







一、前言
今天,我非常荣幸能与大家分享基于机器学习的单词难度预测这个话题,难免有不足之处,还望大家见谅
首先,让我用一个故事开场吧
从前有一个聪明的大学生,他非常喜欢学英语
但是,每次遇到一些难以理解的单词,他都会感到困惑
于是,他决定研究如何预测单词的难度
通过机器学习的方法,他成功地找出一个适合单词难度预测的模型
这个模型通过分析单词的各种特征,例如单词长度、出现频率等,来判断其难度
通过大量的数据训练和测试,这个模型能够准确地预测单词的Z分数
而我们今天将会探讨这个过程
在我们的研究中,我们发现了一些有趣的现象
例如,长单词并不一定就是难词;同时,一些短小的单词却可能具有高难度
这些发现将有助于我们更好地理解单词的难度
通过这个基于机器学习的单词难度预测模型,我们可以为教学提供更有针对性的建议和指导,帮助学生更好地掌握英语
二.数据收集与预处理
数据收集与预处理是数据分析的基础
1.数据源
数据源是指我们获取数据的地方,它决定了数据的可靠性和准确性
常见的数据源有内部数据源和外部数据源
内部数据源包括企业内部的数据库、客户关系管理系统等,这些数据源具有高度的可信度
而外部数据源可以是公开的数据库、市场调研报告等,这些数据源的优势在于覆盖范围广
而数据的收集方法则是指我们如何获取数据的过程
常见的数据收集方法有三种:调查问卷、访谈和观察
调查问卷是主动收集数据的一种方式,通过设计问卷并发放给被调查者来获取数据
访谈是通过面对面或电话等方式与被访者进行交流,以获取详细的信息和观点
观察则是通过观察被研究对象的行为和环境来搜集数据
选择合适的数据源和数据收集方法对于数据分析和决策制定至关重要
数据源下载链接:https://pan.baidu.com/s/1YmTdlnbSJLvLrrx92zz6Qg
提取码:wkk6
下面附上数据源截图:
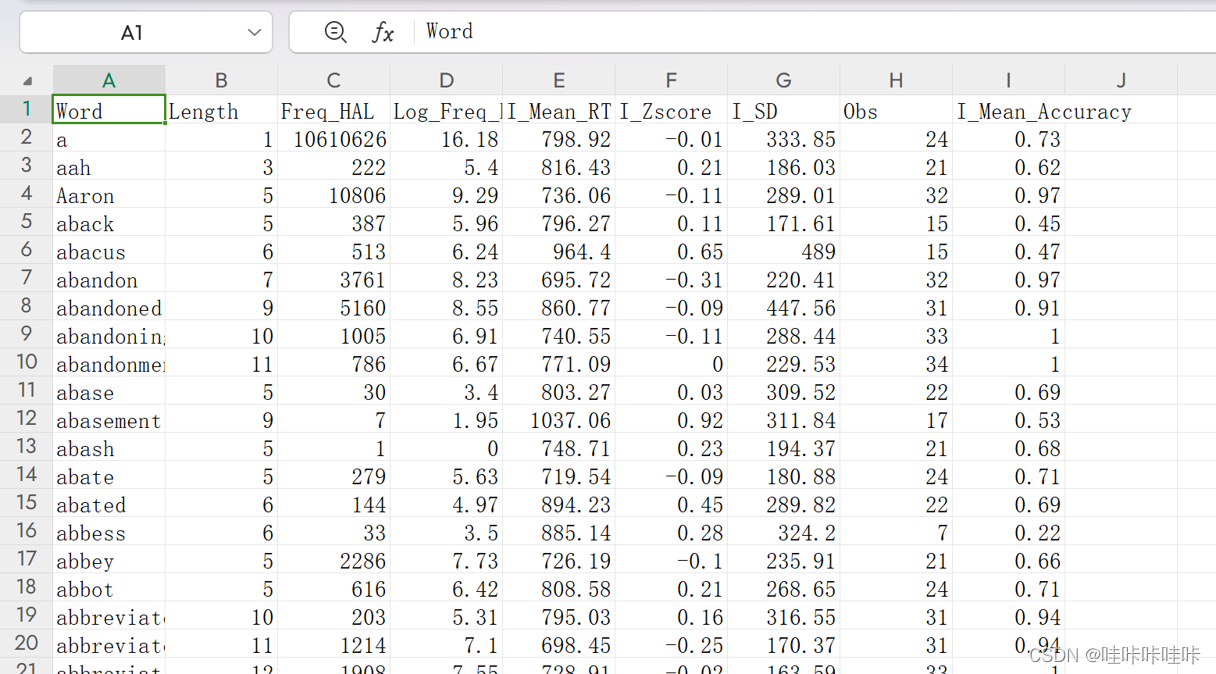
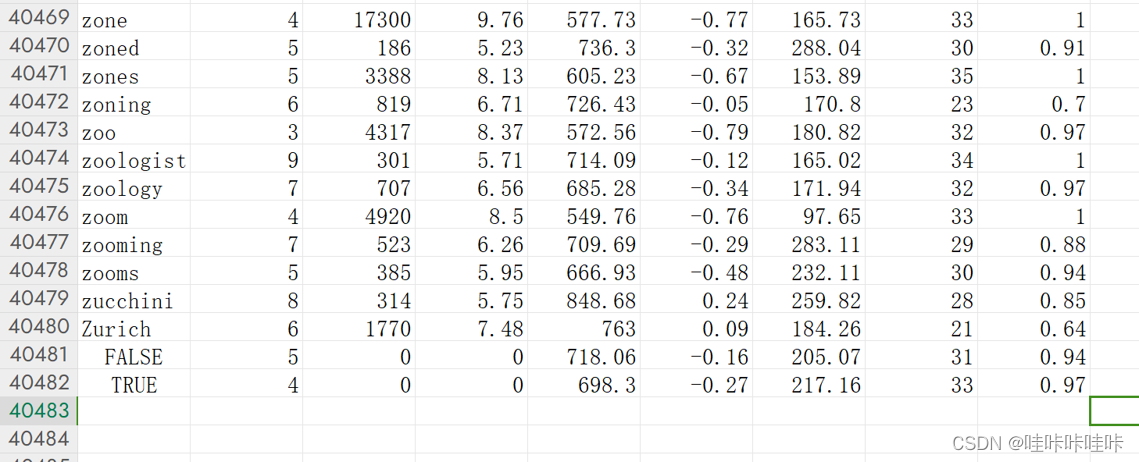
Word(单词):该列表示需要预测难度的单词。
Length(长度):表示单词的长度(字符数)。
Freq_HAL(频率_HAL):该列表示单词在参考语料库中的频率。
Log_Freq_HAL(对数频率_HAL):表示单词频率的对数。
I_Mean_RT(平均反应时间):该列表示识别单词难度的平均反应时间。
I_Zscore(Z分数):是平均反应时间的Z分数值。
I_SD(标准差):表示反应时间的标准差。
Obs(观察数):表示该特定单词的观察次数。
I_Mean_Accuracy(平均准确率):该列表示识别单词难度的平均准确率。
这些列提供了用于预测单词难度的各种特征和指标,包括单词特性、频率、反应时间和准确率。该数据集旨在探索使用机器学习模型来预测单词难度,特别关注字符级别上的卷积神经网络等深度学习方法。 在单词难度预测的数据集中,I_Zscore(Z分数)列表示平均反应时间的Z分数。
读者要想理解何是Z分数,本人建议看这篇文章:
如何通俗的理解z分数 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/364497220个人感觉通俗易懂,是大众都能接受的讲解。
https://zhuanlan.zhihu.com/p/364497220个人感觉通俗易懂,是大众都能接受的讲解。
2.导入所需库
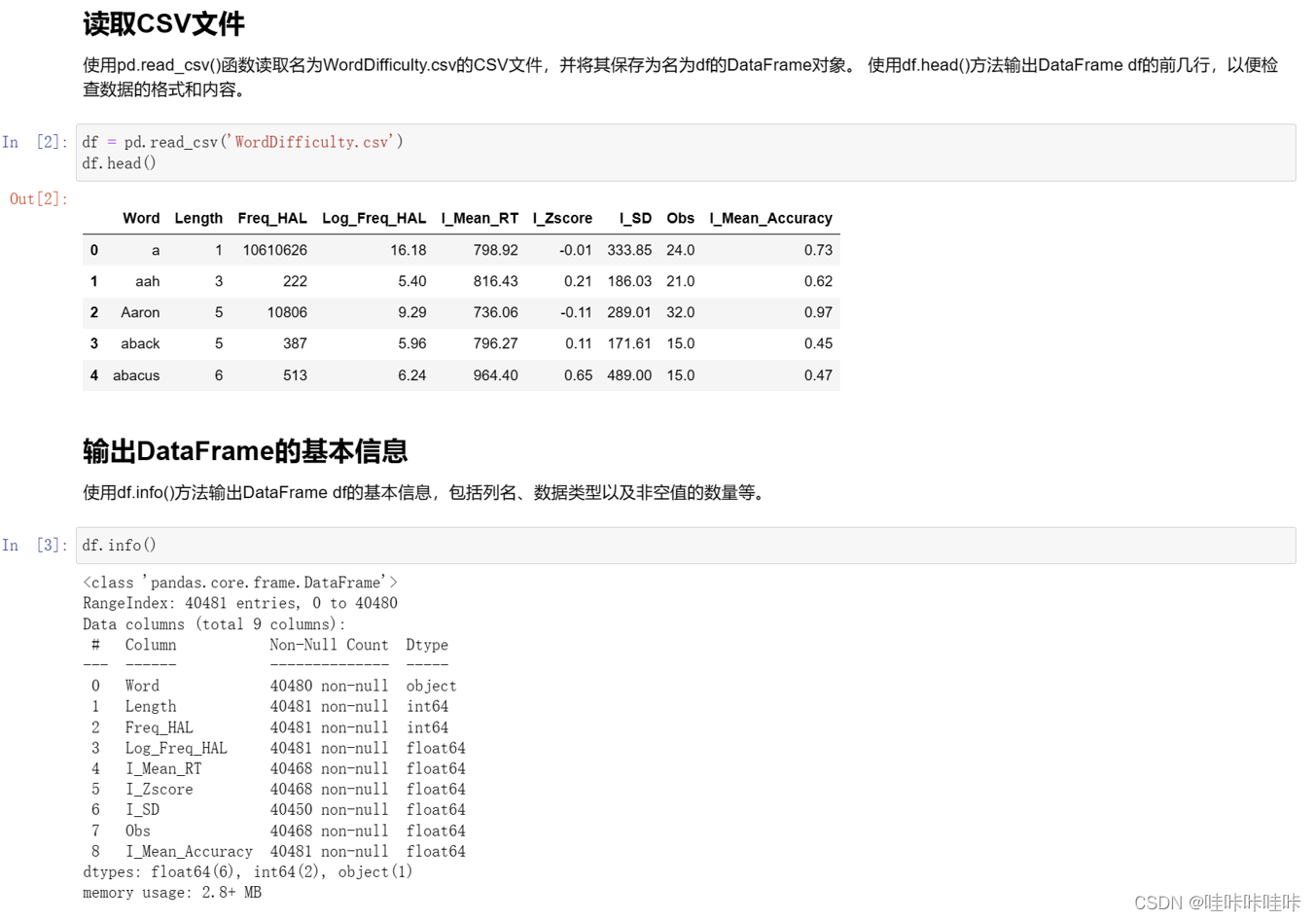
3.读取数据集并输出基本信息
4.数据清洗
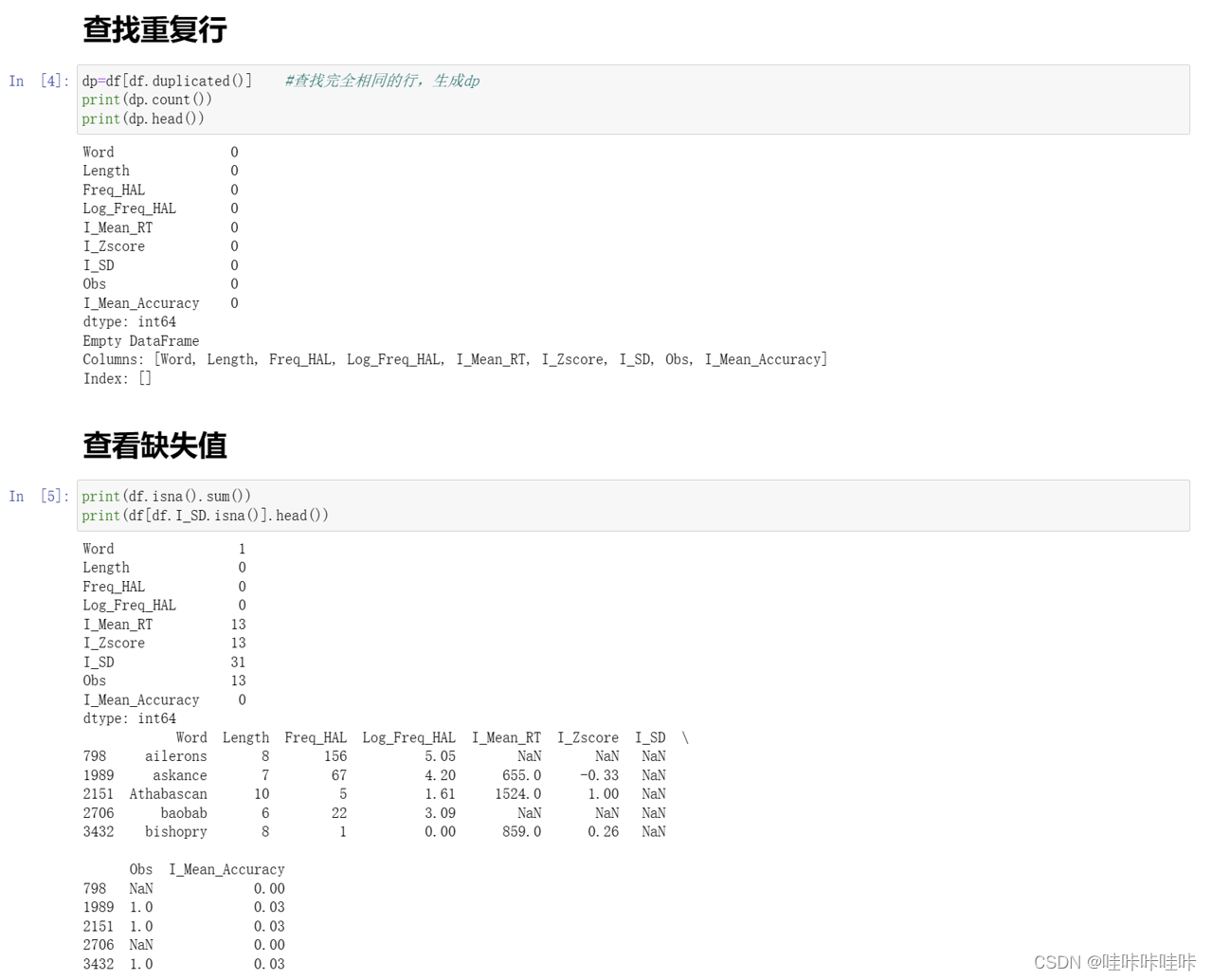
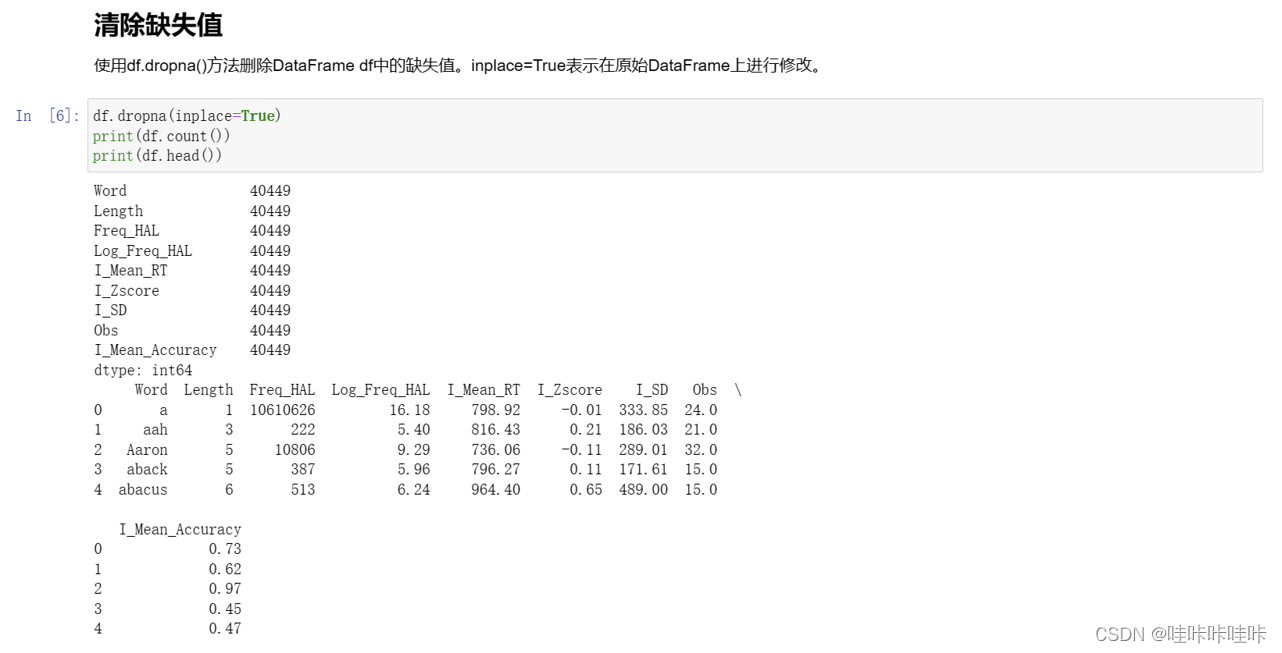
5.查看离群点
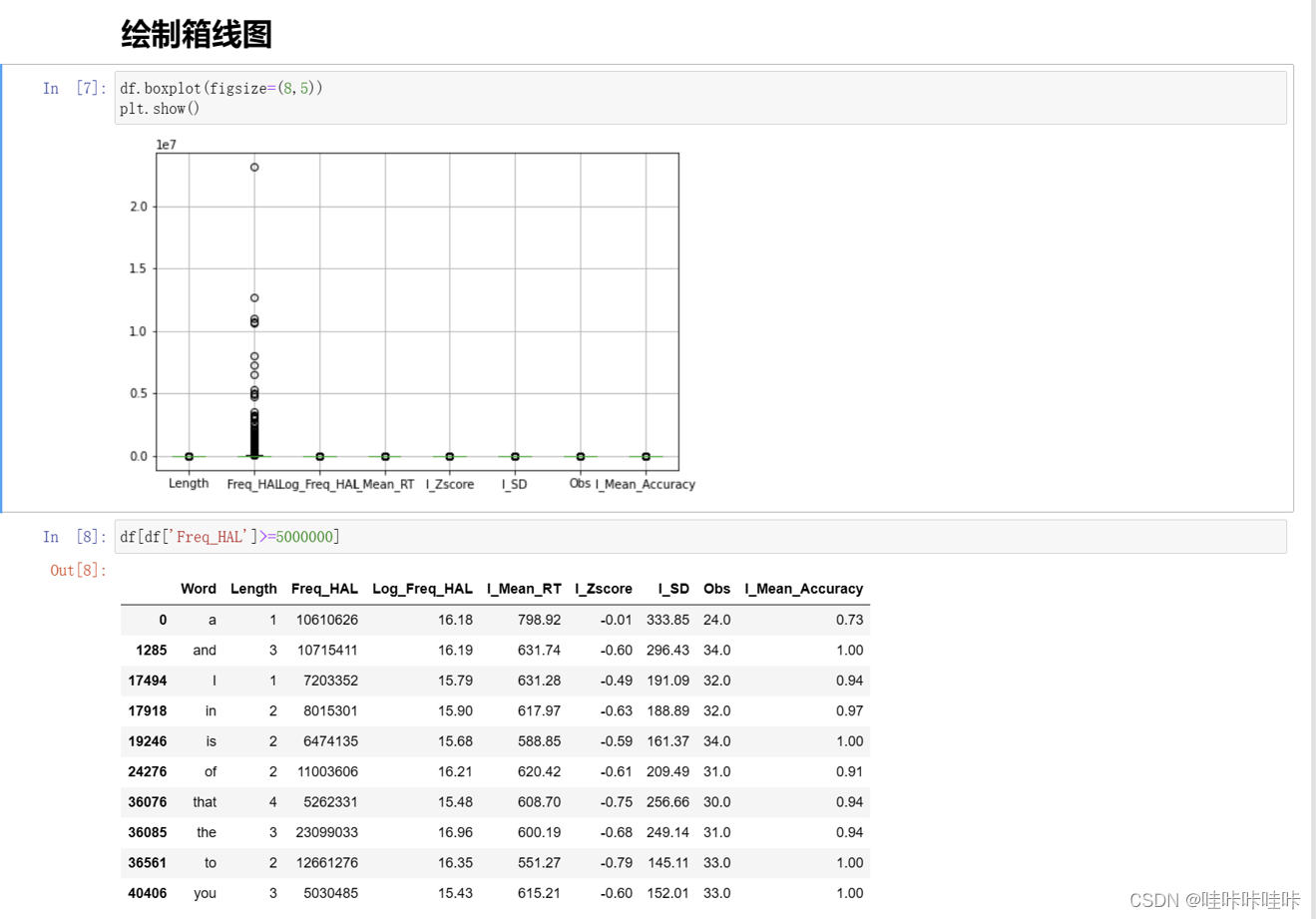
离群点是指与其他数据点相比明显偏离的数据。有时,离群点可能是由于错误、异常或测量误差等原因引起的,这种情况下通常会考虑将其去除。然而,如果离群点是合理且有效的数据,即使它们与其他数据点存在明显差异,也应该保留。
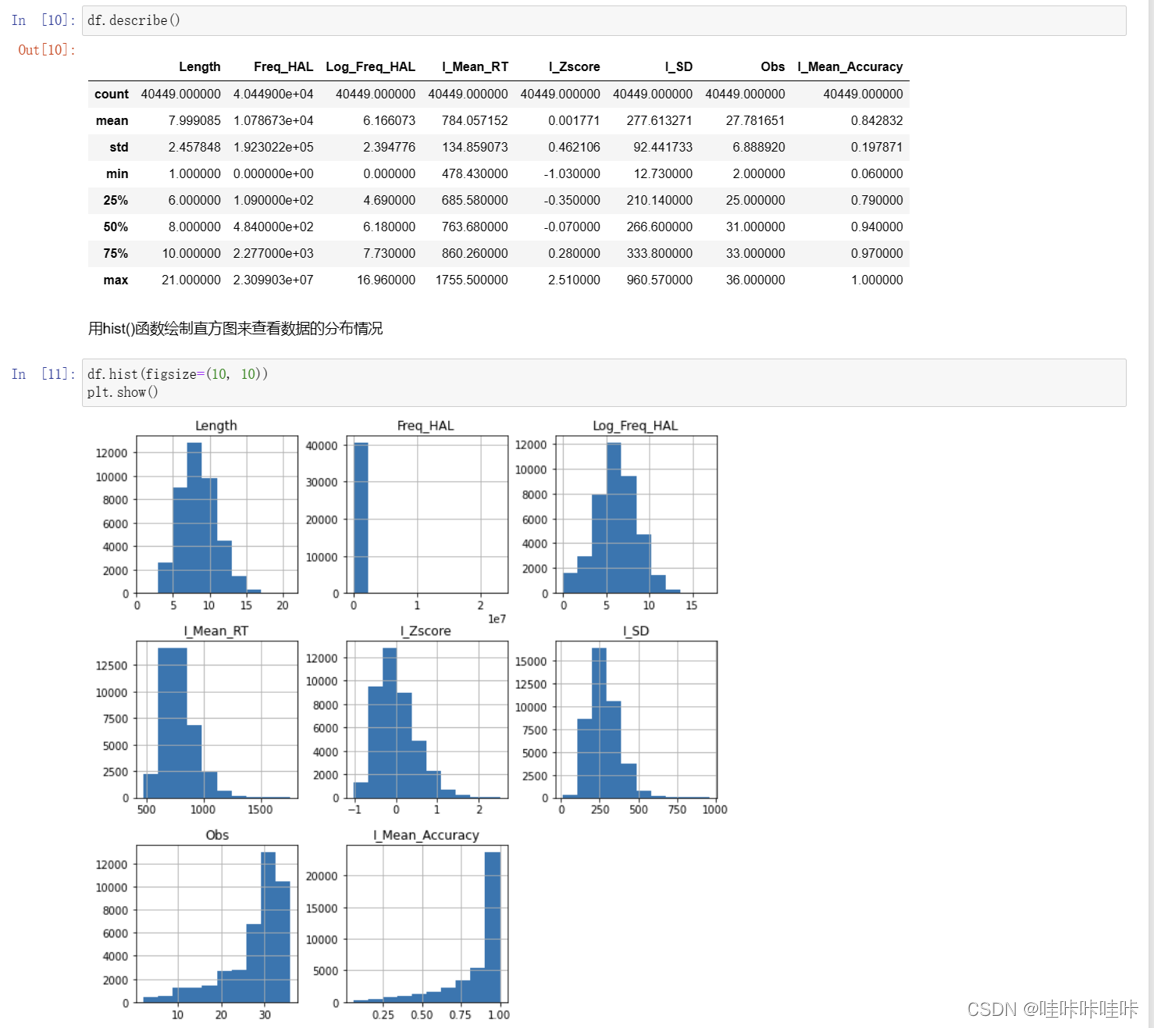
5.对清洗后的数据进行描述并对数据分布情况使用直方图进行可视化
6.对数据进行归一化处理

三、数据可视化
1.随机抽样一半的词汇进行可视化
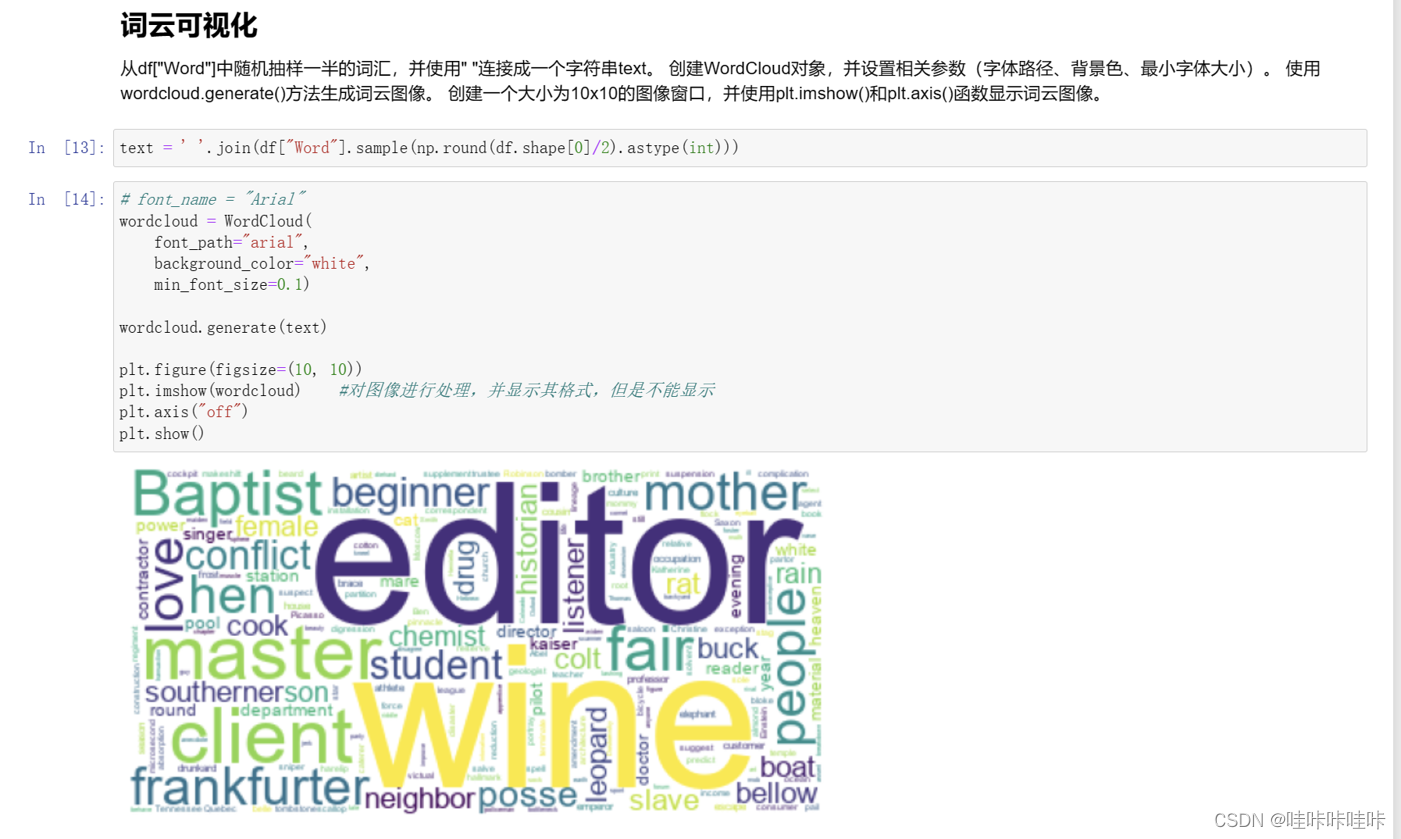
2.生成最难和最容易词汇的词云图


四、特征选择与提取
特征选择是指从原始数据中选择最相关的特征,以便于建立准确的模型
而特征提取则是通过对原始特征进行变换和组合,得到更有信息量的特征
这些方法的应用可以帮助我们减少特征维度,提高模型的泛化能力
1.绘制各特征间的相关热图

五、模型训练与评估
1.准备训练和测试数据

2.计算主成分分析(PCA)
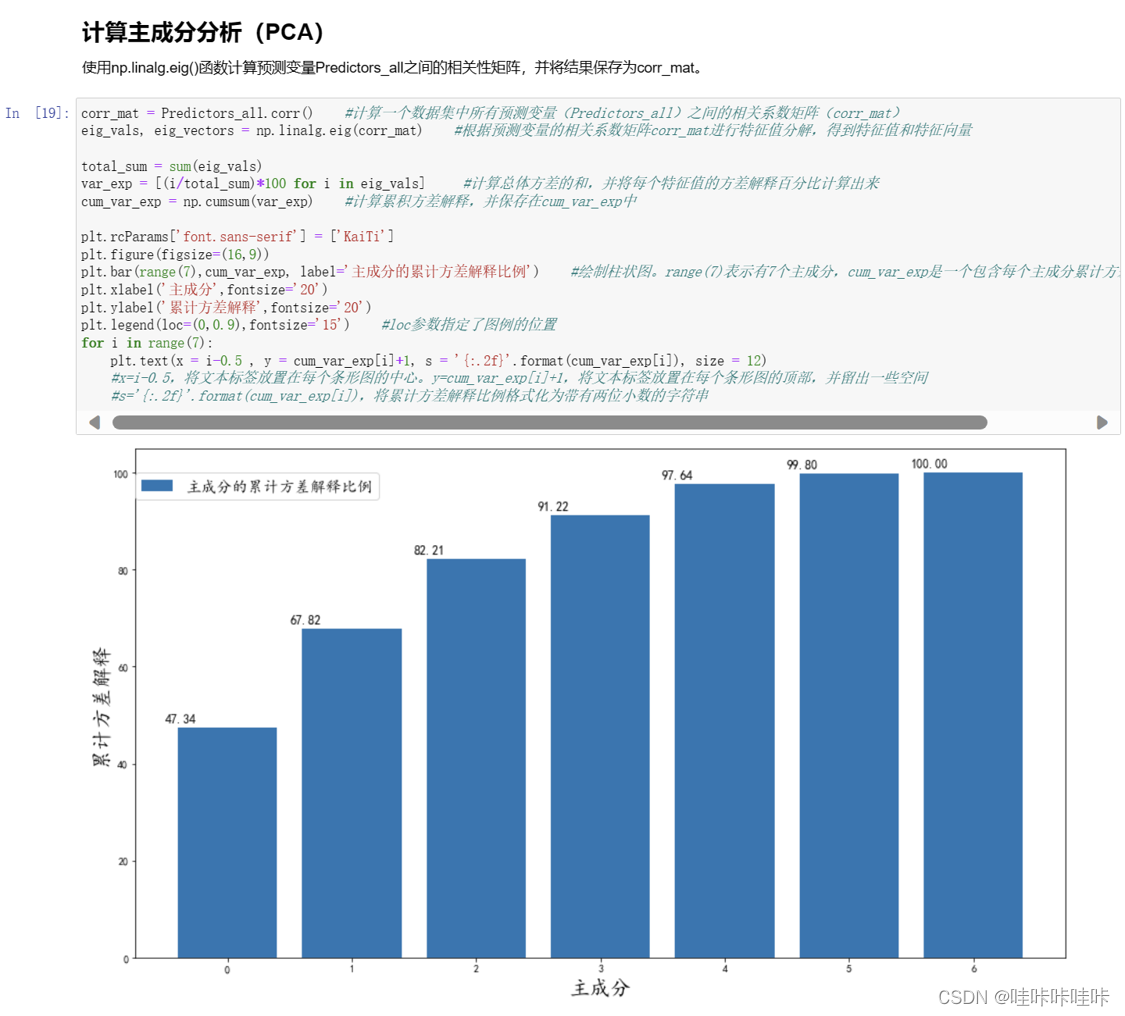
这段代码的目的是进行主成分分析(PCA)以评估预测变量之间的相关性和方差解释比例。主成分分析是一种降维技术,用于将高维数据转换为低维空间,同时保留尽可能多的信息。
具体步骤如下:
通过计算预测变量之间的相关系数矩阵,即corr_mat,来衡量它们之间的线性关系。
使用特征值分解(eig_vals, eig_vectors)对相关系数矩阵进行降维,得到特征值和特征向量。特征值表示每个主成分(特征向量)所解释的方差大小。
计算总体方差的和,并根据每个特征值的方差解释比例计算出每个主成分的方差解释百分比。
计算累积方差解释,即前n个主成分的方差解释比例之和。
使用柱状图可视化主成分的累积方差解释比例,以便确定保留多少主成分可以解释足够多的方差。
在柱状图上添加标签,显示每个主成分的累积方差解释比例。
3.主成分转换

这段代码使用了PCA(主成分分析)模型来对预测变量进行降维处理。
具体步骤如下:
创建了PCA对象acp,并指定了希望得到的主成分数量为4个(n_components=4)。
调用fit_transform()方法,将预测变量数据集Predictors_all作为输入,进行主成分分析。
主成分分析会根据预测变量之间的相关性和方差解释比例,将原始的预测变量转换为新的主成分。
这些主成分是线性组合的结果,每个主成分都具有不同的方差解释程度。
Predictors_PCA保存了降维后的数据,其中每一行对应一个样本,每一列对应一个主成分。
通过这段代码,我们可以得到降维后的数据集Predictors_PCA,该数据集的维数减少到了4维,同时尽可能地保留了原始数据中的方差信息。这有助于简化数据集、减少冗余信息,并提高模型的效率和解释能力。
问:怎样确定主成分数量,为何上述为4?
答:确定主成分的数量可以根据累计方差解释比例来进行判断。累计方差解释比例表示前n个主成分能够解释的总方差的比例。 在上述代码中,通过绘制累计方差解释比例的柱状图,可以观察到每个主成分对总体方差的贡献程度。通过查看柱状图,我们可以找到一个合适的主成分数量,以保留足够多的方差信息。 在这段代码中,使用了4作为主成分的数量(n_components=4)。这可能是基于柱状图中大部分方差解释比例已经被前4个主成分解释了,并且后续的主成分对方差解释的贡献较小。因此,选择4作为主成分的数量可以在保留较高方差解释比例的同时降低数据的维度。
问:累计方差解释比例是选高的还是低的?
答:在选择主成分数量时,累计方差解释比例通常是选高的,而不是选低的。累计方差解释比例越高,表示所选取的主成分能够解释原始数据中更多的方差,这意味着我们可以使用更少的主成分来保留数据的大部分信息,同时减少冗余信息和噪音,提高数据的可解释性和模型的性能。
一般来说,当累计方差解释比例达到90%以上时,我们认为主成分的数量已经足够,可以停止增加主成分的数量。但是,在具体应用场景中,我们需要综合考虑实际需求、数据特点、运算复杂度等因素来选择合适的主成分数量。
需要注意的是,选择主成分数量是一个相对主观的决定,需要根据实际情况进行综合考虑。可以尝试不同的主成分数量,并评估其对模型性能和数据可解释性的影响,找到最合适的主成分数量。
问:主成分能够全部选择么?
答:在主成分分析中,我们通常选择能够解释原始数据中大部分方差的主成分来降低数据的维度,从而减少冗余信息和噪音。如果要选择全部主成分,那么就没有达到降维的目的,无法减少数据的冗余和噪音,而且还会增加计算成本和复杂性。
因此,通常不建议选择全部主成分。相反,我们应该根据累计方差解释比例来选择最小的主成分数量,以保留尽可能多的信息。一般来说,当累计方差解释比例达到90%以上时,我们认为主成分的数量已经足够,可以停止增加主成分的数量,但是具体的主成分数量需要根据实际问题和应用场景来综合考虑。
需要注意的是,选择主成分数量是一个相对主观的决定,需要考虑实际问题和数据特点,并进行多次试验和评估。在实际应用中,我们可以通过交叉验证等方法来评估不同主成分数量下模型的性能和数据可解释性,以找到最合适的主成分数量。
1.模型预测
针对每种类型的预测变量(Predictors)进行三种类型的回归分析:
- KNeighboursRegressor K近邻(回归)
- RandomForestRegressor 随机森林回归器
- GradientBoostingRegressor 梯度提升回归
1.划分训练集和测试集

2.使用线性回归模型预测
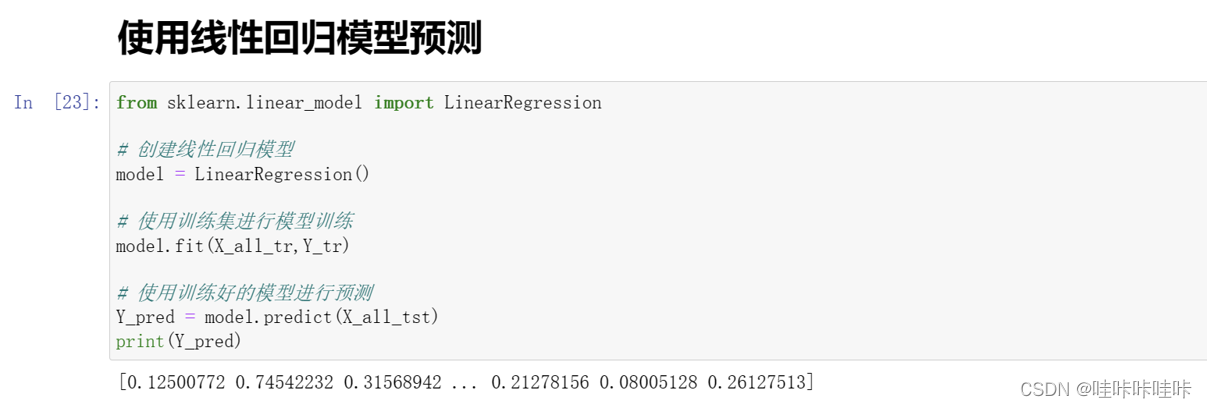
使用scikit-learn库中的线性回归模型(LinearRegression)来进行训练和预测。
具体步骤如下:
导入LinearRegression类:从sklearn.linear_model模块中导入LinearRegression类,该类实现了线性回归模型。
创建线性回归模型对象:使用LinearRegression()创建一个线性回归模型的实例,将其赋值给model变量。
模型训练:使用训练集数据X_all_tr和对应的目标变量Y_tr来训练(拟合)线性回归模型。通过调用fit()方法,模型将根据提供的数据来学习最佳的拟合直线参数。
预测结果:使用训练好的模型对测试集数据X_all_tst进行预测,得到预测结果Y_pred。通过调用predict()方法,模型将根据输入的特征数据生成相应的目标变量预测值。
打印预测结果:将预测结果Y_pred打印输出。
这段代码的目的就是通过线性回归模型对给定的特征数据进行训练,并利用训练好的模型进行预测,最后输出预测结果。
2.分析不同算法和模型在预测结果上的优劣
使用训练集数据X_all_tr和目标值Y_tr来训练回归模型
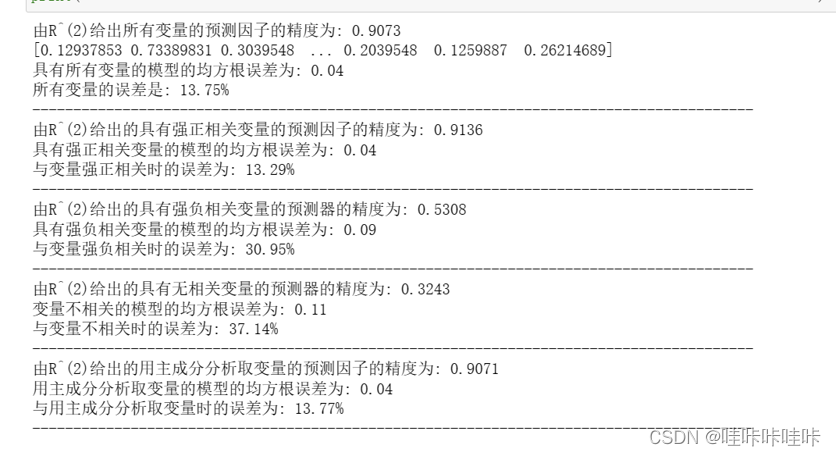
计算并输出使用所有变量进行预测的模型准确度(R^2)
使用训练好的模型对测试集数据进行预测
计算预测值与真实值之间的均方根误差(RMSE)
打印使用所有变量的模型的均方根误差 计算误差,即RMSE除以目标值的均值
打印使用所有变量的模型的误差
1.KNeighboursRegressor K近邻(回归)


问:KNeighboursRegressor与KNN(K近邻)是一个算法么?
答:`KNeighboursRegressor`与`KNN`(K-Nearest Neighbors)是基于相似度度量的算法,但是它们并不是完全相同的算法。
`KNN`是一种分类和回归算法,用于解决监督学习中的各种问题。对于分类问题,`KNN`通过计算新样本点与训练集中每个样本点之间的距离,找到最近的k个邻居,并将新样本点分类为这k个邻居中出现次数最多的类别。对于回归问题,`KNN`同样计算新样本点与训练集中每个样本点之间的距离,找到最近的k个邻居,并将新样本点的输出值设置为这k个邻居的均值。
而`KNeighboursRegressor`是一种基于`KNN`算法的回归器,用于对连续型目标变量进行建模和预测。它使用和`KNN`相同的方法来计算最近邻居,但是在预测过程中使用的是这些邻居的平均值或中位数。
虽然`KNeighboursRegressor`和`KNN`都使用了相同的基本算法原理,但它们的应用场景和目标是不同的。`KNN`通常用于分类和回归两种类型的问题,而`KNeighboursRegressor`则专门用于回归问题。
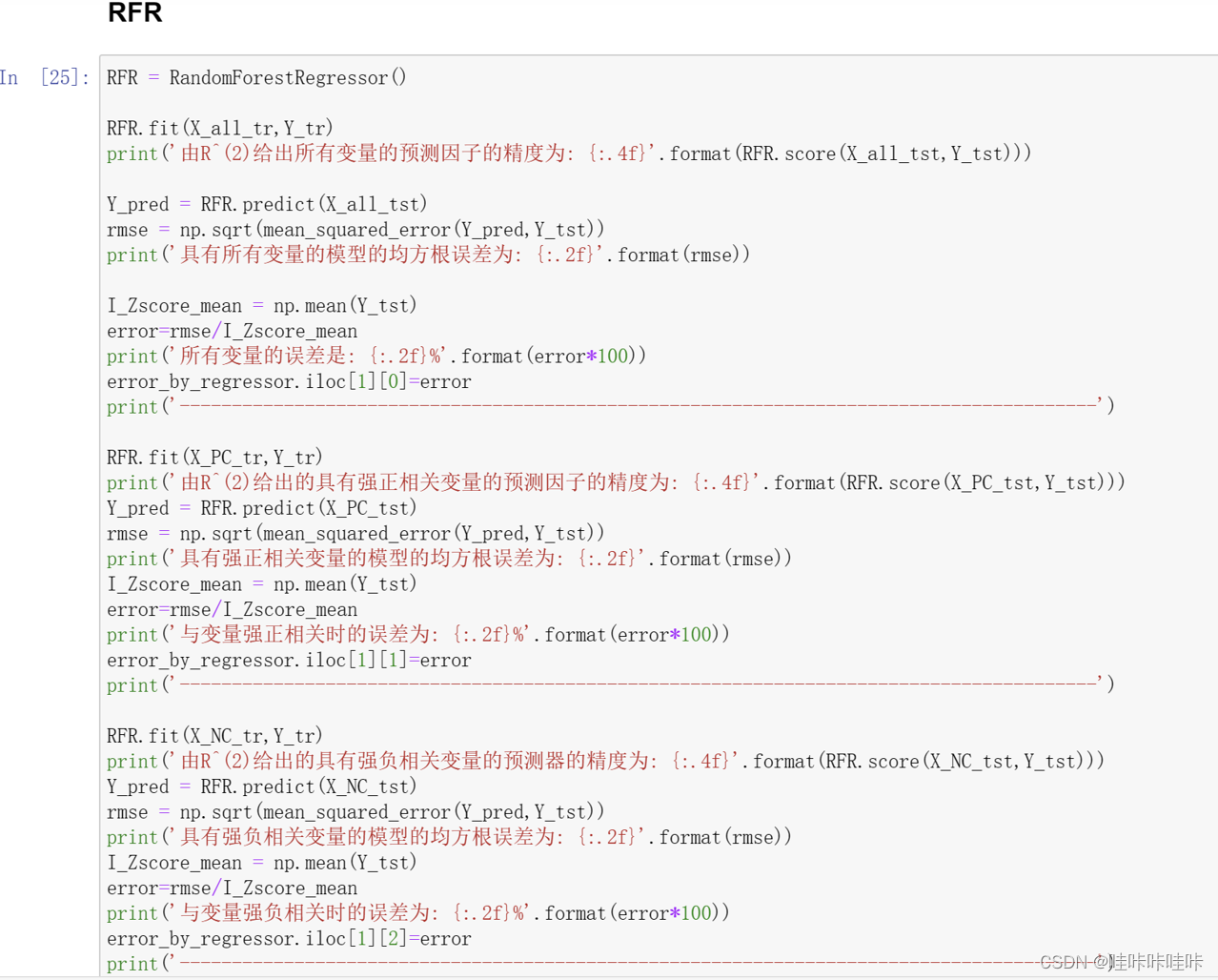
2.RandomForestRegressor 随机森林回归器

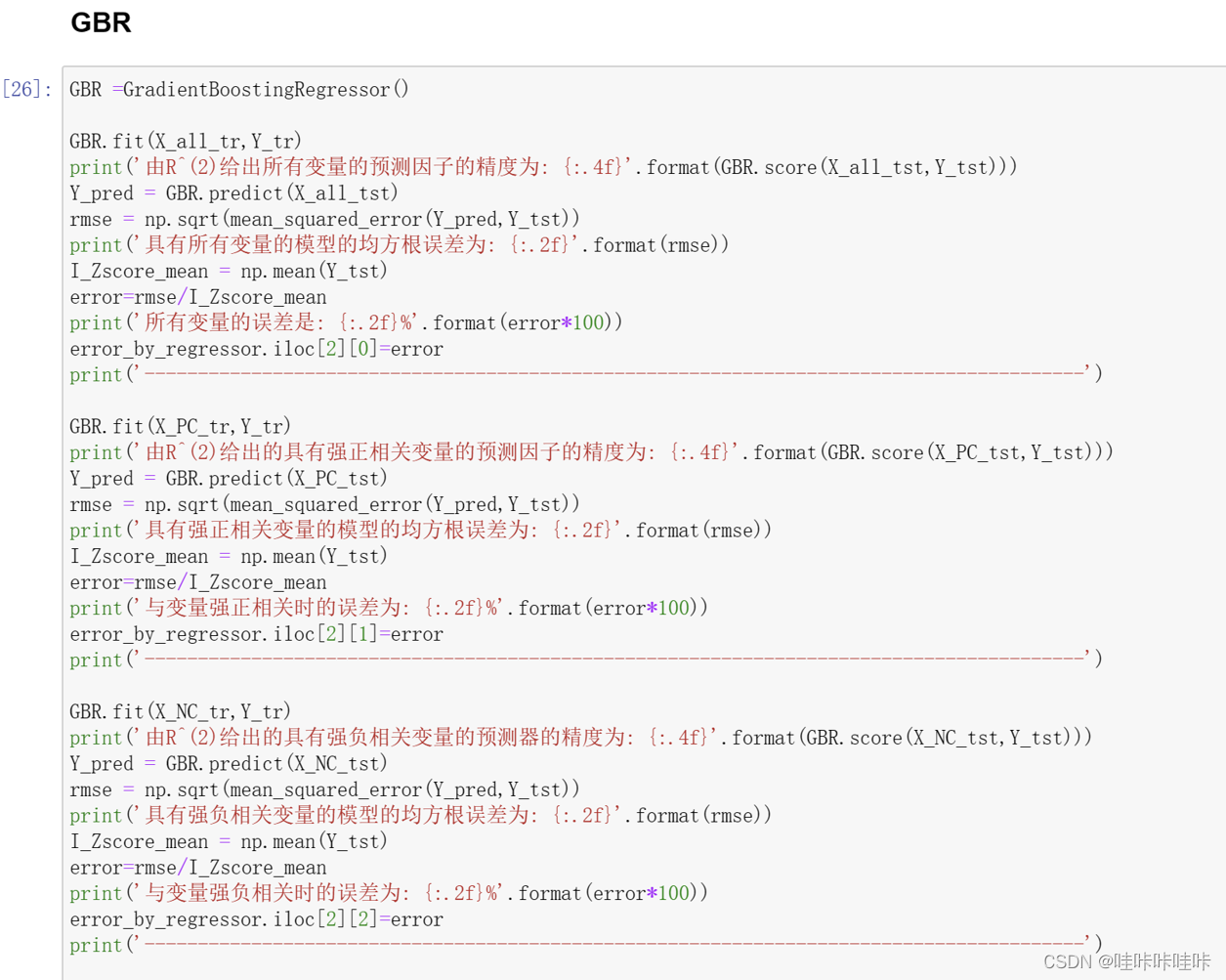
3.GradientBoostingRegressor 梯度提升回归

六、结果分析与解释
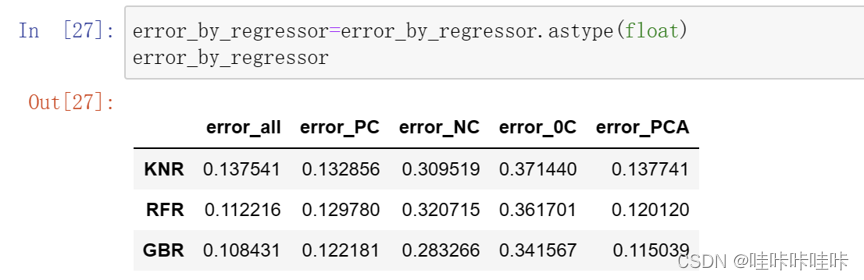
1.评估不同预测变量对于回归模型的影响,并找到最佳的预测变量集合
问:这段代码的目的是什么?
答:这段代码的目的是将`error_by_regressor`中的数据类型转换为浮点型(float)。通常情况下,当我们从外部数据源加载或处理数据时,可能会遇到数据类型不匹配的情况。使用`.astype(float)`将数据类型转换为浮点型可以确保数据被正确地解释和处理。
通过将数据转换为合适的数据类型,可以确保后续的计算或分析过程能够正常进行,并且可以避免由于数据类型不匹配而引起的错误或警告。
2.评估不同预测变量对于回归模型的影响,并找到最佳的预测变量集合
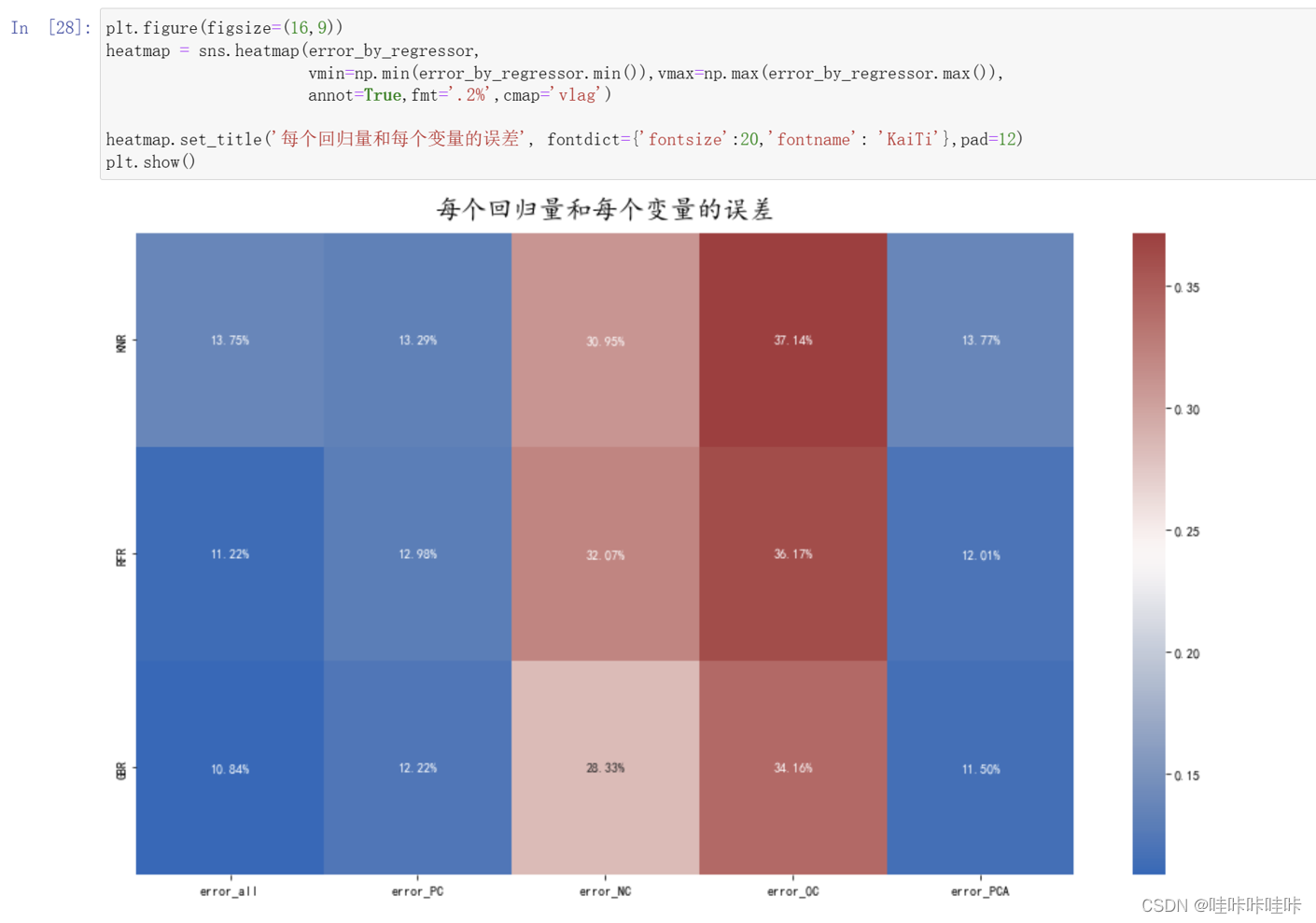
最佳模型是使用所有主成分的梯度提升回归模型,误差为10.84%。
通过所有的方法,可以得出以下结论:
- 使用所有主成分是最佳选择 使用PCA主成分已经够好
- 只使用强正相关的主成分也行
- 只使用强负相关或不相关的主成分较差
问:查看不同回归模型在各个预测变量集合上的误差的目的是什么?
答:查看不同回归模型在各个预测变量集合上的误差的目的是评估不同预测变量对于回归模型的影响,并找到最佳的预测变量集合。
通过比较不同预测变量集合上的误差,我们可以识别出哪些变量对于回归模型的性能有积极影响,哪些变量可能没有带来显著的贡献或可能引入了噪声。
这种分析有助于特征选择和模型优化。通过确定关键的预测变量集合,我们可以构建更简单、更具解释性和更可靠的回归模型。此外,还可以减少模型的复杂度,提高模型的可解释性和泛化能力,降低过拟合的风险。
通过观察不同预测变量集合上的误差,我们还可以了解到不同预测变量之间的相关性和重要性。这有助于我们深入理解数据和问题领域,并为进一步的特征工程提供指导。
综上所述,查看不同回归模型在各个预测变量集合上的误差可以帮助我们优化模型、选择关键的预测变量,并提高回归模型的性能和可解释性。


















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











