







Day14
步骤
- requests - 请求页面,得到响应结果
- BeautifulSoup4 - 根据响应结果解析页面、提取数据
- 写入文件、数据库
引用模块
import requests
from bs4 import BeautifulSoup
注:bs4 -> BeautifulSoup5,bs4模块能从html或者xml中提取数据
我们对中国新闻网进行解析

for page in range(1, 11):
print(f'第{page}页')
URL = f'https://www.chinanews.com.cn/scroll-news/news{page}.html'
引入Headers
在日常爬网页的时候,为了不让网页发现我们在做爬虫操作,我们可以引入Headers,在我们要爬取的网页里可以找到Headers属性,这样网页会认为我们是正常浏览数据,就不容易被拒绝我们的爬虫申请。
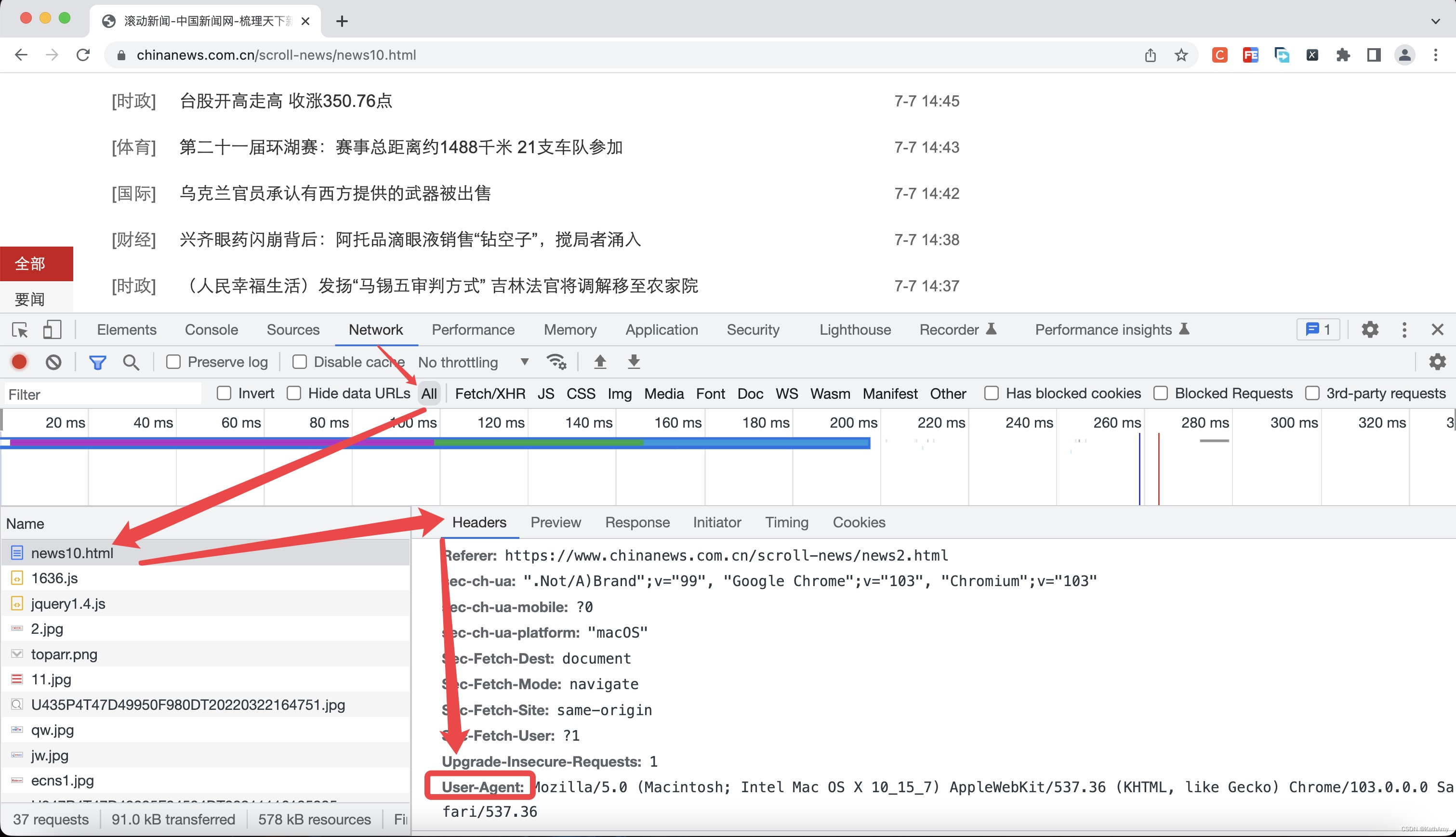
Headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









