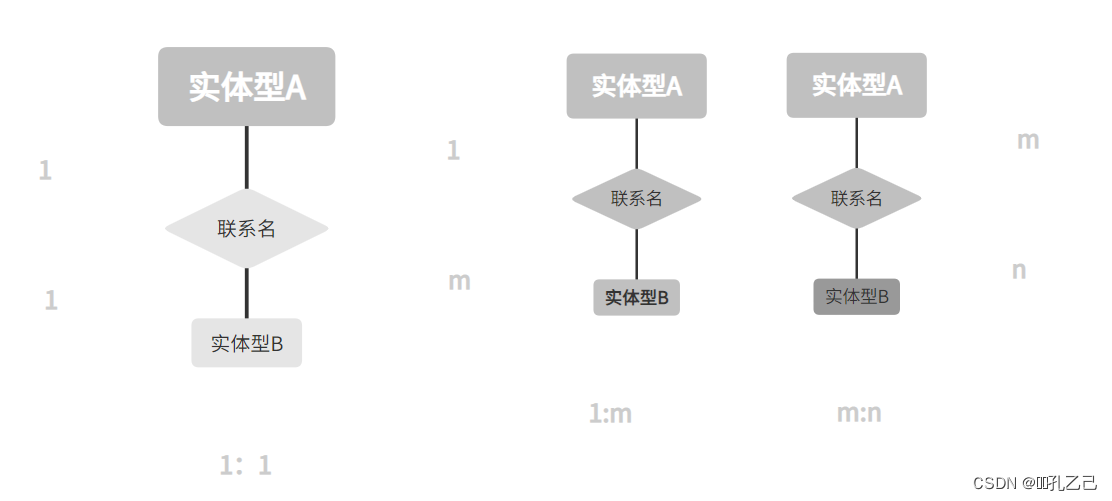
(3)概念模型的一种表示方法:
实体 - 联系方法(Entity—Relationship Approach)
• 用E—R图来描述现实世界的概念模型
• E—R方法也称为E—R模型
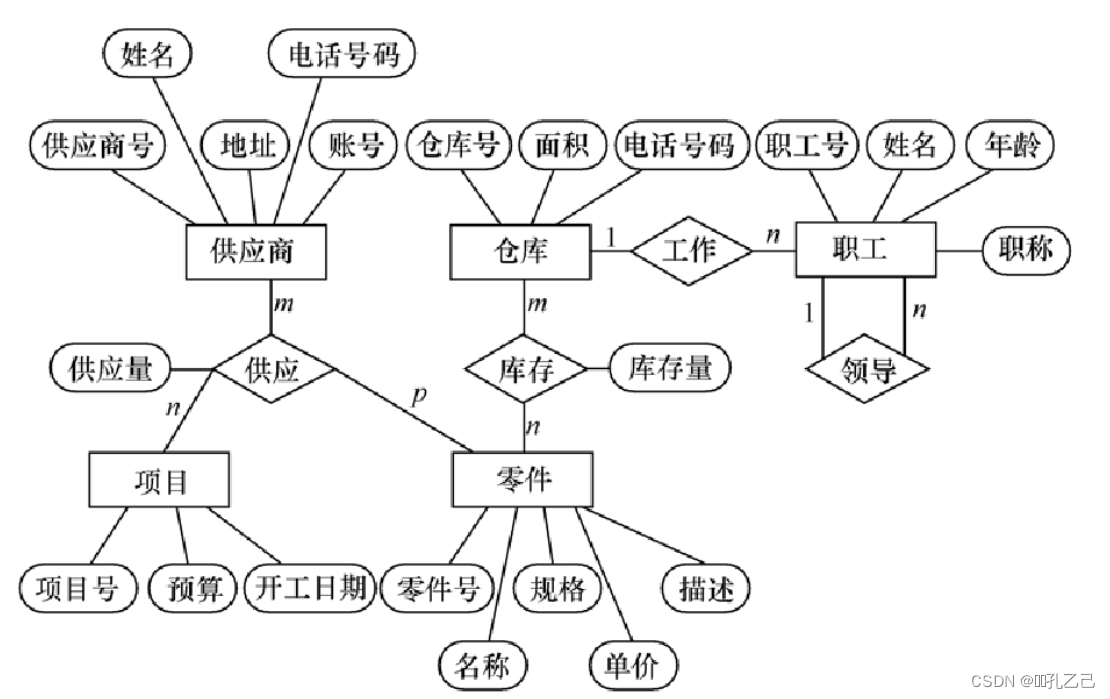
• 实体
仓库: 仓库号、面积、电话号码
零件 :零件号、名称、规格、单价、描述
供应商:供应商号、姓名、地址、电话号码、帐号
项目:项目号、预算、开工日期
职工:职工号、姓名、年龄、职称
• 实体之间的联系
(1)一个仓库可以存放多种零件,一种零件可以存放在多个仓库中。仓库和零件具有多对多的联 系。用库存量来表示某种零件在某个仓库中的数量。
(2)一个仓库有多个职工当仓库保管员,一个职工只能在一个仓库工作,仓库和职工之间是一对多 的联系。职工实体型中具有一对多的联系
(3)职工之间具有领导-被领导关系。即仓库主任领导若干保管员。
(4)供应商、项目和零件三者之间具有多对多的联系
4. 数据模型的组成要素
• 数据模型是严格要求定义的一组概念的集合
精确地描述了系统的静态特性、动态特性和完整性约束条件
• 数据模型由三部分组成:
① 数据结构 -- 描述系统的静态特性
② 数据操作 -- 描述系统的动态特性
③ 完整性约束
(1)数据结构
• 刻画数据模型性质的重要方面
数据结构的类型来命名数据结构:
层次结构 - 层次模型 ,网状结构 - 网转模型 , 关系结构 - 关系模型
• 描述数据库的组成 对象 -- 对象 的类型、内容、性质
• 描述对象之间的联系
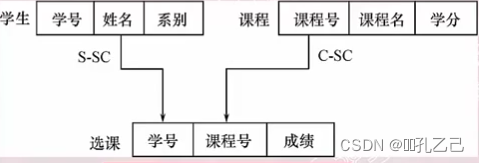
记录:学生 -- 由学号、姓名所在的专业系名等组成
SET TYPE:S-SC -- 学生记录和学生选课记录之间的联系
(2)数据操作
• 对数据库中各种对象的实例允许执行的操作的集合
包括操作及有关的操作规则
数据操作的类型
• 查询
• 更新(包括插入、删除、修改)
数据操作语言
定义数据操作的确切含义、符号、优先级别
实现数据操作的语言:
• 查询语言——Query Language
• 更新语言——DML
(3)数据的完整性约束条件
① 一组完整性规则的集合
• 完整性规则:给定的数据模型中数据及其联系所具备的制约和依存规则
• 用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效和相容
② 数据模型对完整性约束条件的定义
• 反映和规定必须遵守的基本规则的通用的完整性约束条件
• 提供定义完整性约束条件的机制,以反映具体应用所涉及的数据必须遵守的特定的语义约束 条件
5. 常用的数据模型
① 层次模型(Hierarchical Model)——————↘
→ 格式化模型
② 网状模型(Network Model)————————↗
③ 关系模型(Relational Model)
④ 面向对象数据模型(Object Oriented Data Model)——————↘
→ 对象模型
⑤ 对象关系数据模型(Object Relational Data Model)—————↗
⑥ 半结构化数据模型(Semi - struture Data Model)—— 如 XML
⑦ 非结构化数据模型、图模型 ......

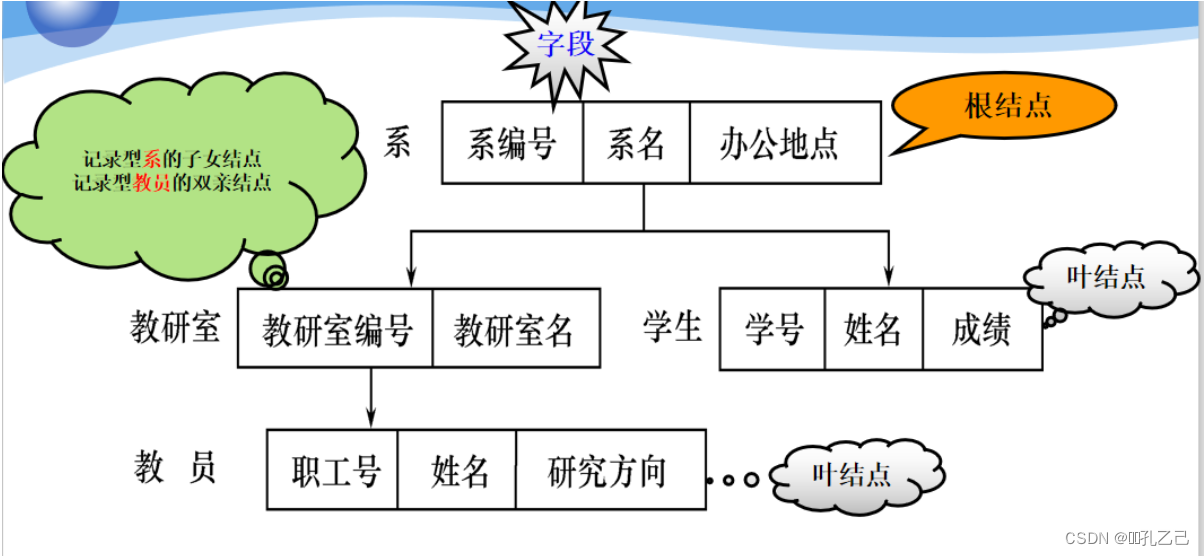
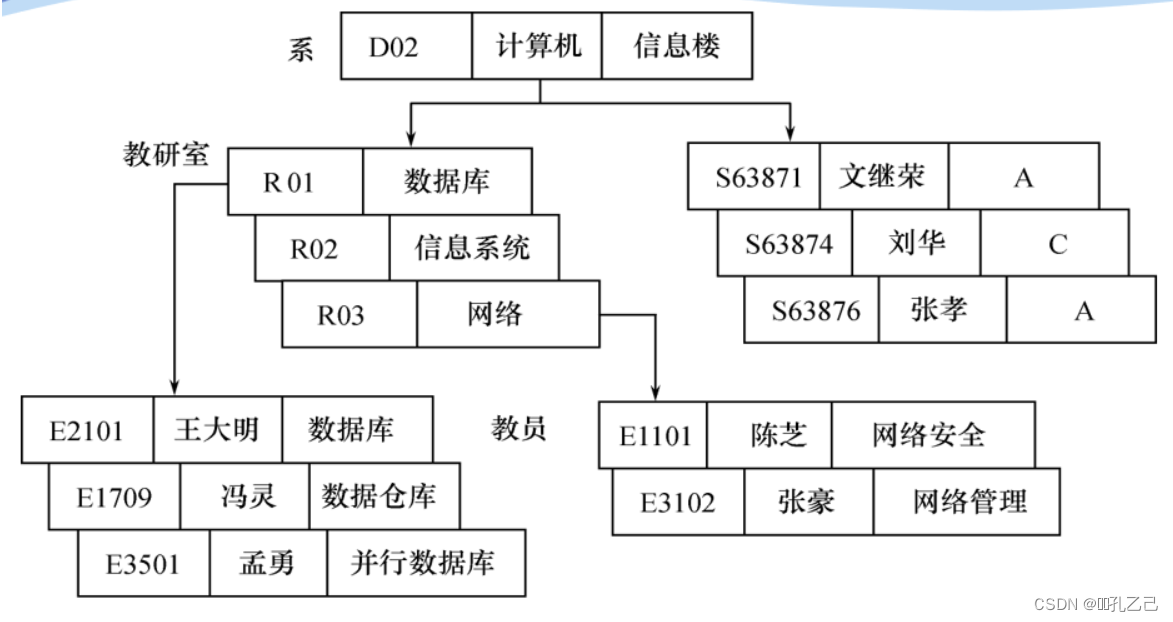
6. 层次模型
(1)层次模型用属性结构来表示各类实体以及是实体间的联系
● 表示方法
• 实体型:用记录类型描述每个结点表示一个记录类型(实体)
• 属性:用字段描述每个记录类型可以包括若干个字段
• 联系:用结点之间的连线表示记录类型(实体)值间的一对多的父子联系
(2)层次模型的定义
满足下面两个条件的基本层次练习的集合为层次模型:
① 有且只有一个结点没有双亲结点,这个结点称为 根结点
② 根以外的其它结点有且只有一个双亲结点
(3)层次模型的数据结构
层次模型中的几个术语:根结点,双亲结点,兄弟结点,叶结点
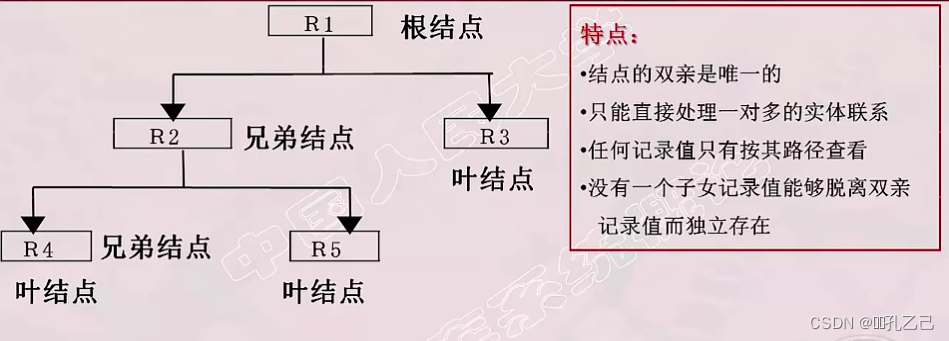
数据结构的特点:
- 结点双亲是唯一的
- 只能直接处理一对多的实体联系
- 每个记录类型可以定义一个排序字段,也称为码字段
- 任何记录值只有按期路径查看
- 没有一个子女记录值能够脱离双亲记录值而独立存在
(4)层次模型的数据操纵与完整性约束
① 层次模型的数据操纵
• 查询
• 插入
• 删除
• 更新
② 层次模型的完整性约束条件
• 无相应的双亲结点值就不能插入子女结点值
• 如果删除双亲结点值。则相应的子女结点值也被同时删除
• 更新操作时,应更新所有相应记录,以保证数据的一致性
(5)层次模型的储存结构
① 邻接法:
按照层次树前序遍历(T-L-R)的顺序把所有记录值依次邻接存放,即通过物 理空间的位置相邻来实现层次顺序。又可分为:子女-兄弟链接法和层次序 列链接法
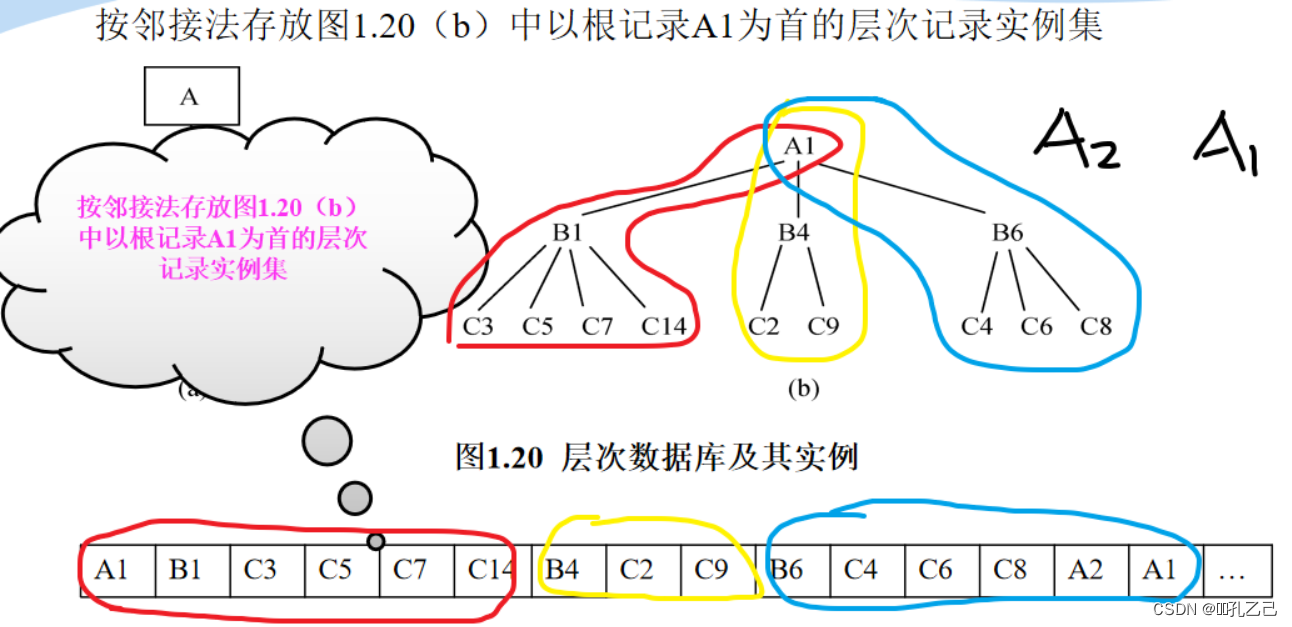
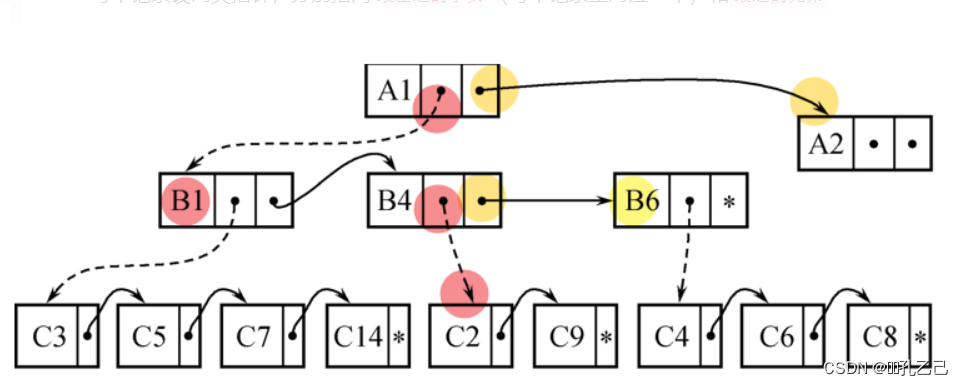
② 子女-兄弟链接法:
每个记录设两类指针,分别指向最左边的子女(每个记录型对应一个)和最近的兄弟
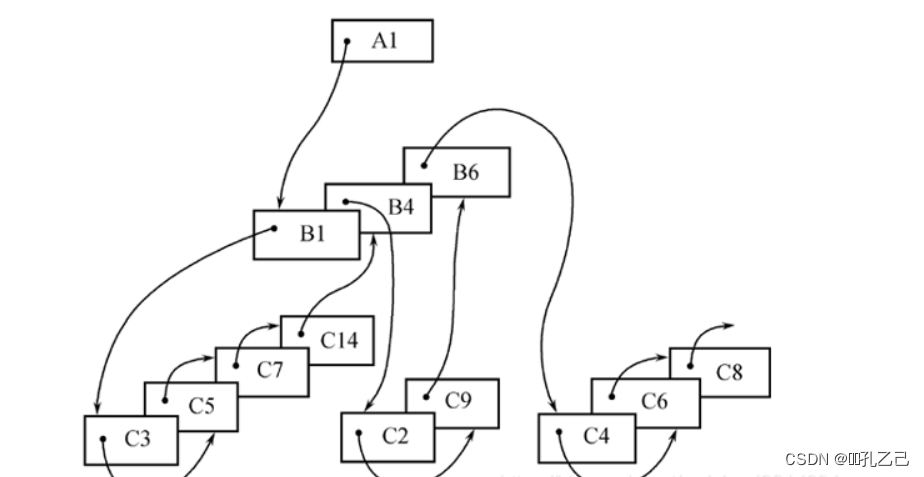
③ 层次序列链接法:
按树的前序穿越顺序链接各记录值
(6)层次模型的优缺点
① 优点
• 层次模型的数据结构比较简单清晰
• 查询效率高,性能优于关系模型,不低于网状模型
• 层次数据模型提供了良好的完整性支持
② 缺点
• 结点之间的多对多联系表示不自然
• 对插入和删除操作的限制多,应用程序的编写比较复杂
• 查询子女结点必须通过双亲及结点
• 层次数据库的命令(语音)趋于程序化
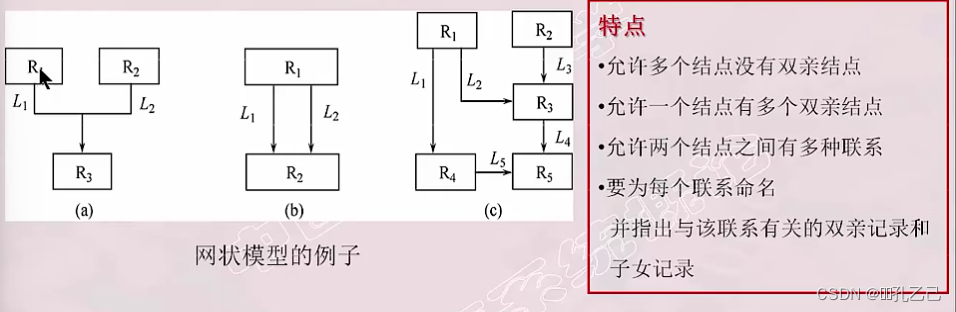
7. 网状模型
(1)网状数据库系统采用网状结构来表示各类实体以及实体间的联系
● 表示方法(与层次数据模型相同)
• 实体型:用记录类型描述每个结点表示一个记录类型(实体)
• 属性:用字段描述每个记录类型可以包括若干个字段
• 联系:用结点之间的连线表示记录类型(实体)值间的一对多的父子联系
(2)网状模型的定义
满足下面两个条件的基本层次联系的集合
① 允许一个以上的结点无双亲
② 一个结点可以有多于一个的双亲
(3)网状模型的数据结构
多对多联系在网状模型中的表示
• 网状模型间接表示多对多联系
• 方法:
将多对多联系分成一对多对多联系
例 :
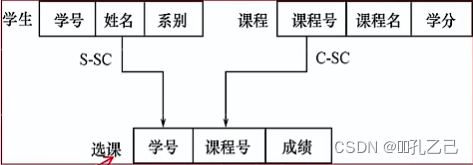
一个学生可以选修若干门课程
某一课程可以被多个学生选修,学生与课程之间的是多对多联系
• 引进一个学生选课的连接记录:
选课(学好,课程号,成绩)
(4)网状模型的数据操纵与完整性约束
● 导航式的查询语言和增删改操作语言
● 完整性约束条件不严格
• 允许插入尚未确定双亲结点值的子女结点值
• 允许只删除双亲结点值
● 实际网络数据库系统提供了一定的完整性约束
• 支持码的概念,唯一标识记录的数据项的集合,取唯一的值
• 保证一个联系双亲记录与子女记录之间是一对多联系
(5)网状模型的优缺点
① 优点
• 能够更为直接地描述现实世界,如一个结点可以有多个双亲
• 具有良好的性能,存取效率较高
② 缺点
• 结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最 终用户掌握
• DDL、DML语言复杂,用户不容易使用
• 记录之间联系是通过存取路径实现的,应用程序必须选择存取路径,加重了程序员的负 担
8. 关系模型
• 关系数据库系统采用关系模型作为数据的组织方式
• 1970年美国IBM公司San Jose研究室的研究员E.F.Codd
首次提出了数据库系统的关系模型
• 数据库厂商退出的数据库管理系统
几乎都支出关系模型
(1)关系模型的数据结构
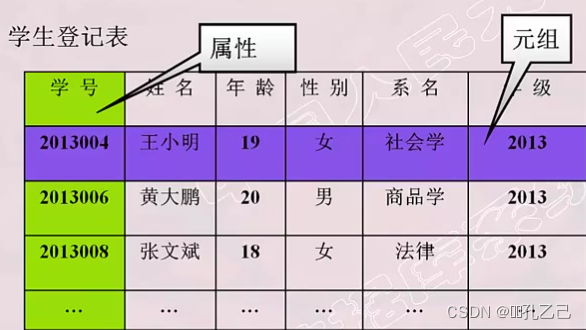
• 关系(Relation):一个关系对应通常说的一张表
• 元祖(Tuple):表中的一行即为一个元祖
• 属性(Attribute):表中的一列即为一个属性,给每一个属性起一个名称既属性名
• 主码(Key):也称为 码键。表中的某个属性组,它可以唯一确定一个元祖
• 域(Domain):是一组具有相同数据类型的值的集合
例:学生年龄属性的域(15 ~ 45岁)
性别的域是(男,女)
系名的域是一个学校所有系名的集合
• 分量:元祖中的一个属性值
• 关系模式:对关系的描述
关系名(属性1,属性2,.......,属性n)
学生(学号,姓名,年龄,性别,系名,年级)
• 在用户观点下,关系模型中数据的逻辑结构是一张二维表
规范化:
• 关系必须是规范化,满足一定的规范条件
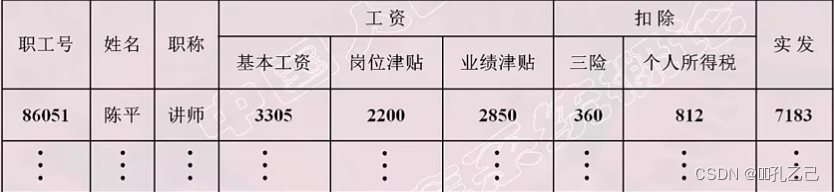
• 最基本的规范条件:关系的每一个分量必须是一个不可分的数据项,不允许表中还有表
• 图:工资和扣除是可分的数据项,不符合关系模型要求
术语对比:

(2)关系模型的操纵和完整性约束
① 数据操作是集合操作,操作对象和操作结果都是关系
• 查询
• 插入
• 删除
• 更新
② 存取路径对用户隐蔽,用户只要指出 “找什么”,不必详细说明 “怎么找”
→ 提高了数据的独立性,提高了用户生产率
③ 关系的完整性约束条件
• 实体完整性——————↘
→关系的两个不变性
• 参照完整性——————↗
• 用户定义的完整性
(3)关系模型的优缺点
① 优点
● 建立在严格的数学概念的基础上
● 概念单一
• 实体和各类联系都用关系来表示
• 对数据的检索结果也是 关系
● 关系模型的存取路径度用户透明
• 具有更高的数据独立性,更好的安全保密性
• 简化了程序员的工作和数据库开发建立的工作
② 缺点
● 存取路径对用户透明,查询效率往往不如格式化数据模型
● 为提高性能,必须对用户的查询请求进行优化,增加了及开发数据库管理系统
9. 对象模型
(1)面向对象关系模型
• 将语义数据模型和面向对象程序设计方法结合起来,用面向对象观点来描述现实世界实体 (对象)的逻辑组织、对象间限制、联系等的模型。
• 一系列面向对象核心概念构成了面向对象数据模型( Object Oriented Data Model, 00模型) 的基础,主要包括以下一些概念:
① 现实世界中的任何事物都被建模为对象。每个对象具有一个唯一的对象标识
(OID)。
② 对象是其状态和行为的封装,其中状态是对象属性值的集合,行为是变更对象状
态的方法集合。
③ 具有相同属性和方法的对象的全体构成了类,类中的对象称为类的实例。
④ 类的属性的定义域也可以是类,从而构成了类的复合。类具有继承性,一个类可以继承 另一个类的属性与方法,被继承类和继承类也称为超类和子类。类与类之间的复合与继 承关系形成了一个有向无环图,称为类层次。
⑤ 对象是被封装起来的,它的状态和行为在对象外部不可见,从外部只能通过对象显式定 义 的消息传递对对象进行操作。
• 面向对象数据库(OODB)的研究始于20世纪80年代,有许多面向对象数据库产品相继问世, 较著名的有Object Store、02、ONTOS等。
• 与传统数据库一样,面向对象数据库系统对数据的操纵包括数据查询、增加、删除、修改 等,也具有并发控制、故障恢复、存储管理等完整的功能。不仅能支持传统数据库应用,也 能支持非传统领域的应用,包括CAD/CAM、OA、CIMS、GIS以及图形、图像等多媒体领 域、工程领域和数据集成等领域。
• 尽管如此,由于面向对象数据库操作语言过于复杂,没有得到广大用户,特别是开发人员的 认可,加上面向对象数据库企图完全替代关系数据库管理系统的思路,增加了企业系统升级 的负担,客户不接受,·面向对象数据库产品终究没有在市场上获得成功。
(2)对象关系数据模型
• 对象关系数据库系统(Object Relational DataBase System, ORDBS) 是关系数据库与面 向对象数据库的结合。
• 它保持了关系数据库系统的非过程化数据存取方式和数据独立性,继承了关系数据库系 统已有的技术,支持原有的数据管理,又能支持00模型和对象管理。各数据库厂商都在 原来的产品基础上进行了扩展。
• 1999 年发布的SQL标准(也称为SQL99),增加了SQL/Object Language Binding, 提供了 面向对象的功能标准。SQL99对ORDBS标准的制定滞后于实际系统的实现。所以各个 ORDBS产品在支持对象模型方面虽然思想一致,但是所采用的术语、语言语法、扩展的 功能都不尽相同。















 3693
3693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









