






线性模型
线性模型:把输入的特征 x 乘上一个权重,再加上一个偏置就得到预测的结果的模型
1.分段线性曲线
Hard Sigmoid 函数的特性是当输入的值,当 x 轴的值小于某一个阈值(某个定值)的时候,大于另外一个定值阈值的时候,中间有一个斜坡。所以它是先水平的,再斜坡,再水平的。
- 所以红色线,即分段线性曲线(piecewise linear curve)可以看作是一个常数,再加上一堆蓝色的函数。分段线性曲线可以用常数项加一大堆的蓝色函数组合出来,只是用的蓝色函数不一定一样。要有很多不同的蓝色函数,加上一个常数以后就可以组出这些分段线性曲线。如果分段线性曲线越复杂,转折的点越多,所需的蓝色函数就越多。
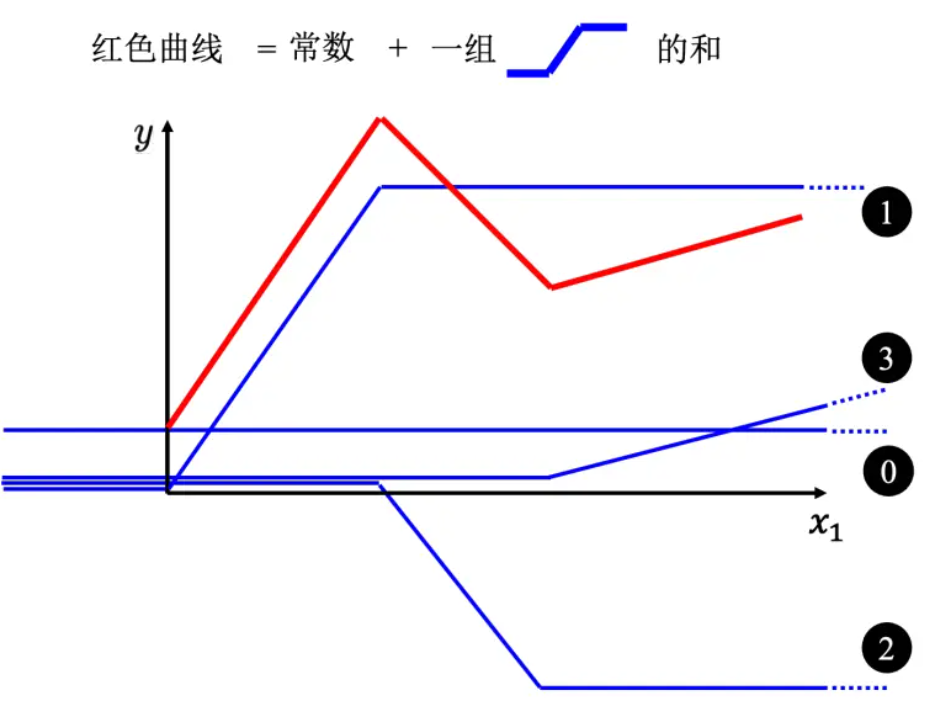
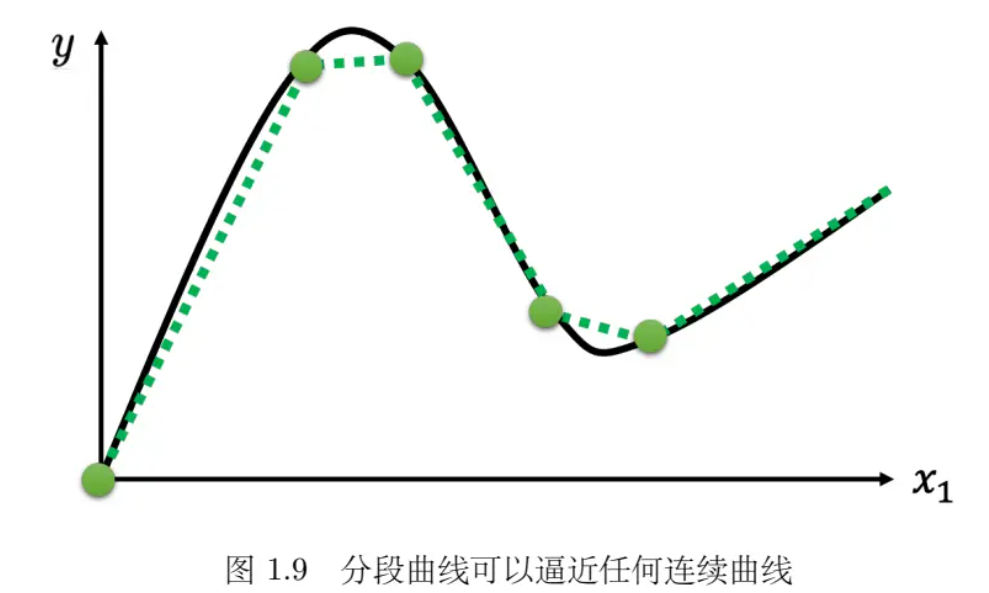
- 可以在这样的曲线上面,先取一些点,再把这些点点起来,变成一个分段线性曲线。而这个分段线性曲线跟原来的曲线,它会非常接近,如果点取的够多或点取的位置适当,分段线性曲线就可以逼近这一个连续的曲线,就可以逼近有角度的、有弧度的这一条曲线。 所以可以用分段线性曲线去逼近任何的连续的曲线,而每个分段线性曲线都可以用一大堆蓝色的函数组合起来。
- 用 Sigmoid 函数来逼近 Hard Sigmoid
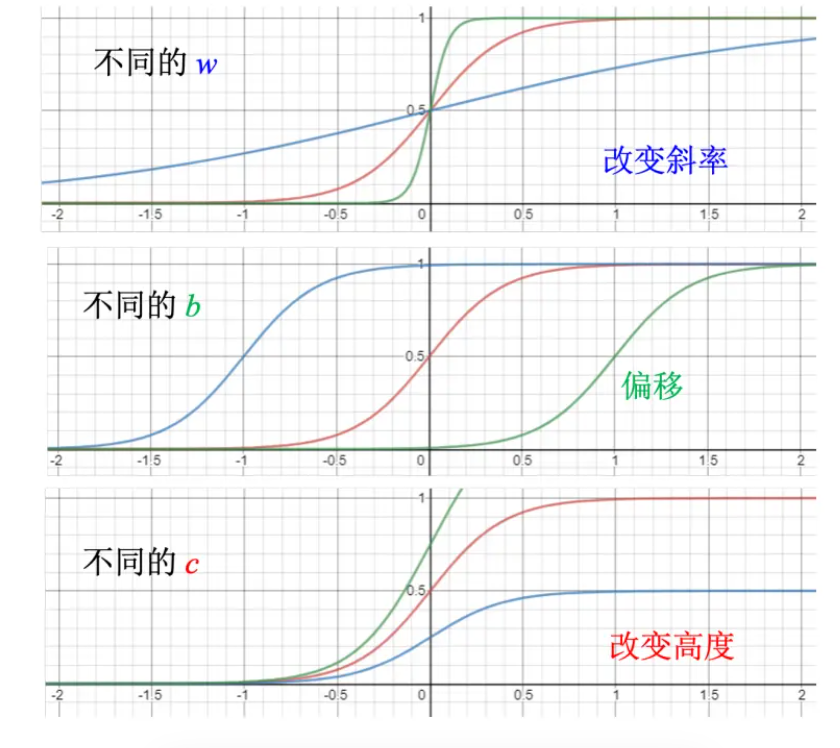
- 调整这里的 b、w 和 c 可以制造各种不同形状的 Sigmoid 函数,用各种不同形状的 Sigmoid函数去逼近 Hard Sigmoid 函数。如下图所示,如果改 w,就会改变斜率,就会改变斜坡的坡度。如果改了 b,就可以把这一个 Sigmoid 函数左右移动;如果改 c,就可以改变它的高度。所以只要有不同的 w 不同的 b 不同的 c,就可以制造出不同的 Sigmoid 函数,把不同的Sigmoid 函数叠起来以后就可以去逼近各种不同的分段线性函数;分段线性函数可以拿来近似各种不同的连续的函数。

- 定义损失
- 用 θ 来统设所有的参数,所以损失函数就变成 L(θ)。损失函数能够判断 θ 的好坏。先给定 θ 的值,即某一组 W, b, cT, b 的值,再把一种特征 x 代进去,得到估测出来的 y,再计算一下跟真实的标签之间的误差 e。把所有的误差通通加起来,就得到损失。
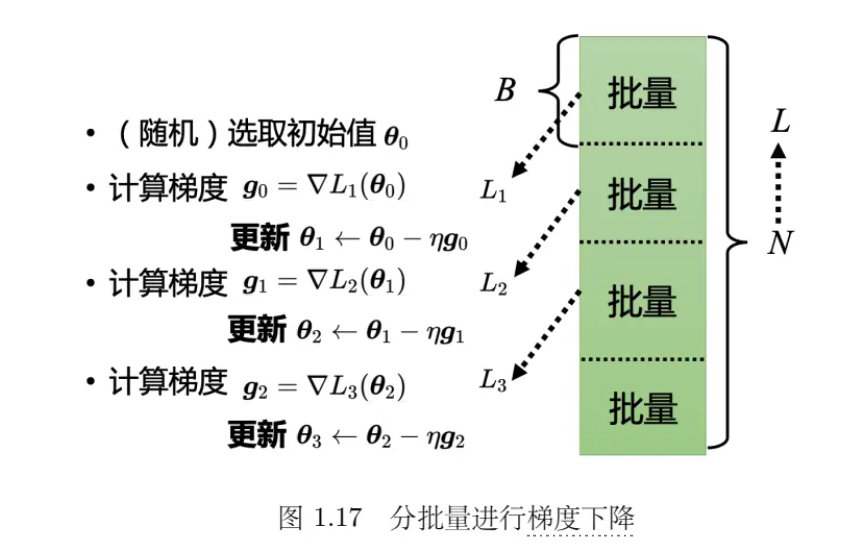
- 把 N 笔数据随机分成一个一个的批量(batch),一组一组的。每个批量里面有 B 笔数据,所以本来有 N笔数据,现在 B 笔数据一组,一组叫做批量。本来是把所有的数据拿出来算一个损失,现在只拿一个批量里面的数据出来算一个损失,记为 L1 跟 L 以示区别。假设 B 够大,也许 L 跟L1 会很接近。所以实现上每次会先选一个批量,用该批量来算 L1,根据 L1 来算梯度,再用梯度来更新参数,接下来再选下一个批量算出 L2,根据 L2 算出梯度,再更新参数,再取下一个批量算出 L3,根据 L3 算出梯度,再用 L3 算出来的梯度来更新参数。所以并不是拿 L 来算梯度,实际上是拿一个批量算出来的 L1, L2, L3 来计算梯度。把所有的批量都看过一次,称为一个回合(epoch),每一次更新参数叫做一次更新。更新跟回合是不同的东西。每次更新一次参数叫做一次更新,把所有的批量都看过一遍,叫做一个回合。更新跟回合的差别,举个例子,假设有 10000 笔数据,即 N 等于 10000,批量的大小是设 10,也就 B 等于 10。10000 个样本(example)形成了 1000 个批量,所以在一个回合里面更新了参数 1000 次,所以一个回合并不是更新参数一次,在这个例子里面一个回合,已经更新了参数 1000 次了。第 2 个例子,假设有 1000 个数据,批量大小(batch size)设 100,批量大小和 Sigmoid的个数都是超参数。1000 个样本,批量大小设 100,1 个回合总共更新 10 次参数。所以做了一个回合的训练其实不知道它更新了几次参数,有可能 1000 次,也有可能 10 次,取决于它的批量大小有多大。
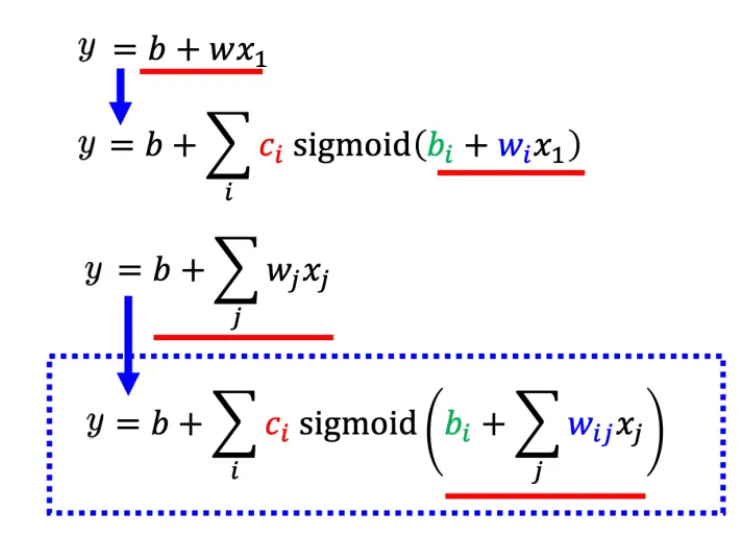
- 构建更有灵活性的函数
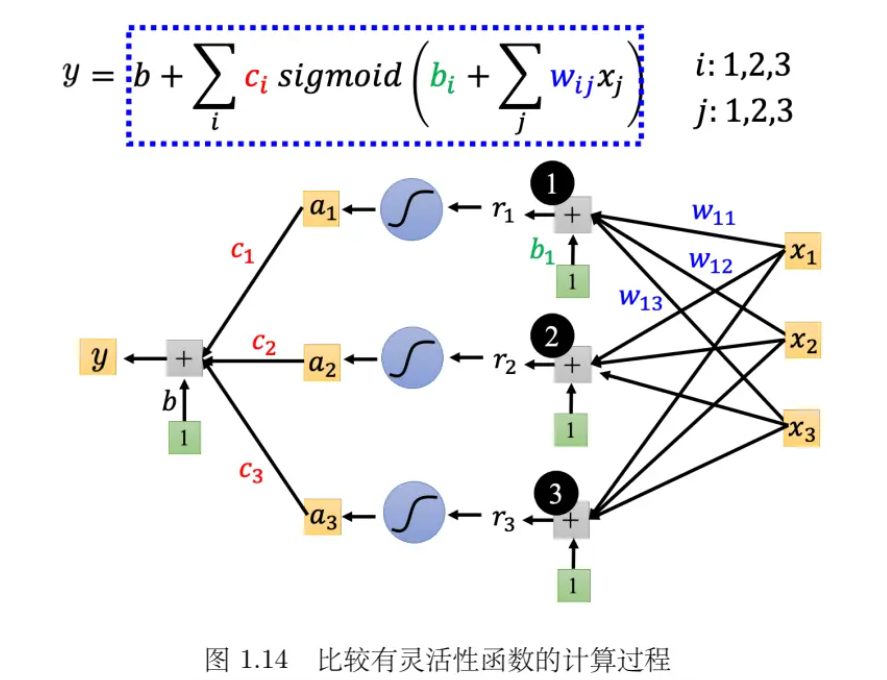
- 例子

2.模型变形
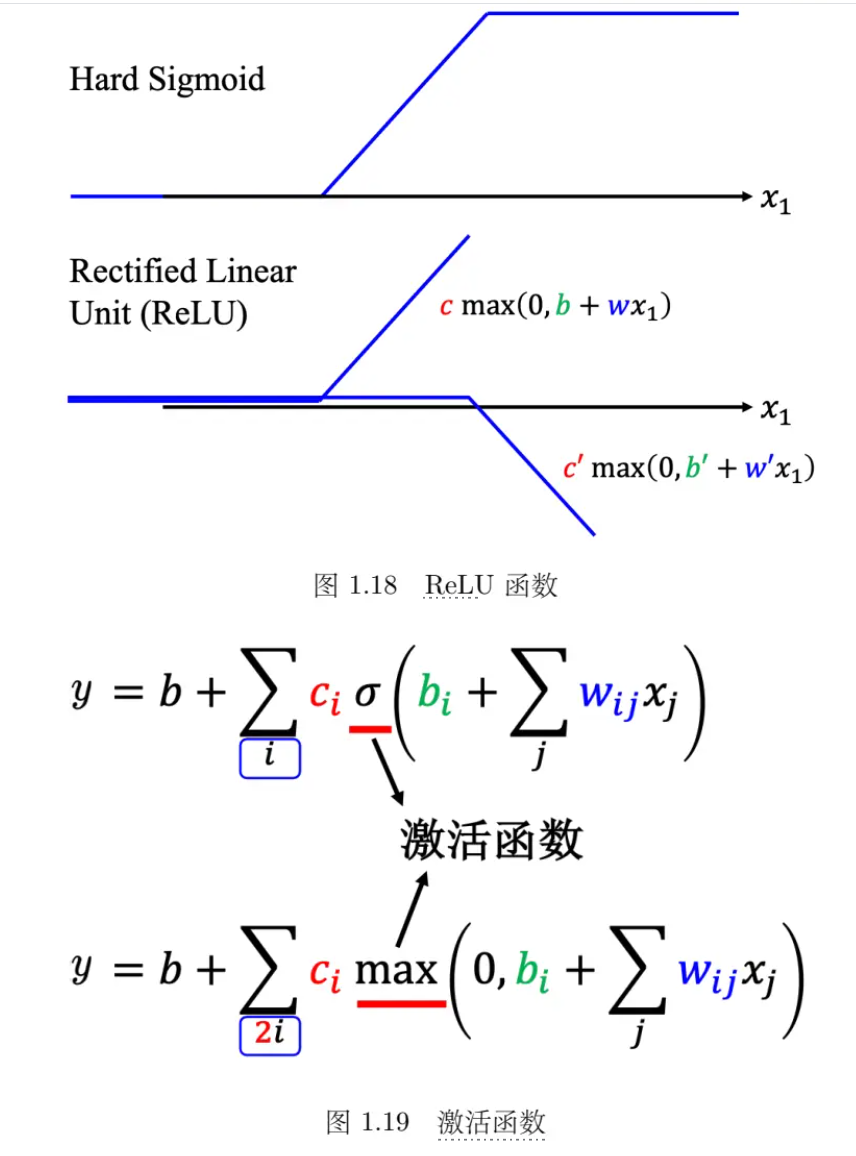
- HardSigmoid 可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的加总,ReLU 的图像有一个水平的线,走到某个地方有一个转折的点,变成一个斜坡,其对应的公式为c ∗ max(0, b + wx1)。在机器学习里面,Sigmoid 或 ReLU 称为激活函数(activation function)。
- 可以继续改模型,如下图 所示,从 x 变成 a,就是把 x 乘上 w 加 b,再通过Sigmoid 函数。不一定要通过 Sigmoid 函数,通过 ReLU 也可以得到 a,同样的事情再反复地多做几次。 所以可以把 x 做这一连串的运算产生 a,接下来把 a 做这一连串的运算产生 a′。反复地多做的次数又是另外一个超参数。注意,w, b 和 w′, b′ 不是同一个参数,是增加了更多的未知的参数。
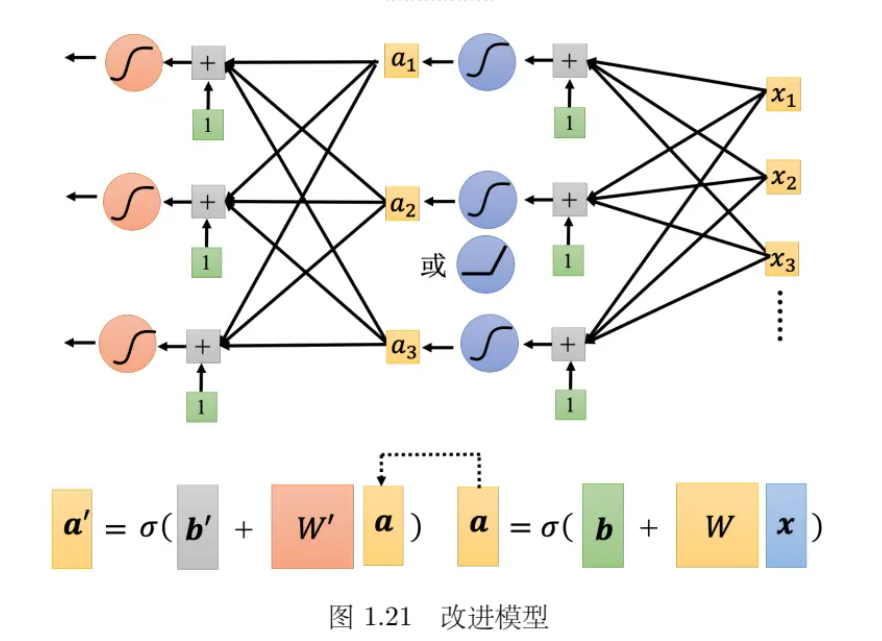
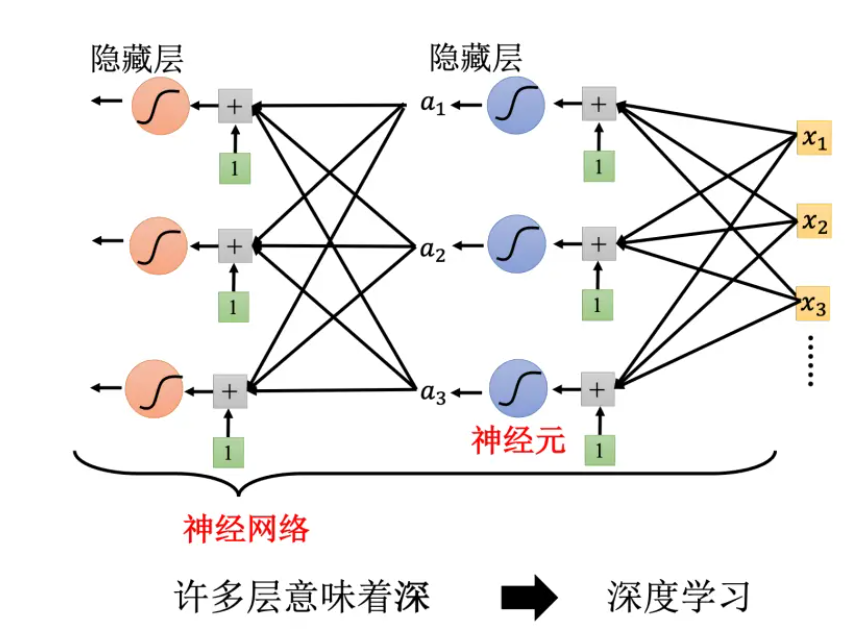
- Sigmoid 或 ReLU 称为神经元(neuron),很多的神经元称为神经网络(neural network)。人脑中就是有很多神经元,很多神经元串起来就是一个神经网络,跟人脑是一样的。人工智能就是在模拟人脑。神经网络不是新的技术,80、90 年代就已经用过了,后来为了要重振神经网络的雄风,所以需要新的名字。每一排称为一层,称为隐藏层(hiddenlayer),很多的隐藏层就“深”,这套技术称为深度学习。
- 过拟合
- 当机器学习模型在训练数据集上表现很好,但在新的、未见过的数据上表现很差时,我们就说这个模型发生了过拟合。过拟合的模型对训练数据的细节和噪声过于敏感,以至于它失去了对新数据的泛化能力。
3.机器学习框架
- 训练集就要拿来训练模型,训练的过程是 3 个步骤。
- 1. 先写出一个有未知数 θ 的函数,θ 代表一个模型里面所有的未知参数。fθ(x) 的意思就是函数叫 fθ(x),输入的特征为 x,;
- 2. 定义损失,损失是一个函数,其输入就是一组参数,去判断这一组参数的好坏;
- 3. 解一个优化的问题,找一个 θ,该 θ 可以让损失的值越小越好。让损失的值最小的 θ 为θ∗,即θ∗ = arg{minθ(L)}
- 有了 θ∗ 以后,就把它拿来用在测试集上,也就是把 θ∗ 带入这些未知的参数,本来 fθfθ(x)里面有一些未知的参数,现在 θ 用 θ∗ 来取代,输入是测试集,输出的结果存起来。
















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









