






目录
在正式讲解实战之前,还得进行一波理论了解,这样才能事半功倍。
1. HTTP请求
首先我们先了解http(https)的请求形式。
请求由客户端向服务端发出,可以分为 4 部分内容:请求方法(Request Method)、请求的网址 (Request URL)、请求头(Request Headers)、请求体(Request Body)。
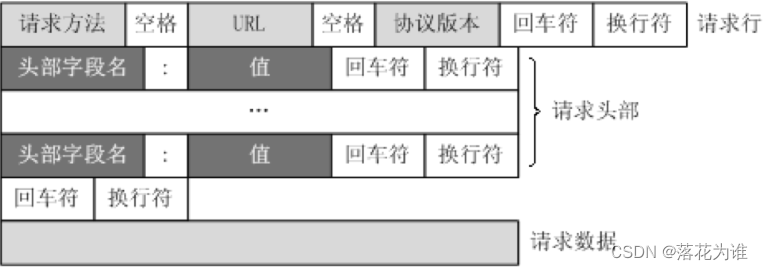
那么我们该如何构造请求呢?这时候我们就要使用socket了(当然requests请求是最方便的,因为它进行了底层封装)。
2.那什么是socket呢?
默认大家都了解过socket,这里就不加赘述了。当然如果不了解的话,下面也有参考文章帮助大家了解。
参考:socket编程入门:1天玩转socket通信技术(非常详细)
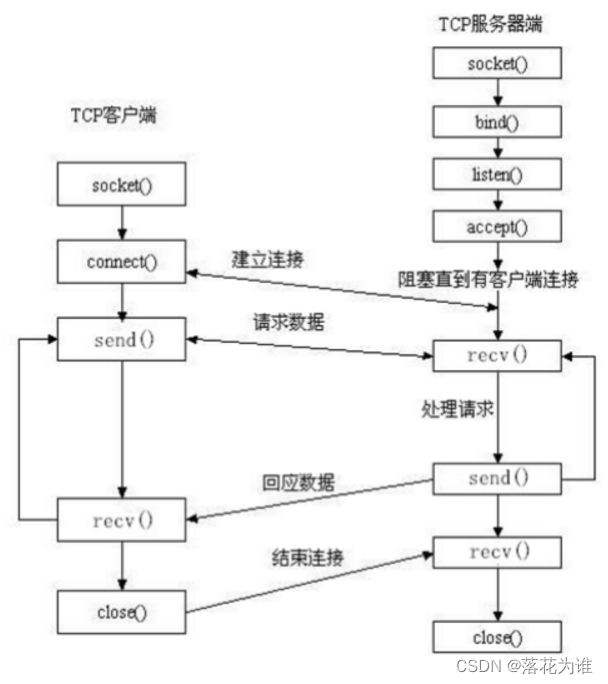
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
三次握手 四次挥手参考: 三次握手和四次挥手知识总结(超详细)-云社区-华为云 (huaweicloud.com)
如下图
| 方法 | 描述 |
|---|---|
| connect( (host,port) ) | host代表服务器主机名或IP,port代表服务器进程所绑定的端口号。 |
| send | 发送请求信息 |
| recv | 接收数据 |
3.使用sockt下载http类型图片
代码如下:
import socket
import re
# 获取到资源地址
url = 'http://image11.m1905.cn/uploadfile/2021/0922/thumb_0_647_500_20210922030733993182.jpg'
# 创建套接字对象
client = socket.socket()
# 创建连接
client.connect(('image11.m1905.cn', 80)) #http默认是80端口,https默认是443端口
# 构造http请求
http_res = 'GET ' + url + ' HTTP/1.0\r\nHost: image11.m1905.cn\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36\r\n\r\n'
# 发送请求
client.send(http_res.encode())
# 建立一个二进制对象用来存储我们得到的数据
result = b''
data = client.recv(1024)
# 循环接收响应数据 添加到bytes类型
while data:
result += data
data = client.recv(1024)
print(result)
# 提取数据
# re.S使 . 匹配包括换行在内的所有字符 去掉响应头
images = re.findall(b'\r\n\r\n(.*)', result, re.S) #返回一个列表
# print(images[0])
# 打开一个文件,将我们读取到的数据存入进去,即下载到本地我们获取到的图片
with open('小姐姐.png', 'wb')as f:
f.write(images[0])
client.close() #关闭套接字其中\r是回车符,\n是换行符。
效果图如下:

如果你对HTTP不同版本的协议不清楚,可以参考我的一篇文章。HTTP详解_落花为谁的博客-CSDN博客
注意:HTTP1.0和HTTP1.1协议都支持长连接(Keep-Alive)。在HTTP1.0中,需要在请求头中添加"Connection: keep-alive"字段才能够启用长连接。而在HTTP1.1中,默认启用长连接,也就是说,当客户端发送一个请求后,TCP连接不会立即关闭,而是保持连接状态等待服务器响应。如果客户端想要关闭连接,则需要在HTTP请求报文头部中添加"Connection: close"字段。这样,在服务器发送完响应后,TCP连接会被关闭,客户端就知道响应已经完成了,可以继续发送下一个请求。但是,关闭连接意味着需要重新建立连接,这会对性能产生一定影响。
4.使用socket下载https类型图片
代码如下:
import socket
import re
class GetImage:
def __init__(self):
pass
def main(self, url):
# 创建套接字对象
client = socket.socket() # 默认TCP
# 创建连接
client.connect(('pic.netbian.com', 80))
# 构造https请求
http_res = 'GET ' + url + ' HTTP/1.0\r\nHost: pic.netbian.com\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36\r\n\r\n'
client.send(http_res.encode())
result = b''
data = client.recv(1024)
while data:
result += data
data = client.recv(1024)
# 提取数据
# re.S使 . 匹配包括换行在内的所有字符 去掉响应头
image = re.findall(b'\r\n\r\n(.*)', result, re.S)
filename = url.split('/')[-1]
# 保存数据
with open(filename, 'wb') as f:
f.write(image[0])
# 关闭套接字
client.close()
if __name__ == '__main__':
url_list = ['https://pic.netbian.com/uploads/allimg/230327/194745-16799176658fd9.jpg',
'https://pic.netbian.com/uploads/allimg/230303/004437-1677775477ee49.jpg',
'https://pic.netbian.com/uploads/allimg/230411/225955-16812251959808.jpg'
]
getimage = GetImage()
for url in url_list:
getimage.main(url)成功下载
相信大家已经注意到了,这次我们请求的是https类型图片,但是我们用的还是80端口,不应该用443端口吗,这是为什么呢?
注意:https是兼容http80端口的,所以使用80端口,你会发现是可以正常获取数据的,但是如果直接使用443端口,反而会报错。大家可以自行尝试。
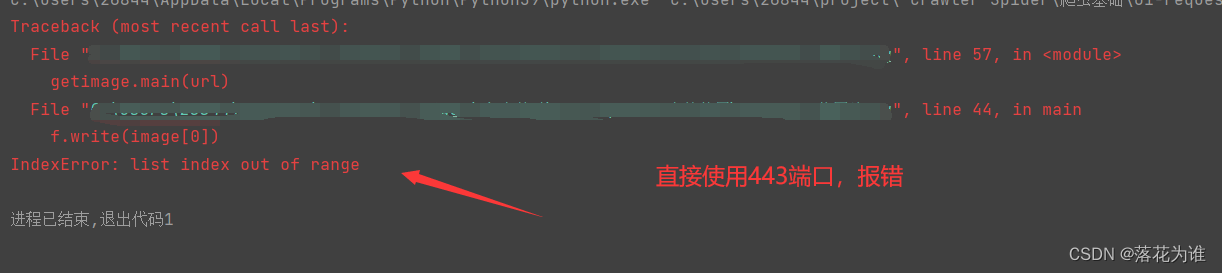
这是为什么呢?
因为https需要使用TLS/SSL进行加密通信。因此我们如果一定要使用443端口,可以采取以下办法。
导入ssl包就可正常解决了,具体如下:
import ssl
# 创建套接字对象
client = socket.socket() # 默认TCP
# 创建SSL上下文
ssl_context = ssl.create_default_context()
# 建立加密连接
client = ssl_context.wrap_socket(client, server_hostname='pic.netbian.com')
# 连接服务器
client.connect(('pic.netbian.com', 443))只要加上上述代码,剩下的都是相同的代码逻辑,就可以正常获取到图片了。
拓展:
TLS(Transport Layer Security)和SSL(Secure Sockets Layer)是用于保护网络通信安全的协议。TLS是SSL的继任者,TLS和SSL都是在传输层(Transport Layer)提供安全性,用于保护数据在网络中的传输过程中不被窃听、篡改或伪造。
TLS/SSL协议基于公钥加密、私钥解密和数字签名技术,使用 X.509 数字证书进行身份验证和密钥交换,同时还支持对数据进行完整性验证和加密。在TLS/SSL协议下,客户端和服务器之间的通信会被加密并且数据传输是安全的。
TLS/SSL协议广泛应用于Web上的数据传输,如网银交易、电子邮件、在线购物等场景。常见的使用TLS/SSL的应用程序包括HTTPS、FTP、SMTP、POP3等。
需要注意的是,TLS和SSL虽然是不同的协议,但是它们的目标和设计原理基本相同,所以在实际应用中常常被一起提及。
今天的分享就到此,希望能够让你对socket有更深的理解。















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









