






# 温馨提示:全文字数1w+,请根据需求选择观看!建议初次搭建的学者,就一步一步来,否则容易出错!本文仅供学习参考使用!
# 简介:耐心,自信来源于你强大的思想和知识基础!!
# 严禁转载
1.虚拟环境准备
1.1 克隆三台虚拟机
1.

2.

3.

4.

5.
重复上述操作3次。创建三个虚拟机
1.2 网络配置
1.2.1 网络配置方法一
1.

2.

3.

4.

5.

6.

7.

8.

9.

10.

11.

12.

13.

14.
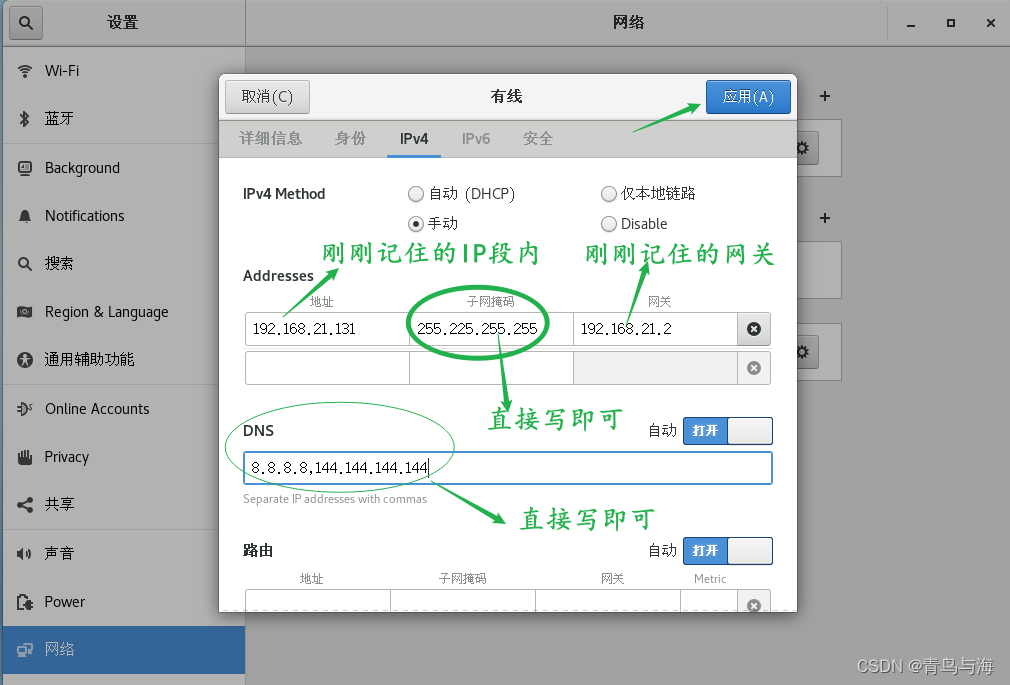
上图仅供参考,是我的!!!!不要照抄!!!忘记ip地址和网关的,可以往上翻一下哦
15.

16.

17.

18.
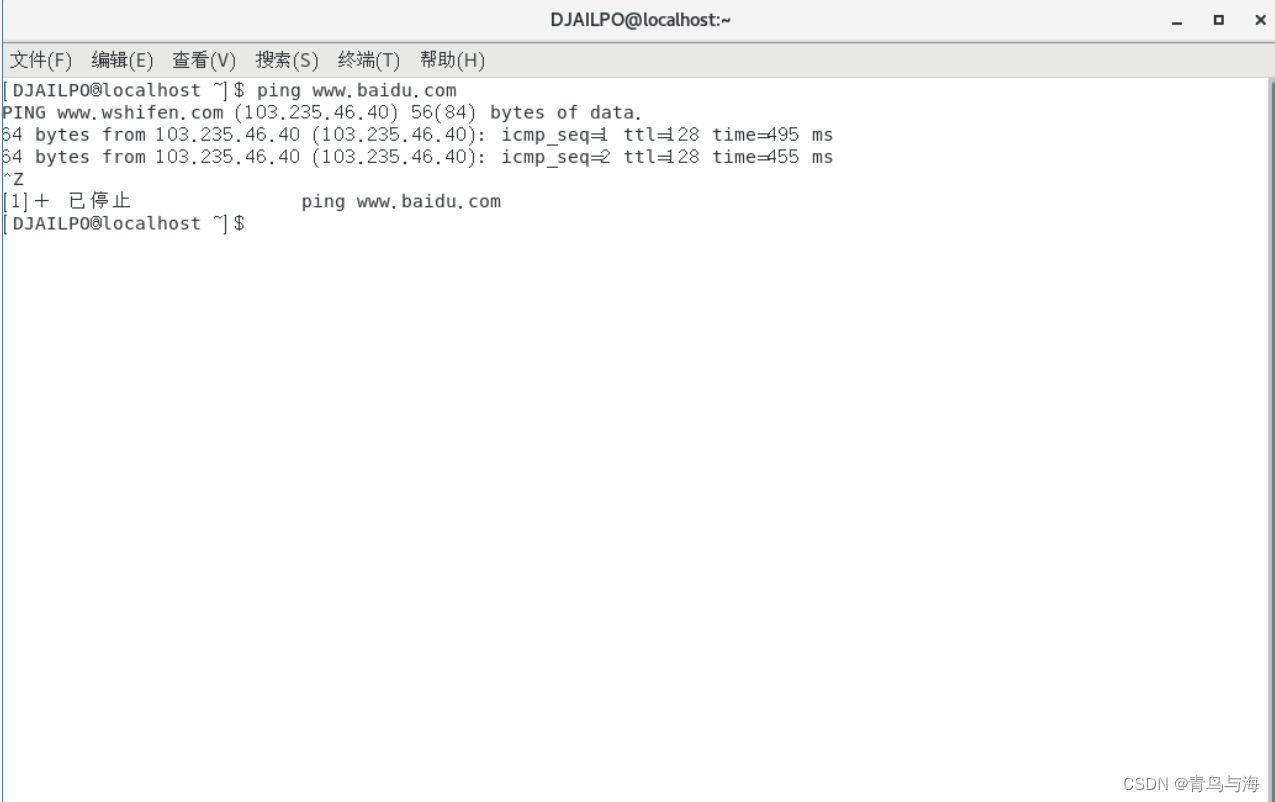
ping www.baidu.com 即可!成功!
19. 附:如果实在ping不出来看下一步

20. 连接上网络后进入网络配置文件
21. 在root用户下进入sudoers文件
vi /etc/sudoers
修改后强制保存退出即可!
22. 那么DJAILPO有了root相关权限后,就可以进入网络配置文件了
命令:sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
其中信息修改

23. 重启网络
systemctl restart network
1.2.2 网络配置方法二
1.先ping一下

2.进行网络配置
这里的普通用户设置拥有root权限。上文有,不在赘述。
sudo vi /etc/sysconfig/network-scripts/ifconfig-ens33
修改其中重要的几个参数或者是添加;注释可以不用管
BOOTPROTO=static #
ONBOOT=yes # 开机自动启动
IPADDR=192.168.21.131 # ip地址
GATEWAY=192.168.21.2 # 网关
NETMASK=255.255.255.255 # 子网掩码
DNS1=8.8.8.8 # DNS 设置首选和备用的 DNS 服务器的 IP 地址。在网络中查询域名时,系统将使用这些 DNS 服务器进行解析。
DNS2=114.114.114.114
3.重启网络
systemctl restart network
4.重启虚拟机 reboot
5.ping一下成功,配置完成!

1.3 相关内容设置
1.3.1 修改主机名
sudo vi /etc/hostname
重启虚拟机后生效
1.3.2 关闭防火墙
systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld.service #临时关闭防火墙
1.3.3 创建用户
root用户下进行:
useradd lizhiqiang # 创建用户lizhiqiang
passwd lizhiqiang #修改密码
1.3.4 配置用户root权限
vi /etc/sudoers
温馨提示:以下操作,若无特别提示,均在lizhiqiang用户下进行的!
进入lizhiqiang用户:su lizhiqiang
1.3.5 在/opt目录下创建文件夹
(1)在/opt目录下创建module、software文件夹
sudo mkdir /opt/module
sudo mkdir /opt/software
(2)修改module、software文件夹的所有者
sudo chown Hadoop: /opt/module
sudo chown Hadoop: /opt/software
1.4 卸载现有JDK
1.4.1 查询是否安装Java软件
rpm -qa | grep -i java
1.4.2 卸载该JDK
卸载命令:进入root用户进行卸载,不然会报错!
rpm -qa |grep -i java|xargs -n1 rpm -e --nodeps1.4.3 查看JDK安装路径
which java
1.5 配置JDK
1.5.1 将JDK导入到opt目录
这里我用的是WinSCP工具:使用的参考链接:WinSCP参考教程
1.5.2 查看软件包是否导入成功

1.5.3 解压JDK安装包到/opt/module目录下
tar -xvf jdk-8u162-linux-x64.tar.gz -C /opt/module
1.5.4 配置JDK环境变量
/opt/module/jdk1.8.0_162 #先获取JDK路径 在路径下使用命令pwd
sudo vi /etc/profile #打开/etc/profile文件,在profile文件末尾添加JDK路径加入以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar让修改后的文件生效:
source /etc/profile1.5.5 测试JDK是否配置成功
which java
javac
java -version

1.6 配置Hadoop
1.6.1 将hadoop安装包导入到/opt/module/software目录
同上用WinSCP将hadoop安装包导入到/opt/software目录下!
解压到opt目录下面的module文件夹下面:
tar -xvf hadoop-3.1.3.tar.gz -C /opt/module/1.6.2 将Hadoop添加到环境变量
sudo vi /etc/profile添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
1.6.3 修改后的文件生效
source /etc/profile1.6.4 测试是否配置成功
hadoop version
2.伪分布式配置
2.1 写到前面
配置文件均在 hadoop 安装目录下的 etc/hadoop 目录下
/opt/module/hadoop-3.1.3/etc/hadoop温馨提示:这里建议快照一下,保护状态!后面要用(将其命名为:jdk和hadoop配置完毕!伪分布式未配置前状态!因为配置完伪分布式后,我们需要恢复到这个状态去配置完全分布式!)
2.2 配置 core-site.xml
命令:
sudo vi core-site.xml在最后的configuration之间加入以下内容:
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Aimehadoop01:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data/tmp</value>
</property>
2.3 配置:hdfs-site.xml
命令:
sudo vi hdfs-site.xml加入内容的原理同上
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2.4 格式化(只用最开始的一次)
进入目录:
/opt/module/hadoop-3.1.3/bin命令:
hdfs namenode -format2.5 启动namenode和datanode
进入目录:/opt/module/hadoop-3.1.3/sbin
命令:hadoop-daemon.sh start namenode # 启动namenode
命令:hadoop-daemon.sh start datanode # 启动datanode
# 注意启动namenode和datanode时要关闭防火墙
命令:systemctl stop firewalld.service # 临时关闭防火墙
命令:systemctl status firewalld.service # 查看防火墙的状态
2.6 jps命令查看

2.7 web端查看HDFS文件系统
打开浏览器:输入:http://Aimehadoop01:9870 (其中Aimehadoop01是静态ip地址映射)
进入成功!伪分布式配置完成!

2.8 特殊说明
2.8.1 Log日志
查看name
cd /opt/module/hadoop-3.1.3/data/tmp/dfs/name/current/输入:
cat VERSION查看data
cd /opt/module/hadoop-3.1.3/data/tmp/dfs/data/current/输入:
cat VERSION2.8.2 重新格式化
删除目录:/opt/module/hadoop-3.1.3中的data和logs文件即可
命令:sudo rm -rf data 和 sudo rm -rf logs 然后在重新格式化即可!
注:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和logs日志,然后再格式化NameNode。
2.9 扩展(可选)
2.9.1 配置:yarn-site.xml
命令:
sudo vi yarn-site.xml加入内容:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Aimehadoop01</value>
</property>

2.9.2 配置:mapred-site.xml
命令:
sudo vi mapred-site.xml加入内容:
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

2.9.3 启动集群
启动前必须保证NameNode和DataNode已经启动!
进入目录:
cd /opt/module/hadoop-3.1.3/sbin命令:
yarn-daemon.sh start resourcemanager #启动ResourceManager
yarn-daemon.sh start nodemanager #启动NodeManager
2.9.4 web端查看
打开浏览器输入:
http://Aimehadoop01:8088/cluster
到此:伪分布式整体配置完毕!
3.完全分布式配置
3.1 准备3台客户机
客户机在最开始已经准备好了。忘掉的自己回去看伪分布式前言!
3.1.1 说明
1.虚拟机Aihadoop02和虚拟机Aihadoop03
创建用户lizhiqiang(可自行命名)并设置密码和上文类似。两个虚拟机都要创建!
2.设置用户lizhiqiang具有root权限(前文有详细教程,这里不在赘述)
3.修改主机名(前文有教程这里不在赘述)
4.添加映射关系!在文件hosts里面 (前文有教程这里不在赘述)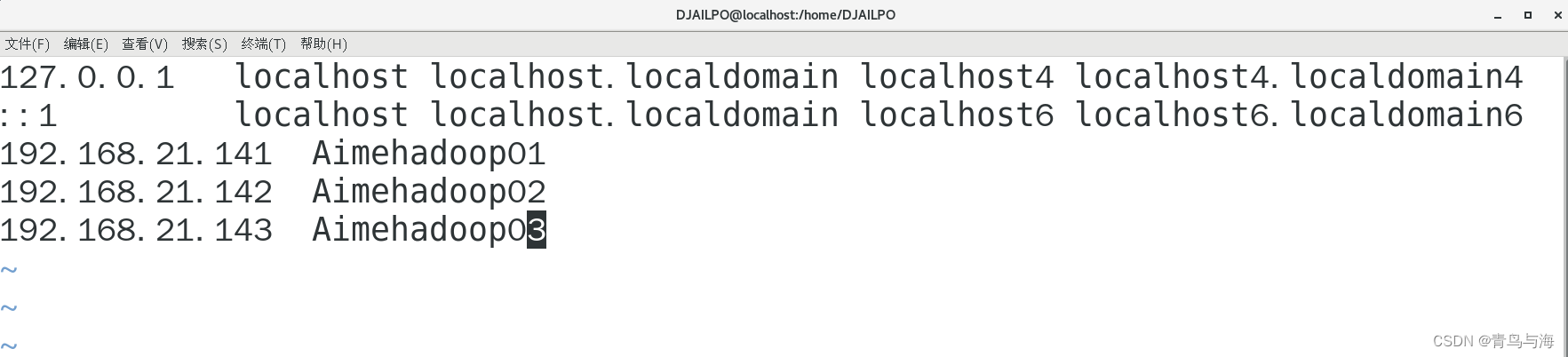
文件hosts
5.修改网络配置(以主机Aimehadoop02为例)
进入:
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33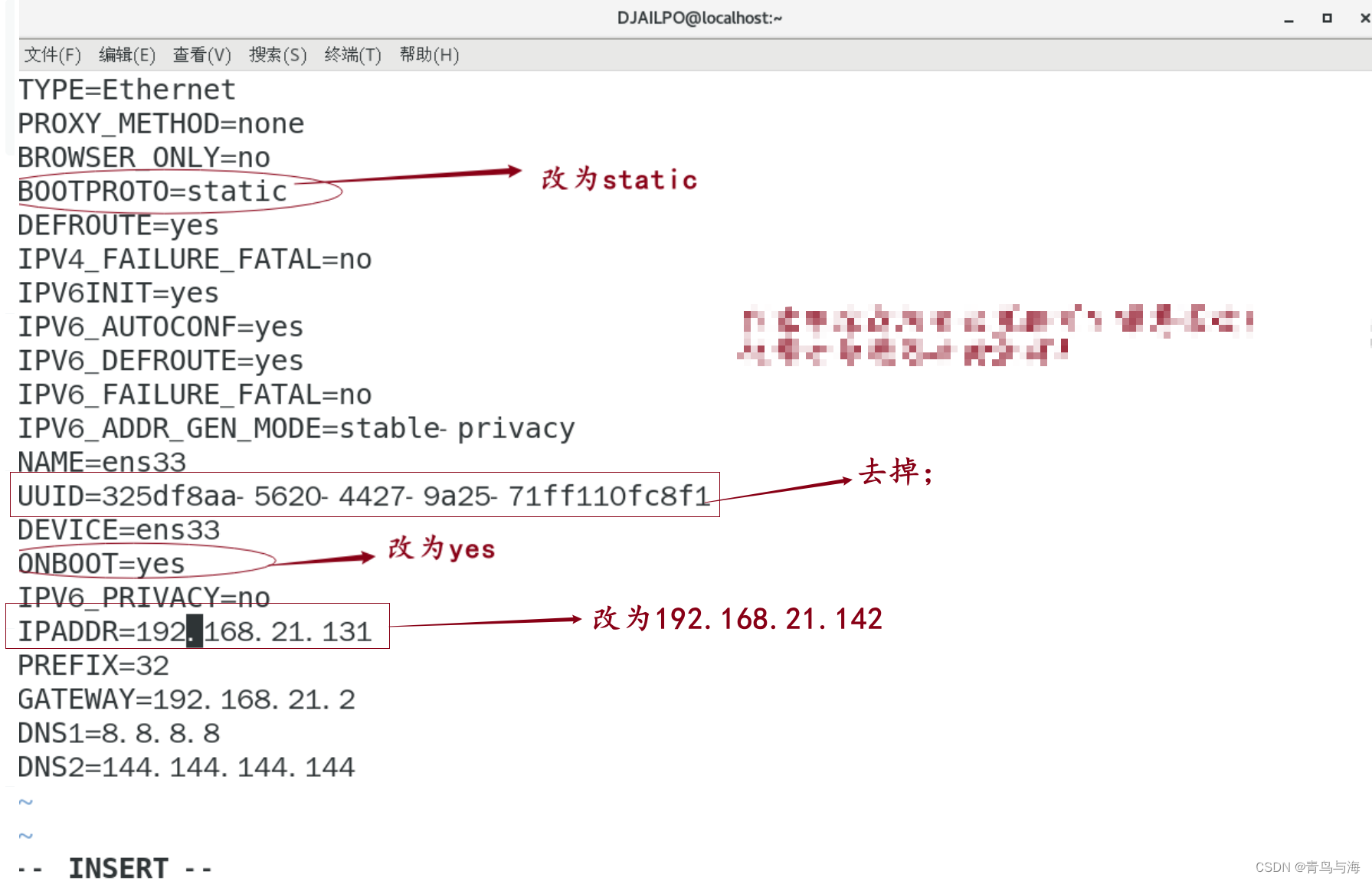
同理主机Aimehadoop03只需要在Aimehadoop02的IPADDR中修改为192.168.21.143即可!(这个ip是我的,你们的话要自己根据自己的ip来改变最后的位数)
6.重启网络
systemctl restart network7.重启虚拟机
reboot8. 最后一步

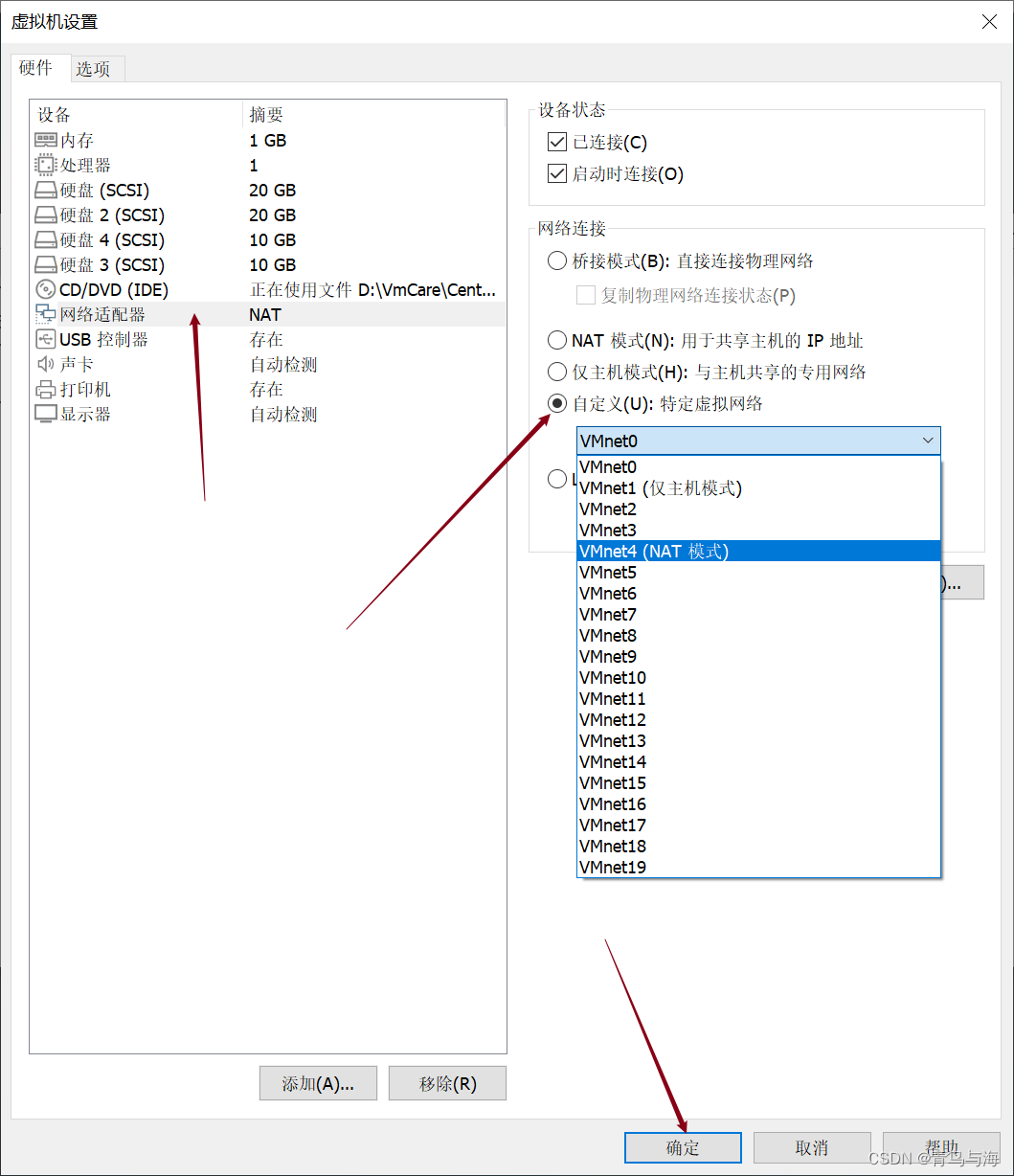
ping www.baidu.com有网即可
3.2 用工具将其他两个虚拟机配置好
3.2.1 工具说明
1.这里我们用工具,因为我们前面已经有了Aimehadoop01的配置jdk和hadoop过程!
(是配置完jdk和hadoop后,没有配置伪分布式前的状态哦!)
2.进入Aihadoop01虚拟机,恢复快照(状态为配置完jdk和hadoop后,没有配置伪分布式前)
3.在Aihadoop2和3中 卸载现有JDK 查询是否安装Java软件:
rpm -qa | grep -i java
4.如果有,卸载该JDK: 卸载命令:(进入root用户进行卸载,不然会报错!)
rpm -qa |grep -i java|xargs -n1 rpm -e --nodeps
5.查看JDK安装路径:which java
6.再次验证:rpm -qa | grep -i java 如果没有显示则说明卸载成功!3.2.2 scp(secure copy)安全拷贝
scp可以实现服务器与服务器之间的数据拷贝
基本语法:scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称1.在Aimehadoop01上,将Aimehadoop01上/opt/module目录下的软件拷贝到Aimehadoop02上。
先给Aimehadoop02 /opt目录设置权限777 :
sudo chmod 777 /opt2.在Aimehadoop01上 root用户 执行
scp -r /opt/module lizhiqiang@Aimehadoop02:/opt3.同理将Aimehadoop01中/opt/module目录下的软件拷贝到Aimehadoop03上.
4.在Aimehadoop01上 将Aimehadoop01上/etc/profile文件 拷贝到Aimehadoop02 /etc/profile上。
要将/etc/profile 权限设置为777 才可以。然后进入root用户。
scp /etc/profile lizhiqiang@Aimehadoop02 :/etc/profile5.同理将Aimehadoop01中/etc/profile目录下的软件拷贝到Aimehadoop03上.
拷贝过来的配置文件别忘了source一下/etc/profile,
3.2.3 rsync 远程同步工具(选择scp其中一个做)
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称1. 在Aimehadoop01上,将Aimehadoop01上/opt/module目录下的软件拷贝到Aimehadoop02上。
rsync -rvl /opt/module lizhiqiang@Aimehadoop02:/opt/2.在Aimehadoop01上 将Aimehadoop01上/etc/profile文件 拷贝到Aimehadoop02 /etc/profile上。
rsync -rvl /etc/profile lizhiqiang@Aimehadoop02 :/etc/profile3.同理将Aimehadoop01中/etc/profile目录下的软件拷贝到Aimehadoop03上.
3.3 SSH免密登录
3.3.1 免密登录原理

3.3.2 生成公钥和私钥
只需要在Aimehadoop01生成密钥对,并将公钥复制到每个需要访问的远程节点上。
ssh-keygen -t rsa #一直按回车直到生成结束即可!执行结束之后每个节点上的/root/.ssh/目录下生成了两个文件 id_rsa 和 id_rsa.pub
3.3.3 公钥拷贝
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id Aimehadoop01
ssh-copy-id Aimehadoop02
ssh-copy-id Aimehadoop033.3.4 登录
ssh 主机名

3.3.5 重新生成密钥对
rm -rf ~/.ssh #这将删除旧的SSH密钥对!然后再根据步骤2生成即可!
3.4 xsync.sh集群分发脚本 (重要!!!)
3.4.1 创建xsync.sh脚本
在/root/目录下创建bin目录,并在bin目录下xsync.sh创建文件,文件内容编写代码如下:
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in Aimehadoop01 Aimehadoop02 Aimehadoop03
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -rvl $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
3.4.2 修改xsync.sh脚本权限
chmod 777 xsync.sh3.4.3 执行脚本
xsync.sh 文件名称
xsync.sh /home/lizhiqiang/bin
#(这个语句的含义是将本机上的 /home/lizhiqiang/bin 路径经过xsync.sh脚本分别分发给里面三台虚拟机)
#那么此时那三台虚拟机就都有这个路径 /home/lizhiqiang/bin 了!因此省去了每台虚拟机都要写文件和修改配置文件的麻烦! 

执行完xsync.sh这个脚本后


这里的bin就是Aimehadoop01执行脚本的命令分配的!里面的所有内容跟Aimehadoop01一致!
3.5 集群配置
3.5.1 集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
3.5.2 核心配置文件
(1)前言
目录均在:/opt/module/hadoop-3.1.3/etc/hadoop 下进行。
配置文件hadoop-env.sh 、yarn-env.sh、mapred-env.sh
并在它们的末尾都加上你自己的jdk路径:
export JAVA_HOME=/opt/module/jdk1.8.0_162
(2)配置core-site.xml
sudo vi core-site.xml加入内容:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://AimeHadoop1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data/tmp</value>
</property>

(3)配置hdfs-site.xml
sudo vi hdfs-site.xml加入以下内容:
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Aimehadoop03:50090</value>
</property>
(4)配置yarn-site.xml
sudo vi yarn-site.xml加入以下内容:
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Aimehadoop03</value>
</property>
(5)配置mapred-site.xml
sudo vi mapred-site.xml加入以下内容:
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

3.5.3 执行xsync.sh脚本
使用xsync.sh脚本将其他另外两个虚拟机配置了!
进入脚本xsync路径:
/home/lizhiqiang/bin执行命令:
./xsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/此时另外两个虚拟机的配置文件都配置完毕(可以自行查看是否配置完成!)建议保存这些虚拟机此时的状态!
3.5.4 配置workers
路径:
/opt/module/hadoop-3.1.3/etc/hadoop命令:
vi workers
在路径/home/lizhiqiang/bin/ 执行命令将workers分配给每个虚拟机!
./xsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/workers自行查看是否成功!
3.5.5 格式化NameNode
集群是第一次启动,需要格式化NameNode (执行前必须关闭防火墙!!!)
进入目录:
/opt/module/hadoop-3.1.3/bin命令:
hdfs namenode -format 这些命令每一个虚拟机都要做!!!
3.5.6 启动
在主虚拟机也就是Aimehadoop01上(前提是步骤8都做了!)
进入目录:
/opt/module/hadoop-3.1.3/sbin执行:
start-all.sh
同理:stop-all.sh那么所有虚拟机的所有相应节点都会关闭!!
3.5.7分别在虚拟机上查看启动情况



3.5.8 Web端查看SecondaryNameNode
(1)浏览器中输入:http://Aimehadoop03:50090
(2)查看SecondaryNameNode信息

到此为止,集群分布式搭建基本完毕!感谢各位的观看!希望能够对你有所帮助!
参考链接:
大数据之Hadoop3.x 运行环境搭建(手把手搭建集群)_hadoop环境搭建-CSDN博客 https://blog.csdn.net/yuan2019035055/article/details/120901871搭建 Hadoop 集群详细教程_配置hadoop集群-CSDN博客https://blog.csdn.net/sculpta/article/details/107850280?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107850280-blog-123782963.235%5Ev38%5Epc_relevant_sort_base2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107850280-blog-123782963.235%5Ev38%5Epc_relevant_sort_base2&utm_relevant_index=1三分钟完成虚拟机联网 小白看了都说好!!! 虚拟机超详细联网教程/步骤 SDN软件定义网络实验_虚拟机联网教程_九号迷妹的博客-CSDN博客https://blog.csdn.net/qq_53429158/article/details/119043547?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%80%8E%E4%B9%88%E8%AE%A9%E8%99%9A%E6%8B%9F%E6%9C%BA%E6%9C%89%E7%BD%91&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-119043547.nonecase&spm=1018.2226.3001.4187WinSCP 使用教程-CSDN博客https://zhengys.blog.csdn.net/article/details/107138719?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107138719-blog-120220823.235%5Ev38%5Epc_relevant_anti_t3_base&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107138719-blog-120220823.235%5Ev38%5Epc_relevant_anti_t3_base&utm_relevant_index=1&ydreferer=aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI2MzgzOTc1L2FydGljbGUvZGV0YWlscy8xMjAyMjA4MjM%2Fb3BzX3JlcXVlc3RfbWlzYz0lMjU3QiUyNTIycmVxdWVzdCUyNTVGaWQlMjUyMiUyNTNBJTI1MjIxNjk1MzUwNDEyMTY4MDAxODg1ODgzNTUlMjUyMiUyNTJDJTI1MjJzY20lMjUyMiUyNTNBJTI1MjIyMDE0MDcxMy4xMzAxMDIzMzQuLiUyNTIyJTI1N0QmcmVxdWVzdF9pZD0xNjk1MzUwNDEyMTY4MDAxODg1ODgzNTUmYml6X2lkPTAmdXRtX21lZGl1bT1kaXN0cmlidXRlLnBjX3NlYXJjaF9yZXN1bHQubm9uZS10YXNrLWJsb2ctMn5hbGx%2BdG9wX2NsaWNrfmRlZmF1bHQtMS0xMjAyMjA4MjMtbnVsbC1udWxsLjE0Ml52OTReY29udHJvbCZ1dG1fdGVybT13aW5zY3AlRTUlQUUlODklRTglQTMlODUlRTYlOTUlOTklRTclQTglOEImc3BtPTEwMTguMjIyNi4zMDAxLjQxODc%3D
https://blog.csdn.net/yuan2019035055/article/details/120901871搭建 Hadoop 集群详细教程_配置hadoop集群-CSDN博客https://blog.csdn.net/sculpta/article/details/107850280?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107850280-blog-123782963.235%5Ev38%5Epc_relevant_sort_base2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107850280-blog-123782963.235%5Ev38%5Epc_relevant_sort_base2&utm_relevant_index=1三分钟完成虚拟机联网 小白看了都说好!!! 虚拟机超详细联网教程/步骤 SDN软件定义网络实验_虚拟机联网教程_九号迷妹的博客-CSDN博客https://blog.csdn.net/qq_53429158/article/details/119043547?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%80%8E%E4%B9%88%E8%AE%A9%E8%99%9A%E6%8B%9F%E6%9C%BA%E6%9C%89%E7%BD%91&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-119043547.nonecase&spm=1018.2226.3001.4187WinSCP 使用教程-CSDN博客https://zhengys.blog.csdn.net/article/details/107138719?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107138719-blog-120220823.235%5Ev38%5Epc_relevant_anti_t3_base&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-107138719-blog-120220823.235%5Ev38%5Epc_relevant_anti_t3_base&utm_relevant_index=1&ydreferer=aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI2MzgzOTc1L2FydGljbGUvZGV0YWlscy8xMjAyMjA4MjM%2Fb3BzX3JlcXVlc3RfbWlzYz0lMjU3QiUyNTIycmVxdWVzdCUyNTVGaWQlMjUyMiUyNTNBJTI1MjIxNjk1MzUwNDEyMTY4MDAxODg1ODgzNTUlMjUyMiUyNTJDJTI1MjJzY20lMjUyMiUyNTNBJTI1MjIyMDE0MDcxMy4xMzAxMDIzMzQuLiUyNTIyJTI1N0QmcmVxdWVzdF9pZD0xNjk1MzUwNDEyMTY4MDAxODg1ODgzNTUmYml6X2lkPTAmdXRtX21lZGl1bT1kaXN0cmlidXRlLnBjX3NlYXJjaF9yZXN1bHQubm9uZS10YXNrLWJsb2ctMn5hbGx%2BdG9wX2NsaWNrfmRlZmF1bHQtMS0xMjAyMjA4MjMtbnVsbC1udWxsLjE0Ml52OTReY29udHJvbCZ1dG1fdGVybT13aW5zY3AlRTUlQUUlODklRTglQTMlODUlRTYlOTUlOTklRTclQTglOEImc3BtPTEwMTguMjIyNi4zMDAxLjQxODc%3D















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









