







目录
什么是正则表达式
百科理解:
- 正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
- 是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
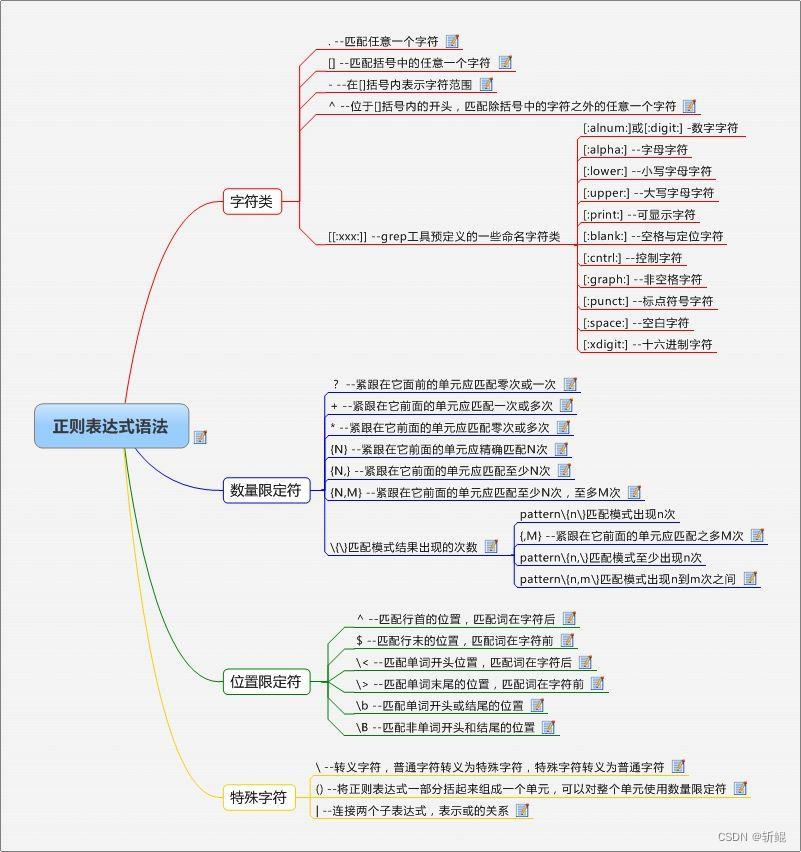
正则表达式匹配规则
🎈易混淆语法:
* ⌛ +
?⌛{n}⌛{n,}⌛{n,m}
[xyz]⌛[^xyz] / [a-z]⌛[^a-z]
\b⌛\B
\s⌛\S
\w⌛\W
🎈常用符号
| 元字符 | 描述 |
| r'正则' | r 表示字符串为非转义的原始字符串 |
| \ | 转义符,如:“\\n”匹配\n,“\n”匹配换行符;“\\”匹配“\”,“\(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| * | 匹配前面的子表达式任意次。如:zo*能匹配“z”,“zo”,“zoo”……*等价于o{0,} |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”,“zoo”。不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”,“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在","和两个数之间不能有空格。 |
| . | 匹配除换行符(\r\n)之外的任何单个字符。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。 |
| \r | 匹配一个回车符。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。 |
| \S | 匹配任何可见字符。 |
| \t | 匹配一个制表符。 |
| \<\> | 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
🎈不常用符号
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \w | 匹配包括下划线的任何单词字符。 |
| \W | 匹配任何非单词字符。 |
🎈分类
贪婪模式和非贪婪模式
字如其名,贪婪模式是“什么都要,不挑”,即把所有可以匹配到的都匹配到;相反,非贪婪模式是“点到为止”,即只匹配能匹配到的第一个
默认贪婪模式,加了?才是非贪婪模式
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多的匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少的匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
python中正则表达式的使用
re模块
🎈re.match()
import re
match_obj = re.match(pattern, string, flags=0)
# pattern:匹配的正则表达式
# string:你要匹配的字符串
#flag:标志位
#匹配成功 re.match 返回一个匹配的对象,否则返回 None
| flag | 描述 |
| re.I | 匹配对大小写不敏感 |
| re.M | 多行匹配 |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.X | 增加可读性,忽略空格和注释 |
可以通过使用group()来提取()里的元组,举栗如下:
import re
match_obj = re.match('(.*) and (.*?) .*','apple and orange reading books',re.M|re.I)
print("match_obj.group():" + match_obj.group())
print("match_obj.group(0):" + match_obj.group(0))
print("match_obj.group(1):" + match_obj.group(1))
print("match_obj.group(2):" + match_obj.group(2))
line = "Cats are smarter than dogs"结果如下:
C:\Users\Administrator\AppData\Local\Programs\Python\Python39\python.exe F:\crawling\text.py
match_obj.group():apple and orange reading books
match_obj.group(0):apple and orange reading books
match_obj.group(1):apple
match_obj.group(2):orange这里需注意:没有()会报如下错,此时就应该检查一下你的正则表达式啦!!!!!
AttributeError: 'NoneType' object has no attribute 'groups'🎈re.search()
返回第一个成功的匹配,否则返回none (类似于非贪婪模式)
re.search(pattern, string, flags=0)🎈search()和match()的区别
- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None
- re.search匹配整个字符串,直到找到一个匹配。
举个栗子:
import re
#span() 返回一个元组包含匹配 (开始,结束) 的位置
match_obj1 = re.match('apple','apple and orange reading books',re.M|re.I).span()
match_obj2 = re.match('reading','apple and orange reading books',re.M|re.I)
print("match_obj1:",match_obj1)
print("match_obj2:",match_obj2)
search_obj1 = re.search('apple','apple and orange reading books',re.M|re.I).span()
search_obj2 = re.search('reading','apple and orange reading books',re.M|re.I).span()
print("search_obj1:",search_obj1)
print("search_obj2:",search_obj2)运行结果:
match_obj1: (0, 5)
match_obj2: None
search_obj1: (0, 5)
search_obj2: (17, 24)🎈findall()
- 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表。
- 如果有多个匹配模式,则返回元组列表;如果没有找到匹配的,则返回空列表。
-
patten.findall(string,pos,endpos)
string 要匹配的字符串 pos 匹配字符串的起始位置 endpos 匹配字符串的终止位置(包头不包尾)
🧨🧨🧨这里和match()和search()区分开
findall()是匹配所有
match()和search()匹配一次,其中match()是匹配一次字符串开始,而search是匹配整个字符串,范围不局限于开始
举个栗子:
patten = re.compile(r'a')
c = patten.findall("Cats are smarter than dogs",1,10)
print(len(c))结果:2
🎈re.compile()
- 返回 RegexObject 对象。
- 用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
re.compile('正则表达式',flags)举个栗子:
patten = re.compile(r'ts')
a = patten.match("Cats are smarter than dogs",1,4)
print(a)
patten = re.compile(r'ts')
b = patten.match("Cats are smarter than dogs",2,4)
print(b)结果如下:
None
<re.Match object; span=(2, 4), match='ts'>🎈re.sub
- 功能:替换
- re.sub(pattern, repl, string, count=0, flags=0)
| patten | 正则匹配模式 |
| repl | 函数/值,要被替换的样式 |
| string | 即将被替换的字符串 |
| count | 替换的次数,默认为0表示全局替换 |
new_string = re.sub(r'Cats','human','Cats are smarter than dogs')
print(new_string)结果:
C:\Users\Administrator\AppData\Local\Programs\Python\Python39\python.exe F:\crawling\text.py
human are smarter than dogs














 5581
5581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









