






Abstract
新兴的大规模分布式存储系统面临着在数万或数十万个存储设备之间分发 Pb 级数据的任务。这种系统必须均匀分布数据和工作负载,以有效利用可用资源并最大化系统性能,同时促进系统增长并管理硬件故障。我们开发了 CRUSH,这是一个可扩展的伪随机数据分布函数,专为基于对象的分布式存储系统而设计,可有效地将数据对象映射到存储设备,而无需依赖中央目录。因为大型系统本质上是动态的,所以 CRUSH 旨在简化存储的添加和删除,同时最大限度地减少不必要的数据移动。该算法适应多种数据复制和可靠性机制,并根据用户定义的策略分发数据,这些策略强制跨故障域分离副本。
1 Introduction
基于对象的存储是一个新兴的架构,有望提高可管理性、可扩展性和性能。与传统的基于块的硬盘不同,基于对象的存储设备(OSD)在内部管理磁盘块的分配,提供一个接口供他人读写那些大小不一的命名的对象。在这样一个系统中,每个文件的数据通常被条带化(strip)分布在整个系统集群的相对少量的对象上。对象在多个设备上被复制(或者采用别的冗余方法)以在出现故障时放置数据丢失。基于对象的存储系统通过使用小的对象列表来代替大的块列表,并且分散了低级块的分配问题,以简化数据布局。尽管这种方式通过减少文件分布的元数据和复杂性很大程度上提升了可扩展性,但最根本的问题:在成千上万台存储设备(往往具有不同的性能和容量)之间分发数据的问题仍然存在。
大多数系统简单地将新数据写到未充分利用的设备上。这种方式的根本问题是数据一旦写入就很少移动了。即使是一个完美的分布,在存储系统扩展的时候也会变得不平衡,因为新的磁盘要么是空的要么只存放新的数据。要么新要么旧的磁盘可能会很忙(这取决于系统的负载),但是只有在极少的情况下会平等地利用两者来充分利用可用的资源。
一个可靠的解决办法是将所有的数据随机分布在可用的存储设备上。这会产生一个平衡的概率分布,并均匀地将新旧数据混合在一起。添加新存储设备时,会将现有数据的随机样本迁移到新的存储设备上,以恢复平衡。这种方式的关键优势在于,平均而言所有设备的负载都是相似的,从而使系统在任何可能的负载下都有很好的性能。此外,在一个大型的存储系统中,单个的大文件会被随机分配到很多可用的设备上,从而提供很高的并行性和聚合带宽。然而,简单的基于哈希函数的分布无法处理设备数量的变化,会导致大量的数据重组。此外,通过将每个磁盘的副本分布在许多其他设备上来分散复制的现有随机分布方案,很有可能会因同时发生的设备故障而丢失数据。
我们已经开发了 CRUSH(可扩展哈希下的受控复制), 这是一种伪随机数据分发算法,能够高效、稳定地在异构、结构化存储集群中分发对象副本。CRUSH 被实现为伪随机的确定性函数,它将输入值(通常是对象或对象组标识符)映射到存储对象副本的设备列表。这与传统方法的不同之处在于,数据放置不依赖于任何类型的按文件或按对象的目录——CRUSH 只需要对组成存储集群的设备进行简洁、层次化的描述,并了解副本放置策略。这种方法有两个主要优点:第一,它是完全分布式的,使得大型系统中的任何一方都可以独立地计算任何对象的位置;第二,元数据需要的很少,大多是静态的,只有当设备添加或者删除的时候才会改变。
CRUSH旨在以最佳的方式将数据分配给可用资源,在添加或删除存储设备时高效地重新组织数据,并对对象副本放置实施灵活的约束,从而在出现同时或相关硬件故障时最大限度地提高数据安全性。CRUSH支持多种数据安全机制,包括 n 路复制(镜像)、RAID 奇偶校验方案或其他形式的擦除编码,以及混合方法(例如 RAID-10)。这些特性使得 CRUSH 非常适合管理超大型(多 Pb)存储系统中的对象分布,在这些系统中,可伸缩性、性能和可靠性至关重要
2 Related Work
略
3 The CRUSH algorithm
CRUSH算法基于每个设备的权重来将数据分配到存储设备中,近似为均匀地概率分布。该分布由分层的集群图控制,该集群图表示可用的存储资源,并由构建该集群的逻辑元素组成。例如,大的系统可以描述为:cabinets组成的rows,shelves组成的cabinets和由storage devices组成的shelves。数据分布策略是根据放置规则定义的,放置规则指定从集群中选择多少个副本目标以及对副本放置施加什么限制。例如,可以指定将三个镜像副本放在不同物理机柜中的设备上,以便它们不共享同一电路。
给定一个整数输入值 x,CRUSH 将输出 n 个不同存储目标的有序列表R。CRUSH利用一个强多输入整数哈希函数,其输入包括 x,使得映射完全确定,并且仅使用聚类图、放置规则和 x 就可以独立计算。分布是伪随机的,因为在来自相似输入的结果输出之间或者在任何存储设备上存储的项目之间没有明显的相关性。我们说 CRUSH 生成副本的分散分布,因为共享一个项目的副本的设备集看起来也独立于所有其他项目。
3.1 Hierarchical Cluster Map
集群图由设备和桶组成,两者都有数字标识符和权重值。存储桶可以包含任意数量的设备或其他存储桶,允许它们在存储层次结构中形成内部节点,其中设备始终位于叶子位置。存储设备被管理员分配权重,以此控制他们负责存储数据的相对数量。、尽管一个大型系统可能包含具有各种容量和性能特性的设备,但随机数据分布在统计上将设备利用率与工作负载相关,这样设备负载与存储的数据量平均成正比。这产生了一维的放置度量:weight,它是从设备的容量中导出的。桶的weight被定义为它包含的所有桶/设备的weight和。
桶可以任意地组合,以构成表示可用存储的层次结构。比如,用户可能创建一个集群图,在最低层使用"shelf"桶来代表安装的独立设备,然后将shelf组合成"cabinet"来将在同一个机架上安装的设备分组。"cabinets"可能进一步组成"row"或者"room",形成更大的系统。通过伪随机散列函数递归地选择嵌套的桶项目,将数据放置在层次结构中。在传统哈希技术中,目标容器(设备)数量的任何变化都会导致容器内容的大规模重组,与此相反,CRUSH 基于四种不同的桶类型,每种桶类型都有不同的选择算法,以解决因添加或删除设备以及总体计算复杂性而导致的数据移动问题。
3.2 Replica Placement
CRUSH设计用以在加权设备间均匀地分布数据,来保持存储和设备带宽资源使用的统计平衡。副本在层次结构中所放置的位置对数据安全也有重要影响。通过翻译安装系统的底层物理组织,CRUSH可以模拟—进而解决—相关设备故障的潜在来源。典型的来源包括物理接近性、共享电源和共享网络。通过将这种信息编码到集群图中,CRUSH的放置规则可以将对象副本分到不同的故障区域,并且仍然保持所需的分布。例如,为了解决同时发生故障的可能性,可能希望确保数据副本位于不同机架、电源、控制器或物理位置中的设备上。
为了适应CRUSH在数据复制策略和底层硬件配置方面的各种可能的使用场景,CRUSH为每个复制策略或者分发规则定义了放置规则,允许存储系统或管理员精确定义对象副本应该如何放置。例如,一个系统可能有一个规则,选择一对目标用于双向镜像,一个用于在两个不同的数据中心选择三个目标用于3路镜像,一个用于6个存储设备上的RAID-4,以此类推。
每条放置规则都由在一个简单的执行环境中作用到层次结构的一系列操作组成,展示为算法1的伪代码。CRUSH的整数输入 x 通常是对象名称或其他标识符,例如其复制品将被放置在相同设备上的一组对象的标识符。take(a) 函数在存储层次结构中选择一个项目(通常是一个存储桶),并将其分配给 vector ,
充当后续操作的输入。select(n,t)函数对于每个
中的元素i迭代一次,然后选择挂在i下面的子树中的n个t类型的单元。存储设备具有已知的固定类型,并且系统中的每一个桶都有一个类型域用来区分桶的类型(比如“rows”和“cabinets”)。对于
中的每个i,select(n,t)函数在需要的r个单元上迭代,并递归下降通过任意中间桶,通过c(r,x)伪随机地选择桶里的一个嵌套的单元,直到返回需要的类型t。返回的n个结果被放回到向量I中,要么形成接下来select(n,t)的输入,要么通过emit操作放到结果向量中。

例如,在Table1中定义的规则从层次结构中的根部开始,首先用select(1,row)选择一个“row”类型的桶(它选择了row2)。接下来的select(3,cabinet)在之前选择的row2下面选择嵌套的三个不同的cabinet (cab21,cab23,cab24),而最后的select(1,disk)在三个cabinet上迭代,然后在每一个下面选择单个的disk。最终结果是三个disk分布在cabinet中,但都在同一个row中。因此,这种方法让副本既可以分离也可以集中在某个容器类型中,这对于可靠性和性能考虑都是有用的特性。如远程复制场景(其中一个副本存储在远程站点)或分层安装(例如,快速的近线存储和较慢的高容量阵列)中可能预期的那样,由多个获取、发出块组成的规则允许从不同的存储池中显式提取存储目标。
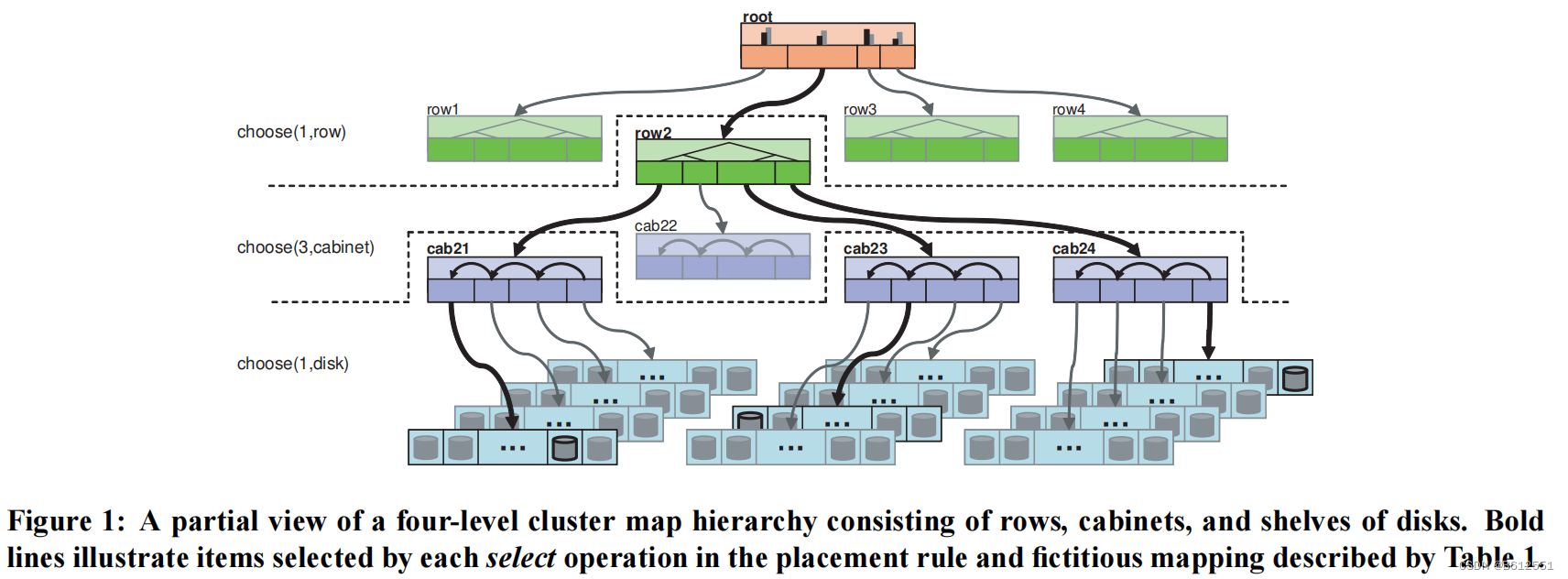
3.2.1 Collisions, Failure, and Overload
select(n,t)函数可以遍历存储分层结构的许多层,以便定位嵌套在其起始点之下的指定类型 t 的 n 个不同单元,这是一个以r(选择的副本数量)=1,...,n为参数的递归过程。在这个过程中,CRUSH可能由于三个原因会用一个修改的输入r'来拒绝和重新选择单元:在当前集合中该单元已经被选择(一个冲突,select(n,t)的结果必须是不重复的)、一个设备出现故障、或者一个设备过载了。发生故障或过载的设备在群集图中被相应地标记,但被留在层次结构中以避免不必要的数据移动。CRUSH通过使用集群图中指定的概率进行伪随机拒绝,选择性地分散过载设备数据的一部分——通常与它所报告的过度使用有关。对于故障或过载的设备,通过在选择select(n,t)开始时重新启动递归,均匀地重新分配项目。在冲突的情况下,首先在递归的内部使用另一个r‘来尝试局部搜索,并避免使整个数据分布偏离更可能发生碰撞的子树(例如,桶小于n)。
3.2.2 Replica Ranks
奇偶校验和擦除编码方案的放置要求与复制略有不同。在主副本复制方案中,在出现故障后,通常希望以前的副本(已经有数据副本)成为新的主副本目标。在这种情况下,CRUSH 可以使用通过使用重新选择“前 n 个”合适的目标,其中f是目前select(n,t)尝试的放置失败的次数。然而,对于奇偶和擦除编码方案,存储设备在 CRUSH 输出中的排序或位置是关键的,因为每个目标存储数据对象的不同位。特别是,如果一个存储设备出现故障,应在 CRUSH 的输出列表
中将其替换到位,以便列表中的其他设备保持相同的排序(即在R中的次序)。在这种情况下,CRUSH 使用
进行重选,其中
是 r 上失败的尝试次数,从而定义了一个序列在概率上独立于其他副本的故障。相比之下,RUSH 对故障设备没有特殊处理;像其他现有的散列分布函数一样,它隐含地假设使用“前 n 个”方法来跳过结果中的故障设备,这使得它不适用于奇偶校验方案。
3.3 Map Changes and Data Movement
在大型文件系统中,数据分布的一个关键因素是如何对存储资源的添加或删除进行响应。CRUSH 始终保持数据和工作负载的均匀分布,以避免负载不对称和相关的可用资源利用不足。当单个设备出现故障时,CRUSH标记该设备,但将其留在层次结构中,在那里它将被不被使用,其内容将被放置算法统一地重新分配。这种集群映射的变化会让总数据中比重的数据被重新映射到新的存储设备(w是所有设备的总权重),因为只移动了出现故障的设备上的数据。
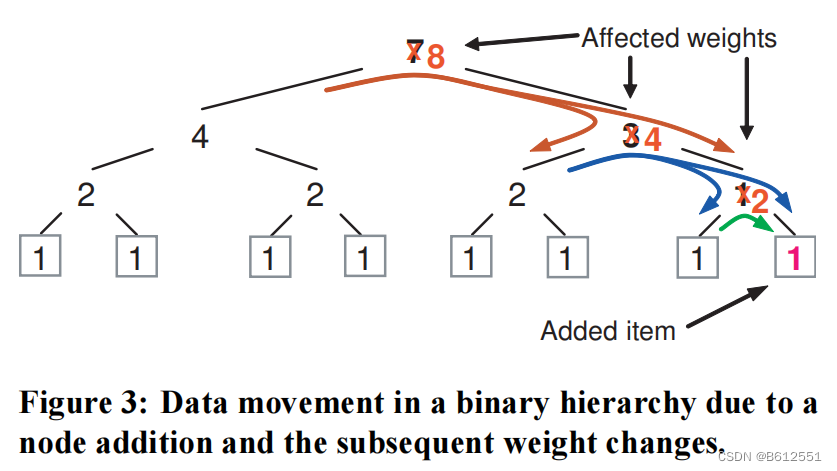
当修改集群层次结构时,情况会更加复杂,例如添加或删除存储资源。CRUSH算法映射过程使用聚类图作为加权分层决策树,可以产生超出理论最优值的额外数据移动。在层次结构的每一层层次上,当相对子树权重的变化改变了分布时,一些数据对象必须从权重减少的子树移动到权重增加的子树。因为层次结构中每个节点上的伪随机放置决策在统计上是独立的,所以移动到子树的数据在该点下均匀地重新分布,并且不一定被重新映射到最终导致权重变化的叶项。只有在放置过程的后续级别(更深层次的)级别上,(通常是不同的)数据会被移动以保持正确的总体相对分布。图3中的二进制层次结构的情况说明了这种一般效果。
层次中数据移动量又一个下限,这是将留在新添加设备的权重为
的数据的占比。数据的移动量会随着层次结构的高度
增加,渐进上界为
。当
相对于
较小时,移动量接近这个上界,因为在递归的每一步移动到子树中的数据对象被映射到相对权重较小的项的概率非常低。
3.4 Bucket Types
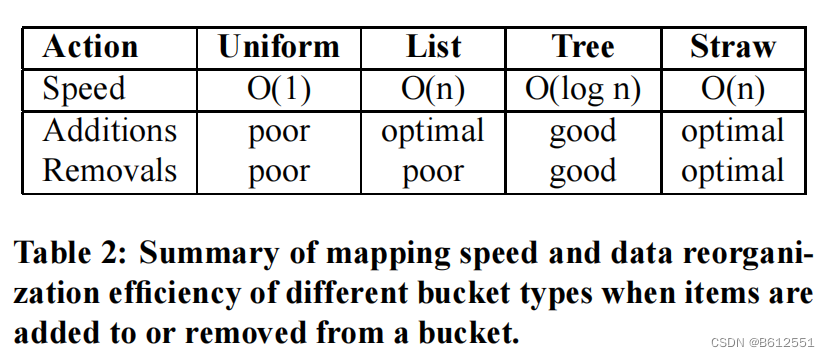
一般来说,CRUSH 旨在协调两个相互竞争的目标:映射算法的效率和可扩展性,以及当集群由于添加或删除设备而发生变化时,通过最少的数据迁移来恢复平衡的分布。为此,CRUSH 定义了四种不同的桶来表示集群层次结构中的内部(非叶)节点:统一桶uniform buckets、列表桶list buckets、树桶tree buckets和稻草桶straw buckets。每个桶类型都基于不同的内部数据结构,并利用不同的函数c(r,x)在副本放置过程中伪随机选择嵌套项目,代表了计算和重组效率之间的不同权衡。统一桶受到限制,因为它们必须包含所有具有相同权重的项(很像传统的基于散列的分布函数),而其他桶类型可以包含具有任何权重组合的项的组合。这些不同在Table2中进行了总结。
3.4.1 Uniform Buckets
在大型系统中,设备很少单独添加。相反,新存储通常部署在相同设备的块中,通常作为服务器rack中的附加shelf,或者作为整个cabinet。达到使用寿命的设备通常会作为一个整体退役(个别故障除外),这使得将它们作为一个单元来处理变得很自然。在这种情况下,CRUSH的uniform bucket被用来代表一组相同的设备。这样做的关键优势是与性能相关的:CRUSH可以在恒定的时间内将复制副本映射到统一的桶中。在均匀性限制不合适的情况下,可以使用其他桶类型。
给定一个CRUSH输入值x和一个副本数r,我们使用函数c(r,x)=(hash(x)+ rp)mod m从一个大小为m的uniform bucket中选择一个项,其中p是一个随机(但确定性)选择的大于m的素数。对于任何r≤m,我们可以使用一些简单的数论引理证明我们总是来选择一个不同的项。对于r > m,这个保证不再成立,这意味着具有相同输入x的两个不同的副本r可能得到相同的项目。在实践中,这只意味着放置算法的碰撞非零概率和随后的回溯。
如果统一桶的大小发生变化,设备之间就会对数据进行完整的重新洗牌,就像传统的基于散列的分布策略一样。
3.4.2 List Buckets
它的结构是链表结构,所包含的item可以具有任意的权重。CRUSH从表头开始查找副本位置,它先得到表头item的权重Wh,然后和剩余所有节点权重之和Wr做比较,然后根据hash(x, r, item)得到一个[0~1]值v,如果v在[0~Wh/Wr],则副本在表头item中,并返回item的id,否则继续遍历剩余的链表。这个方法是从RUSHp算法中演变过来的,将数据分布问题转变为“most recently added item, or older items”。这种方法对于总是有新节点加入的情况很有好处,但当有节点从中间或者尾部删除时,就会带来一些数据迁移。这也和它的计算方法有关系,如果从尾部删除一个节点后,Wr的值回发生变化,所以ratio的值也会发生变化。使用这种bucket会使得数据要么存储在新加入的节点上,要么就还保留在原来老的地方。
List Bucket的查找复杂度为O(n),所以只适用于规模比较小的集群。
3.4.3 Tree Buckets
该方法是从RUSHt演化过来的,主要是为了解决规模比较大的环境,查找复杂度O(logn)。Tree buckets中的元素被组织成一个加权的二叉查找树,所有的项都位于叶子节点。每一个内部节点都知道他左右子树的权重,并且按照固定的策略打上标签。当需要从bucket众选出一项时,CRUSH从root节点开始查找副本的位置,它先得到节点的左子树的权重Wl,得到节点的权重Wn,然后根据hash(x, r, node_id)得到一个[0~1]的值v,假如这个值v在[0~Wl/Wn)中,则副本在左子树中,否则在右子树中。继续遍历节点,直到到达叶子节点。Tree Bucket的关键是当添加删除叶子节点时,决策树中的其他节点的node_id不变。二叉树中节点的node_id的标识是根据对二叉树的中序遍历来决定的(node_id不等于item的id,也不等于节点的权重)。
二叉树的节点的标签方法使用的是一个简单固定的方法,以避免树中有节点增加或者节点减少而导致节点标签的变化。这个规则很简单:
1)树中最左侧的叶子节点永远是1
2)每次树增长的时候都会产生一个的新的根节点,之前的根节点会变成新根节点的左孩子。新的根节点的标签等于老的根节点的标签向左移一位(1,10,100,etc)。树的右侧的标签会复制左侧节点的标签并在最左侧在加上一个1。
tree bucket在查询性能上相比于list要好,而且数据迁移的控制也比较好。当一个节点发生变化时,只会导致节点所在子树上发生数据迁移。
3.4.4 Straw Buckets
列表桶和树桶的结构是,需要计算有限数量的哈希值,并与权重进行比较,以选择一个桶项。在这样做的时候,它们以一种赋予某些项目优先级的方式进行划分和征服(例如,那些位于列表开头的项目),或者完全无需考虑项目的整个子树。这提高了副本放置过程的性能,但当桶的内容由于添加、删除或重新加权项目而改变时,也可能引入次优重组行为。
这种类型让Bucket所包含的所有item公平的竞争(不像list和tree一样需要遍历)。这种算法就像抽签一样,所有的item都有机会被抽中(只有最长的签才能被抽中)。每个稻草的长度基于项目的权重的三次方用f(wi)进行调整,这样权重较重的项目更有可能赢得抽签。每个签的长度是由f(Wi)*hash(x, r, i) 决定的,Wi是item i的权重,i是item的id号。c(r, x) = MAX(f(Wi) * hash(x, r, i))。目前,这种Bucket是Ceph默认使用的Bucket,所以它也是经过大规模测试的,稳定性较好。虽然它的查询性能不如List和Tree,但它在控制数据迁移方面是最优的。
参考:Ceph学习之Crush算法—— Bucket_ceph中crush的bucket的作用_瞧见风的博客-CSDN博客















 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









