






pyecharts制作各类型可视化组合图
本文数据来源:汽车之家的1~6月汽车销量
文章目录
前言
汽车行业近些年时常成为各大媒体和消费者关注的焦点,我国汽车品牌经过十几年的技术发展,市场占比一直逐步提升。随着国家政策大力扶持发展新能源汽车和各种互联网巨头的入局,中国汽车市场的“混战”越来越激烈,前有万亿帝国比亚迪、长城、吉利、长安等传统企业,后有蔚来,小鹏,理想等造车新势力,更有华为、百度等互联网大佬入场。所以我将获取2022一月到六月的汽车销售,进行可视化分析2022中国市场各大品牌汽车销量情况
提示:以下是本篇文章正文内容,下面案例可供参考
一、爬取 汽车之家1~6月汽车销量
import requests
from lxml import etree
import pandas as pd
from sqlalchemy import create_engine
class CarSales(object):
def __init__(self):
# 定义url参数,爬取全部汽车销售情况
self.__num_ = None
self.__num1 = None
# 储存dataframe的columns
self.__first = None
self.__month = ['202201', '202202', '202203', '202204', '202205', '202206']
# 将所有dataframe储存起来
self.__dataframe = []
# 将车系分类
self.__car_class = {
'1': [2, '两厢车'],
'2': [3, '三厢车'],
'3': [1, 'MPV'],
'5': [6, 'SUV']
}
self.__url = None
self.__header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
def get_data(self, url):
"""爬取网站内容并转化为text"""
data = requests.get(url=url, headers=self.__header)
data.encoding = 'utf8'
data_transform = data.text
if len(data_transform):
print('爬取成功!')
return data_transform
def xpash_data(self, data, month):
"""进行xpath解析"""
list_data = []
xp = etree.HTML(data)
result_xp = xp.xpath("//table//tr")
for num, object_ in enumerate(result_xp):
if num != 0:
result = object_.xpath('./td/text()|.//a/text()')[:5]
if self.__num_:
result.extend([self.__num_, month])
list_data.append(result) # 将数据暂时储存在列表里并返回
print("**********")
self.__first = [object_.xpath('./th/text()')[:5] for num, object_ in enumerate(result_xp) if num == 0][0] # 将列名提取出来
print(list_data)
return list_data
def reserve_data(self, data):
"""将文件储存成csv文件"""
self.__first.extend(['class_car', 'month'])
df = pd.DataFrame(data, columns=self.__first) # 将数据转化为dataframe形式
df['class_car'] = df['class_car'].map(lambda x: self.__car_class[str(x)][1])
print(df.head())
self.__dataframe.append(df)
df.to_csv(f'car_month.csv',index=False)
print(f'car_month.csv输出成功!')
def to_sql(self, data):
# 将数据写入mysql
try:
concet = create_engine("mysql+pymysql://root:123456@localhost:3306/ds")
data.to_sql('arc_num_month', concet, if_exists='replace',index=False)
except Exception as error:
print('写入数据库异常{}'.format(error))
def main(self):
data_list = []
for month in self.__month:
for i in [1, 2, 3, 5]:
value = self.__car_class[str(i)][0]
self.__num_ = i
for num in range(1, value+1):
print(i,num)
self.__num1 = num
print(self.__num_, self.__num1)
print(self.__url)
self.__url = f'http://xl.16888.com/body-{str(self.__num_)}-{month}-{month}-{str(self.__num1)}.html'
print(self.__url)
# 1 爬取网页
data = self.get_data(self.__url)
# 2 xpath解析
xp_data = self.xpash_data(data, month)
data_list.extend(xp_data)
# 3 将数据储存方便使用
self.reserve_data(data_list)
# 4 将数据写入mysql
new_df = pd.concat(self.__dataframe, axis=0)
print(new_df)
self.to_sql(new_df)
if __name__ == '__main__':
get_car = CarSales()
get_car.main()
二、进行数据清洗和数据挖掘
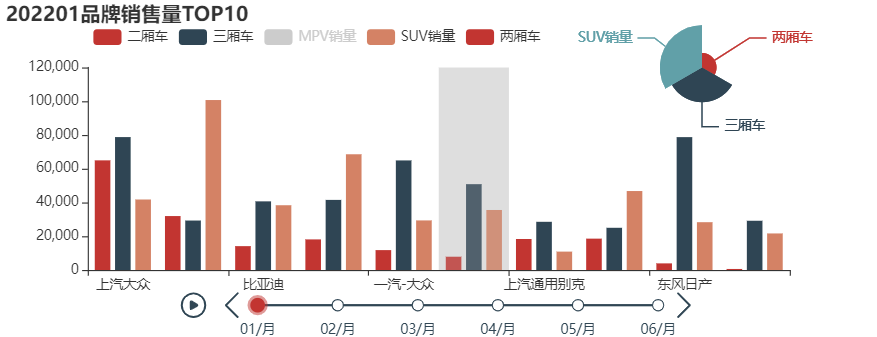
绘制添加时间轴的top10品牌的销量可视化
import pandas as pd
from pyecharts.charts import *
import pyecharts.options as opts
import numpy as np
china_car = ['上汽通用五菱', '上汽名爵', '长安汽车', '吉利汽车', '比亚迪', '奇瑞新能源', '长城新能源', '长安马自达', '零跑汽车',
'江汽集团', '上汽集团', '吉麦新能源', '北汽新能源', '东风小康', '电动屋','御捷新能源', '华晨新日','江铃集团新能源',
'小虎汽车', '云雀汽车', '国机智骏', '广汽埃安', '奇瑞汽车', '东风乘用车', '小鹏汽车', '一汽红旗', '广汽乘用车', '几何汽车',
'东风启辰', '蔚来','威马汽车', '东风风行', 'BEIJING汽车','吉利新能源', '东风新能源', '凯翼汽车', '东南汽车','上汽大通', '江淮汽车',
'睿蓝汽车', '华晨鑫源', '野马汽车', '岚图汽车','开瑞汽车', '大运汽车', '长城汽车', '理想', '合众汽车', '东风汽车', '金康赛力斯',
'星途', '北京越野', '广汽三菱', '创维汽车','SWM斯威汽车', '广汽蔚来','天际汽车', '中国重汽VGV','爱驰汽车', '广汽理念']
data = pd.read_csv('car_month.csv')
data.info()
data.any(axis=0).isnull()
data['品牌/国'] = data['厂商'].map(lambda x: '中国' if x in china_car else '其他国家')
data.head()
top_10 = data.groupby('厂商').agg({'销量': 'sum', '品牌/国': 'first'}).sort_values(by='销量', ascending=False)[:10]
top10_list = top_10.index.tolist()
month_dict = {}
for month in data['month'].unique().tolist():
type_dict = {}
for class_car in data['class_car'].unique().tolist():
car_list = []
for type_ in top10_list:
new_data = data[(data['month'] == month) & (data['厂商'] == type_) & (data['class_car'] == class_car)]['销量'].sum()
car_list.append(int(new_data))
type_dict[class_car] = car_list
month_dict[month] = type_dict
country_dict = {}
for month in data['month'].unique().tolist():
country_list = []
for country in data['class_car'].unique().tolist():
country_list.append(int(data[(data['month'] == month) & (data['class_car'] == country)][['销量']].sum().values))
country_dict[month] = country_list
country_dict
ti = Timeline(init_opts=opts.InitOpts(width="900px", height="500px"))
grid = Grid()
for month in data['month'].unique().tolist():
bar = Bar()
bar.add_xaxis(top10_list)
bar.add_yaxis('二厢车',month_dict[month]['两厢车'])
bar.add_yaxis('三厢车',month_dict[month]['三厢车'])
bar.add_yaxis('MPV销量',month_dict[month]['MPV'],is_selected=False)
bar.add_yaxis('SUV销量',month_dict[month]['SUV'])
bar.set_global_opts(title_opts=opts.TitleOpts(title='{}品牌销售量TOP10'.format(month)),
tooltip_opts=opts.TooltipOpts(is_show=True, trigger="axis", axis_pointer_type="shadow"),
legend_opts = opts.LegendOpts(is_show=True,pos_left='10%',pos_top='7%'))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
pie = Pie()
pie.add(series_name='销量对比',
data_pair=[['两厢车', country_dict[month][0]],
['三厢车', country_dict[month][1]],
['SUV销量', country_dict[month][3]]],
center=['80%', '20%'],
radius='25%', rosetype='area')
pie.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
pie.set_series_opts(tooltip_opts=opts.TooltipOpts(is_show=True))
bar.overlap(pie)
ti.add(bar.overlap(pie) ,time_point=str(month)[-2:]+'/月')
ti.render_notebook()
ti.render('time_plot.html')
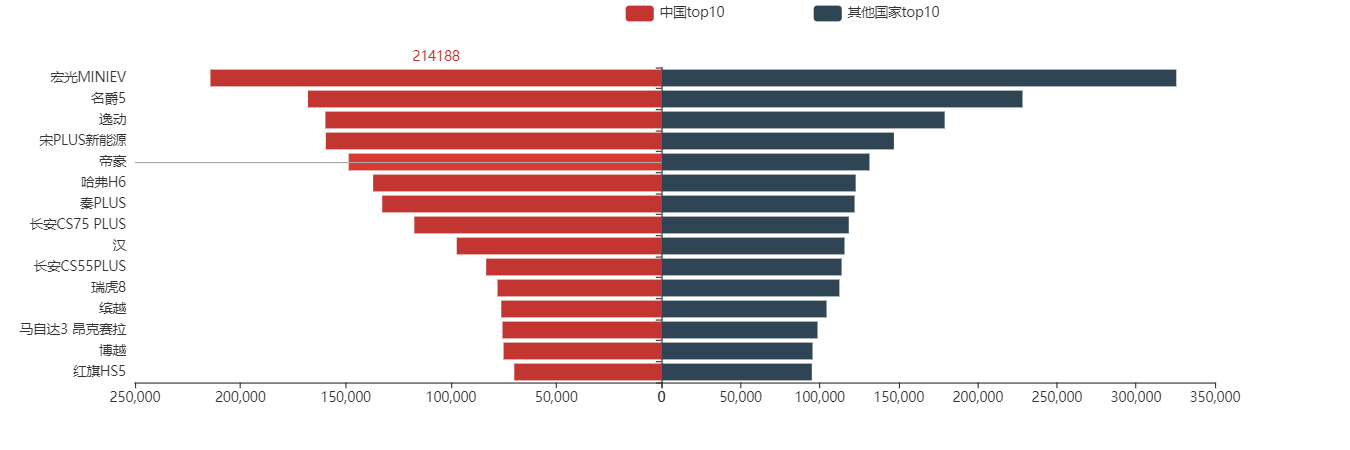
绘制国产品牌和国外品牌销量top15旋风图
top15_china = data[data['品牌/国'] == '中国'].groupby('车型')[['销量']].sum().sort_values(by='销量', ascending=False)[:15]
top15 = data[data['品牌/国'] == '其他国家'].groupby('车型')[['销量']].sum().sort_values(by='销量', ascending=False)[:15]
grid = Grid()
bar = Bar()
bar.add_xaxis(top15_china.index.tolist()[::-1])
bar.add_yaxis('中国top10',top15_china['销量'].values.tolist()[::-1])
bar.set_global_opts(xaxis_opts=opts.AxisOpts(is_inverse=True),
yaxis_opts=opts.AxisOpts(),
tooltip_opts=opts.TooltipOpts(is_show=True, trigger="axis", axis_pointer_type="line"))
bar.set_series_opts(label_opts=opts.LabelOpts())
bar.reversal_axis()
grid.add(bar, grid_opts=opts.GridOpts(pos_right='51%'))
bar1 = Bar()
bar1.add_xaxis(top15.index.tolist()[::-1])
bar1.add_yaxis('其他国家top10',top15['销量'].values.tolist()[::-1])
bar1.set_global_opts(xaxis_opts=opts.AxisOpts(is_inverse=False),
yaxis_opts=opts.AxisOpts(is_show=False),
legend_opts = opts.LegendOpts(pos_right='30%'),
tooltip_opts=opts.TooltipOpts(is_show=True, trigger="axis", axis_pointer_type="line"))
bar1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
bar1.reversal_axis()
grid.add(bar1, grid_opts=opts.GridOpts(pos_left='49%'))
grid.render_notebook()
 国产品牌汽车类别占比,和总类别占比
国产品牌汽车类别占比,和总类别占比
data['min_price'] = data['售价(万元)'].map(lambda x: str(x).split('-')[0])
data['max_price'] = data['售价(万元)'].map(lambda x: str(x).split('-')[1])
# 这里是个人划分的
data.head()
def price_class(data):
if data < 15:
return 'A级车'
elif data < 22:
return 'B级车'
elif data < 35:
return 'C级车'
else:
return 'E级车'
data['price_class'] = data['min_price'].map(lambda x: price_class(float(x)))
data[(data['price_class'] == 'A级车') & (data['month'] == month)][['销量']].sum().values.tolist()
a_list,b_list,c_list,e_list = [],[],[],[]
for month in data['month'].unique().tolist():
a_list.extend(data[(data['price_class'] == 'A级车') & (data['month'] == month)][['销量']].sum().values.tolist())
b_list.extend(data[(data['price_class'] == 'B级车') & (data['month'] == month)][['销量']].sum().values.tolist())
c_list.extend(data[(data['price_class'] == 'C级车') & (data['month'] == month)][['销量']].sum().values.tolist())
e_list.extend(data[(data['price_class'] == 'E级车') & (data['month'] == month)][['销量']].sum().values.tolist())
pie = Pie()
pie.add(series_name='',
data_pair=[['A级车', data[data['price_class'] == 'A级车'][['销量']].sum().values.tolist()],
['B级车', data[data['price_class'] == 'B级车'][['销量']].sum().values.tolist()],
['C级车', data[data['price_class'] == 'C级车'][['销量']].sum().values.tolist()],
['D级车', data[data['price_class'] == 'D级车'][['销量']].sum().values.tolist()]],
center=['40%','50%'],
radius='80%', rosetype='area')
pie.set_global_opts(legend_opts=opts.LegendOpts(is_show=True), title_opts = opts.TitleOpts(title='总体车型占比'))
pie.set_series_opts(tooltip_opts=opts.TooltipOpts(is_show=True, formatter= '{b}:{c}</br>{d}%'),
itemstyle_pots = opts.ItemStyleOpts(border_color='green',border_width='20', border_type='dashed'),
label_opts = opts.LabelOpts(is_show=True, position='right'))
line = Line()
line.add_xaxis(['', '', ''])
line.add_yaxis('',['','',''])
line.set_global_opts(title_opts=opts.TitleOpts(title='总体车型占比'), xaxis_opts=opts.AxisOpts(is_show=False),
yaxis_opts=opts.AxisOpts(is_show=False),
legend_opts = opts.LegendOpts(pos_left='1%',pos_top='10%',orient='vertical'))
pie1 = Pie()
pie1.add(series_name='',
data_pair=[['A级车', data[(data['price_class'] == 'A级车') & (data['品牌/国'] == '中国')][['销量']].sum().values.tolist()],
['B级车', data[(data['price_class'] == 'B级车') & (data['品牌/国'] == '中国')][['销量']].sum().values.tolist()],
['C级车', data[(data['price_class'] == 'C级车') & (data['品牌/国'] == '中国')][['销量']].sum().values.tolist()],
['D级车', data[(data['price_class'] == 'E级车') & (data['品牌/国'] == '中国')][['销量']].sum().values.tolist()]],
center=['85%', '30%'],radius=['15%','30%'])
pie1.set_global_opts(legend_opts=opts.LegendOpts(is_show=True),title_opts=opts.TitleOpts(title='国产品牌车型占比'))
pie1.set_series_opts(tooltip_opts=opts.TooltipOpts(is_show=True, formatter= '{b}:{c}</br>{d}%'),
itemstyle_pots = opts.ItemStyleOpts(border_color='green',border_width='20', border_type='dashed'),
label_opts = opts.LabelOpts(is_show=True, position='right'))
line.overlap(pie).overlap(pie1).render_notebook()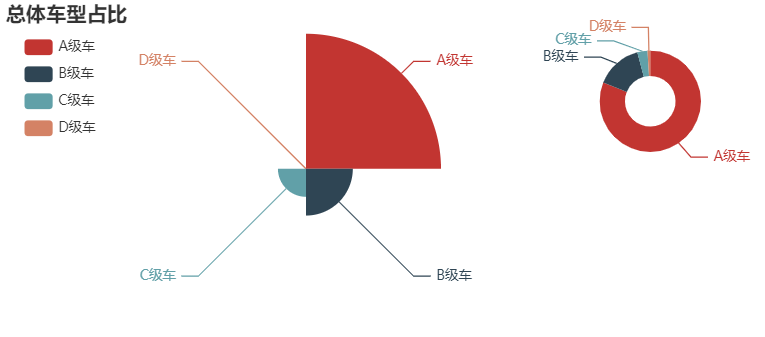
top10厂商热销车型价格分布箱型图和1~6月总体销量top10
# top10厂商热销车型价格分布箱型图
list1, list2 = [], []
for month in data['month'].unique().tolist():
list1.append(int(data[(data['month'] == month) & (data['品牌/国'] == '中国')][['销量']].sum().values))
list2.append(int(data[(data['month'] == month) & (data['品牌/国'] == '其他国家')][['销量']].sum().values))
table_new2 = data[data['品牌/国'] == '其他国家'].groupby('month')[['销量']].sum().sort_values(by='month')
table_new2 = pd.merge(table_new2[['销量']].cumsum(), table_new2, on=table_new2.index)
table_new2.columns = ['month', '总销量','月销量']
table_new2['总销量'] = table_new2[['总销量']].shift(1).fillna(0)
table_new2
x = table_new1['month'].values.tolist()
y1 = table_new1['总销量'].values.tolist()
y2 = table_new1['月销量'].values.tolist()
x_list = [str(i) for i in data['month'].unique().tolist()]
line = Line()
line.add_xaxis(xaxis_data= x_list)
line.add_yaxis('中国', y_axis=list1)
line.add_yaxis('其他国家', y_axis=list2)
line.set_global_opts(tooltip_opts=opts.TooltipOpts(is_show=True, trigger="axis", axis_pointer_type="line"),
toolbox_opts=opts.ToolboxOpts(is_show=True, pos_right='5%'),
title_opts=opts.TitleOpts(title='各月地区销量',subtitle='中国——其他国家'),
xaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_align_with_label=True),boundary_gap=False),
datazoom_opts=opts.DataZoomOpts(is_show=True))
line.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
grid = Grid()
bar = Bar()
bar.add_xaxis(xaxis_data=x)
bar.add_yaxis(" ",y1,stack="总量",itemstyle_opts=opts.ItemStyleOpts(color="rgba(0,0,0,0)"))
bar.add_yaxis(" ",y2, stack="总量")
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
bar.set_global_opts(yaxis_opts=opts.AxisOpts(type_="value",is_show=False),
title_opts=opts.TitleOpts(title='中国品牌总增长',pos_right='10%',pos_top='5%',
title_textstyle_opts=opts.TextStyleOpts(font_size=12)),
tooltip_opts=opts.TooltipOpts(is_show=True,axis_pointer_type='line',trigger="axis"))
line1 = Line()
line1.add_xaxis(x_list)
line1.add_yaxis('',list_sum)
line1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
bar.overlap(line1).render_notebook()
grid.add(bar.overlap(line1), grid_opts = opts.GridOpts(pos_left='70%', pos_bottom='70%'))
grid.add(line, grid_opts = opts.GridOpts(pos_left='10%', pos_bottom='10%'))
grid.render_notebook()
# 1~6月总体销量top10
name_list = []
name_list1 = []
top_10.index.tolist()
for name in top_10.index.tolist():
name_list.append(sum(data[(data['厂商'] == name) & (data['class_car'] == '三厢车')][['min_price']].values.tolist(),[]))
name_list1.append(sum(data[(data['厂商'] == name) & (data['class_car'] == 'SUV')][['min_price']].values.tolist(),[]))
avg_list = [sum([float(num) for num in i])/len(i) for i in name_list]
avg_list1 = [sum([float(num) for num in i])/len(i) for i in name_list1]
box = Boxplot()
box.add_xaxis(top_10.index.tolist())
box.add_yaxis('三厢车',name_list)
box.add_yaxis('SUV',name_list1)
box.set_global_opts(title_opts=opts.TitleOpts(title='各厂商各型车价格分布', subtitle='top10厂商'),
xaxis_opts=opts.AxisOpts(axislabel_opts={'rotate':45}))
line = Line()
line.add_xaxis(top_10.index.tolist())
line.add_yaxis('三厢车平均价',avg_list,
linestyle_opts=opts.LineStyleOpts(color="blank", width=5),
itemstyle_opts=opts.ItemStyleOpts(border_width=4, border_color="red", color="blue"),
symbol='DIAMOND')
line.add_yaxis('SUV平均价',avg_list1,
linestyle_opts=opts.LineStyleOpts(color="green", width=5),
itemstyle_opts=opts.ItemStyleOpts(border_width=4, border_color="red", color="blank"),
symbol='DIAMOND')
line.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
box.overlap(line).render_notebook()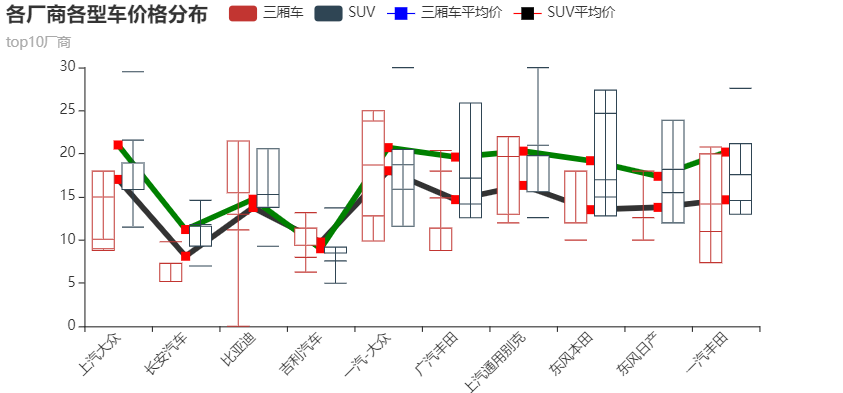
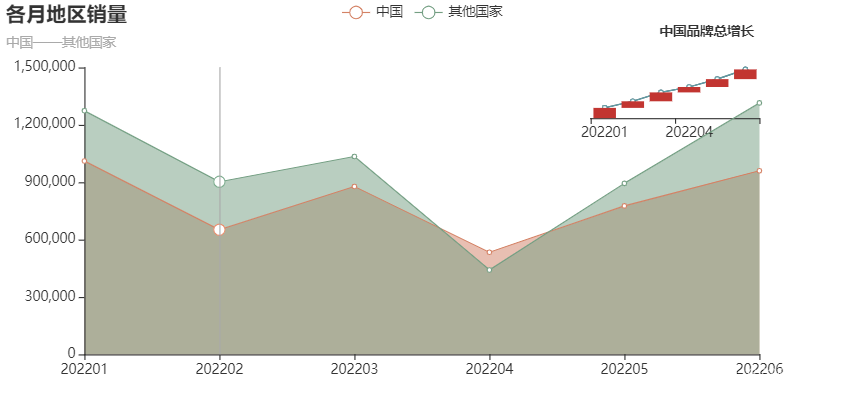
三、可视化展示
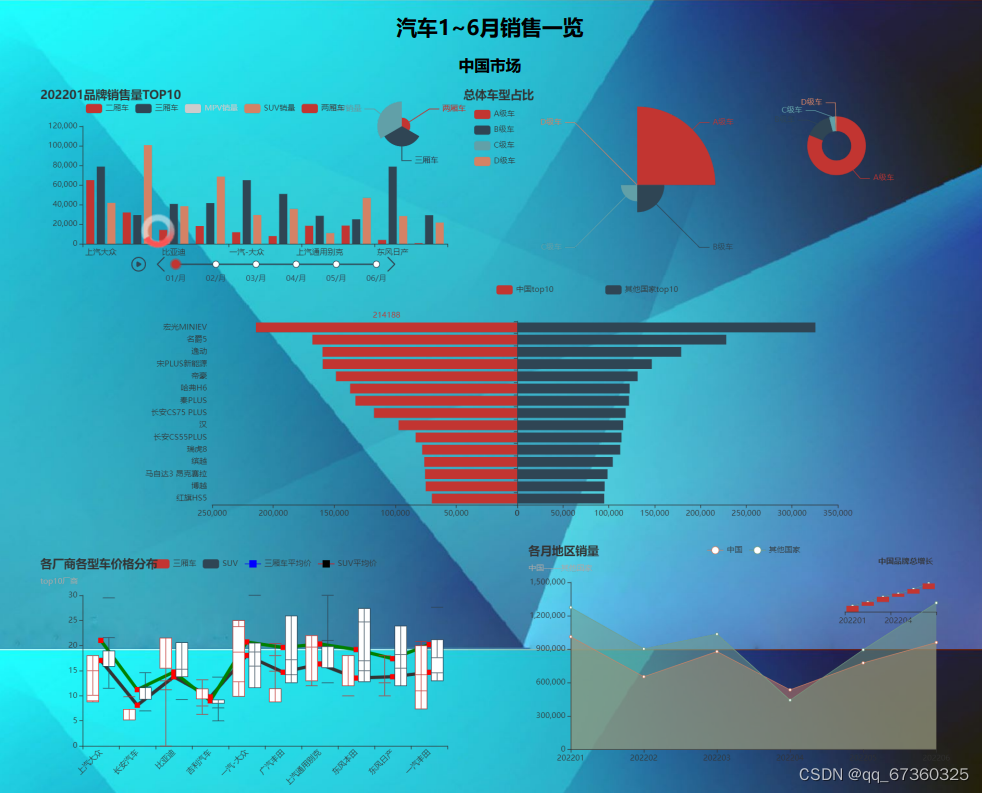
制作成可视化界面 html文件地址:















 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









