





段落开头这个颜色表示不重要,这个颜色表示重要
Code and data are available at here
ABSTRACT
As social media platforms are evolving from text-based forums into multi-modal environments, the nature of misinformation in social media is also transforming accordingly. Misinformation spreaders have recently targeted contextual connections between the modalities e.g., text and image. However, existing datasets for rumor detection mainly focus on a single modality i.e., text. To bridge this gap, we construct MR2 , a multimodal multilingual retrievalaugmented dataset for rumor detection. The dataset covers rumors with images and texts , and provides evidence from both modalities that are retrieved from the Internet. Further, we develop established baselines and conduct a detailed analysis of the systems evaluated on the dataset. Extensive experiments show that MR2 will provide a challenging testbed for developing rumor detection systems designed to retrieve and reason over social media posts. Source code and data are available at: https://github.com/THU-BPM/MR2.
随着社交媒体平台从基于文本的论坛发展为多模式环境,社交媒体中的错误信息的性质也相应发生了变化。错误信息的传播者最近针对模态之间的上下文连接,例如文本和图像。然而,现有的谣言检测数据集主要集中在单一模态,即文本。为了填补这一空白,我们构建了 MR2,这是一个用于谣言检测的多模态多语言检索增强数据集。该数据集涵盖了带有图像和文本的谣言,并提供了从互联网检索得到的两种模态的证据。此外,我们开发了已建立的基线,并对在该数据集上评估的系统进行了详细分析。大量实验表明,MR2将为开发旨在检索和推理社交媒体帖子的谣言检测系统提供一个具有挑战性的测试平台。源代码和数据可在以下网址获得:https://github.com/THU-BPM/MR2。
1.INTRODUCTION
Nowadays, billions of multimodal posts containing texts, images, and videos are shared throughout the Internet, mainly via social media. Misleading rumors circulated in these platforms are not limited to one specific modality, despite the majority of existing efforts for rumor detection focusing on textual data [2, 42, 74]. It is more challenging to detect rumors presented in different modalities, as it necessitates the evaluation of each modality and the credibility of the combination [1, 6, 53]. For instance, consider the anti-vaccination tweet in Figure 1: the text reads “COVID vaccines do this”, and an image of a dead person is attached. Although the image and text are not individually misinformative, combined they create misinformation.
如今,数十亿包含文本、图像和视频的多模态帖子通过互联网传播,主要通过社交媒体。在这些平台上流传的误导性谣言不局限于一种特定的模态,尽管大多数现有的谣言检测工作都集中在文本数据上。检测以不同模态呈现的谣言更具挑战性,因为它需要评估每种模态及其组合的可信度。例如,考虑图1中的反疫苗推文:文本写着“COVID疫苗做这个”,并附有一张死人的图片。虽然单独的图像和文本并不具有误导性,但它们组合在一起就会产生错误信息。

Datasets for rumor detection often focus on a single modality, such as text [10, 14, 35, 72, 76], thus missing crucial information conveyed by other modalities. There are a few multimodal datasets for rumor detection [8, 23, 42, 71] available, but these datasets are usually small or contain limited evidence such as metadata. Machine-generated texts or manipulated images can be detected based on their contents [63, 69]. However, identifying mismatched image-text pairs requires understanding across the same and different modalities. A rumor detection system that only models the content of the post may not be able to determine its veracity, while incorporating additional metadata (e.g. number of reposts, comments) is helpful but not sufficient to provide grounding evidence for the post [74, 76].
谣言检测数据集通常侧重于单一模态,比如文本,因此错过了其他模态传达的关键信息。有一些多模态谣言检测数据集可用,但这些数据集通常较小或包含有限的证据,如元数据。机器生成的文本或被篡改的图像可以根据其内容进行检测。然而,识别不匹配的图像-文本对需要跨同一和不同的模态进行理解。一个仅对帖子内容建模的谣言检测系统可能无法确定其真实性,而同时纳入额外的元数据(例如转发次数、评论)虽然有所帮助,但不足以为帖子提供基础证据。
To bridge this gap, we propose a novel approach that incorporates retrieved texts and images as evidence for better misinformation detection. As shown in Figure 2, we first use the image in the post to find its other occurrences via reverse image search. We then retrieve the textual evidence (i.e., descriptions) and compare it against the text in the post. Similarly, we use the text to find other images as visual evidence. Retrieving evidence from the Internet incorporates world knowledge that helps to detect well-presented misinformation. For example, the textual evidence in Figure 2 indicates that the image is mainly about the outbreak in New York, which has no connection to the COVID vaccines. The visual evidence illustrates how the vaccine functions rather than causing death. Our approach can be applied for early detection since retrieved texts and images do not rely on the proliferation(扩散) process over time as social context (e.g., metadata, comments). To verify the effectiveness of the proposed formulation, we constructed a sizable multimodal dataset MR2 , which consists of 14,700 English and Chinese posts with textual and visual evidence retrieved from the Internet. To characterize the challenge of the dataset presented, we conducted a thorough analysis and demonstrated the utility of the dataset by developing established baselines. Our key contributions are summarized as:
• We incorporate the retrieved multimodal evidence for detection. Compared with prior efforts, ours is better resilient to mismatched rumors and amenable to early detection.
• We construct a sizable multimodal dataset that consists of 14,700 real-world English and Chinese posts with textual and visual evidence retrieved from the Internet.
• We develop established baselines and conduct a detailed analysis of the systems evaluated on the dataset, identifying challenges that need to be addressed in future research.
为了弥补这一差距,我们提出了一种新颖的方法,将检索到的文本和图像作为证据,以更好地检测错误信息。如图2所示,我们首先使用帖子中的图像通过反向图像搜索找到其其他出现位置。然后,我们检索文本证据(即描述),并将其与帖子中的文本进行比较。类似地,我们使用文本来查找其他图像作为视觉证据。从互联网检索证据涵盖了有助于检测错误信息的世界知识。例如,图2中的文本证据表明该图像主要与纽约的爆发有关,与COVID疫苗无关。视觉证据说明了疫苗的功能,而不是导致死亡。我们的方法可用于早期检测,因为检索到的文本和图像不依赖于社交上下文(例如元数据、评论)随时间的传播过程。为了验证所提出的公式的有效性,我们构建了一个规模可观的多模态数据集 MR2,其中包含了来自互联网的 14,700 条英文和中文帖子,具有文本和视觉证据。为了描述数据集所面临的挑战,我们进行了彻底的分析,并通过开发已建立的基线来展示数据集的实用性。我们的主要贡献总结如下:
• 我们将检索到的多模态证据纳入检测。与先前的努力相比,我们的方法对不匹配的谣言更具弹性,易于早期检测。
• 我们构建了一个规模可观的多模态数据集,包括了 14,700 条来自真实世界的英文和中文帖子,具有从互联网检索的文本和视觉证据。
• 我们开发了已建立的基线,并对在数据集上评估的系统进行了详细分析,确定了未来研究需要解决的挑战。
2 RELATED WORK
2.1 Rumor Detection Datasets
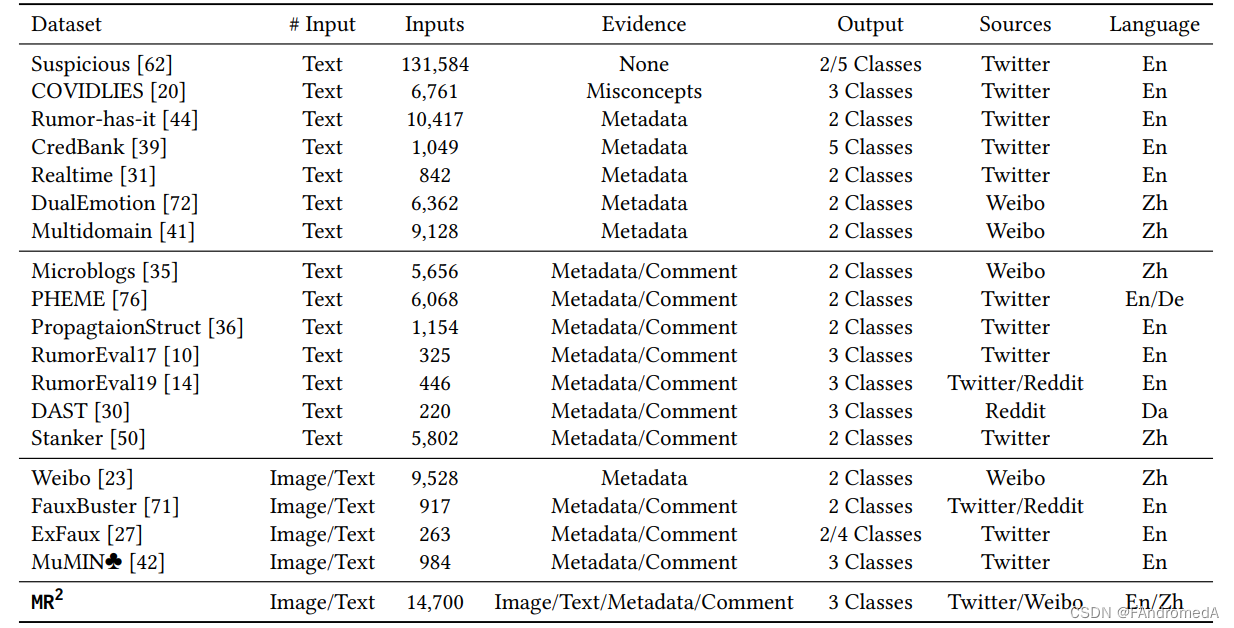
We review the existing rumor detection dataset as summarized in Table 1. As shown in the table, most existing datasets focus on rumors that only contain textual statements. Early efforts in rumor detection do not use any evidence beyond the textual content itself [62]. Content-based approaches that only rely on linguistic (lexical and syntactical) features are applied to capture deceptive cues or writing styles to detect rumors. However, many linguistic features are language-dependent, limiting the generality of these approaches. Recent developments in natural language generation have exacerbated(加剧) this issue [5, 47], with machine-generated text sometimes being perceived as more trustworthy than humanwritten text [69]. Recently, some studies empirically show that rumor and non-rumor spread differently on social media, forming propagation patterns that could be harnessed(利用) for the rumor detection [36, 40, 67, 76]. Therefore, metadata is incorporated as propagation-based evidence, including post statistics (e.g. publication date, hashtag, URL) [35, 44], user demographics (such as age, gender, location, and education) [36, 39], social network structure (in the form of connections between users such as friendship or follower/followee relations) [31, 76], and user reactions (e.g. number of re-posts or likes) [41, 72]. Such propagation-based statistics can serve as indicators of rumorousness [54, 56, 77]. Apart from metadata, other datasets further incorporate a set of relevant posts (e.g. re-posts and replies of the source tweets) to model the propagation pattern for better detection [10, 14, 30, 50].
我们在表1中总结了现有的谣言检测数据集。正如表中所示,大多数现有数据集侧重于只包含文本陈述的谣言。早期的谣言检测工作不使用文本内容以外的任何证据。只依赖于语言(词汇和句法)特征的基于内容的方法被应用于捕获欺骗性线索或写作风格以检测谣言。然而,许多语言特征是依赖于语言的,限制了这些方法的普适性。自然语言生成的最新进展加剧了这一问题,有时机器生成的文本被认为比人类编写的文本更可信。最近的一些研究实证显示,谣言和非谣言在社交媒体上传播方式不同,形成了可用于谣言检测的传播模式。因此,元数据被作为传播为基础的证据纳入,包括帖子统计信息(例如发布日期、哈希标签、URL)、用户人口统计信息(如年龄、性别、位置和教育程度)、社交网络结构(以用户之间的连接形式,如友谊或关注/被关注关系)、用户反应(例如转发或点赞次数)。这些基于传播的统计数据可以作为谣言性的指标。除了元数据,其他数据集进一步纳入了一组相关帖子(例如源推文的转发和回复),以建模传播模式以实现更好的检测。
Nowadays multimodal misinformation can be easily generated by using many neural network-based editing tools. For example, deepfakes can be used to manipulate or fabricate visual content [38, 58], such as editing the objects, replacing backgrounds, or changing captions. Recent efforts in realistic images and art generation from natural language descriptions have exacerbated this issue [21, 48, 49, 52]. However, existing efforts in multimodal rumor detection are limited, both in size and scope. For example, ExFaux [27] collects 263 image-based tweets, and FauxBuster [71] includes 917 posts from Twitter and Reddit. Though ModalFusion [23] includes 9,528 textual statements paired with images, it only contains metadata as the evidence for detection. Relying on the visual and textual contents of rumors without considering the state of the world may not be able to identify well-presented misinformation, such as mismatch rumors. On the other hand, while metadata offers information complementary to the textual content which is useful when the latter is unavailable, it does not provide sufficient evidence grounding the rumor [74, 76]. Compared to existing datasets, MR2 further incorporates world knowledge by retrieving evidence from the Internet. Rumor detection systems trained on MR2 can synthesize additional multimodal contexts for better detection. There exist datasets focused on fact-checking [3, 22], but A claim can be factual regardless of whether it is a rumour [16, 75], as it is based on language subjectivity and growth of readership [44].
如今,利用许多基于神经网络的编辑工具可以轻松生成多模态错误信息。例如,Deepfakes 可以用于操纵或制作视觉内容,例如编辑对象、替换背景或更改字幕。最近在从自然语言描述生成逼真图像和艺术方面的努力加剧了这一问题。然而,现有的多模态谣言检测工作在规模和范围上都存在限制。例如,ExFaux 收集了 263 条基于图像的推文,而 FauxBuster 包括了来自 Twitter 和 Reddit 的 917 条帖子。虽然 ModalFusion 包括了 9,528 条文本陈述与图像配对,但它只包含了元数据作为检测的证据。仅依赖于谣言的视觉和文本内容而不考虑世界状况可能无法识别出呈现良好的错误信息,如不匹配的谣言。另一方面,虽然元数据在文本内容不可用时提供了与之互补的信息,但它并不能提供足够的证据来证实谣言。与现有数据集相比,MR2通过从互联网检索证据进一步融入了世界知识。在MR2上训练的谣言检测系统可以合成额外的多模态上下文以实现更好的检测。存在专注于事实核查的数据集,但无论声明是否是谣言,它都可以是事实,因为它基于语言主观性和读者群的增长。
2.2 Rumor Detection Models
We group existing rumor detection models into two categories: content-based methods and propagation-based methods. Contentbased methods only rely on the content of the post itself, while propagation-based methods further incorporate social contexts (e.g. metadata, comments). Early content-based systems employ supervised classifiers with feature engineering, relying on surface features such as Reddit karma and up-votes [7, 43], Twitter-specific types [4, 17], named entities and verbal forms in political transcripts [78]. However, these studies don’t consider the visual features that would be beneficial. Multi-modal data have been exploited by a set of studies to facilitate the detection. Jin et al. [23] employs recurrent neural networks to encode textual and visual features and fused them based on attention mechanism. Wang et al. [64] further incorporates event-invariant features by using the adversarial network to model Twitter events. In order to capture the relationships among multiple modalities, recent efforts explore various approaches to jointly learn the representations across modalities. Khattar et al. [24] leverages a variational auto-encoder to learn a shared representation of visual and textual contents. Qian et al. [45] adopts the hierarchical attention and Wu et al. [66] leverages the co-attention mechanism to fuse the multi-modal representations.
我们将现有的谣言检测模型分为两类:基于内容的方法和基于传播的方法。基于内容的方法仅依赖于帖子本身的内容,而基于传播的方法进一步融入了社交上下文(例如元数据、评论)。早期的基于内容的系统采用了监督分类器与特征工程,依赖于表面特征,如 Reddit 的 karma 和点赞,Twitter 特定类型,政治记录中的命名实体和动词形式。然而,这些研究并未考虑到可能有益的视觉特征。一些研究利用多模态数据来促进检测。例如,Jin 等人采用循环神经网络来编码文本和视觉特征,并基于注意机制融合它们。Wang 等人通过使用对抗网络模拟 Twitter 事件进一步融合了事件不变特征。为了捕获多模态之间的关系,最近的研究探索了各种方法来共同学习跨模态的表示。Khattar 等人利用变分自编码器学习视觉和文本内容的共享表示。Qian 等人采用分层注意力,而 Wu 等人利用协同注意机制融合了多模态表示。
Propagation-based approaches based on sequence or graph modeling have recently become popular, as they allow models to use the context of surrounding social media activity to inform decisions.These approaches often exploit the ways in which information is discussed and shared by users, which are strong indicators of rumorousness [77]. Kockina et al. [26] uses an LSTM [19] to model branches of tweets, processing sequences of posts and outputting a label at each time step. Ma et al. [37] employs Tree-LSTMs [57] to directly encode the structure of threads, and Guo et al. [15] models the hierarchy by using attention networks. Lu and Li [33] learn the representations of user interactions and their correlation with source tweets. Recent works have explored fusing more domain-specific features into neural networks [72]. Graph Neural Networks [25] have also been adopted to model the propagation behavior of a potentially rumorous claim [29, 40, 67]. Although the propagation uncertainty between different nodes has been considered [65], multimodal fusion for graphs has yet to be explored. Recent work has thus proposed to perform multimodal alignment for better fusing the features [73]. While propagation-based approaches can be useful for rumor detection, they are not ideal for early rumor detection. MR2 can play a crucial role in early detection, since retrieved texts and images do not rely on propagation-based features. Rumor detection systems trained on MR2 can be applied before misinformation spreads widely; this is also known as prebunking and has been shown to be more effective than post-hoc debunking [28, 51, 59].
基于序列或图建模的基于传播的方法最近变得流行,因为它们允许模型使用周围社交媒体活动的上下文信息来决策。这些方法通常利用用户讨论和分享信息的方式,这些方式是谣言性的强烈指标。Kockina 等人使用 LSTM 模型来建模推文的分支,处理帖子序列并在每个时间步输出标签。Ma 等人采用 Tree-LSTMs 直接编码线程的结构,而 Guo 等人通过使用注意力网络来建模层次结构。Lu 和 Li 学习了用户互动的表示及其与源推文的相关性。近期的工作探索了将更多领域特定特征融合到神经网络中。图神经网络也被采用来建模潜在的谣言性主张的传播行为。虽然考虑了不同节点之间的传播不确定性,但尚未探索图的多模态融合。最近的工作提出通过进行多模态对齐来更好地融合特征。虽然基于传播的方法对于谣言检测可能有用,但对于早期谣言检测并不理想。MR2 在早期检测中可以发挥关键作用,因为检索到的文本和图像不依赖于基于传播的特征。在 MR2 上训练的谣言检测系统可以在错误信息广泛传播之前应用;这也被称为预驳斥,已被证明比事后驳斥更有效。
3 DATASET CONSTRUCTION
MR2 contains two rumor detection datasets in English and Chinese. The English dataset MR2-E is constructed by using posts from Twitter and the Chinese dataset MR2-C includes posts from Weibo.
3.1 Data Analysis
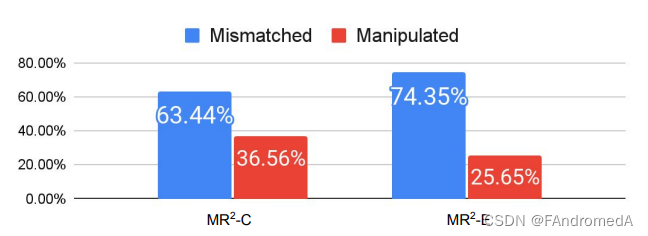
In order to investigate the effectiveness of the retrieval-based method, we conduct a human evaluation of retrieval-based, content-based, and propagation-based methods. We first analyze the distribution of multimodal rumors circulated on social media platforms by sampling 200 verified rumors from Twitter and Weibo, and categorize them into two types: mismatched and manipulated. Figure 3 show that most rumors spread over social media platforms are mismatched posts, with 63.44% from Weibo and 74.35% from Twitter being mismatched posts. This is likely due to the deceptive nature of mismatched posts, which are true if we only consider one modality (text or image). Then we ask the annotators to verify the posts based on the content, social context, and retrieved evidence. 500 rumors are randomly sampled from Weibo, and each annotator is given 50 rumors with their corresponding social contexts (i.e. comments) and retrieved visual and textual evidence from the Internet. The annotation team has 15 members, and 5 members are only involved in data validation. All annotators are native Chinese speakers. Annotators are required to answer (yes or no) if the content of the post, the social context, or the retrieved evidence provides sufficient information to predict the label of the post. To ensure the annotation quality, they are trained by the authors and go through several pilot annotations. We conduct an additional inter-annotator agreement and manual validation to ensure annotation consistency. For inter-annotator agreement, we randomly select 20% (n = 100) of rumors to be annotated by 5 annotators. We calculate the Fleiss K score [13] to be 0.78, which demonstrates that the annotation results are largely invariant through data validation [1].
为了调查基于检索的方法的有效性,我们对基于检索、基于内容和基于传播的方法进行了人工评估。我们首先通过从 Twitter 和微博中随机抽取 200 个已验证的谣言,分析了社交媒体平台上流传的多模态谣言的分布,并将它们分为两类:不匹配和被操纵。图3显示,大多数在社交媒体平台上传播的谣言都是不匹配的帖子,其中微博中有 63.44% 的帖子,Twitter 中有 74.35% 的帖子是不匹配的帖子。这可能是由于不匹配帖子的欺骗性质,如果我们只考虑一个模态(文本或图像),那么它们就是真实的。然后我们要求注释员基于内容、社交上下文和检索到的证据验证帖子。从微博中随机抽取了 500 个谣言,每个注释员分配了 50 个谣言及其对应的社交上下文(即评论)和从互联网检索到的视觉和文本证据。注释团队共有 15 名成员,其中 5 名成员仅参与数据验证。所有注释员都是母语为中文的人。要求注释员回答(是或否),帖子的内容、社交上下文或检索到的证据是否提供了足够的信息来预测帖子的标签。为了确保注释质量,他们经过作者的培训,并进行了几次试点注释。我们进行了额外的注释者一致性检查和手动验证,以确保注释一致性。对于注释者一致性检查,我们随机选择了 20%(n = 100)的谣言由 5 名注释者进行注释。我们计算 Fleiss K 分数为 0.78,表明通过数据验证,注释结果在很大程度上是不变的。
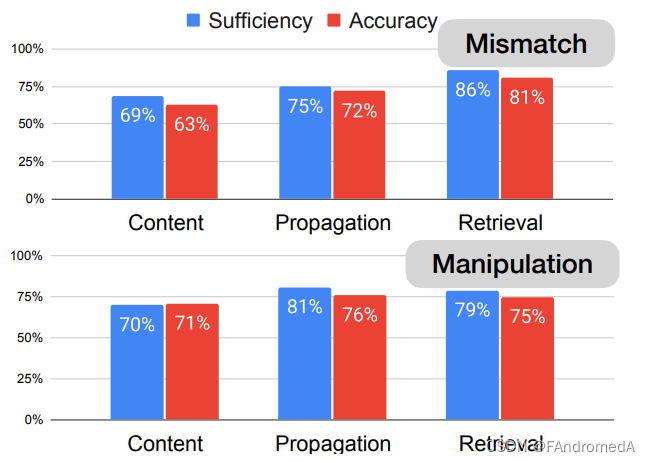
We report the average results in Figure 4, only 69% of contents provide sufficient information to verify the claim. Our same analysis suggests that for 86% of the instances, using retrieved evidence provides sufficient details to determine the factuality. In the second phase, each annotator is given a post with different contexts and asked to infer the labels of 25 posts. Human predictions are more accurate when retrieval evidence is given (81% vs. 72%). However,we notice that the performance gap between propagation and retrieval is smaller in prediction accuracy. One reason is that the retrieved evidence contains more irrelevant information that may affect the prediction accuracy. Overall, our findings suggest that the retrieval-based method is better suited for mismatched posts, and is amenable to early detection when social context is missing. Additionally, if a rumor detection system is able to extract relevant information from retrieved evidence, it will gain benefits from contextual clues.
我们在图4中报告了平均结果,只有 69% 的内容提供了足够的信息来验证声明。我们的分析表明,在 86% 的实例中,使用检索到的证据提供了足够的细节来确定事实性。在第二阶段,每个注释员被分配一个带有不同上下文的帖子,并被要求推断 25 个帖子的标签。当提供检索证据时,人类预测更准确(81% 对比 72%)。然而,我们注意到在预测准确率方面,传播和检索之间的性能差距较小。一个原因是检索到的证据包含了更多的无关信息,可能会影响预测准确率。总的来说,我们的研究结果表明,基于检索的方法更适合不匹配的帖子,并且在缺乏社交上下文时更易于早期检测。此外,如果一个谣言检测系统能够从检索到的证据中提取相关信息,它将从上下文线索中获益。
3.2 Posts Collection
3.2.1 English Dataset.
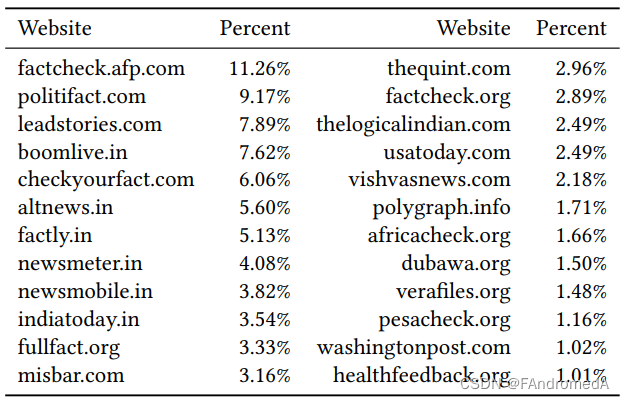
Following the RumorEval shared tasks [10, 14], we adopt a three-way classification scheme: Rumors, NonRumors, and Unverified Posts as many posts spreading over social media cannot be verified with existing information [10, 36]. To collect rumors, we utilize the Google Fact Check Tools API1 , a resource that gathers verified claims from fact-checking agencies from around the world. We scrape 48,070 verified claims from active English fact-checking agencies until July 2022. Table 2 displays the distribution of their sources. From these claims, we manually review the corresponding fact-checking articles, and extract 6,287 tweets from them. Fact-checkers usually employ fine-grained labels to represent degrees of truthfulness (true, mostly-true, mixture, etc.). To unify these tweets in the three-way classification scheme, we design a mapping (as shown in Table 3) to standardize the original labels. The majority of fact-checked tweets are labeled as rumors due to journalists usually verifying claims that spread misinformation. The numbers of unverified tweets and non-rumors are limited (167 and 103, respectively). To compensate for this, we sample extra non-rumors and unverified posts that provoke a similar number of reposts [76]. The threshold is based on the median number of reposts. For the non-rumors, we use tweets from authoritative news agencies on Twitter, while for unverified posts, we gather the posts of general threads that are not reported as rumors in the same period. As shown in Table 5, rumors, nonrumors and unverified posts have similar number of threads(主题,例如推特的#xxx) and users.
根据 RumorEval 共享任务 [10, 14],我们采用了三分类方案:谣言、非谣言和未验证帖子,因为许多在社交媒体上传播的帖子无法通过现有信息进行验证。为了收集谣言,我们利用了 Google Fact Check 工具 API,这是一个从世界各地的事实核查机构收集已验证声明的资源。我们从截至 2022 年 7 月的活跃英文事实核查机构中爬取了 48,070 条已验证声明。表2显示了这些来源的分布情况。通过这些声明,我们手动查阅了相应的事实核查文章,并从中提取了 6,287 条推文。事实核查人员通常使用细粒度的标签来表示真实度的程度(真实、大多为真、混合等)。为了将这些推文统一到三分类方案中,我们设计了一个映射(如表3所示),以标准化原始标签。由于记者通常会核实传播错误信息的声明,因此大多数经过事实核查的推文都被标记为谣言。未经验证的推文和非谣言的数量有限(分别为 167 和 103)。为了补偿这一点,我们随机抽样了额外的非谣言和未验证帖子,这些帖子引起的转发数量相似[76]。阈值基于转发数的中位数。对于非谣言,我们使用了 Twitter 上权威新闻机构的推文,而对于未验证的帖子,我们收集了在同一时期未被报道为谣言的普通帖子。正如表5所示,谣言、非谣言和未验证帖子的主题数(例如推特的#xxx)和用户数相似。
Aiming at building a multimodal dataset, we remove text-only posts. Next, we perform data deduplication to remove posts with similar textual and visual content to prevent data leakage in the training procedure. We remove duplicated images from the raw set with a near-duplicated image detection algorithm based on locality sensitive hashing [55]. Small or long images in terms of the resolution are also removed to maintain good quality. We identify posts concerning the same events based on one-pass text clustering2 and make sure they are not contained in both training and testing sets. The training, development, and testing sets contain approximately a number of posts with a ratio of 8:1:1. Social contexts of posts are also included in the dataset. We gather the corresponding metadata, such as publication dates, number of reposts, replies and likes, names of users, locations, hashtags, and URLs. All comments to the post including reposts and replies are also collected. While Weibo does not provide an API endpoint to retrieve conversational threads provoked by source posts, it is possible to collect them by scraping posts through the web client interface. We develop a script that enable us to collect and store complete threads for all the source posts. As shown in Table 4, the resulting Twitter dataset consists of 1,418 rumors, 2,318 non-rumors, 3,240 unverified posts, and 576,254 threads in total.
为了构建一个多模态数据集,我们移除了仅包含文本的帖子。接下来,我们执行数据去重,以移除具有相似文本和视觉内容的帖子,以防止训练过程中的数据泄漏。我们使用基于局部敏感哈希的近似重复图像检测算法从原始集合中移除重复的图像。根据分辨率,我们还删除了尺寸太小或太长的图像,以保持良好的质量。我们基于一次文本聚类来识别涉及相同事件的帖子,并确保它们不包含在训练和测试集中。训练、开发和测试集的比例大约是 8:1:1。数据集还包括帖子的社交上下文。我们收集了相应的元数据,例如发布日期、转发数、回复数和点赞数、用户姓名、位置、哈希标签和 URL。所有评论,包括转发和回复,也都被收集了。虽然微博没有提供用于检索由源帖子引发的对话主题的 API 端点,但可以通过网络客户端界面来收集它们。我们开发了一个脚本,使我们能够收集并存储所有源帖子的完整主题。如表4所示,生成的 Twitter 数据集总共包含 1,418 条谣言、2,318 条非谣言、3,240 条未经验证的帖子和 576,254 条主题。
3.2.2 Chinese Dataset.
For the Chinese dataset, we obtain a set of verified rumors from March 2017 to July 2022 from the official rumor debunking center of Weibo3 . Suspicious posts that provoke a high number of reposts are reported to the center, then auditors from Weibo would examine the posts and verify them as rumors or nonrumors. This system serves as an authoritative source to collect rumors in prior efforts [23, 35, 72]. We adopt a similar strategy to collect non-rumors and unverified posts as described in the construction of the English dataset. Table 5 provides more details, the resulting MR2-C dataset consists of 1,754 rumors, 2,609 nonrumors, 3,361 unverified posts, and 497,233 threads in total. Detailed statistics of MR2-E and MR2-C are presented in Table 4 and 5 respectively. Meanwhile, Figure 5 shows the word clouds of these two datasets. The datasets have a similar proportion to the three classes, with MR2-C having fewer and shorter comments or threads. This is possible because Chinese social media have more non-political and non-scientific content. The analysis of word frequency revealed that MR2-E mainly focuses on topics such as politics, public health, social news, and natural science, and MR2-C is mainly about social news and public health. This indicates that the domains of rumor dissemination on Twitter and Weibo overlap.
对于中文数据集,我们从微博官方辟谣中心获取了一组从 2017 年 3 月到 2022 年 7 月的已验证谣言。引起大量转发的可疑帖子会被报告给该中心,然后微博的审核人员会检查这些帖子,并验证它们是否为谣言或非谣言。该系统作为一个权威来源,用于收集先前工作中的谣言 [23, 35, 72]。我们采用类似的策略来收集非谣言和未验证的帖子,如英文数据集的构建所述。表5提供了更多细节,生成的 MR2-C 数据集总共包含 1,754 条谣言、2,609 条非谣言、3,361 条未经验证的帖子和 497,233 条主题。MR2-E 和 MR2-C 的详细统计数据分别在表4和表5中呈现。同时,图5显示了这两个数据集的词云。这两个数据集在三个类别上的比例相似,但 MR2-C 的评论或主题较少且较短。这可能是因为中国社交媒体上的内容更多地是非政治和非科学的内容。词频分析显示,MR2-E 主要关注政治、公共卫生、社会新闻和自然科学等主题,而 MR2-C 主要关注社会新闻和公共卫生。这表明 Twitter 和微博上的谣言传播领域存在重叠。

3.3 Evidence Retrieval
3.3.1 Textual Evidence.
We use the image of the input post as the query to retrieve textual evidence by using Google Reverse Image Search4 . The Search Engine returns a list of images similar to the query image. In addition, the URLs of the web pages that contain these images are returned. We developed a web crawler to crawl the descriptions of the top 20 images based on the URLs. Concretely, the crawler first visits the web page and saves the title, then searches for the tag of the image using its URL and image content matching based on perceptual hashing. After locating the image, we are able to retrieve the description. We scrape the tag, as well as the tag’s textual attributes such as alt, imagealt, caption, data-caption, and title. From each page, we collect all the non-redundant text snippets that we found. The search engine returns up to 20 search results. We create a list of websites that spread misinformation based on the list of fake news websites by Wikipedia5 . We filter out the web URLs that appear on this list. We further discard a page if the detected language of the title is nonEnglish, using the fastText library6 for language identification. In practice, we keep the descriptions from the top 𝑁=5 search results as textual evidence.
我们使用输入帖子的图像作为查询,通过使用 Google 反向图像搜索来检索文本证据。搜索引擎返回了一个与查询图像相似的图像列表。此外,还返回了包含这些图像的网页的 URL。我们开发了一个网络爬虫,根据这些 URL 抓取前 20 张图像的描述。具体来说,爬虫首先访问网页并保存标题,然后使用 URL 和基于感知哈希的图像内容匹配来搜索图像的标签。定位到图像后,我们能够检索到描述。我们抓取了 <figcaption> 标签以及 <img> 标签的文本属性,如 alt、imagealt、caption、data-caption 和 title。从每个页面,我们收集所有非冗余的文本片段。搜索引擎最多返回 20 个搜索结果。我们根据维基百科的假新闻网站列表创建了一个传播虚假信息的网站列表。我们过滤掉出现在该列表中的网页 URL。如果标题的检测语言为非英语,则进一步丢弃页面,使用 fastText 库进行语言识别。在实践中,我们保留前 𝑁=5 个搜索结果的描述作为文本证据。
3.3.2 Visual Evidence.
Next, we use the text of the input post as the query to retrieve visual evidence by using the Google Programmable Search Engine7 . The Search Engine returns a list of images based on the query text. We saved the top 10 images retrieved by the search engine. We further filter out the images from the list of misinformation websites. In practice, we keep the top 𝑁=5 images as visual evidence after removing such images. It is important to note that, unlike the inverse image search, the search results here do not always correspond to the exact match of the textual query. Therefore, the visual evidence might be more loosely related to the image of the post. However, even if it is not exactly related to the input, it potentially provides implicit information to verify the post. Take the doctor with dead bodies in Figure 1 as an example, if the vaccine is causing death, top images returned by the search engine should reflect this event. However, the top results are images introducing how vaccine functions. Comparing the retrieved images against the image of the post is beneficial to reason over the overlap of regions and objects between the images for better prediction.
接下来,我们使用输入帖子的文本作为查询,通过使用 Google 可编程搜索引擎来检索视觉证据。搜索引擎基于查询文本返回一组图像。我们保存了搜索引擎检索到的前 10 张图像。我们进一步从虚假信息网站列表中过滤出这些图像。在实践中,我们在移除这些图像后保留前 𝑁=5 张图像作为视觉证据。需要注意的是,与逆图像搜索不同,这里的搜索结果并不总是与文本查询的精确匹配相对应。因此,视觉证据可能与帖子的图像关系较松散。然而,即使它与输入不完全相关,它也可能提供了隐含信息来验证帖子。以图1中的医生和尸体为例,如果疫苗导致死亡,搜索引擎返回的前几张图像应该反映这一事件。然而,顶部结果是介绍疫苗功能的图像。将检索到的图像与帖子的图像进行比较有助于推理出图像之间的重叠区域和对象,从而更好地进行预测。
4 BASELINE SYSTEMS
4.1 Retrieval-Based Model
In this section, we will present the baseline using retrieved texts and images as evidence for rumor detection. We define an instance as a tuple representing two different modalities of contents: the textual content 𝑇 and the visual content 𝑉 of the post, and a set of textual evidence
and visual evidence
, where 𝑛 is the number of evidence. The proposed model consists of three components, including a textual encoder, visual encoder, and classifier.
在本节中,我们将介绍使用检索到的文本和图像作为谣言检测证据的基线方法。我们将一个实例定义为一个元组,表示两种不同内容的模态:帖子的文本内容 𝑇 和视觉内容 𝑉,以及一组文本证据
和视觉证据
,其中 𝑛 是证据的数量。所提出的模型包括三个组件,包括文本编码器、视觉编码器和分类器。
4.1.1 Textual Encoder.
This module aims to encode the texts of the post and retrieved evidence, then select relevant evidence based on the post. Given the textual content of a post and corresponding retrieved textual evidence. We use a context encoder to encode the sentences into contextualized representations. The context encoder can be a Transformer [60] or a BERT [11]. Here we use the BERT as an example. We first feed the text of the post 𝑇 into BERT and use the representation of the CLS tokens as the textual post representation. Similarly, we feed the textual evidence independently to the BERT, and concatenate the CLS of each piece of evidence as the textual evidence representation:
该模块旨在对帖子和检索到的证据的文本进行编码,然后根据帖子选择相关证据。给定帖子的文本内容和相应的检索到的文本证据。我们使用一个上下文编码器来将句子编码成上下文化的表示。上下文编码器可以是 Transformer 或 BERT 。这里我们以 BERT 为例。我们首先将帖子的文本内容 𝑇 输入到 BERT 中,并使用 CLS 令牌的表示作为文本帖子表示。类似地,我们将每个文本证据 独立地输入到 BERT 中,并将每个证据片段的 CLS 连接起来作为文本证据表示:
is the representation of the textual post, where 𝑑 is the embedding size.
∈
is the representation of the textual evidence, where 𝑑 is the embedding size and 𝑛 is the number of textual evidence. After obtaining the representations of the textual post and evidence, we use the attention mechanism [11] to select relevant evidence for later prediction. The calculation involves a query and a set of key-value pairs. The output is computed as a weighted sum of the values, where the weight is computed by a function of the query with the corresponding key. Here we view the representation of the post
as the query and the representation of the evidence
as the key:
其中, 是文本帖子的表示,其中 𝑑 是嵌入大小。
∈
是文本证据的表示,其中 𝑑 是嵌入大小,𝑛 是文本证据的数量。在获取文本帖子和证据的表示后,我们使用注意力机制 [11] 来选择相关的证据进行后续预测。计算涉及一个查询和一组键-值对。输出被计算为值的加权和,其中权重由查询和相应键的函数计算。这里我们将帖子的表示
视为查询,将证据的表示
视为键:
where ∈
and
∈
are trainable projection matrices.
∈
is the output of the text encoder.
其中, ∈
和
∈
是可训练的投影矩阵。
∈
是文本编码器的输出。
4.1.2 Visual Encoder.
This module aims to encode the visual content of the post and retrieved evidence, then select relevant evidence based on the post. First, we represent the visual context by using an encoder, which can be a ResNet [18] or Vision Transformer [12], pretrained on the ImageNet dataset [9]. Here we use ResNet as an example. We feed the visual content of the post 𝑉 and visual evidence into the ResNet:
该模块旨在对帖子和检索到的证据的视觉内容进行编码,然后根据帖子选择相关证据。首先,我们使用一个编码器来表示视觉内容,这个编码器可以是在 ImageNet 数据集上预训练的 ResNet [18] 或 Vision Transformer [12]。这里我们以 ResNet 为例。我们将帖子的视觉内容 𝑉 和视觉证据 输入到 ResNet 中:
∈
is the representation of the visual post, where 𝑑 is the embedding size.
∈
is the representation of the visual evidence, where 𝑛 is the number of visual evidence. Similar to Eqn. 2, we compute the output of the enhanced visual representations as
∈
.
∈
是视觉帖子的表示,其中 𝑑 是嵌入大小。
∈
是视觉证据的表示,其中 𝑛 是视觉证据的数量。类似于公式(2),我们计算增强后的视觉表示的输出为
∈
。
4.1.3 Classifier.
We concatenate the textual representation and visual representation to get the multimodal representation for classification. Then a feed-forward neural network (FFNN) is applied over the concatenated representations:
我们将文本表示和视觉表示串联起来,以获得用于分类的多模态表示。然后,将其输入到一个前馈神经网络(FFNN)中:
where is then fed into a linear layer followed by a softmax operation to obtain a probability distribution over three labels.
其中 然后被输入到一个线性层,接着进行 softmax 操作,以获得三个标签的概率分布。
4.2 Content-Based Model
It only relies on the textual and visual contents of the post itself. We adopted three baselines, including models that only use textual content, visual content, and both of them. Text-Based Model. only considered the textual content of the post. BERT [11] and RoBERTa [32] are used as contextualized encoders to encode the textual content. Similar to the retrieved-based model, the representation of the CLS token is used for prediction. Image-Based Model. only considered the visual content of the post. ResNet [18] and Vision Transformer [12] are used as visual encoders. Both are pretrained on ImageNet [9]. The output representation of the visual encoder is used for classification. Multi-Modal Model. encodes both the textual and visual contents of the input post. We include two baselines: MVAE [24] and CLIP [46]. MVAE reconstructs both modalities from the shared multi-modal representation based on a variational auto-encoder. CLIP is an image-language pretrained model. We pass the image and text of the post to CLIP and normalize their representations. A joint representation is produced by using a dot product of the output visual and textual representations. The resulting joint representation is then used for prediction.
它仅依赖于帖子本身的文本和视觉内容。我们采用了三种基线模型,包括仅使用文本内容、仅使用视觉内容以及两者都使用的模型。基于文本的模型。仅考虑帖子的文本内容。BERT [11] 和 RoBERTa [32] 被用作上下文编码器来编码文本内容。与基于检索的模型类似,CLS 令牌的表示被用于预测。基于图像的模型。仅考虑帖子的视觉内容。ResNet [18] 和 Vision Transformer [12] 被用作视觉编码器。两者都是在 ImageNet [9] 上预训练的。视觉编码器的输出表示被用于分类。多模态模型。编码输入帖子的文本和视觉内容。我们包括两个基线模型:MVAE [24] 和 CLIP [46]。MVAE 基于变分自编码器从共享的多模态表示重构两种模态。CLIP 是一个图像-语言预训练模型。(现有模型:https://www.modelscope.cn/models/iic/multi-modal_clip-vit-base-patch16_zh/summary)我们将帖子的图像和文本传递给 CLIP,并规范化它们的表示。通过使用输出视觉和文本表示的点积,产生一个联合表示。然后将产生的联合表示用于预测。
4.3 Propagation-Based Model
It models the propagation structure of the input post based on its social contexts. We include tree-based, graph-based, and modalfusion models.
Tree-Based Model. models the information flow from the input post and its comments as a tree structure to capture complex propagation patterns. We included two competitive rumor detection models as baselines, including Tree-RvNN [37] and TreeTransformer [34]. Tree-RvNN defines a top-down tree, feature vectors of posts are generated based on their propagation paths. A tree-lstm [57] is employed to directly encode the tree, then a maxpooling layer is applied over the leaf posts to form the final representation. Tree-Transformer leverages the attention mechanism [60] to select important reply posts and combine the representation of the top-down and bottom-up trees.
Graph-Based Model. views the propagation structure as the graph and aggregates the information via a message-passing scheme. We included two graph-based models: GLAN [68] and EBGCN [65]. GLAN constructs a heterogeneous graph to capture the interactions among the input post, reposts, and users. Then graph attention networks [61] is used to get the representations for classification. ENGCN formulates the propagation structure as a top-down propagation graph and a bottom-up dispersion graph. The graph embedding is generated for prediction by using the edge-weighted graph convolutional networks [25].
Modal-Fusion Model. combines the information from the content of the post and its social context. We adopted two baselines: AttRNN and MFAN. Att-RNN [23] employed recurrent neural networks to encode textual and visual features and fused them together with metadata based on the attention mechanism. MFAN [73] jointly uses textual, visual, and social graph features, involving multi-modal alignment for better fusion, and utilizing potential relationships to enhance the graph features [73].
它基于社交上下文模拟了输入帖子的传播结构。我们包括基于树结构、图结构和模态融合的模型。
基于树的模型。将输入帖子及其评论的信息流建模为树结构,以捕捉复杂的传播模式。我们包括两个竞争性的谣言检测模型作为基线,包括 Tree-RvNN [37] 和 Tree-Transformer [34]。Tree-RvNN 定义了一个自顶向下的树,基于其传播路径生成帖子的特征向量。然后使用树形 LSTM [57] 直接编码树,然后应用最大池化层对叶子帖子进行汇总以形成最终表示。Tree-Transformer 利用注意力机制 [60] 选择重要的回复帖子,并将自顶向下和自底向上树的表示结合起来。
基于图的模型。将传播结构视为图,并通过消息传递方案聚合信息。我们包括两个基于图的模型:GLAN [68] 和 EBGCN [65]。GLAN 构建了一个异构图来捕获输入帖子、转发和用户之间的交互。然后使用图注意力网络 [61] 来获取用于分类的表示。EBGCN 将传播结构形式化为自顶向下的传播图和自底向上的扩散图。通过使用加权图卷积网络 [25] 生成图嵌入以进行预测。
模态融合模型。将帖子内容和社交上下文的信息结合起来。我们采用了两个基线模型:Att-RNN 和 MFAN。Att-RNN [23] 使用循环神经网络编码文本和视觉特征,并基于注意力机制将它们与元数据融合在一起。MFAN [73] 共同使用文本、视觉和社交图特征,涉及多模态对齐以实现更好的融合,并利用潜在的关系增强图特征。
5 EXPERIMENTS AND ANALYSES
5.1 Experimental Setup
Following Jin et al. [23] and Zhang et al. [70], we computed the Accuracy and Macro F1 as the evaluation metric. The hyper-parameters are chosen based on the development set. Results are reported with mean and standard deviation based on 5 runs. For the textual encoder of the retrieval-based model, we use the BERT-Base default tokenizer with a max-length of 256 to preprocess data. For the visual encoder of the retrieval-based model, we use ResNet 152 to encode the visual images. We scale the image proportionally so that the short side is 256, and crop the center to 224 ∗ 224. For the feedforward neural network of the classifier, we set the layer dimensions as -1024-verification_labels, where
= 768 ∗ 5 + 2048 ∗ 5. We use BertAdam [11] with 9𝑒−6 learning rate, warmup with 0.1 to optimize the cross-entropy loss and set the batch size as 16.
根据 Jin 等人 [23] 和 Zhang 等人 [70] 的方法,我们计算准确度和宏平均 F1 值作为评估指标。超参数是根据开发集选择的。结果基于 5 次运行的平均值和标准差进行报告。对于检索式模型的文本编码器,我们使用了 BERT-Base 默认分词器,最大长度为 256 用于预处理数据。对于检索式模型的视觉编码器,我们使用 ResNet 152 来编码视觉图像。我们按比例缩放图像,使短边为 256,并将中心裁剪为 224 × 224。对于分类器的前馈神经网络,我们将层维度设置为 -1024-verification_labels,其中
= 768 × 5 + 2048 × 5。我们使用 BertAdam [11] 优化交叉熵损失,设置学习率为 9𝑒−6,使用 0.1 的热启动,并将批量大小设置为 16。
5.2 Main Results
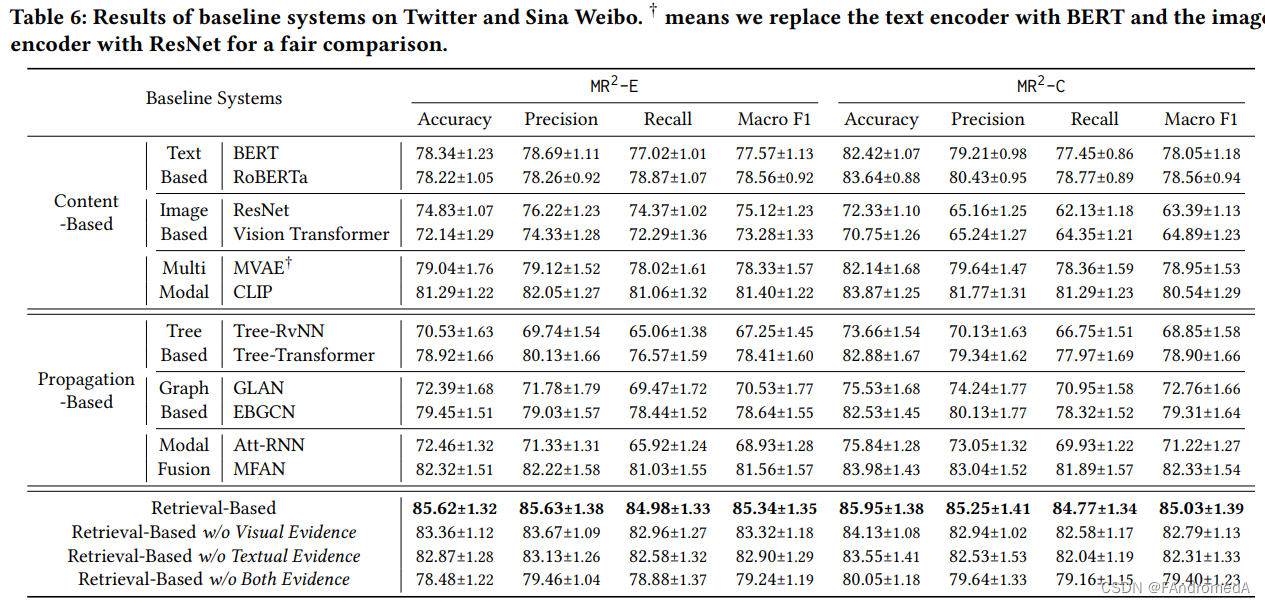
Content-based Method. Table 6 shows that multimodal baselines consistently outperform text-based and image-based baselines on both datasets. Results from CLIP demonstrate the highest F1 score of 81.46% on MR2-E and 81.54% on MR2-C, indicating that solely relying on text or visual modality cannot accurately identify misinformation. Furthermore, learning a good shared representation between modalities is necessary for identifying multimodal rumors. Generally, text-based baselines perform better than image-based counterparts, due to the higher ratio of misinformation presented in the textual modality. The proposed retrieval-based model achieved an F1 score of 85.34% on MR2-E and 85.03% on MR2-C, which is significantly higher than the content-based systems. This implies that retrieving multimodal evidence from the internet provides world knowledge to help detect well-presented misinformation. The retrieval-based model has less performance decline on MR2-C, which contains more challenging mismatched posts, as additional evidence is better resilient to mismatched cases.
内容为基础的方法。表 6 显示,在两个数据集上,多模态基线始终优于仅使用文本或图像的基线。来自 CLIP 的结果显示了最高的 F1 得分,MR2-E 上为 81.46%,MR2-C 上为 81.54%,表明仅依赖文本或视觉模态无法准确识别错误信息。此外,学习良好的模态共享表示对于识别多模态谣言是必要的。一般来说,由于在文本模态中呈现错误信息的比例较高,文本为基础的基线表现优于图像为基础的对应基线。所提出的检索式模型在 MR2-E 上取得了 85.34% 的 F1 得分,在 MR2-C 上为 85.03%,明显高于内容为基础的系统。这意味着从互联网检索多模态证据提供了世界知识,有助于检测错误信息的良好呈现。检索式模型在包含更具挑战性的不匹配帖子的 MR2-C 上性能下降较少,因为额外的证据对于不匹配案例更具有韧性。
Propagation-based Method. MFAN outperforms tree-based and graph-based methods that mainly focus on modeling the input text and its surrounding social contexts, since MFAN fuses information from different modalities (text, image, and social contexts). Compared to the best content-based model CLIP, MFAN achieves better results on both MR2-E (81.56% v.s. 81.40%) and MR2-C (82.33% v.s. 80.54%), which suggests that incorporating social contexts improves the performance of the multimodal model. It was also observed that propagation-based methods do not suffer the same performance decrease on MR2-C as content-based systems. This might be due to the fact that social contexts provide more information to identify mismatched posts. However, content-based models have higher robustness than other models, likely because irrelevant information is also presented in social contexts. The retrieval-based model achieved higher accuracy and F1 score than MFAN, further proving the effectiveness of retrieving multimodal evidence. Moreover, the standard deviation of the retrieval-based model was lower than propagation-based models and comparable to content-based methods, showing that retrieved evidence maintains a better balance between relevant and irrelevant information.
传播基础方法。MFAN 胜过了主要关注建模输入文本及其周围社交背景的基于树和基于图的方法,因为 MFAN 融合了来自不同模态(文本、图像和社交背景)的信息。与最佳内容为基础的模型 CLIP 相比,MFAN 在 MR2-E(81.56% 对 81.40%)和 MR2-C(82.33% 对 80.54%)上取得了更好的结果,这表明融合社交背景提高了多模态模型的性能。观察到传播基础方法在 MR2-C 上没有像内容为基础的系统那样出现性能下降。这可能是因为社交背景提供了更多信息来识别不匹配的帖子。然而,内容为基础的模型具有比其他模型更高的鲁棒性,这很可能是因为社交背景中也包含了无关信息。检索式模型的准确性和 F1 得分均高于 MFAN,进一步证明了检索多模态证据的有效性。此外,检索式模型的标准偏差低于传播基础模型,并且与内容为基础的方法相当,表明检索的证据在相关信息和无关信息之间保持了更好的平衡。
5.3 Analyses and Discussions
Ablation Study. We conduct an ablation study to show the effectiveness of different modules of the retrieval-based model on the test set. Retrieval-based model w/o Visual Evidence, Retrieval-based model w/o Textual Evidence, and Retrieval-based model w/o Both Evidence mean that textual, visual and all evidences are removed from the retrieved evidence, and only the remaining evidence and the original post are used to detect whether it is a rumor or not. The results from Table 6 demonstrate that the two types of evidence all contributes positively to the performance and can bring 4.13% (Visual Evidence), 4.58% (Textual Evidence), and 5.87% (Both Evidence) Macro F1 improvements, respectively. Among them, text evidence obtained from image retrieval brings better benefits, which may be related to the fact that textual evidence usually describes the objects in the image, and the relationship between objects can often explain whether the original post is a rumor.
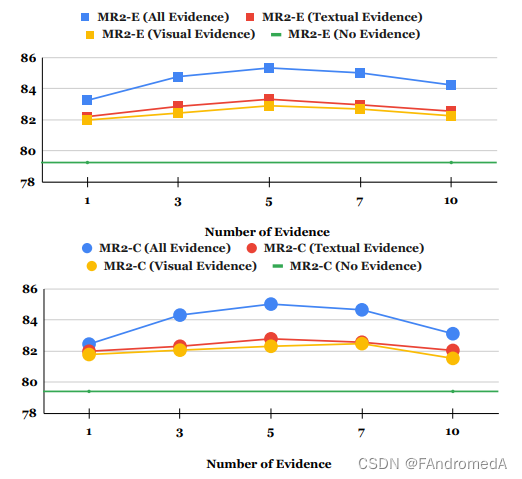
Effects of Evidence. In Figure 7, we vary the numbers of retrieved visual and textual evidence from 1 ∼ 10 and report the Macro F1 on the test set of MR2-E and MR2-C. The fluctuation results indicate that both the quantity and quality of retrieved visual and textual evidence affect the performance. Using insufficient textual or visual evidence will give the original post less explanatory information, thus affecting the effect of the model on rumor detection. Using too much textual or visual evidence will introduce irrelevant or erroneous noise and affect the performance of the model. From Figure 7, we can observe that the damage to model performance caused by introducing more evidence is slightly less than the impact of insufficient evidence. A direction that can be studied on our benchmark in the future is how to screen a large amount of noisy evidence to obtain more informative and effective evidence.
Ablation Study(注释:消融研究“Ablation study”一词起源于20 世纪60 年代和70 年代的实验神经心理学领域,通过切除部分动物大脑来研究这对动物行为的影响。 在机器学习领域,尤其是复杂的深度神经网络中,"消融研究"被用来描述切除网络某些部分的过程,以便更好地了解网络的行为。). 对检索式模型的不同模块进行割裂研究,以展示在测试集上的效果。“无视觉证据的检索模型”、“无文本证据的检索模型”和“无两种证据的检索模型”意味着从检索到的证据中移除了文本、图像和所有证据,只使用剩余的证据和原始帖子来检测它是否为谣言。从表 6 的结果可以看出,这两种类型的证据都对性能产生了积极的贡献,并且可以分别带来 4.13%(视觉证据)、4.58%(文本证据)和 5.87%(两种证据)的宏 F1 改进。其中,通过图像检索获取的文本证据带来了更好的效益,这可能与文本证据通常描述图像中的对象以及对象之间的关系可以解释原始帖子是否为谣言有关。
证据的影响。在图 7 中,我们改变了检索到的视觉和文本证据的数量从 1 ∼ 10,并报告了 MR2-E 和 MR2-C 测试集上的宏 F1。波动的结果表明,检索到的视觉和文本证据的数量和质量都会影响性能。使用不足的文本或视觉证据会给原始帖子带来较少的解释信息,从而影响模型对谣言检测的效果。使用过多的文本或视觉证据会引入无关或错误的噪音,影响模型的性能。从图 7 中可以观察到,引入更多证据造成的对模型性能的损害略小于不足证据的影响。未来在我们的基准上可以研究的一个方向是如何筛选大量的噪声证据以获取更多信息和更有效的证据。
No matter how much evidence is employed, our method consistently outperforms the baseline model: No Evidence, which shows the effectiveness of adding evidence. In our model, we adopt 5 textual and visual evidence for each post to achieve the best performance. Another interesting finding is that adding textual evidence works better than adding visual evidence, which may be related to the fact that textual evidence retrieval is easier to obtain highquality results than visual evidence retrieval. Therefore, how to improve the retrieval ability of visual evidence is also a research direction in the future.
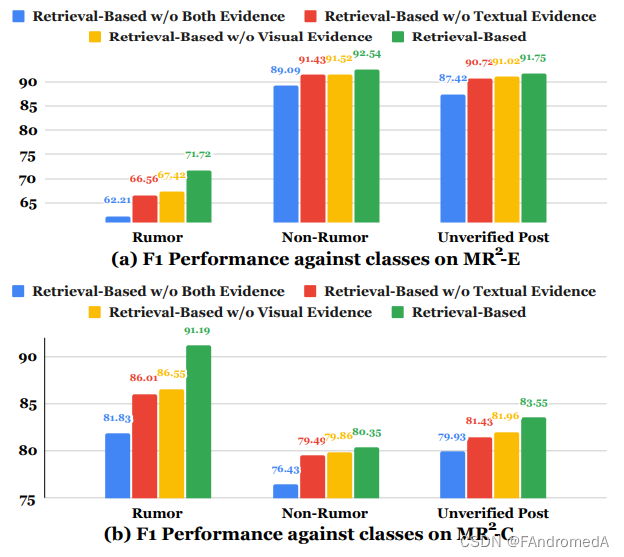
Performance against Classes. We study the F1 performance changes against classes after adding retrieval evidence in Figure 7. A general conclusion is that all classes can obtain an average 5.70% improvement in F1 performance from retrieved evidence, among which textual evidence has a greater improvement than visual evidence (3.57% vs. 3.02%). An interesting finding is that the F1 performance of “Rumor” class that performs poorly in MR2-E and that performs better in MR2-C improves more, which fully shows that a gap that affects the performance of the “Rumor” class is the amount of information in the retrieved evidence, and more sufficient auxiliary evidence can lead to more improvements.
无论使用多少证据,我们的方法始终优于基线模型:无证据模型,这表明了添加证据的有效性。在我们的模型中,我们对每个帖子采用了5个文本和视觉证据以获得最佳性能。另一个有趣的发现是,添加文本证据比添加视觉证据效果更好,这可能与文本证据检索更容易获得高质量结果有关,而视觉证据检索则是一个未来研究方向,如何提高视觉证据的检索能力。
对类别的性能。我们研究了在添加检索证据后F1性能随类别的变化情况,见图7。一个总体结论是,所有类别的F1性能都可以从检索证据中获得平均5.70%的改善,其中文本证据的改善比视觉证据更大(3.57% vs. 3.02%)。一个有趣的发现是,在MR2-E中表现不佳的“谣言”类别,在MR2-C中表现更好,改进更多,这充分表明影响“谣言”类别性能的差距是检索证据中的信息量,更充足的辅助证据可以带来更多的改进。
Case Study. We give the case study in Figure 8. For the original post 1 from Twitter, since the text of the original post is similar to the semantics expressed in the image, and the language style of the post is similar to the news post, the content-based systems will recognize it as “Non-Rumor”. Propagation-based systems will also be identified as “Non-Rumor” based on the original post because no useful information is given in the comments. According to the “False” annotations in the retrieved visual evidence and the “Fabricated” and “No” content in the textual evidence, retrieval-based systems can correctly predict the post as “Rumor”. For the original post 2 from Sina Weibo, the style of the original text of this post is close to the news expression, and the comments are also related to the original post. According to the evidence retrieved in the web, it can be mutually confirmed with the original post, so all systems incorrectly predict it as “Non-Rumor”. However, all systems ignore the actual casualties in the original post are still an unconfirmed matter, so the original post should be labeled as “Unverified Post”.
案例研究。我们在图8中给出了案例研究。对于来自Twitter的原始帖子1,由于原始帖子的文本与图像中表达的语义相似,且帖子的语言风格类似于新闻帖子,基于内容的系统将把它识别为“非谣言”。基于传播的系统也会根据原始帖子将其识别为“非谣言”,因为评论中没有提供有用的信息。根据检索到的视觉证据中的“错误”注释以及文本证据中的“虚构”和“否”内容,检索为基础的系统可以正确地将帖子预测为“谣言”。对于来自新浪微博的原始帖子2,该帖子的原始文本风格接近新闻表达,评论也与原始帖子相关。根据在网络中检索到的证据,它可以与原始帖子相互确认,因此所有系统都错误地将其预测为“非谣言”。然而,所有系统都忽略了原始帖子中实际伤亡情况仍然是未经证实的事实,因此原始帖子应标记为“未经证实的帖子”。

6 CONCLUSION AND FUTURE WORK
In this paper, we explore multimodal rumor detection using visual and textual evidence. Our approach is more resistant to image manipulation and allows early detection compared to content-based methods, as it doesn’t depend on propagation-based features. We create large multimodal datasets (MR2 ) and develop baseline models, expecting MR2 to be a stimulating challenge for rumor detection. This proposed approach achieves competitive benchmark results but faces three main challenges. First, using search engines provides related knowledge but introduces noisy evidence, potentially misleading model predictions. Second, not all evidence is trustworthy, and reliable sources may contradict, posing difficulties for machine learning systems, including ours. Obtaining reliable, relevant evidence is a crucial future research direction. Lastly, evidence can be found in other modalities beyond texts and images, such as tables, info lists, knowledge graphs, videos, and audio. Human experts can extract information from these diverse sources, but our system only handles textual and visual evidence. Incorporating multi-modal evidence is another important future research direction.
在本文中,我们探讨了利用视觉和文本证据进行多模态谣言检测。与基于内容的方法相比,我们的方法对图像操纵更具抵抗力,并且允许早期检测,因为它不依赖于基于传播的特征。我们创建了大规模的多模态数据集(MR2),并开发了基准模型,期望MR2成为谣言检测的激动人心的挑战。这种提出的方法取得了竞争性的基准结果,但面临着三个主要挑战。首先,使用搜索引擎提供相关知识,但引入了嘈杂的证据,可能会误导模型的预测。其次,并非所有的证据都是可信的,可靠的来源可能会产生矛盾,给包括我们在内的机器学习系统带来困难。获取可靠、相关的证据是一个重要的未来研究方向。最后,证据不仅可以在文本和图像等模态中找到,还可以在表格、信息列表、知识图谱、视频和音频等其他模态中找到。人类专家可以从这些多样的来源中提取信息,但我们的系统只处理文本和视觉证据。整合多模态证据是另一个重要的未来研究方向。















 3878
3878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









