







目录
Urllib
一、Url组成
http www.baidu.com 80/443 s ed=zhoou
协议 主机 端口号 路径 参数瞄点
二、Response知识点
response = urllib.request.urlopen(‘http://www.baidu.com’)
-
一个类型六个方法
一个类型:HTTPRequest
六个方法:
read()--------以字节读取
readline()---读取一行
readlines()
getcode()---返回状态码200无误
geturl()
getheaders()-状态信息
三、反爬
-
1.UA反爬
-
2.header中加入cookie反爬信息
referer用来做防盗链,判断当前路径是否由上一个链接进入,一般图片
-
3.常用反爬手段
登陆界面,爬取个人信息(utf-8)时报编码错,是因为爬取时返回到登陆界面(GB2312)
加载图片时,懒加载,图片标签有data-original的就不要看src了,直接用data-original
四、解析
1.Xpath解析
-
1.xpath 基本语法
/子 //子孙
html_tree.xpath('// /')
html_tree.xpath('//body//ul[@id=""]')
查标签中内容
html_tree.xpath('//body//ul[@id=""]/text()')
查询id中包含l的标签
html_tree('//ul/li[contains(@id,"l")]/text()')
以l开头的标签
html_tree('//ul/li[starts-with(@id,"l")]/text()')
-
2.XPath分类
本地文件
tree = etree.parse('xxxx.html')服务器响应文件
context=response.read().decode()
html_tree=etree.HTML(context)2.JsonPath解析
-
参考案例
import json
import jsonpath
file = json.load(open('shgjh.json','r',encoding='utf-8'))
jsonpath.jsonpath(file,'$.story..price')
最后一本书:
'$..book[@.length-1]'
选择所有价格大于10元的书籍
#条件过滤前面要加一个?
'$..book[?(@.price>10)]'五、编解码
-
1.get请求方式:
Urllib.parse.quote(‘’) 单参数
Urllib.parse.urlencode(‘’) 多参数
data={
'wd':'zhoujielun',
'sex':'man',
'location':'china Taiwan'
}
all=urllib.parse.urlencode(data)-
2.post请求方式:
- Post请求的参数必须编码
all=urllib.parse.urlencode(data).encode(‘utf-8’)
post请求的参数是不会拼接在url的后面的,作为data一个整体,用在urllib.request.Request(url,data,header)
-
3.Get和post请求方式的区别:
Get请求不需要编码,只有post请求需要编码
Get请求需要url的拼接,post请求不需要url的拼接
六、异常:URLError\HTTPError(了解)
HTTPError是URLError的子类
Try...except进行捕获异常
七、Headerler处理器
-
1.应用于:
动态cookie、代理Request
Proxies={ ‘http’:’121.230.211.142:2356’’}
-
2.代理池:
import random
(request已经写出)
#代理池:
posix_pool=[
{'http':'60.170.204.30:8060'},
{'http':'60.170.204.30:8061'},
{'http':'60.170.204.30:8062'}
]
#代理
posix=random.choice(posix_pool)
hander=urllib.request.HTTPHandler()/ProxyHandler(proxies=proxies)
opner=urllib.request.build_opener(hander)
response=opner.open(request)八、下载
-
1.图片,音频
Urllib.request.urlretrieve(url,’name’)请求里面的url链接中写的是接口链接
-
2.json文件
with open('json文件名字.json','w',encoding='utf-8') as fp:
fp.write(context)时间,名,值
爬虫+存入数据库,最近两个小时,一个小时更新一次
Pymysql、Pandas、Sklearn、Numpy
九、Selenium
-
1.简单介绍
一个用于web应用程序测试的工具,像用户真正访问一样,支持无界浏览器
当浏览器不给我们某些数据时即可使用 Selenium
request
response = requests.get(‘http://www.baidu.com’)
一、Response知识点
-
一个类型六个属性
一个类型:response
六个方法:
encoding---设置相应编码格式
text---字符串的形式返回网页源码
url---返回地址
contend---返回二进制数据
status_code、headers
getheaders()---状态信息
二、与urllib的区别
请求方式的区别
| request | |
| get | requests.get()/请求参数是params |
| post | requests.post()/请求参数是data |
三、案例之:requests_cookie登录古诗网
- 需求:跳过验证登录故事网
- 代码:
# 请求网址:https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx
# 请求方法:POST
# User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36
import requests
# 接口判断方法:登陆失败不跳转页面
# 表单数据
# type="hidden"--隐形用户不可见,而大部分用户不可见的为可变内容
# 爬取时可变数据:_VIEWSTATE、__VIEWSTATEGENERATOR、code
# 获取网页url
all_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
all_response = requests.get(url=all_url,headers=headers)
all_content = all_response.text
# 解析请求
from bs4 import BeautifulSoup
soup = BeautifulSoup(all_content,'lxml')
VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# print(type(VIEWSTATE))
# 验证码
# 首先保存验证码
src = soup.select('#imgCode')[0].attrs.get('src')
# print(src)
text_url = 'https://so.gushiwen.cn' + src
# print(text_url)
# 误区:这里不能使用urllib的方式存图,因为会访问两次导致验证码刷新
# 解决办法:通过session把请求变成一个对象
session = requests.session()
response_ma = session.get(text_url)
# 存图只能用二进制的方式
contend_ma = response_ma.content
# wb-将图片以二进制的方式写入文件
with open('yanzhengma.jpg','wb') as fp:
fp.write(contend_ma)
yanzhengma = input("请输入验证码")
#这里一般不手动输入验证码,而是通过一些平台破解验证码,如‘超级鹰’
url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE':VIEWSTATE,
'__VIEWSTATEGENERATOR':VIEWSTATEGENERATOR,
'from: http':'//so.gushiwen.cn/user/collect.aspx',
'email':' 1485676249@qq.com',
'pwd':' 863096',
'code':yanzhengma
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
response = session.post(url=url,data=data,headers=headers)
content = response.text
with open('login.html','w',encoding='utf-8') as fp:
fp.write(content)
scrapy
-
一、基本了解
是什么:
爬取、提取结构性数据的框架
用途:
数据挖掘、信息处理、存储历史数据
基本使用:
在win终端运行代码:
#创建爬虫项目
scrapy startproject baidu_spider
#创建爬虫文件
cd xx\baidu_spider\baidu_spider\spiders
scrapy genspider baidu
#运行爬虫
scrary crawl baidu.pyresponse部分属性:
text\body\xpath\extract()\extract_first()
contend = response.text
# 以二进制输出源代码
contend = response.body
# xpath解析response的内容
contend = response.xpath('//span/input[@id="su"]/@value')
# 提取seletor中data属性值
contend.extract()
# 取seletor列表第一个数据
contend.extract_first()
print(contend)-
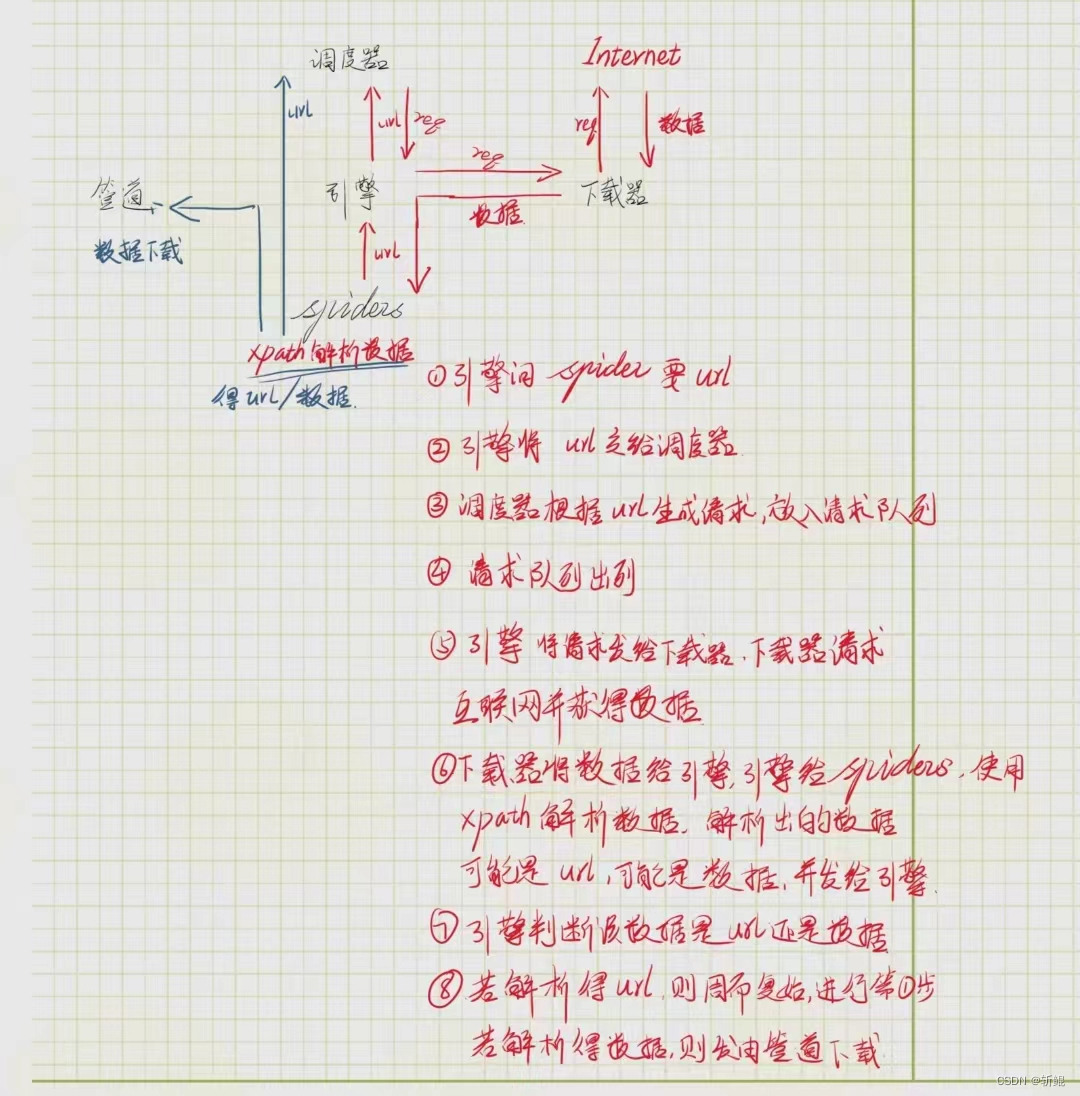
二、scrapy架构
工作原理
(如图)
案例分析【汽车之家】
需求:爬取汽车之家的汽车产品和产品价格
需求分析:
- 分别获取car 的名字和价格(此时获取的是列表)
- for循环拆开列表,用extract() 分开取值
代码如下:
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["car.autohome.com.cn"]
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
# print('=========================================')
car_name = response.xpath('//a[@class="font-bold"]/text()')
# 输出车名列表
# print(car_name)
car_price = response.xpath('//span[@class="font-arial"]/text()')
for i in range(len(car_name)):
car = car_name[i].extract()
price = car_price[i].extract()
print(i,car,price)一些快捷键
-
pycharm
| tab | 向前缩进 |
| shift + tab | 向后缩进 |
| ctrl + L | 控制区--搜索 |
| ctrl + R | 正则匹配 |
| ctrl + alt + L | 格式化 |
-
网页
| ctrl + f | 搜索 |















 4984
4984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









