






目录
变量:存储单个元素的内存空间
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
一、数组的概念
数组是存放相同类型数据的集合,在内存中开辟了连续的空间,通常配合循环使用
二、数组的分类
普通数组:不需要声明直接定义,下标索引只能是整数
关联数组:需要用declare -A声明否则系统不识别,索引可以是字符串
三、数组名和索引
索引的编号(下标)从0开始,属于数值索引
索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash 4.0版本之后开始支持bash的数组支持稀疏格式(索引不连续)
四、数组的格式
1、数组的定义
①直接把要加入数组的元素用小括号括起来,中间用空格分开
第一种
格式: 数组名=(value0 value1 value2)
例如:num=(10 20 30 40)

②精确的给每一个下表索引定义一个值加入数组,索引数字可以不连续
第二种
格式: 数组名=([0]=value [1]=value [2]=value...)
例如: num=([0]=10 [1]=20 [2]=30 [3]=40)

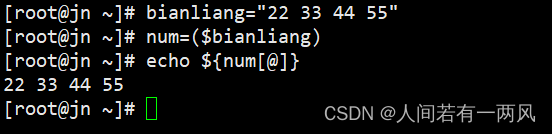
③先把要加入数组的元素全部先赋值给一个变量,然后引用这个变量加入到数组
第三种
格式: 变量= "value0 value1 value2 value3"
数组=($列表名)
例如:
list= "10 20 30 40"
num=($list)
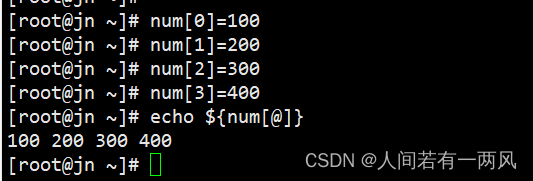
④直接定义数组索引对应的的元素
格式: 数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
例如: num[0]="10" num[1]="20" num[2]="30"
定义数组最简单的办法就是:a=(10 20 30 40)
读取数组中的全部长度使用:echo ${#a[*/@]}
读取数组中的下标对应的元素长度: echo ${#a[下标]}
读取数组中的全部内容使用:echo ${a[*/@]}
读取数组中的下标对应的元素内容: echo ${a[下标]}
2、获取数组列表

3、获取数组长度
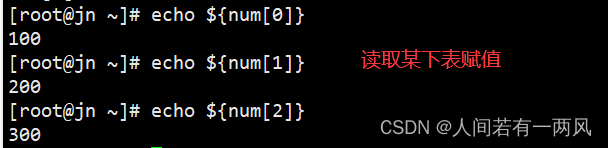
 4、读取某下标赋值
4、读取某下标赋值
5、数组遍历
使用for循环。遍历输出数组中的每一个元素

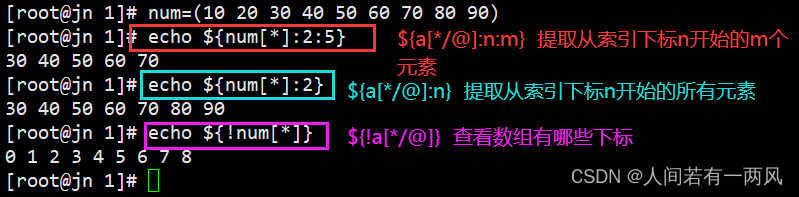
6、数组元素的切片
${a[*]:n:m} 提取从索引下标n开始的m个元素
${a[*]:n} 提取从索引下标n开始的所有元素
${!a[*]} 查看数组有哪些下标
7、数组元素的临时替换
${a[*]/n/m} 将a数组中的元素中有n字符串的替换为m字符串,如果一个元素有多个n字符串只替换一次
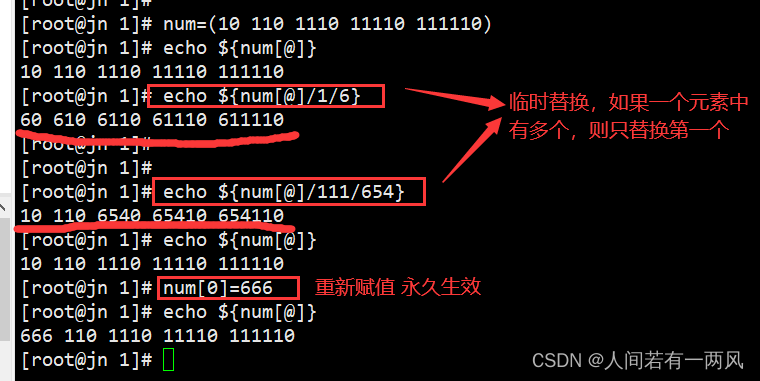
8、数组的删除 unset
a=(45 10 100 1000 20 30)
unset a //删除数组
a=(45 10 100 1000 20 30)
unset a[3] //删除数组第3个元素

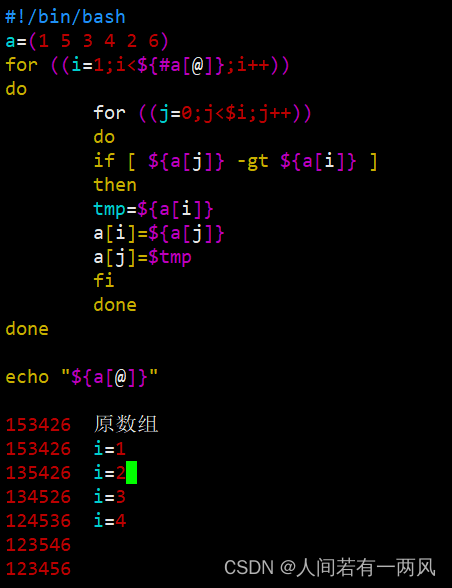
五、冒泡数组
数组排序算法:冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









