







ifconfig
通过指令ifconfig便可以查看到两个网络接口:
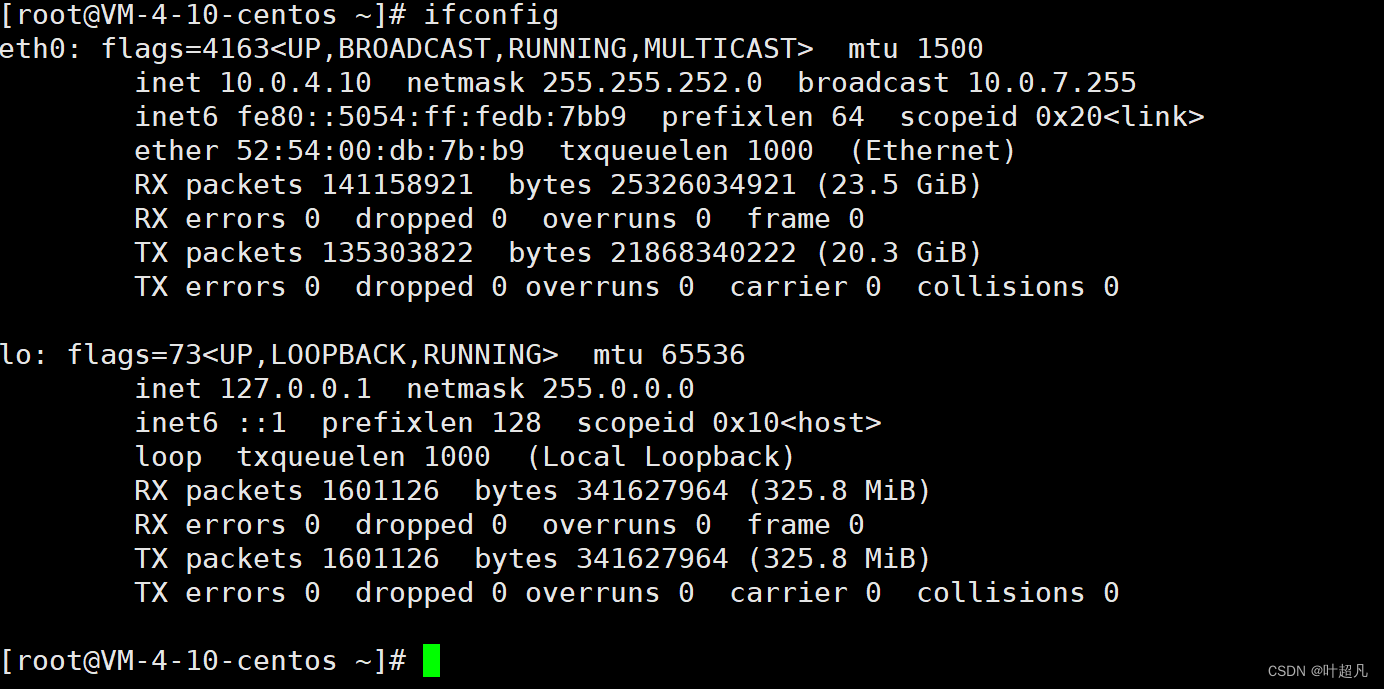
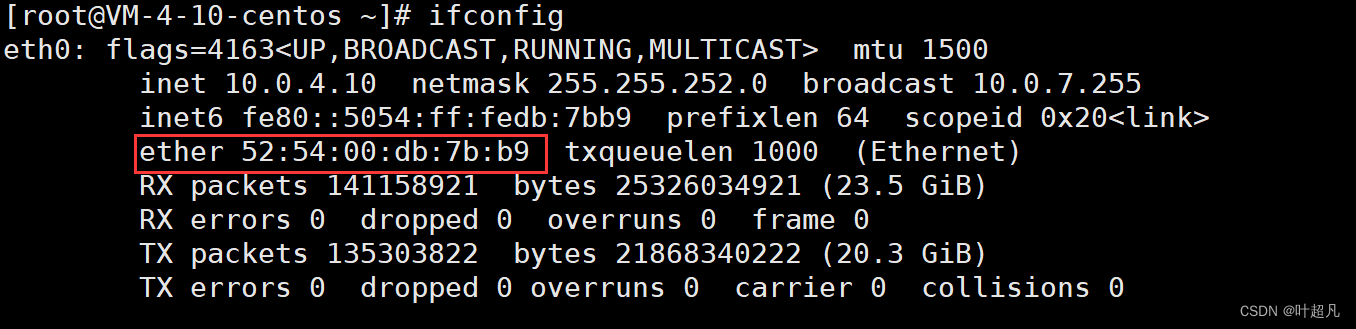
我们当前使用的是一个linux服务器并是一个终端设备,所以他只需要一个接口用来入网即可,而上面的etho就刚好入网接口,这个接口是操作系统给我们维护好的一般叫做eth0,如果有些小伙伴自己装的是虚拟机则可能叫做其他的名字比如说es33等等,这个接口是直接接入到网络当中的,也就是说机器想要接收数据或者发送数据都是通过这个接口来进行实现的,该接口一定配有对应的mac地址比如说上述图片中的ether后面的一长串数字,ether就是以太的意思:
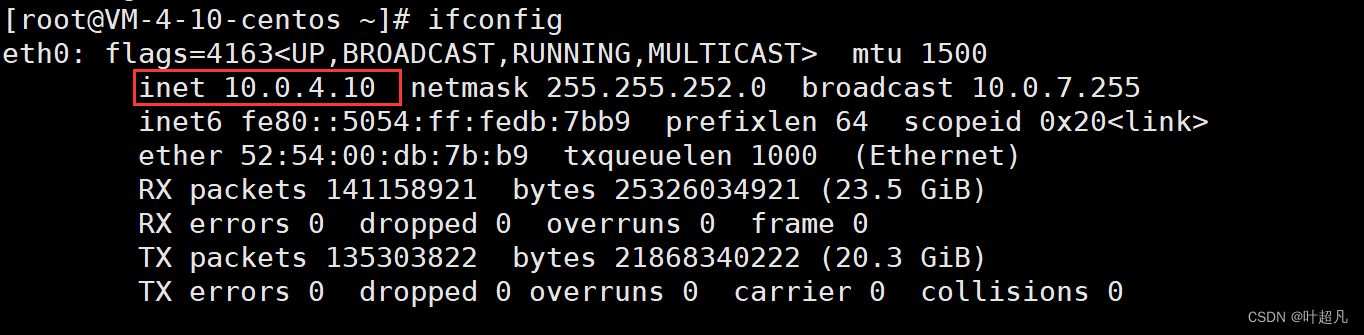
然后ip地址就是inet后面的一长串数字:
但是有小伙伴肯定会感到十分的不解,因为我们登录云服务器所使用的地址也就是公网ip并不是这样的,而是下面这样的图片:
那么这里大家就得注意一下,你使用的公网ip是属于你的云服务器能被你正常访问所赋予的ip,你可能买的腾讯云,阿里云,华为等等,不管你买的是什么云,你最终内部匹配的地址都是在人家公司内网的,所以上面inet后面的地址就是内网ip私有ip或者局域网ip。ip地址通过点来作为分隔符将一串数字划分成四个数字每个数字的值为0-255,我们把这样的地址表示方法称为点分十进制把这样的地址就称之为ipv4。而mac地址长度为48位, 及6个字节. 一般用16进制数字加上冒号的形式来表示(例如: 08:00:27:03:fb:19)在网卡出厂时就确定了, 不能修改. mac地址通常是唯一的(虚拟机中的mac地址不是真实的mac地址, 可能会冲突; 也有些网卡支持用户配置mac地址)。
ip地址和mac地址的区别
大家在做高铁的时候一定看到过下面这样的场景:

大屏上面显示着每辆高铁是从哪个地方出发,终点站又是哪里?那么这是一个场景,但是大家在高铁上时有可以从高铁上看到这样的场景:
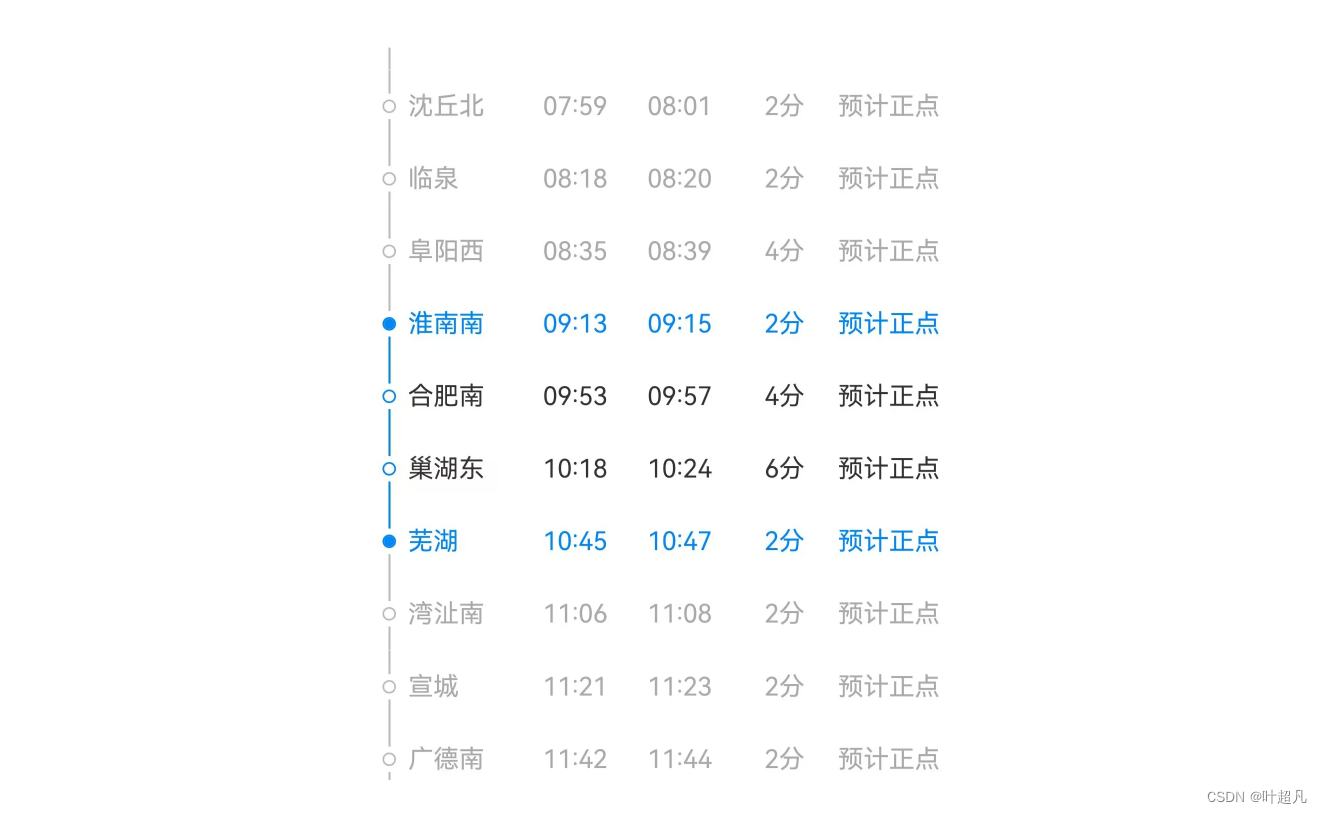
上面显示着当前的高铁位于哪一站,上一站是什么,下一站又要到哪去?随着高铁的运行这张照片显示的信息也在不停的变化,比如说当前高铁位于淮南站那么他是从阜阳西来的下一站就到达了合肥南站,等到达了合肥南之后当前的屏幕上显示的信息就是当前站是合肥南他是从淮南南开来的下一站将到达巢湖东,所以通过这两个照片我们不难发现第一张提供的是起始地点和最终目的地就好比唐僧总是会说我是从东土大唐而来将前往西天取景,而第二张照片提供的信息就是你当前所处的具体位置和你下一步要前往的具体位置,就好比唐僧当前在琵琶洞那么他的下一站就可能就是火焰山或者女儿国,所以我们不难发现进行长途跋涉的时候地址是分为两套的,一个是你要去的终极目的地这种地址就是计算机中的IP地址也可以称之为源IP地址,他为我们未来的每一个阶段提供方向和目标,另外一种就是当前所在位置的地址我从哪里来到哪里去,该类地址一直在变化我们把这相邻的两个地址称之为mac地址,并且mac地址也分为目的mac地址和源mac地址,所以ip地址提供是方向mac地址则表示当前方向完成的可行性,这就好比大学刚开始的时候我们定的大学目标是进大厂华为,那么实现这个目标的步骤就是先学c语言再学数据结构再学操作系统等等等,那么进华为就相当于ip地址,先学啥再学啥就相当于mac地址,从一个mac地址跳转到另外一个mac地址就说明两个地址是挨着的,当两个地址位于同一个局域网时便使用mac地址,比如说下面的这张图片(应该是应用层不是用户层):
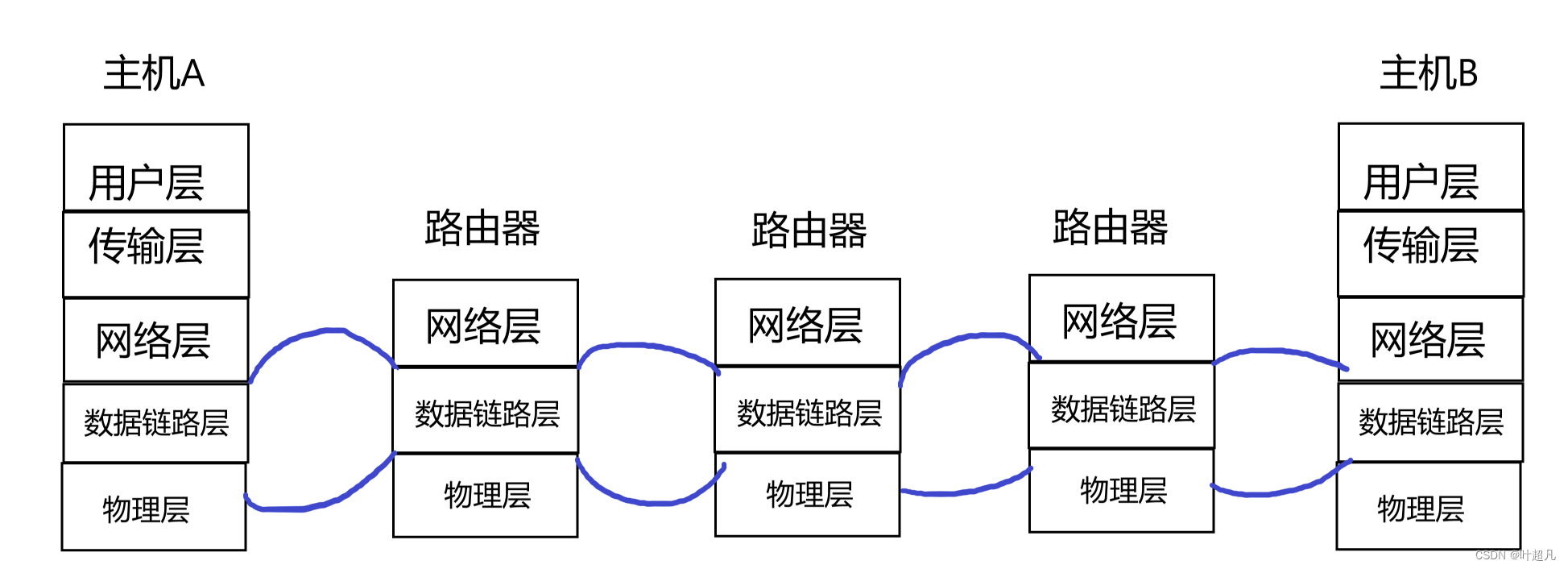
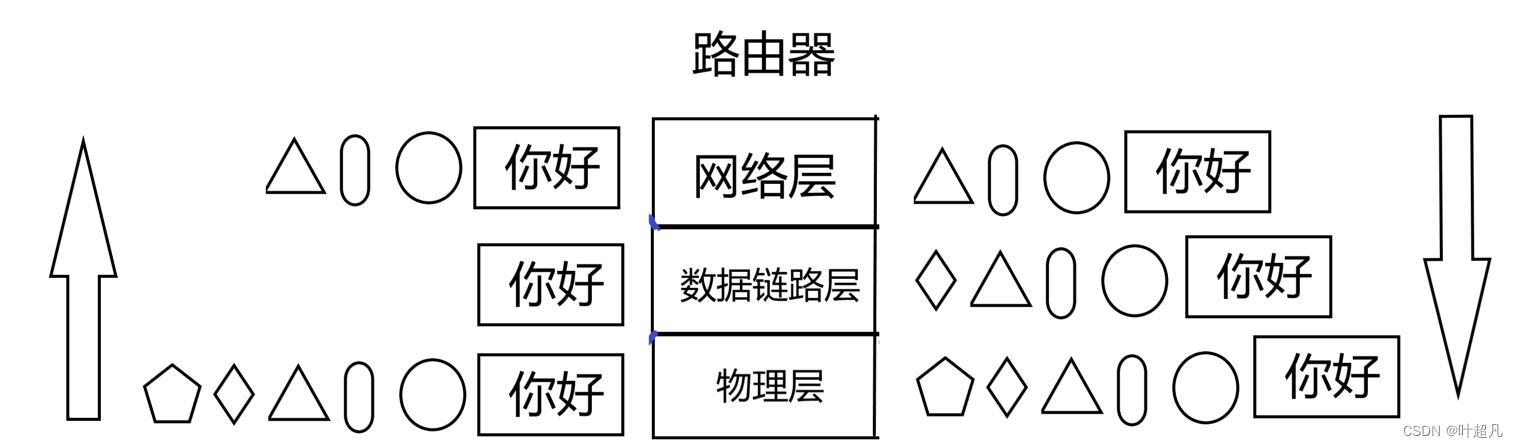
主机和路由器之间是直接连接的,路由器和路由器之间也是直接连接的,所以他们位于主机和路由器,以及路由器和路由器之间是位于同一个局域网的,所以消息可以直接传递,所以我们表面上看到的消息跨网络传输实际上是由无数个子网组成的,知道了这一点之后我们就可以结合之前学习的内容再来理解一下数据转发的过程,首先从应用层接收数据然后通过当前的主机对数据进行包装然后到达了最底层:
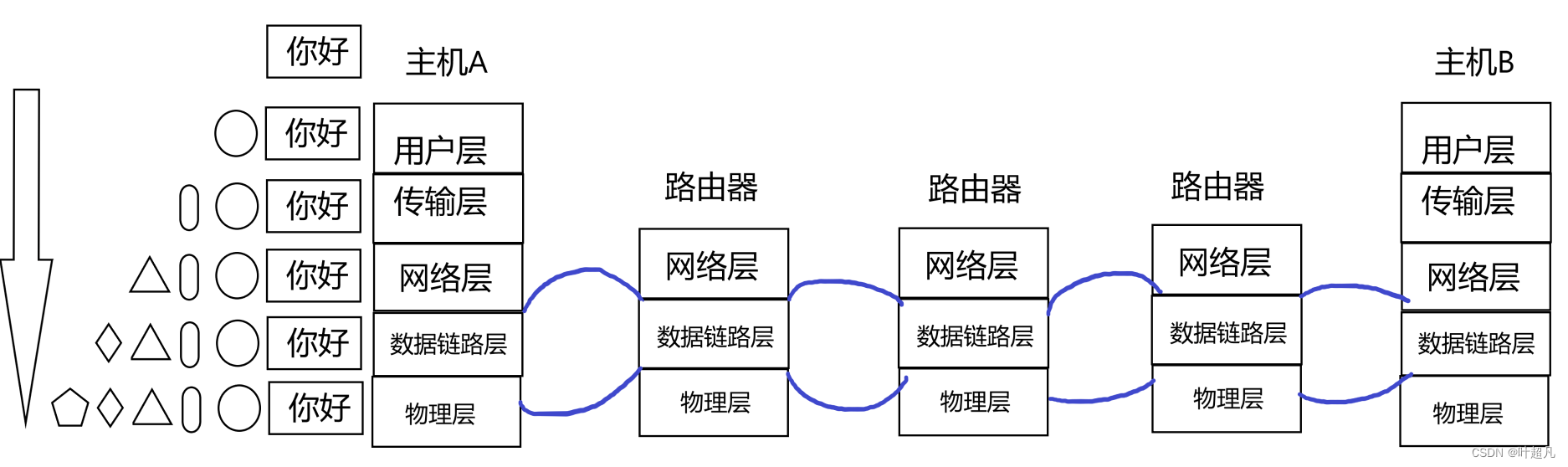
因为主机A和路由器直接相连所以便可以将数据直接传递给第一个路由器:
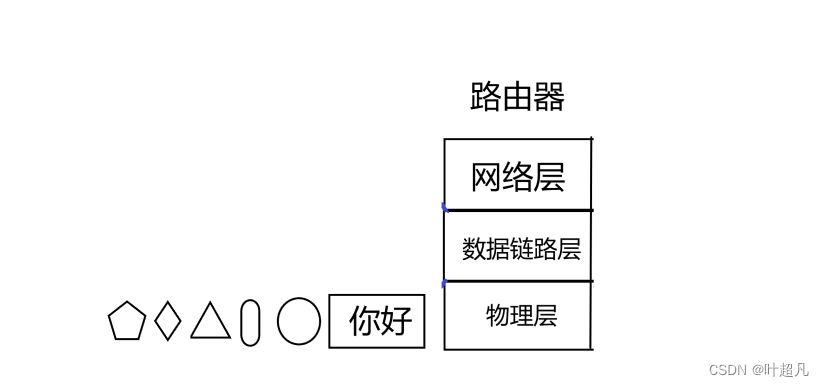
路由器拿到数据之后并不知道当前的数据是发向何处的,而路由器工作在网络层网络层的作用又刚好是负责地址管理和路由选择,所以数据来到路由器之后就会向上解包分用来到网络层之后就可以对报头进行解析这样便可以知道当前数据的目的地址是哪里?这样他便可以知道要将该数据发送到哪个路由器
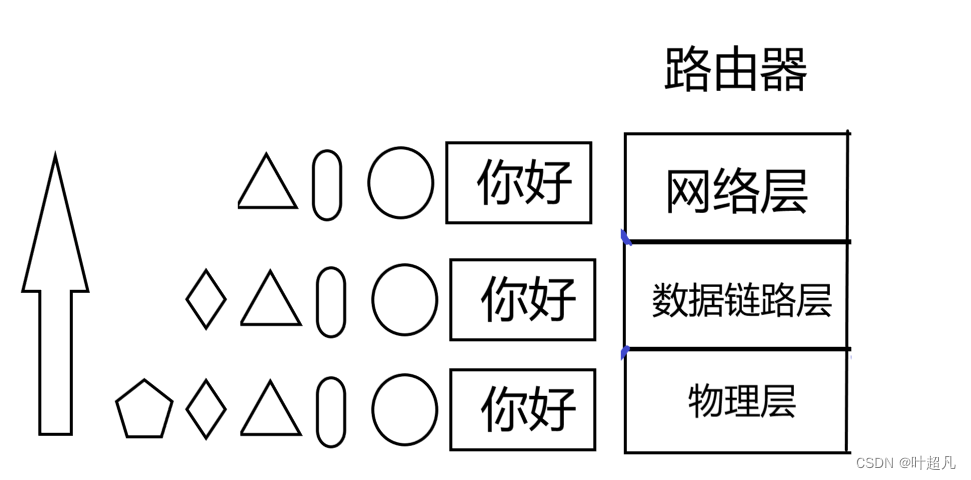
又因为网络层不能直接转发到对应的路由器上,所以知道往哪发送数据之后便向下进行封装然后通过物理层传递到对应的路由器上进行相同的步骤,直到到达对应的主机即可。
端口号
假设当前存在两个机器,一个机器的IP地址为IPA另外一个机器的地址为IPB,假设主机A把一段数据发送给了主机B

那将数据从A主机上发送到B主机是目的吗?答案肯定是不是的,真正通信的不是这两个机器而是这两个机器上的软件,那么这里就存在一个问题:数据在传递的时候可以通过公网ip来标识一台主机,所以可以确保将数据发送的时候不会出现错误,但是每台主机上都有很多的应用和服务,那我们该如何保证主机上的A进程发出的数据能够准确的交给另一台主机上的B进程呢?也就是在网络通信的时候如何来表示各主机上客户或者服务进程的唯一性呢?如果没有办法保证唯一性则可能会出现微信上收到的消息在抖音上呈现,抖音上接收到的视频在微信上播放,所以为了更好的表示一台主机上服务进程的唯一性,我们这里就引入一个东西新的概念叫做端口号,端口号是传输层的内容所以他是传输层要维护的一个概念,但是端口号在应用层中也要被使用所以我们还是得知晓这个内容,因为操作系统中的进程具有唯一性所以我们可以使用端口号来标识进程,也就是用一个新的数字来表示一个进程,通过系统调用可以将进程和端口号绑定起来,端口号是一个2字节16位的整数,用来标识主机上一个进程的唯一性然后告诉操作系统当前的这个数据要交给哪一个进程来处理,ip地址(主机全网唯一性)+该主机上的端口号标识该服务器上进程的唯一性,那么这两个东西合在一起就可以表示该主机上对应的服务进程在全网中的唯一性,所以主机A上的进程具有唯一性(ipA+portA),主机B上的进程也具有唯一性(ipB+portB),而软件的运行在操作系统中是以进程作为载体的,所以网络通信的本质其实就是进程间通信,通信的本质是让不同的进程先看到同一份资源,这个资源就是网络,所以通信的本质就是在对共享资源做io,所以我们所有上网的行为无外乎就两种:把我的数据发送出去和收到别人发给我的数据。端口号用来标识一台主机上进程的唯一性,所以一个端口号不能被多个进程绑定,但是一个进程可以绑定多个端口号,并且不同机器上对应进程的端口号可以是一样的,因为IP地址在全网具有唯一性。在网络通信的过程中,ip+port是用来表示唯一性的,源端口在向目的端口发送数据的时候还得将自己的ip和port发送给对方,因为目的端口可能还要将一些数据发送回来,所以未来在发送数据的时候一定会多发送一部分数据,那么这部分数据就以协议的形式呈现。
pid和端口号
这里就存在一个问题进程的pid也是具有唯一性的那为什么要用port端口号而不是进程的pid来标识唯一性呢?如果从技术的角度出发使用pid是一定可以做到和端口号同样的功能,但是系统是系统,网络是网络,如果使用pid来标识网络中的唯一性的话就会导致网络和系统的强耦合,所以单独设置的一个好处就是让网络和系统解耦,第二个好处就是:一般都是客户端先发出的网络请求所以这就要求客户端每次都能找到服务器的进程,所以服务器的唯一性不能有任何的改变,也就是说ip地址加上port不能做任何的改变,这就好比在中国120一定是急救电话,119一定是火警电话,port的值是我们自己设置的,在公司里面会有明确规定哪个服务哪个进程绑定哪个端口号比如说抖音进程一定绑定的是8080这个端口号,所以不管抖音重新被加载多少次每次绑定的端口号都是8080,只要我们不亲自修改那么他的值就不会发生改变,ip地址是每个服务器特有的也不会轻易发生改变,所以ip+port也就不会轻易的发生改变,所以客户端每次找都能够轻松的找到,但是pid是很容易改变的将同一个程序多次加载进内存时每次产生的pid地址都不一样,所以不能使用pid来标识唯一性这就好比第一次打119是火警电话第二次打就变成了急救电话第三次打变成了警察电话,并且不是所有的进程都需要网络服务和请求,但是所有的进程都需要pid,这也是为什么不用pid来做标识的原因。看到这里大家的心里肯定还有一个疑问:操作系统是如何根据port找到指定的进程的呢?方法很简单使用哈希表将端口号和pcb的地址绑定起来,这样找到了端口号就可以找到pcb的地址,有了pcb的地址之后就可以找打pcb,找到了pcb就可以找到对应进程的各种信息和属性并操作进程了。
UDP和TCP的初步了解
在网络通信的时候一定是从上往下进行调用的,不存在说应用层直接调用网络层的接口,而是应用层调用传输层的接口再调用网络层的接口,那么传输层就存在两个协议一个叫做UDP一个叫做TCP,TCP(Transmission Control Protocol 传输控制协议)是可靠的,也就是说使用这个协议通信的时候如果出现了丢包,重复发送,以及我们发的太快对方来不及接收等等情况时,该协议能够帮助我们很好的处理上述的突发情况,至于是如何解决的这里就不需要我们关心,因为该协议是操作系统内部来进行维护的我们知道即可,此外在使用该协议通信之前得先建立链接,就好比一个人输入手机号码给另外一个人打电话的时候,另外一个人得先确认接听之后两人才能正常的通信,最后就是该协议是面向字节流,那么看到这里大家对TCP理解就是可靠传输,有链接的即可。UDP(User Datagram Protocol 用户数据报协议),该协议与TCP相反他是不需要链接的,就好比日常在发送邮件的时候直接发送即可无需对方的同一,此外该协议是不可靠传输在发送数据出现丢包等异常的时候他是不会对其进行处理的,最后该协议是面向数据包报的这个特性后面再讲。那么看到这里想必大家心里存在一个问题:UDP是不可靠传输,TCP是可靠的传输,那为什么UDP协议还存在呢?可靠的传输难道不是更好吗?那么这里大家要知道的一点就是可靠和不可靠实际上是一个中性词,可靠往往就意味着在代码的维护上和编码上是更加复杂的,而不可靠则说明该协议在维护和编码上是比较轻松容易的,所以这里各有取舍大家按照自己的需求来进行选着,比如说银行在转账的时候可以使用UDP协议吗?一定不能对吧,那要是存在一种场景他不在意是否丢包但是要求传输数据时的速度和流量消耗的大小的话那他还会选着TCP协议肯定就不会了对吧,比如说抖音直播等等,那么这就是对两个协议的初步认识。
网络字节序
数据是有高权值和低权值之分比如说1234表示的是一千两百三十四,那么这个一就是高权值位四就是低权值位,而计算机内存的地址也有高地址和低地址之分,所以内存在存储数据的时候就存在两种情况将低权值位的数据放到低地址处和将低权值位的数据放到大端,那么我们把第一种情况就称之为小端存储,将第二种情况称之为大端存储,那么在网络通讯的过程中就可能会出现这种情,当前存在两个主机A和主机B,A主机是大端存储的B主机是小端存储,发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出,接收主机把从网络上接到的字节依次保存在接收缓冲区中也是按内存地址从低到高的顺序保存,因此网络数据流的地址是这样规定:先发出的数据是低地址,后发出的数据是高地址,所以网络数据流同样有大端小端之分,所以A主机发送出来的大端数据是可以直接在网络上传输的,但是主机B是小端机所以数据抵达了B之后就会出现数据混乱的问题

并且未来我们在编码发送数据或者接收数据的时候我们怎么知道接收到的数据是大端数据还是小端数据呢?我们要把某个数据发送给一个主机,那我们怎么知道对方的主机是大端机还是小端机呢?所以为了解决这个问题我们就定了一个规定:网络中的数据都是大端。那么有了这个规定之后大端机在发送数据的时候可以直接发送,在接收数据的时候也可以直接接收,而小端机在发送数据的时候就得先将小端数据转换成为大端数据再发送,接收数据数据的时候也得现将数据转换成为小端数据再进行接收,那么这么做就可以解决世界上所有大小端的问题。那么操作系统为了简化我们在发送数据时转换大小端的工作量就提供了下面这些库函数来实现网络字节序和主机字节序的转换:
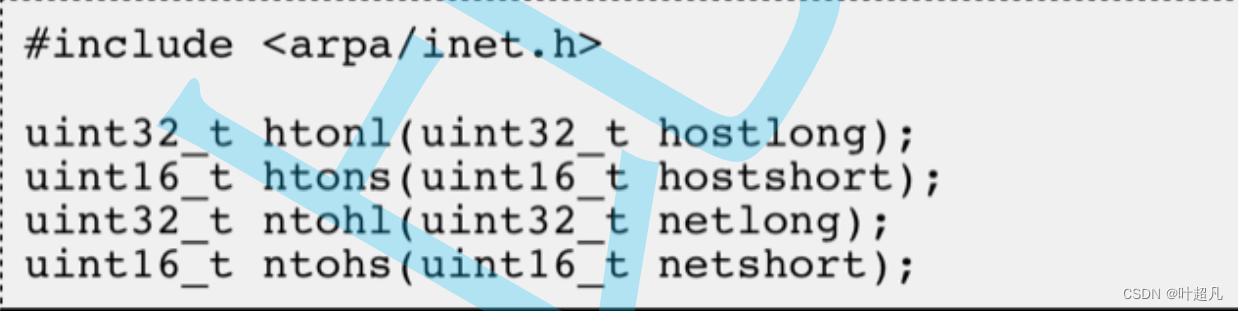
h表示的是house也就是主机的意思,to表示的发送的意思,n表示的net也就是网络的意思,l表示的就是long也就是32字节,s表示的就是short也就是16字节,那么htonl的意思就是将32字节的主机序列转换成为网络序列,ntohs的意思就是将16字节的网络序列转换成为主机序列,那么这个主机序列到底是大端还是小端该函数自己会进行判断,将你想要转换的数据作为参数传递过来该函数返回的就是对应的大端序列的数据,但是这里大家心里可能会存在一个疑惑这里只有long和short那我以后想要发送的数据是字符串该怎么办,以后发送的数据是浮点数该怎么办?那么这里大家就不用担心我们未来发送的所有数据在网络中都是字符串,并且未来我们使用原生的接口read或者send在发送和接收数据的时候自动会对字符串数据做大小端转换,而上面列出来的几个函数是比较特殊的也就是说遇到特殊的场景就会使用他,如果我们没有使用他就表明该接口可以自动的帮助我们做大小端转换,那么这就是网络字节序的概念。
socket套接字
虽然现在的应用层已经有了非常成熟的方案但是我们先不考虑他,我们自己来写应用层的代码,既然我们自己要写应用层而传输层又是操作系统所管理的,应用层得先将数据添加报头再传递传输层,所以操作系统必须得提供访问一些系统调用接口来供使用者使用,那么我们就把这种借口称之为socket编程接口,我们下面就列举了一些常见的socket接口:
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,
socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);
ip地址加上端口号可以在全网中标定主机上进程的唯一性,我们把ip地址加端口号就可以称之为套接字,网络套接字至少有三种:网络套接字编程,原始套接字,unix域间套接字,这三种套接字的运用场景完全不一样,网络套接字既能实现网络通信也能实现本地间通信,而unix域间套接字只能实现本地通信,所以unix套接字我们就不学,原始套接字并不是用来做应用层开发的,使用这种套接字可以不按照顺序从上往下进行传递,他可以绕过传输层从而访问底层的各种各样的数据,所以各种抓包的软件网络侦测的软件在底层使用的就是原始套接字来完成的,那么这种套接字我们也不学,所以我们真正学习的套接字就是网络套接字,有3个套接字就一定得有三套不同的接口,但是这些接口本质上都是套接字的这种思想,并且各种接口之间很多功能都是重合的,所以面对这样的场景是我们就像只涉及一套接口,然后通过不同的参数解决所有网课或者其他场景下的通信问题。接口不一样无外乎就两种一个是参数的个数不一样,一个就是参数的类型不一样,对于个数不一样c语言可以采用结构体的方式来解决,但是类型不一样c语言就很难解决,所以为了解决套接字接口中参数类型不一样的问题就有了sockaddr结构,首先有一个结构叫做struct sockaddr_in这里的in表示的是inet也就是网络通信的套接字,还有一个叫做struct sockaddr_un这里的un表示的是unix套接字
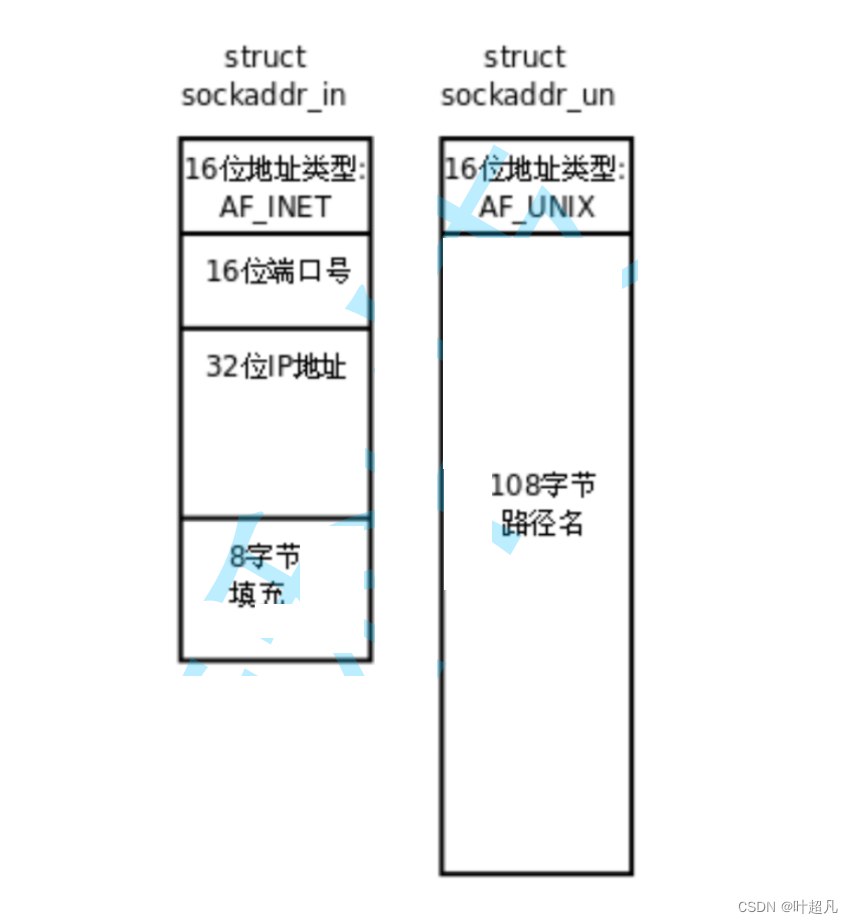
这两个结构的类型很明显是不一样的所以在设计对应接口的时候就必定得设计出两种不同的接口,但是接口得设计者就不想这么干于是就设计出来了一个名为struct sockaddr的结构:
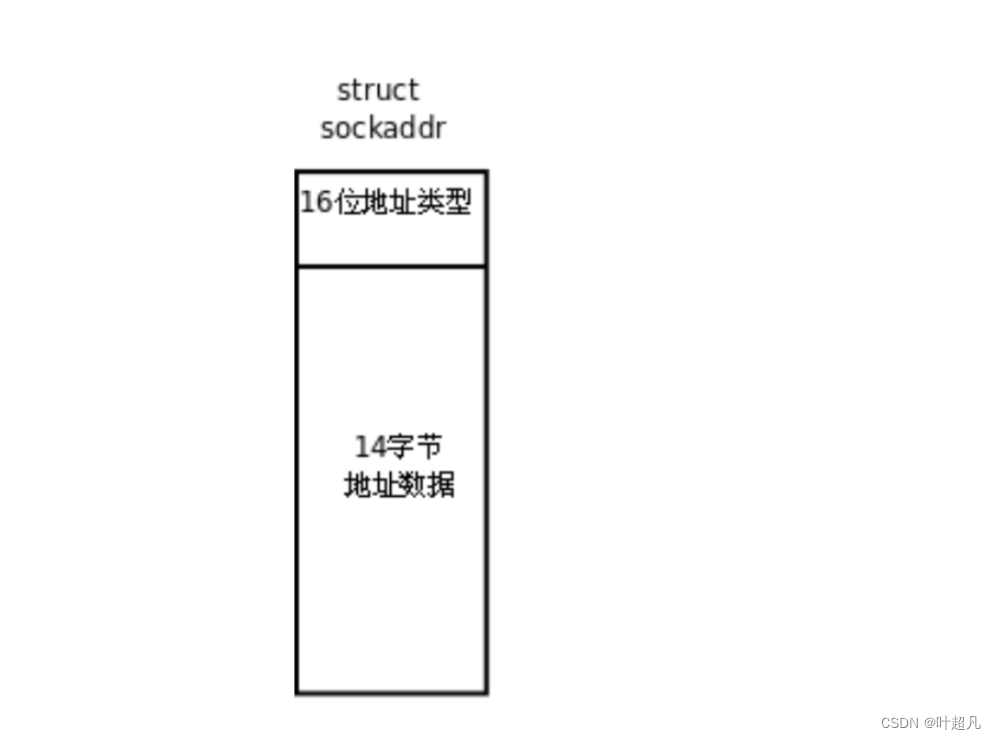
通过图片可以看到sockaddr_in和sockaddr_un的前两个字节都叫做地址类型,这个地址类型表示当前采用的是网络通信还是本地通信,也就是用AF_INET和AF_UNIX来区分我用的是sockaddr_in还是sockaddr_un,那么sockaddr也就利用了这个特性把前两个字节作为标识地址类型从而区分是sockaddr_in还是sockaddr_un,所以在使用的时候我们可以先填写的sockadd_in结构体或者sockaddr_un结构体,然后再通过强制类型转换将参数传递过去,然后在对应函数的内部查看参数的前两个字节的内容从而知道你是网络通信还是本地通信,最后再用强制类型转换的方式将指针的类型给你转换过去,那么这里的sockaddr就相当于c++中的基类,sockaddr_in和sockaddr_un就相当于是子类,通过这样的方法就可以解决参数中类型不一致的问题,可是这样的做法也许会让小伙伴感到疑问,为什么不用void来作为参数呢?而是使用两次强制类型转换呢?答案很简单因为在做这个接口的时候void还没有问世,那么这就是网络编程的预备知识。
















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











