






ps:本人小白,勿喷,写文章太难了
一、背景
一时兴起与代码练习
二、目标:
主要了解各个人物重要性,主要以文本出现次数为指标
三、主要操作流程
1、通过爬虫从网站中获取三国演义的文本信息
url:https://www.shicimingju.com/book/sanguoyanyi.html
2、使用jupyter notebook进行数据分析
四、分维度统计
1、对各个词语的出现次数进行统计并绘制词云图
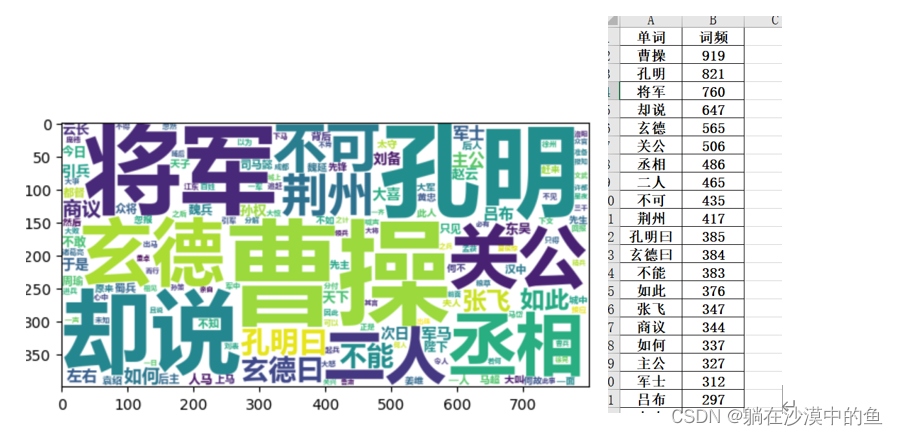
(1)人物方面
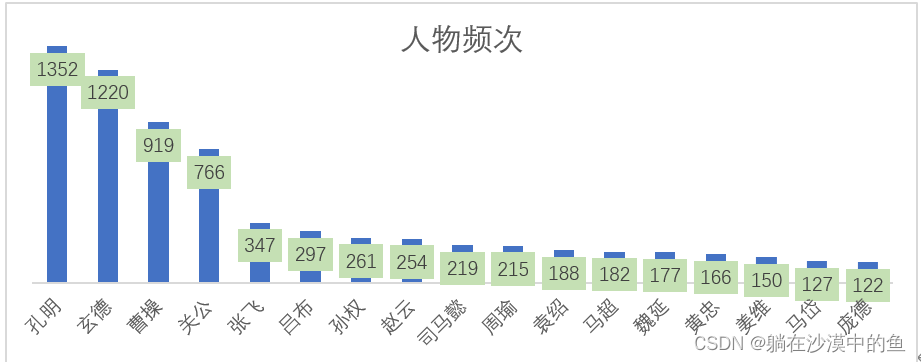
① 结合实际词频发现:孔明的出场频次实际为1352次(孔明821次,孔明曰385次,诸葛亮146次),玄德的出场频次实际为1220次(分别是玄德565次,玄德曰384次,刘备271次),曹操位列第三,为919次
结果是:孔明>刘备>曹操
ps:因单词中出现将军、丞相等名词不易分类,因此暂以忽略处理
② 孔明和玄德的出场部分携带“曰”字,侧面可以说明其长者的身份
附:前100个的词频单词中的人物
(2)地名方面
针对词频前100个的单词,筛选出具备地理意义的单词
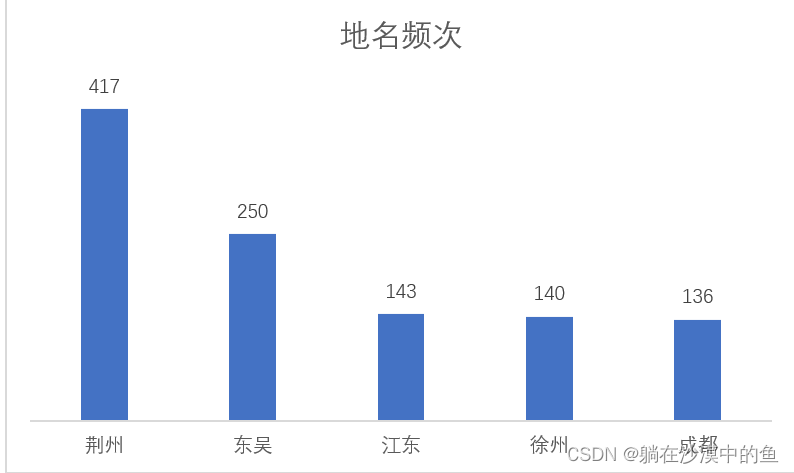
文章中,荆州是出现频率较高的地名,可以侧面说明三国演义中荆州其重要的战略地理意义
附一下爬虫代码:
from bs4 import BeautifulSoup
import requests
import pandas as pd
headers = {
'User-Agent':''
}
#首页地址
main_url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
#发起请求,获取了主页页面源码
response = requests.get(url=main_url,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
#数据解析:章节标题+详情页链接
soup = BeautifulSoup(page_text,'lxml')
a_list = soup.select('.book-mulu > ul > li > a')
fp = open('./sanguo.txt','w',encoding='utf-8')
data_dict = {}
for a in a_list:
title = a.string #章节标题
detail_url = 'https://www.shicimingju.com'+a['href'] #详情页地址
#请求详情页的页面源码数据
response = requests.get(url=detail_url,headers=headers)
response.encoding = 'utf-8'
detail_page_text = response.text
#解析:解析章节内容
d_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = d_soup.find('div',class_='chapter_content')
content = div_tag.text #章节内容
fp.write(title+':'+content+'\n')
print(title,'爬取保存成功!')
data_dict[title] = content
fp.close()
data_last = pd.DataFrame(data_dict)
data_last.to_excel('sanguo.xlsx')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









