








这篇文章是我在保研过程中自己耗尽心血搜集总结的专业课面试问题,几乎涵盖了电子信息专业的所有专业课。我凭借这个复习,保研过程都比较顺利,我在参加复旦、自所和清华的面试中都有被问到过当中的题目,参考价值非常大,相信在保研过程中会祝大家一臂之力!
高等数学
凹凸函数
这意味着函数的图像位于任意两点连线的下方。数学上,如果函数的二阶导数(如果存在)在整个定义域内都非负,即 二阶导大于等于0,那么该函数也是凹函数。
这意味着函数的图像位于任意两点连线的上方。数学上,如果函数的二阶导数(如果存在)在整个定义域内都非正,即 二阶导小于等于0,那么该函数是凸函数。
凸函数(Convex Function)
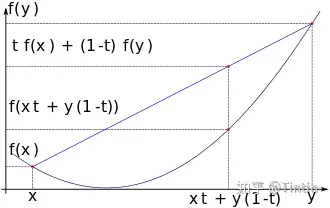
图4 凸函数
当 t∈[0,1]t\in [0,1] ,定义域上任意两点 x,yx,y 都满足f(tx+(1−t)y)≤tf(x)+(1−t)f(y)f(tx+(1-t)y)\leq tf(x)+(1-t)f(y)\\
这个公式意思就是:函数上任意两点连线在该函数上方。或者也可以这样解释:任意一点的切线在该函数下方。
注:上方和下方主要针对图4而言; 还有一点是这里的凸不是指高等数学里的凸凹,假如上图对应 f(x)=x2f(x)=x^2 ,而 −x2-x^2 依旧是凸函数,把图4翻转一下,公式换成大于等于号依旧满足。那么什么是非凸函数?
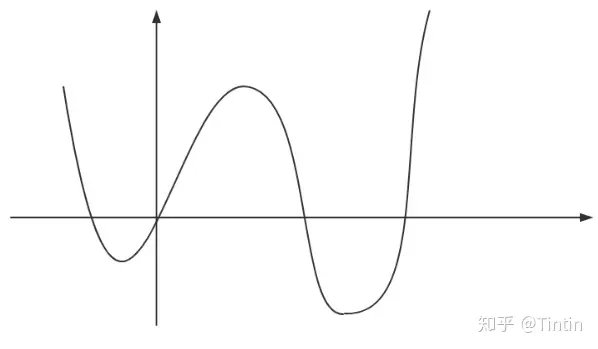
图5 非凸函数
如图5,取两点连线不满足都在函数的上方或下方。
以上解释为了便于理解,更严谨的方式应该从凸集开始介绍,废话太多不写。然后记住凸函数的几个性质:
· 有全局最优解。如图5神经网络优化的过程中很可能陷入左边的局部最优解,而实际最优解在右边,神经网络很多层实际是一个高度复杂的非凸函数,这也是为什么神经网络需要用SGD的原因,SGD的随机性可以使得它逃出局部最小,逃离鞍点。总之,凸函数就没有这些问题,它只有一个最优解。
· 一阶导只存在一个零点。根据上一条只有一个极值。
· 二阶导正定。一般在求解过程中都是用矩阵表示,也叫Hessian矩阵。为什么神经网络不用牛顿法?因为Hessian矩阵的逆不好计算。
拉格朗日中值定理
拉格朗日中值定理的直观含义是:在闭区间上连续并在开区间上可导的函数,必然存在一个点使得其瞬时变化率等于其平均变化率。
极限的定义
如果函数f(x)当x无限接近于某一特定值a时,其输出值趋于某一固定值L,则称函数f(x)在x趋于a时的极限为L。
导数的定义
导数的定义:导数就是在某点的瞬时变化率。
可导的充要条件:1、连续 2、左导数与右导数存在且相等。
微分的概念
微分描述的是当自变量发生微小变化时,函数值的变化量。
连续和一致连续的区别
函数连续是指在某点的极限等于函数值。F(x)在x0点连续,x0是固定的,而一致连续是函数在区间上的性质,要求在一段区间上均连续。
微分中值定理
微分中值定理包括拉格朗日中值定理和柯西中值定理。
罗尔中值定理:如果一个函数在区间的两端取相同的值,那么在该区间内部至少有一点的导数为零。这个点被称为函数的“驻点”,即函数在这一点的斜率为零。
二次积分和二重积分的区别与联系
二重积分是二元函数在二维区域的积分,通常用来计算三维空间的体积。
二次积分相当于是一元函数做了两次一次积分,是在一维区域上的积分。
联系:求解二重积分时通常是将积分区间投影到一维,将二重积分转化为二次积分计算。
黎曼积分
一段闭区域上的积分近似于将区间分割成n段,分割点的函数值乘以分割区间长度再累计求和。
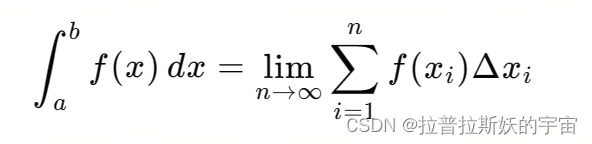
牛顿莱布尼兹公式
把定积分计算转化成不定积分。一个函数在某个区间上的定积分等于它的一个原函数在该区间上限和下限的差值。
梯度散度旋度
梯度是一个向量场,表示一个标量场(即一个只依赖于空间位置的量)在某一点处的最大变化率以及变化的方向。如果有一个标量场 𝑓(𝑥,𝑦,𝑧)f(x,y,z),它的梯度 ∇𝑓 定义为: ∇𝑓=(∂𝑓∂𝑥,∂𝑓∂𝑦,∂𝑓∂𝑧)梯度的方向是标量场增长最快的方向,其大小是该方向上的最大变化率。
散度是一个标量场,表示一个向量场在某一点处的发散程度。如果有一个向量场 𝐹(𝑥,𝑦,𝑧)=(𝐹𝑥,𝐹𝑦,𝐹𝑧)F(x,y,z)=(Fx,Fy,Fz),它的散度 ∇⋅𝐹∇⋅F 定义为: ∇⋅𝐹=∂𝐹𝑥∂𝑥+∂𝐹𝑦∂𝑦+∂𝐹𝑧∂𝑧∇⋅F=∂x∂Fx+∂y∂Fy+∂z∂Fz 散度可以解释为在该点单位体积内的净流量。如果散度为正,表示场在该点向外发散;如果为负,则表示向内汇聚。
旋度是一个向量场,表示一个向量场在某一点处的旋转趋势。旋度 ∇×F 定义为: ∇×𝐹=(∂𝐹𝑧∂𝑦−∂𝐹𝑦∂𝑧,∂𝐹𝑥∂𝑧−∂𝐹𝑧∂𝑥,∂𝐹𝑦∂𝑥−∂𝐹𝑥∂𝑦)∇×F=(∂y∂Fz−∂z∂Fy,∂z∂Fx−∂x∂Fz,∂x∂Fy−∂y∂Fx) 旋度的方向垂直于旋转平面,其大小是单位面积上的最大旋转速率。如果旋度为零,表示该点的向量场没有旋转。
三个微分中值定理的区别与联系
罗尔中值定理、拉格朗日中值定理、柯西中值定理
罗尔中值定理关注导数为0的情况,是拉格朗日中值定理的特例,要求在区间端点值相同。
柯西中值定理是拉格朗日中值定理的推广,适用于两个函数的情况。
格林公式
格林公式的表述:
设有一个简单闭曲线 C 与一个平面区域 D,曲线 𝐶C 按照逆时针方向定义边界 ∂𝐷∂D。如果向量场 𝐹F 在 𝐷D 上具有连续的一阶偏导数,那么格林公式可以表述为:
∮𝐹⋅𝑑𝑟=∬(∇×F)⋅dS
这里:
- ∮𝐶 表示沿着曲线 𝐶 的线积分。
- 𝐹⋅𝑑𝑟 是向量场 𝐹 与微小向量元素 𝑑𝑟 的点积。
- ∬𝐷 表示在区域 𝐷 上的二重积分。
- ∇×𝐹 是向量场 𝐹 的旋度(curl)。
- 𝑑𝑆 是在区域 𝐷 上的微小面元素,通常指向外部。
格林公式的分量形式:
如果向量场 𝐹F 可以表示为 𝐹=(𝑀(𝑥,𝑦),𝑁(𝑥,𝑦))F=(M(x,y),N(x,y)),那么格林公式可以写成分量形式:
∮𝐶(𝑀𝑑𝑥+𝑁𝑑𝑦)=∬𝐷(∂𝑁∂𝑥−∂𝑀∂𝑦)𝑑𝐴
高斯公式
对于一个体积 𝑉在 𝑅3 中,它的边界表面是 𝑆,𝑆的外法向量场为 𝑛。如果 𝐹 是一个向量场,那么高斯散度定理可以表述为:
∫∇⋅𝐹 𝑑𝑉=∫𝐹⋅𝑑𝑆
这里:
- ∇⋅𝐹 是向量场 𝐹F 的散度(divergence),即流体流动的体积变化率。
- ∫𝑉 表示对体积 𝑉V 进行积分。
- ∫𝑆 表示对曲面 𝑆S 进行积分。
- ⋅表示点积。
高斯散度定理的几何意义:
定理表明,通过一个闭合曲面的向量场的流量(即曲面积分部分)等于该曲面包围的体积内散度的总和。这可以用来计算流体的流动、电场和磁场的通量等问题。
向量范数
常见的向量范数包括:
-
𝐿1 范数(曼哈顿范数): ∥𝑥∥1=∑𝑖=1𝑛∣𝑥𝑖∣∥x∥1=∑i=1n∣xi∣ 它表示向量所有元素绝对值的和。
-
𝐿2范数(欧几里得范数): ∥𝑥∥2=∑𝑖=1𝑛𝑥𝑖2∥x∥2=∑i=1nxi2 它是向量元素平方和的平方根,也是我们通常所说的欧几里得距离。
-
𝐿∞ 范数(最大范数): ∥𝑥∥∞=max(∣𝑥1∣,∣𝑥2∣,…,∣𝑥𝑛∣)∥x∥∞=max(∣x1∣,∣x2∣,…,∣xn∣) 它是向量所有元素绝对值的最大值。
-
p-范数: ∥𝑥∥𝑝=∑𝑖=1𝑛∣𝑥𝑖∣𝑝𝑝∥x∥p=p∑i=1n∣xi∣p 当 𝑝p 取不同的值时,𝑝p-范数有不同的形式,𝐿1L1 和 𝐿2L2 范数是 𝑝p-范数的特例。
-
Frobenius 范数: 对于矩阵 𝐴A,Frobenius 范数定义为: ∥𝐴∥𝐹=∑𝑖=1𝑚∑𝑗=1𝑛𝑎𝑖𝑗2∥A∥F=∑i=1m∑j=1naij2 它是矩阵元素平方和的平方根。
线性代数
矩阵是空间变换
矩阵乘法不具备交换性,比如将一个图形先旋转后拉伸和先拉伸后旋转得到的结果是不一样的。
行列式是什么
行列式是矩阵变换后的放大率。
行列式为负表示图形发生了翻折。行列式为0表示变换后图形发生了降维。(矩阵不可逆)
矩阵的秩是什么
矩阵的秩是矩阵中线性无关的行或列的数量。(行秩列秩)
本质是矩阵空间变换后的维度、矩阵列向量所张成空间的维度(基向量的个数)。
求解方法是将矩阵化为行阶梯形式,非零行的个数。
线性方程组解的条件
① 无解:系数矩阵秩 < 增广矩阵的秩
② 唯一解:系数矩阵秩 = 增广矩阵的秩 = 列数 𝑛
③ 无穷解:系数矩阵秩 = 增广矩阵的秩 < 列数 𝑛
矩阵的迹
矩阵的迹是矩阵对角线元素之和。
施密特正交化
施密特正交化是将非正交基转化为正交基。
标准正交基:两个正交的向量,且长度为1.
Jordan标准型
Jordan标准型是一种特殊的矩阵形式,用于简化对线性算子的研究。它由一系列称为Jordan块的较小矩阵组成,每个Jordan块位于矩阵的对角线上,其特点是:
- 对角线上的元素是相同的特征值。
- 超对角线上的元素是1(即从左上到右下的对角线)。
- 其它位置的元素是0。
一个 𝑛×𝑛 矩阵 𝐴A 被称为Jordan矩阵,如果它满足以下形式:
𝐽=(𝐽10⋯00𝐽2⋯0⋮⋮⋱⋮00⋯𝐽𝑘)J=J10⋮00J2⋮0⋯⋯⋱⋯00⋮Jk
其中,每个 𝐽𝑖 是形如:
𝐽𝑖=(𝜆𝑖10⋯00𝜆𝑖1⋯0⋮⋮⋮⋱⋮000⋯𝜆𝑖)Ji=λi0⋮01λi⋮001⋮0⋯⋯⋱⋯00⋮λi
正定矩阵
一个n阶实对称矩阵A被称为正定矩阵,如果对于任意非零向量X,都有X^TAX > 0。
-
在凸优化中,正定矩阵可以保证函数的二阶导数是正定的,从而确保函数的局部极小值就是全局最小值。
- 如果一个矩阵的所有特征值都是正数,那么这个矩阵是正定的。
如果对于实对称矩阵 𝐴 ,若其为正定矩阵,则表示它对于任意一个非零向量的线性变换前后夹角 𝜃<90∘ 。
如果对于实对称矩阵 𝐴 ,若其为半正定矩阵,则表示它对于任意一个非零向量的线性变换前后夹角 𝜃≤90∘ 。
线性空间
线性空间是一个集合,其中的向量满足加法和标量乘法。向量空间中有一组基向量,所有向量都可以表示为基向量的线性组合。
全等变换
变换前后对象性质完全相同,仅位置、方向或尺度发生变化,而不改变其形状和结构。 例如:平移、旋转、镜像、缩放
特征值与特征向量
, x为特征向量,lamda为特征值
特征向量是做空间变换后方向不发生改变的向量,特征值为伸缩倍率。
过程:
- 求解特征值:通过求解特征多项式 det(𝐴−𝜆𝐼)=0det(A−λI)=0 来找到矩阵 𝐴A 的特征值。
- 求解特征向量:对于每个特征值 𝜆λ,求解线性方程组 (𝐴−𝜆𝐼)𝑣=0(A−λI)v=0 来找到对应的特征向量。
特征值为复数意味着矩阵所对应的变换是旋转变换。
特征空间是由相同特征值的特征向量组成的子空间。
实对称矩阵一定有n个线性独立特征向量,并可以进行特征分解
。
不恰当的例子,对物体进行受力分析,各个方向上力合成最后的力。特征值分解就好比是对最终的力分解成各个方向上的力,特征向量表示力的方向,特征值表示各方向力的大小。
特征值分解针对方针,SVD可以对非方阵进行分解。
奇异值分解(SVD)
只有方阵可以进行特征分解。对于一般的矩阵,可以用奇异值分解进行分解。一个一般的矩阵可以被分解成这样:
(把各个矩阵的维度标出来的话就是 )
对于任意一个𝑚×𝑛的矩阵 𝐴A,SVD可以将矩阵 𝐴A 分解为三个特定的矩阵的乘积,形式如下:
𝐴=𝑈Σ𝑉𝑇A=UΣVT
其中:
- 𝑈 是一个 𝑚×𝑚 的正交矩阵,其列被称为左奇异向量。
- Σ 是一个 𝑚×𝑛 的对角矩阵,对角线上的非负实数被称为奇异值,并且按降序排列。这些奇异值反映了矩阵 𝐴 在各个方向上的拉伸或压缩程度。
- 𝑉 是一个 𝑛×𝑛 的正交矩阵,其列被称为右奇异向量。
- 𝑉𝑇 是 𝑉 的转置矩阵。
实现数据降维,像PCA
- 数据降维(如主成分分析PCA)。
- 信号处理和图像压缩。
- 求解线性方程组和矩阵求逆。
正交矩阵
正交矩阵是一种特殊的方阵,其行向量和列向量都是正交的,并且每个向量都是单位向量。这意味着正交矩阵的列向量(或行向量)构成了一个正交基。具体来说,如果一个𝑛×𝑛n×n的矩阵 𝑄Q 是正交的,那么它满足以下条件:
𝑄𝑇𝑄=𝑄𝑄𝑇=𝐼QTQ=QQT=I
其中:
- 𝑄𝑇是矩阵 𝑄的转置。
- 𝐼 是单位矩阵,即对角线上的元素都是1,其余元素都是0的方阵。
正交矩阵的属性包括:
- 保持长度不变:正交矩阵可以将向量旋转而不改变其长度。如果 𝑣 是一个向量,那么 𝑄𝑣 与 𝑣 具有相同的长度。
- 保持角度不变:正交矩阵保持向量之间的夹角不变。如果 𝑢 和 𝑣 是两个向量,那么 𝑢𝑇𝑣 等于 (𝑄𝑢)𝑇(𝑄𝑣)(Qu)T(Qv)。
- 行列式的绝对值为1:正交矩阵的行列式 det(𝑄)det(Q) 要么是1,要么是-1。如果 det(𝑄)=1det(Q)=1,那么 𝑄是一个特殊正交矩阵;如果 det(𝑄)=−1det(Q)=−1,那么 𝑄 是一个反射矩阵。
正交变换指的是一种保持向量间距离和角度不变的线性变换。在几何上,这意味着正交变换不会改变任何两点之间的距离,也不会改变向量之间的夹角。例如空间中的旋转。
合同矩阵
,则A与B合同。
- 合同的意义:两矩阵合同,说明两矩阵是同一二次型在不同基上的对称矩阵
- 合同矩阵的正负惯性指数一样
- 矩阵相似则必定合同(特征值相同,特征值符号相同,正负惯性指数也相同)
相似矩阵
,则A与B相似,两矩阵是同一线性变换在不同基上的矩阵。
相似矩阵特征值相同。
逆矩阵
逆矩阵是线性代数中的一个重要概念,指的是一个方阵(行数和列数相等的矩阵)的逆,如果存在的话。给定一个 𝑛×𝑛 的矩阵 𝐴A,如果存在一个矩阵 𝐵 使得:
𝐴𝐵=𝐵𝐴=𝐼AB=BA=I
其中 𝐼I 是 𝑛×𝑛 的单位矩阵,那么矩阵 𝐵 就被称为矩阵 𝐴 的逆矩阵,记作 𝐴−1。
逆矩阵的关键特性包括:
- 唯一性:如果一个矩阵有逆矩阵,那么这个逆矩阵是唯一的。
- 单位矩阵:单位矩阵的逆矩阵是它自己,即 𝐼−1=𝐼I−1=I。
- 转置的逆:如果 𝐴A 的逆矩阵是 𝐵B,那么 𝐴A 的转置的逆是 𝐵B 的转置,即 (𝐴𝑇)−1=(𝐴−1)𝑇(AT)−1=(A−1)T。
- 行列式:如果矩阵 𝐴A 是可逆的,那么它的逆矩阵的行列式是 𝐴A 行列式的倒数,即 det(𝐴−1)=1det(𝐴)det(A−1)=det(A)1。
- 线性方程组:逆矩阵可以用于解线性方程组 𝐴𝑥=𝑏Ax=b,解为 𝑥=𝐴−1𝑏x=A−1b。
逆矩阵的求法:
求逆矩阵的过程通常包括以下步骤:
- 计算行列式:首先计算矩阵 𝐴A 的行列式,如果行列式为零,则 𝐴A 没有逆矩阵。
- 求伴随矩阵:将矩阵 𝐴A 的每个元素替换为它的代数余子式,然后转置得到伴随矩阵(Adjugate matrix)。
- 乘以行列式的倒数:将伴随矩阵的每个元素乘以 𝐴A 行列式的倒数,得到逆矩阵 𝐴−1A−1。
注意:
不是所有的矩阵都有逆矩阵。如果一个矩阵的行列式为零,那么它就没有逆矩阵,这样的矩阵被称为奇异矩阵(Singular matrix)。只有行列式不为零的矩阵才是可逆的,满秩,也称为非奇异矩阵(Non-singular matrix)。
伪逆
Pseudo Inverse,即伪逆,是线性代数中的一个概念,用于描述那些不满足逆矩阵存在条件的矩阵的“逆”。对于一个矩阵,如果它不是方阵或者它的行列式为零(即奇异矩阵),那么它没有常规意义上的逆矩阵。然而,伪逆提供了一种扩展逆矩阵概念的方法。
定义:
对于一个 𝑚×𝑛 的矩阵 𝐴,如果存在一个 𝑛×𝑚 的矩阵 𝐵,使得: 𝐴𝐵𝐴=𝐴 𝐵𝐴𝐵=𝐵 (𝐴𝐵)𝑇=𝐴𝑇𝐵𝑇(AB)T=ATBT (𝐵𝐴)𝑇=𝐵𝑇𝐴𝑇(BA)T=BTAT 那么矩阵 𝐵B 被称为矩阵 𝐴A 的伪逆,记作 𝐴+A+
矩阵的微分
矩阵的微分是一个在多变量微积分和线性代数中使用的概念,它扩展了标量函数的微分概念。在最简单的形式中,矩阵的微分涉及到矩阵元素相对于其他变量的变化率。
概率论与数理统计
什么是概率密度函数及其性质
概率密度函数用于计算随机变量在某个区间上分布的概率。
在某段区间上的积分表示在这段区间发生的概率。
性质:非负性、累计积分为1
边缘概率分布与联合概率分布
边缘概率分布是指多维随机变量中某一个或几个随机变量的概率分布。当我们考虑一个多维随机变量的联合概率分布时,如果只关注其中的某一个或几个随机变量的概率分布,那么这些被关注的随机变量的概率分布就是它们的边缘概率分布。
大数定律
当随机变量发生的次数n趋于无穷大时,随机变量的均值会依概率收敛于期望。
伯努利大数定律:频率依概率收敛于概率。
切比雪夫不等式
它提供了一个随机变量偏离其期望值的概率的上限估计。
中心极限定理
独立同分布随机变量的和或均值在样本数量足够大时,近似服从正态分布。
- 棣莫弗-拉普拉斯(De Moivre-Laplace)定理:可以用二项分布逼近正态分布。随机变量𝑋∼𝑏(𝑛,𝑝),当𝑛足够大时,𝑋∼𝑁(𝑛𝑝,𝑛𝑝(1−𝑝))
正态分布的概率密度函数具有如下形式:
其中:
- 𝑥x 是随机变量。
- 𝜇μ 是分布的均值(期望值)。
- 𝜎σ 是分布的标准差。
- 𝜎2σ2 是方差。
概率论与数理统计的关系
概率论主要研究随机现象及其规律。概率论为数理统计提供了理论基础。
数理统计则应用概率论的原理来分析和解释数据。它利用统计方法根据样本数据对总体进行推断和结论。
贝叶斯公式
P(A∣B)=P(B∣A)⋅P(A)/P(B)
- 𝑃(𝐴∣𝐵):在证据B出现后,A发生的概率。这就像是在发现新线索后,你认为嫌疑人有罪的可能性。
- 𝑃(𝐵∣𝐴):如果A真的发生了,那么证据B出现的概率。这就像是如果嫌疑人真的有罪,那么发现这个线索的可能性。
- 𝑃(𝐴):A发生的概率,也就是在没有新线索之前,你认为嫌疑人有罪的可能性。
- 𝑃(𝐵):证据B出现的概率,不管A是否发生。
贝叶斯公式的美妙之处在于,它允许你不断地根据新的证据来调整你对事件的看法。
无偏估计
无偏估计(Unbiased Estimator)是统计学中的一个概念,指的是一个估计量(estimator)的期望值(expected value)或平均值与被估计的参数的真实值(parameter's true value)相等。换句话说,如果一个估计量的期望值恰好等于被估计的总体参数,那么这个估计量就被称为无偏的。
对于一个参数 𝜃,如果存在一个估计量 𝜃^,使得: 𝐸[𝜃^]=θ 那么我们就说 𝜃^是 𝜃的无偏估计。
方差
- 对于常数𝐶,有𝐷(𝐶𝑋)=𝐶2𝐷(𝑋),𝐷(𝑋+𝐶)=𝐷(𝑋)
- 𝐷(𝑋+𝑌)=𝐷(𝑋)+𝐷(𝑌)+2𝐸{[𝑋−𝐸(𝑋)][𝑌−𝐸(𝑌)]}
- 协方差Cov(𝑋,𝑌)=𝐸{[𝑋−𝐸(𝑋)][𝑌−𝐸(𝑌)]}
- 相关系数
- 相关系数为0说明:
- 两变量不相关
- Cov(𝑋,𝑌)=0
- 𝐸(𝑋𝑌)=𝐸(𝑋)𝐸(𝑌)
- 𝐷(𝑋+𝑌)=𝐷(𝑋)+𝐷(𝑌)
- 独立说明两变量不相关,但是不相关不能说明两变量独立。不相关只能说明没有线性关系,独立说明两随机变量没有任何关系
似然函数
- 最大似然估计:似然函数为𝐿(𝜃)=∏𝑖=1𝑛𝑝(𝑥𝑖;𝜃)(离散型);𝐿(𝜃)=∏𝑖=1𝑛𝑓(𝑥𝑖;𝜃)(连续型)。我们需要找到使似然函数最大的参数,即:𝜃^=argmax𝜃𝐿(𝜃)
各种分布
- 指数分布 常用于描述独立随机事件发生的时间间隔。
- 均匀分布 用于描述在某个区间内所有值同等可能的情况。
- 泊松分布 用于模拟在固定时间或空间内发生稀有事件的次数。
- 二项分布 用于描述固定次数的独立实验中成功的次数,其中每次实验的成功概率相同。
马尔科夫性质
Markov性,通常称为马尔可夫性质,是数学和统计学中的一个概念,特别是在概率论和随机过程中。它描述了一个系统的未来状态只依赖于当前状态,而与之前的历史状态无关的性质。
Type I Error
当我们进行假设检验并得出结论时,有两种可能的错误:
- Type I Error:拒绝了正确的零假设,也就是说,我们错误地得出了两组之间有差异的结论,而实际上并没有差异。
- Type II Error:未能拒绝错误的零假设,也就是说,我们错误地得出了两组之间没有差异的结论,而实际上存在差异。
复变函数
解析函数
一个函数如果在某区间内的每一点都可导,那么我们就说这个函数在该区间内是解析的。解析函数的例子包括多项式函数、指数函数、对数函数、三角函数等。这些函数不仅在某一点可导,而且在其整个定义域内的每一点都可导。
解析:函数在某点处解析指函数在该点极其领邻域内处处可导。
奇点:未定义的点。如 𝑓(𝑥)=1𝑥 的极点为0。
柯西-黎曼方程(C-R方程)
是复分析中一组基础方程,它们与复函数的可微性紧密相关。对于复平面上的点 𝑧=𝑥+𝑖𝑦,其中 𝑥 和 𝑦是实数,𝑖 是虚数单位,一个复函数 𝑓(𝑧)=𝑢(𝑥,𝑦)+𝑖𝑣(𝑥,𝑦)可以分解为实部 𝑢和虚部 𝑣。
柯西-黎曼方程的定义:
如果复函数 𝑓(𝑧) 在点 𝑧0 可微,则在该点它必须满足以下两个偏导数存在且相等的条件,即柯西-黎曼方程:
∂𝑢∂𝑥=∂𝑣∂𝑦 ∂𝑢∂𝑦=−∂𝑣∂𝑥
几何解释:
- 第一个方程表明,沿着实轴方向的变化率(𝑢u 对 𝑥x 的偏导数)等于沿着虚轴方向的变化率(𝑣v 对 𝑦y 的偏导数)。
- 第二个方程表明,𝑢u 对 𝑦y 的偏导数的负值等于 𝑣v 对 𝑥x 的偏导数,这反映了复平面上的旋转对称性。
柯西-黎曼方程与解析函数的关系:
- 如果一个复函数在某个区域内的每点都满足柯西-黎曼方程,那么这个函数在该区域内是解析的(analytic)。
- 反之,如果一个函数在某区域内解析,那么它在该区域内的每点都满足柯西-黎曼方程。
- 解析函数:柯西-黎曼方程是定义解析函数的关键条件之一。
考虑一个简单的复函数 𝑓(𝑧)=𝑧2f(z)=z2,其中 𝑧=𝑥+𝑖𝑦z=x+iy。它的实部 𝑢u 和虚部 𝑣v 分别为:
𝑢(𝑥,𝑦)=𝑥2−𝑦2u(x,y)=x2−y2 𝑣(𝑥,𝑦)=2𝑥𝑦v(x,y)=2xy
计算偏导数:
∂𝑢∂𝑥=2𝑥∂x∂u=2x ∂𝑣∂𝑦=2𝑥∂y∂v=2x ∂𝑢∂𝑦=−2𝑦∂y∂u=−2y ∂𝑣∂𝑥=2𝑦∂x∂v=2y
可以看到,这些偏导数满足柯西-黎曼方程,因此 𝑓(𝑧)=𝑧2 是一个在复平面上解析的函数。
柯西-黎曼方程是复分析中的基础,它们提供了一种检验函数可微性和解析性的方法。
柯西积分定理
如果一个复函数 𝑓(𝑧) 在一个简单闭曲线 𝐶 所围成的区域内是解析的,那么沿曲线 𝐶 的积分可以计算,并且满足:
∮𝐶𝑓(𝑧) 𝑑𝑧=0
这意味着,如果函数在整个闭合路径 𝐶 内部及其边界上都是解析的,那么沿该路径的积分结果为零,积分与路径无关。
公式 𝑓(𝑧0)=1/2𝜋𝑖∮𝐿𝑓(𝑧)/𝑧−𝑧0𝑑𝑧 称为柯西积分公式
留数定理
假设 𝑓(𝑧) 是一个在除了有限个奇点 𝑧1,𝑧2,…,𝑧𝑛 以外的区域内解析的复函数,并且 C 是一个简单闭合路径,它包含这些奇点在内。如果 𝑓(𝑧)在 C 内部除了 𝑧1,𝑧2,…,𝑧𝑛以外的地方都是解析的,那么沿路径 C 的积分可以表示为:
∮𝐶𝑓(𝑧) 𝑑𝑧=2𝜋𝑖∑Res(𝑓,𝑧𝑘)
留数:把函数 𝑓(𝑧) 在某个孤立奇点 𝑧0 的去心邻域内洛朗展开,称负一次方项的系数 𝑐−1 为 𝑓(𝑧) 在 𝑧0 点的留数,记作 Res[𝑓(𝑧),𝑧0] ,即
机器学习
欧氏距离与余弦距离
在机器学习问题中,分析两个特征向量之间的相似性时,常使用余弦相似度来表示。
欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
余弦距离不是一个严格定义的距离。
Word2Vec
Word2Vec是一种浅层的网络结构,有两种结构分别是CBOW(Continues Bag Of Words)和Skip-gram。CBOW是根据上下文出现的词语来预测当前词的生成概率,而Skip-gram是根据当前词来预测上下文中词的生成概率。
主成分分析法(PCA)
N 个二维特征的点 (xi,yi),i∈{1,2,...,N}(x_i,y_i),拟合一条直线。数据方差大的方向为主特征,方差小方向为噪音。特征值是沿其特征向量方向上方差,PCA利用SVD对数据进行分解,保留特征值大的信息,去掉特征值小的信息,将数据投影到方差大的方向上。
PCA是无监督算法,当数据中有很多个类别时就会出现很大的误差,如下图2中将两个类别投影到同一方向上无法区分。
线性判别分析法(LDA)
LDA是有监督的特征分解算法。
中心思想:投影后类内方差最小,类间方差最大。即同类别样本尽量靠拢,不同类别样本尽量分散
与PCA的区别:
-
监督学习:LDA是一种监督学习方法,它使用标签信息来优化类别间的分离度,而PCA是一种无监督学习方法,不使用标签信息。
-
目标:LDA的目标是最大化类别间的分离度和最小化类别内的离散度,而PCA的目标是最大化数据的方差。
-
应用场景:LDA适用于分类问题,而PCA通常用于数据降维和可视化。
支持向量机(SVM)
中心思想:找到一个超平面能够很好的分离不同类别样本。它有两个目标。
目标1:正确分类。对于二分类问题,该平面使得两类分别在平面的两侧。
目标2:两类满足一定间距。分类正确不够,还需要分的足够清楚,点到平面距离越大越好,使boundary足够清晰。
LDA与SVM的联系与区别
线性判别分析(LDA)和支持向量机(SVM)都是监督学习算法,它们在机器学习和统计学中被广泛用于分类问题。
- 线性与非线性:LDA主要用于线性可分的数据,而SVM可以通过核技巧处理非线性可分的数据。
- 模型复杂度:SVM通常比LDA更复杂,尤其是在使用核函数时。LDA的模型复杂度较低,因为它只依赖于均值和协方差。
- 泛化能力:SVM通常具有更好的泛化能力,尤其是在数据不是线性可分的情况下。LDA在数据是高斯分布且协方差相同时效果较好。
- 计算复杂度:SVM的训练过程可能比LDA更耗时,特别是当数据集很大或使用复杂的核函数时。LDA的训练过程相对简单,因为它主要涉及均值和协方差的计算。
- 应用场景:LDA更适合于具有明确线性边界的数据集,而SVM则更适用于复杂的、非线性的数据集。
Normal Equation(正规方程)
对于一个线性回归模型 𝑦=𝑋𝛽+𝜖,其中:
- 𝑦 是响应变量(因变量)。
- 𝑋 是设计矩阵,包含解释变量(自变量)。
- 𝛽 是参数向量,需要估计。
- 𝜖 是误差项。
正规方程通过求解以下优化问题来找到参数 𝛽β 的估计值: min𝛽∑𝑖=1𝑛(𝑦𝑖−𝑋𝑖𝛽)2 其中,𝑦𝑖是第 𝑖i 个观测值,𝑋𝑖是第 𝑖i 行的设计矩阵,𝑛是观测值的数量。
正规方程的解:
正规方程的解可以通过对参数 𝛽 的损失函数进行求导并设置导数为零来获得。这导致以下方程: 𝑋𝑇𝑋𝛽=𝑋𝑇𝑦其中:
- 𝑋𝑇是设计矩阵 𝑋 的转置。
- 𝑋𝑇𝑋是 𝑋 的转置与 𝑋的乘积,是一个对称矩阵。
- 𝑋𝑇𝑦是 𝑋 的转置与响应向量 𝑦的乘积。
正规方程的解为: 𝛽^=(𝑋𝑇𝑋)−1𝑋𝑇 这里,𝛽^β^ 是参数 𝛽β 的估计值。
自动控制原理
能控性
对于一个动态系统,如果存在一个控制输入序列,使得系统从任何初始状态都能够在有限时间内转移到任何期望的最终状态,则称该系统是能控的。
李雅普诺夫稳定性
系统的能量保持不变。
深度学习
Clip
Clip的核心思想是利用海量的弱监督文本,通过对比学习,将图片和文本预训练获得的编码向量在空间上对齐。
RNN
传统的RNN结构在处理长序列时会出现梯度消失或梯度爆炸问题,导致难以捕捉长序列信息。
Residual模块作用
解决退化的空间特征学习问题,因为原始的激活信息在时间转移后仍可通过identity映射访问。防止随着模型层数的加深,出现梯度消失或爆炸,导致性能下降。
TSM+2DCNN=3DCNN
C++
时间复杂度与空间复杂度
-
常见时间复杂度:
- O(1):常数时间复杂度,表示算法的执行时间是一个固定的常数。
- O(log n):对数时间复杂度,如二分查找。while()循环
- O(n):线性时间复杂度,如遍历数组。
- O(n log n):如快速排序、归并排序等基于比较的排序算法。
- O(n^2):平方时间复杂度,如简单的嵌套循环。for()循环
- O(2^n):指数时间复杂度,如递归的斐波那契数列计算。
- O(n!):阶乘时间复杂度,如旅行商问题的暴力解法。
-
常见空间复杂度:
- O(1):常数空间复杂度,算法使用固定大小的空间。
- O(log n):对数空间复杂度,通常是递归算法的栈空间。
- O(n):线性空间复杂度,通常是存储输入数据所需的空间。
- O(n^2):平方空间复杂度,通常是二维数组所需的空间。
- O(2^n):指数空间复杂度,通常是递归深度为指数级别。
- O(n!):阶乘空间复杂度,通常是存储所有可能排列的空间。
C++的特性
面向对象编程
继承:通过派生类扩展基类的功能。
封装:将数据和操作封装在类中,以增强安全性和简化编程。
多态:多态则基于封装和继承,使不同的子类对象能够以相同的方式响应消息或函数调用。
高效性。C++生成的机器码执行效率高,能够直接与硬件交互,适合开发对性能要求较高的应用程序。
跨平台性:C++代码可以在不同的操作系统上编译和运行,提供了良好的可移植性。
内存管理:C++提供了手动内存管理的能力,但同时也可能导致内存泄漏和悬挂指针等问题。
标准库丰富:C++标准库提供了丰富的功能,包括数据结构、算法、输入输出等,便于开发人员快速构建功能强大的应用程序。
数据结构
链表
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的种类主要为:单链表,双链表,循环链表
链表的存储方式:链表的节点在内存中是分散存储的,通过指针连在一起。(数组在内存中是连续的)
信号与系统
什么是高斯白噪声?
高斯白噪声(white Gaussian noise,WGN)是一种理想化的随机信号,它在统计特性上具有两个显著的特点:一是其幅度分布服从高斯分布,即正态分布;二是其功率谱密度在整个频域内服从均匀分布。
零状态响应与零输入响应
零输入响应:没有外加激励信号的作用,只由起始状态所产生的响应。
零状态响应:起始状态为零,由系统外加激励信号所产生的响应。
齐次解(自由响应):仅依赖于系统本身。
特解(强迫响应):仅由激励函数决定。
无失真传输
线性失真:幅度失真、相位失真
非线性失真:产生了新频率分量
为实现无失真传输,系统需要满足:幅度特性对所有有用的频率为常数、相位特性与频率承线性关系(群时延为常数)
为尽量补偿线性失真,在接收端之前采用均衡器与原系统级联,使得新系统的幅度和相位特性满足无失真传输条件。
滤波器的用途
什么是线性系统?
叠加性:系统对多个输入信号的响应等于各个输入信号分别经过系统后的响应之和。
齐次性:系统对输入信号进行缩放后,输出信号也会相应地按比例缩放。
线性性:系统对输入信号进行线性组合后,输出信号也会按相同的线性关系组合。
时不变性:系统对输入信号的响应与输入信号在时间上的平移无关,即系统的特性不随时间的变化而变化。
因果性:系统的输出只依赖于当前和过去的输入信号值,而不依赖于未来的输入信号。
这些特点使得线性系统具有可预测、稳定、可分析和可控制的优势,因此在信号处理、通信系统、控制系统等领域得到广泛应用。
线性系统的基本组成单元?
线性元件(Linear Element):例如,电阻、电感、电容等都是常见的线性元件。
时延元件(Time Delay Element):例如,时钟电路中的触发器就是一种常见的时延元件。
系统组合单元(System Combination Element):例如,滤波器、放大器、传输线等都是由线性元件和时延元件组合而成的系统。
傅里叶级数与傅里叶变换?
傅里叶级数是将周期函数分解成一系列不同频率的三角函数的线性组合(叠加)。频域上是离散的。
傅里叶级数展开的周期信号必须满足狄里克莱条件(在周期内绝对可积)。
傅里叶变换是将非周期函数或周期函数(不局限于某个周期)表示为连续频率的正弦和余弦函数的积分。对于一个连续函数 𝑓(𝑡)f(t),其傅里叶变换 𝐹(𝜔)F(ω) 定义为: 𝐹(𝜔)=∫−∞∞𝑓(𝑡)𝑒−𝑗𝜔𝑡 𝑑𝑡F(ω)=∫−∞∞f(t)e−jωtdt
非周期信号可以看成是周期T趋于无穷大的周期信号,谱线间隔,谱线间隔趋于无穷小,由离散谱变为连续谱,因此,时域非周期信号在频域上是连续的。
拉普拉斯变换
拉普拉斯变换是对傅里叶变换的改进,做傅里叶变换的函数需要满足绝对可积的严格条件,而拉普拉斯变换引入了衰减因子(傅里叶变换乘以衰减因子e-at),s=a+jw,复频域上的变换不需要满足绝对可积的条件,应用范围更广,结果更简洁。
拉普拉斯变换是一种积分变换,用于将时域信号转换为复频域信号,便于分析和解决线性时不变系统的微分方程。
傅里叶变换是时域到频域,拉普拉斯变换是时域到复频域,复频域实际上是三维空间,底面为频率点,高为幅值。
在求解一般非周期信号作用于具体电路的响应时,用H(s)更方便,拉氏变换求逆变换方便。
傅里叶变换求逆变换麻烦,所以很少使用H(jw)。H(jw)的意义在于研究信号传输特性和滤波器特性。
极点分布对系统稳定性的影响?
若系统对任意的有界输入其零状态响应也是有界的,则为稳定系统。
系统的稳定性与系统的因果性和极点的位置有关。
若系统传函的极点都在s的左半平面,则系统是稳定的。
全通系统与最小相移系统
若系统函数的极点位于左半平面,零点位于右半平面,且零极点关于jw轴互为镜像,则系统为全通系统。
若是离散系统则极点和零点之间是共轭倒异关系。
全通系统的幅频特性为常数,只改变信号的相频特性,常用于相位校正,作相位均衡器或移相器。
连续系统中零点仅位于左半平面或jw轴的系统为最小相移系统。
离散系统中零点均在单位圆内。
非最小相移函数可以看作是最小相移函数与全通函数的乘积。
能量信号与功率信号
能量有限的信号为能量信号,通常非周期信号属于能量信号。
功率有限的信号为功率信号, 通常周期信号属于功率信号。
卷积
求系统对于输入信号的输出响应,将输入的激励信号与系统的单位脉冲响应卷积。
利用卷积的方法求系统的零状态响应。首先把激励信号分解为冲激函数序列,然后令每一冲激函数单独作用于系统求其冲击响应,最后把这些响应叠加即可得到系统对此激励信号的零状态响应。
卷积是一种数学运算,用于描述两个函数的综合效果。在信号处理中,卷积用于分析系统的输入信号和系统的脉冲响应如何结合产生输出信号。
Z变换
z变换是分析离散序列的变换方式,由抽样序列的拉普拉斯变换引出,z=e^sT,s域中的虚轴对应z域中的单位圆。
自相关函数
自相关函数的傅里叶变换等于信号的功率谱密度。这意味着通过分析自相关函数,可以得到信号的频率内容。
数字信号处理
DTFT
序列的傅里叶变换称为离散时间傅里叶变换,时域是离散非周期,频域是周期连续。周期为2pi
单位圆上的z变换是序列的傅里叶变换。z=e^jw
序列需要绝对可和才存在傅里叶变换。
DFT
引入DFT是为了利用计算机来计算傅里叶变换。
DFT是对DTFT频域的N点等间隔采样,对应时域就是周期延拖,即把离散周期时域变换为周期离散频域。
DFT是z变换在单位圆上的均匀抽样。
FFT
FFT是DFT的一种快速计算方式,利用了旋转因子的周期性和对称性,将N点的DFT分解为N/2点的DFT相加,减小了计算量,将运算速度提高了大约N/logN倍
为什么理想滤波器不可能实现?
因为理想滤波器的单位脉冲响应是非因果且无限长的。
幅频特性和相频特性
幅频特性表示信号通过滤波器后各频率成分振幅衰减情况。
相频特性表示各频率成分通过滤波器后在时间上的延时情况。
幅度特性和相位特性
幅度特性可正可负,而幅频特性只能为正值。
IIR滤波器的设计
IIR是无限长单位脉冲响应滤波器,先根据指标设计模拟滤波器,再将模拟滤波器转化为数字滤波器。(巴特沃斯低通滤波器设计)
脉冲响应不变法:一种时域逼近的方法,,
是线性频率映射,但是在
附近会产生频谱混叠,因此只能设计带限滤波器。
双线性变换法:为了解决频谱混叠采用非线性频率压缩,缺点是与
之间是非线性关系。
FIR滤波器的设计
稳定和线性相位是FIR滤波器最突出的优点。
线性相位是指群时延是一个常数
线性相位的时域约束条件是h(n)关于(N-1)/2对称。h(n)=h(N-1-n)
窗函数法是利用窗函数截取一段h(n),用有限长序列去近似代替无限长序列,引起的误差叫做吉布斯效应。
窗函数法又称为傅氏级数法,就是找到N个傅里叶级数系数h(n),以N项傅氏级数去近似代替无限项傅氏级数。
线性相位FIR数字滤波器的零点分布特点
零点是互为倒数的共轭对
通信原理
什么是平稳随机过程?
如果一个随机过程的所有统计特性不随时间变化,那么它就是严格平稳的。
宽平稳:均值为常数,协方差(自相关函数)仅与时间差有关。
调制的目的和本质
天线的长度与波长成正比,将信号调制到高频可以减小天线的长度,将信号以电磁波的形式辐射出去。
调制的本质是把各种信号的频谱搬移,使他们互不重叠的占据不同的频率范围,实现一个信道中传输多路通话。
调制是将基带信号通过载波变换为适合在信道中传输的信号,载波随信号而变化。
调制的主要作用是扩展基带信号的频带,使其能够与传输媒介相匹配,从而提高信号传输的可靠性和效率,提高抗干扰能力。
频谱和带宽的关系
频谱是信号在频率域上的表示,带宽是信号占据的频率范围。
信源编码与信道编码
信源编码:信源编码是指将来自信源的信息进行压缩和编码,以减少信息的冗余度,从而达到更高效的存储和传输。信源编码的作用是通过消除或减少冗余信息,使得信息在传输过程中占用更少的带宽或存储空间。常见的信源编码方法包括霍夫曼编码、香农-费诺编码等。
信道编码:信道编码是指对经过信源编码后的信息添加冗余,以便在传输过程中能够检测和纠正错误,提高传输的可靠性。例如:奇偶校验码、线性分组码等。
脉冲编码调制(PCM)
脉冲幅度调制(PAM)是利用脉冲序列对连续信号进行抽样产生的信号(时间离散,幅度连续)
PCM的过程为抽样、量化、编码(A/D转换)
匹配滤波器
匹配是指滤波器的性能与信号的特性达到某种一致,使得滤波器输出端的信号功率与噪声功率的比值最大(信噪比最大)。
匹配滤波器的冲激响应是信号的镜像平移。h(t)=s(T-t)
3G
3G的核心技术是CDMA(码分多址)。码分是指利用一组正交码序列来区分各路信号,它们占用的频带和时间都可以重叠。理论依据是利用自相关函数抑制互相关函数的特性来选取正交信号码组中的所需信号。
OFDM正交频分复用
OFDM将整个频带划分为多个子载波,这些子载波在频域上是正交的,同时传输不会相互干扰,提高了带宽利用率,并且提高了信息传输速率,还抗多径干扰。
多址技术(多路复用)
FDMA(1G):用频率来区分用户,每个用户分以不同的频率。
TDMA(2G):用时间来区分用户,在相同的频段下,用户轮流发送信息。
CDMA(3G):用编码来区分用户,在相同的频段下,用户赋予不同的编码。
蓝牙技术
蓝牙是一种短距离通信技术,用于在设备之间传输数据,在2.4G频段。
雷达的基本原理
雷达是利用无线波进行目标探测和追踪,通过测量发射和接收信号的时间差来确定目标位置。
MIMO
MIMO,全称是多输入多输出(Multiple Input Multiple Output),通过在发送端和接收端使用多个天线来显著提高数据传输的速率和可靠性。
清华源镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some packets
启动tensorboard
tensorboard --logdir data
电路
为什么要引入相量?
A: 相量是交流电路分析中的一种重要方法,可以将正弦交流量用复数表示,极大简化了计算过程,特别是在计算电路的稳态响应时,能够方便地处理幅值和相位的问题。
全电流定律是什么?
A: 全电流定律,又称基尔霍夫电流定律(KCL),是指在任何一个节点上,流入节点的电流总和等于流出节点的电流总和。这个定律反映了电荷守恒的原理。
请讲解下TTL和CMOS的区别
PN结的结构
理想运放的特点
1、理想运放特点
- 增益无穷大
- 输入阻抗无穷大
- 输出阻抗为0
2、虚断使用条件
- 基本无门槛(来源于运放的输入阻抗非常大)
3、虚短使用的条件
- 负反馈
- 工作在线性放大区
CMOS的工作原理
当在栅极(G)和源极(S)之间施加适当的电压时,形成导电沟道,晶体管导通,允许电流流过漏极(D)和源极(S)。如果栅极电压不适当,晶体管则截止,阻止电流流动。
计算机
TCP/IP结构的各层功能是什么?
TCP/IP模型有四层:应用层负责处理特定网络应用的通信;传输层提供端到端的通信服务;网络层负责数据包的路由和转发;链路层负责物理传输介质上的数据传输。
OSPF协议的作用是什么?
OSPF(开放最短路径优先)是一种链路状态路由协议,用于IP网络中的内部网关协议,基于最短路径优先算法计算路由,适用于大型复杂网络。
电磁场
常见波导的传输模式有哪些?
常见波导的传输模式包括矩形波导的TE(横电磁波)模式和TM(横磁波)模式,以及圆波导的TE、TM和TEM(横电磁波)模式。
传输线反射系数如何定义?
传输线的反射系数定义为反射波的电压振幅与入射波的电压振幅之比。它是一个复数,描述了传输线终端负载对入射电波的反射情况。
非均匀介质,极化后内部出现束缚电荷。
均匀介质,极化后只在自由电荷附近和界面处出现束缚电荷。
电场使介质极化产生束缚电荷,束缚电荷产生电场。
电势:电场力移动单位正电荷做功。
N波:E垂直入射面
P波:E平行入射面
趋肤效应:对于高频电磁波,电磁场和高频电流集中在金属表面很薄的一层。
达朗贝尔方程:电流产生矢势波动、电荷产生标势波动
推迟势是达朗贝尔方程的解。推迟势的物理意义在于,它考虑了电磁场的传播延迟,即电磁场的相互作用不是瞬时的,而是以有限速度(光速)传播的。这意味着,一个电荷在某一时刻的状态,需要经过一段时间才能影响到远处的观测点。这种延迟是电磁场的因果性质的体现,即效应不能发生在原因之前。


















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











