






实践方法论
目录
k 折交叉验证(k-foldcross validation)
1.模型偏差
- 模型偏差可能会影响模型训练。
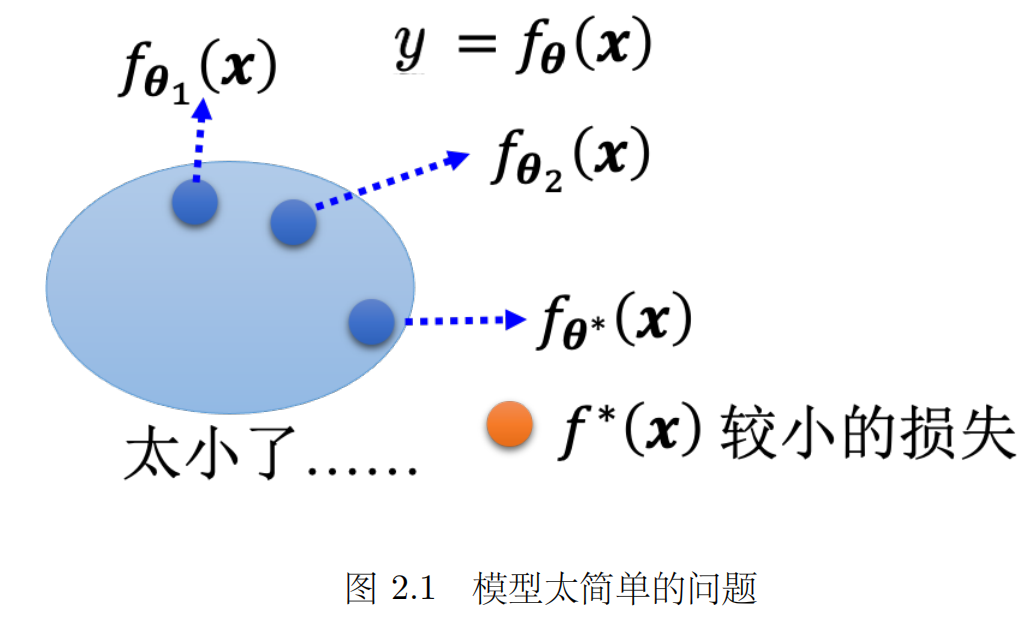
- 举个例子,假设模型过于简单,一个有未知参数的函数代θ1 得到一个函数 fθ1(x),同理可得到另一个函数 fθ2(x),把所有的函数集合起来得到一个函数的集合。但是该函数的集合太小了,没有包含任何一个函数,可以让损失变低的函数不在模型可以描述的范围内。在这种情况下,就算找出了一个 θ ∗,虽然它是这些蓝色的函数里面最好的一个,但损失还是不够低。这种情况就是想要在大海里面捞针(一个损失低的函数),结果针根本就不在海里。
- 这个时候重新设计一个模型,给模型更大的灵活性。如果模型的灵活性不够大,可以增加更多特征,可以设一个更大的模型,可以用深度学习来增加模型的灵活性,这是第一个可以的解法。但是并不是训练的时候,损失大就代表一定是模型偏差,可能会遇到另外一个问题:优化做得不好。
2.优化问题
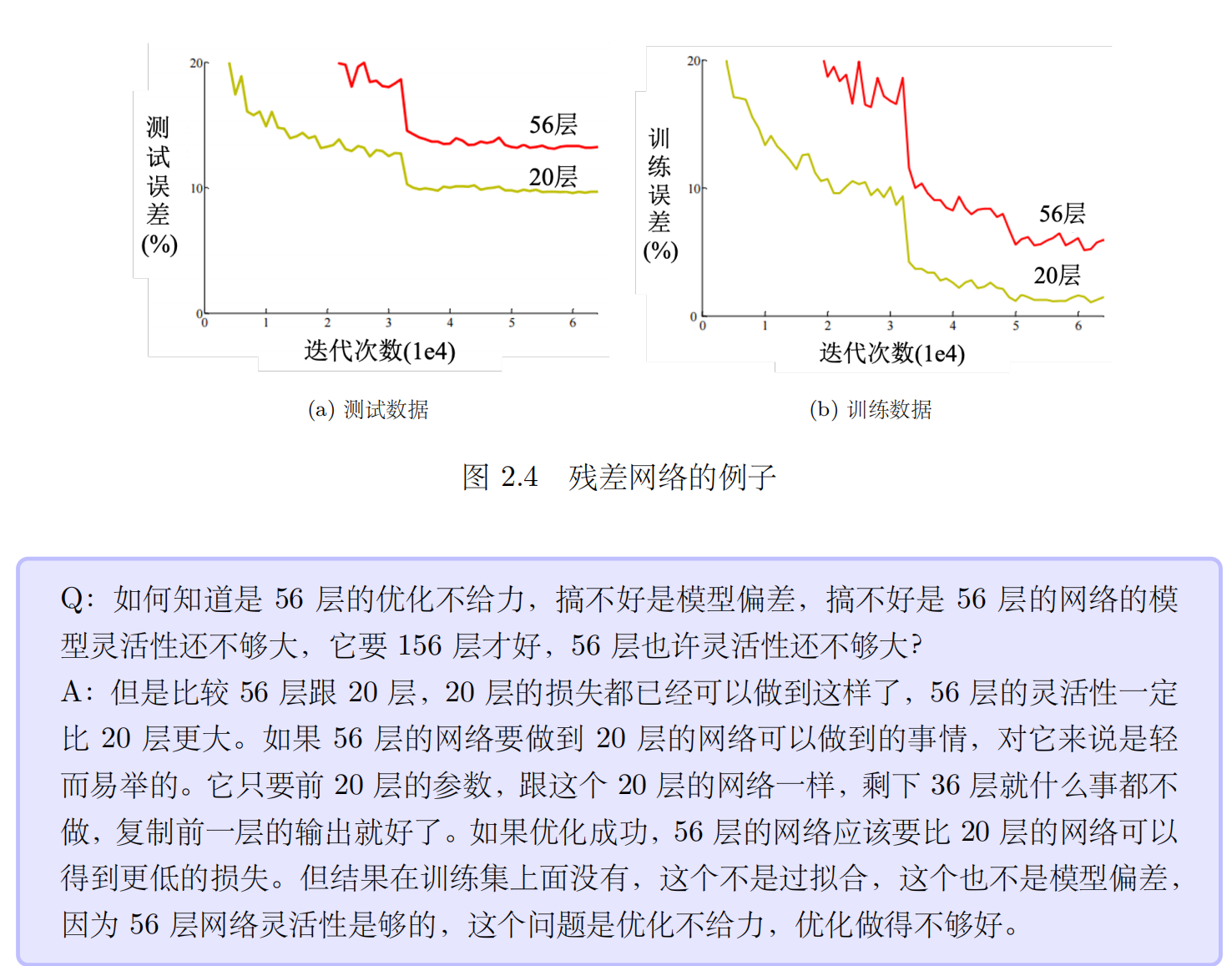
- 一般只会用到梯度下降进行优化,这种优化的方法很多的问题。比如可能会卡在局部最小值的地方,无法找到一个真的可以让损失很低的参数。
- 梯度下降这一个算法无法找出损失低的函数,梯度下降是解一个优化的问题,找到 θ ∗ 就结束了。但 θ ∗ 的损失不够低。这个模型里面存在着某一个函数的损失是够低的,梯度下降没有给这一个函数。这就像是想大海捞针,针确实在海里,但是无法把针捞起来。训练数据的损失不够低的时候,到底是模型偏差,还是优化的问题呢。找不到一个损失低的函数,到底是因为模型的灵活性不够,海里面没有针。还是模型的灵活性已经够了,只是优化梯度下降不给力,它没办法把针捞出来 到底是哪一个。
- 但如果训练数据上面的损失小,测试数据上的损失大,可能是真的过拟合。在测试上的结果不好,不一定是过拟合。要把训练数据损失记下来,先确定优化没有问题,模型够大了。接下来才看看是不是测试的问题,如果是训练损失小,测试损失大,这个有可能是过拟合。

3.过拟合
- 怎么解决过拟合的问题呢,有两个可能的方向:
- 第一个方向是往往是最有效的方向,即增加训练集。可以做数据增强(data augmentation,),这个方法并不算是使用了额外的数据。
- 数据增强就是根据问题的理解创造出新的数据。举个例子,在做图像识别的时候,常做的一个招式是,假设训练集里面有某一张图片,把它左右翻转,或者是把它其中一块截出来放大等等。对图片进行左右翻转,数据就变成两倍。但是数据增强不能够随便乱做。在图像识别里面,很少看到有人把图像上下颠倒当作增强。因为这些图片都是合理的图片,左右翻转图片,并不会影响到里面的内容。但把图像上下颠倒,可能不是一个训练集或真实世界里面会出现的图像。如果给机器根据奇怪的图像学习,它可能就会学到奇怪的东西。所以数据增强,要根据对数据的特性以及要处理的问题的理解,来选择合适的数据增强的方式。
- 另外一个解法是给模型一些限制,让模型不要有过大的灵活性。
- 解决过拟合的问题,要给模型一些限制,最好模型正好跟背后产生数据的过程,过程是一样的就有机会得到好的结果。
- 给模型制造限制可以有如下方法:给模型比较少的参数。如果是深度学习的话,就给它比较少的神经元的数量,本来每层一千个神经元,改成一百个神经元之类的,或者让模型共用参数,可以让一些参数有一样的数值。全连接网络(fully-connected network)其实是一个比较有灵活性的架构,而卷积神经网络(Convolutional Neural Network,CNN)是一个比较有限制的架构。CNN 是一种比较没有灵活性的模型,其是针对图像的特性来限制模型的灵活性。所以全连接神经网络,可以找出来的函数所形成的集合其实是比较大的,CNN 所找出来的函数,它形成的集合其实是比较小的,其实包含在全连接网络里面的,但是就是因为CNN 给了,比较大的限制,所以 CNN 在图像上,反而会做得比较好。
- 这边产生了一个矛盾的情况,模型的复杂程度,或这样让模型的灵活性越来越大。但复杂的程度和灵活性都没有给明确的定义。比较复杂的模型包含的函数比较多,参数比较多。如下图所示,随着模型越来越复杂,训练损失可以越来越低,但测试时,当模型越来越复杂的时候,刚开始,测试损失会跟著下降,但是当复杂的程度,超过某一个程度以后,测试损失就会突然暴增了。这就是因为当模型越来越复杂的时候,复杂到某一个程度,过拟合的情况就会出现,所以在训练损失上面可以得到比较好的结果。在测试损失上面,会得到比较大的损失,可以选一个中庸的模型,不是太复杂的,也不是太简单的,刚刚好可以在训练集上损失最低,测试损失最低。

4.交叉验证
- 比较合理选择模型的方法是把训练的数据分成两半,一部分称为训练集(training set),一部分是验证集(validation set)。比如 90% 的数据作为训练集,有 10% 的数据作为验证集。在训练集上训练出来的模型会使用验证集来衡量它们的分数,根据验证集上面的分数去挑选结果
k 折交叉验证(k-foldcross validation)
- k 折交叉验证就是先把训练集切成 k 等份。在这个例子,训练集被切成 3 等份,切完以后,拿其中一份当作验证集,另外两份当训练集,这件事情要重复 3 次。即第一份第 2 份当训练,第 3 份当验证;第一份第 3 份当训练,第 2 份当验证;第一份当验证,第 2 份第 3 份当训练5.不匹配

5.不匹配
- 不匹配跟过拟合其实不同,一般的过拟合可以用搜集更多的数据来克服,但是不匹配是指训练集跟测试集的分布不同,训练集再增加其实也没有帮助了。
- 增加数据也不能让模型做得更好,所以这种问题要怎么解决,匹不匹配要看对数据本身的理解了,我们可能要对训练集跟测试集的产生方式有一些理解,才能判断它是不是遇到了不匹配的情况。















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









