









哈喽,我是我不是小upper~
今天咱们来深入了解一个和信息论紧密相关的知识点 —— 信息增益。信息增益在很多领域都有重要应用,尤其是在机器学习构建决策树的过程中,它可是个 “得力助手”。
首先,得搞清楚信息增益到底是什么。简单来讲,信息增益就是一种衡量 “某个特征有没有用” 的工具。具体来说,它衡量的是我们在知道某个信息之后,不确定性减少了多少。
为了让大家更好理解,我来举个例子。假设你现在是一名侦探,正在调查一个案件,目前有 100 个嫌疑人。
一开始,你对这个案子几乎一无所知,每个嫌疑人都有可能是凶手,他们的可能性均等。在这种情况下,你心里肯定充满了疑惑,完全不知道该从哪里入手,此时的不确定性达到了最大。这就好比在黑暗中摸索,周围全是迷雾,根本看不清方向。
然后,事情出现了转机,有人给你提供了一条关键信息:“凶手是男的”。根据这条线索,你马上可以把女性嫌疑人排除掉。假设这 100 个嫌疑人里女性有 60 人,那么筛掉她们之后,就只剩下 40 个男性嫌疑人了。对比之前,现在你的困惑程度是不是大大降低了呢?从原本要在 100 个人里找凶手,变成了只在 40 个人里找,范围一下子缩小了很多。而这个因为知道了 “凶手是男的” 这条信息,导致困惑程度减少的量,就是信息增益。它就像是在黑暗中为你点亮了一盏灯,帮你照亮了一部分前行的道路,让你离真相更近了一步。
那么,信息增益跟机器学习里的决策树又有什么关系呢?在决策树算法中,有一个很经典的 ID3 算法。在构建决策树的过程中,有一个关键步骤就是选择 “分裂节点”,简单理解,就是决定用哪个特征来划分数据。这时候,信息增益就派上用场了。我们会用信息增益来判断:到底哪个特征能最有效地减少数据的混乱程度?也就是说,用哪个特征来划分数据,能让原本杂乱无章的数据变得更加 “有条理”“更干净”,让我们能更清晰地从数据中找到规律、做出决策。比如在分析客户购买行为数据时,可能有客户年龄、性别、收入等多个特征,通过计算每个特征的信息增益,我们就能知道哪个特征对判断客户是否购买商品最有帮助,然后就选择这个特征来构建决策树的节点,一步一步将数据划分得越来越细致,最终形成一个能够准确预测客户购买行为的决策树模型。
原理详解
在深入了解信息增益之前,我们得先掌握一些基本概念,其中最重要的就是熵(Entropy),它可是信息论的核心概念。
1. 基本概念:信息论核心 —— 熵(Entropy)
熵是由香农提出的,专门用来度量 “随机变量不确定性” 的一个指标。这里说的随机变量,就好比我们在机器学习里经常遇到的类别标签,比如预测明天是晴天、阴天还是雨天,“天气状况” 就是一个随机变量;又比如判断一封邮件是垃圾邮件还是正常邮件,“邮件类别” 也是随机变量。
熵的计算公式是:
这里面,X代表随机变量,就像前面提到的 “天气状况” 或者 “邮件类别”;是X的第i个取值,假如X是 “天气状况”,那
可能是 “晴天”“阴天”“雨天” 这些具体的天气情况;
表示
发生的概率,如果根据以往的天气数据统计,晴天出现的概率是 0.3,那 p(晴天)=0.3。
从这个公式可以看出,熵越大,意味着系统越混乱、越不确定。打个比方,如果一个城市每天晴天、阴天、雨天出现的概率都差不多,那这个城市的天气熵值就比较大,因为很难准确预测明天到底是什么天气;相反,如果一个地方常年都是晴天,那它的天气熵值就很小,甚至接近 0,因为天气状况非常确定。当熵为 0 时,表示这个随机变量的取值是完全确定的,没有任何不确定性。
2. 信息增益
理解了熵之后,我们再来看看信息增益(Information Gain,简称 IG)。信息增益主要表示在知道某个特征A的取值后,目标变量Y的熵减少了多少。
它的定义公式是:
这里的表示在不知道任何特征时,目标变量Y的不确定性,也就是目标变量Y的原始熵。比如说,我们要预测客户是否会购买某件商品,在没有任何其他信息的情况下,每个客户购买或不购买的不确定性就是
。
而\(H(Y|A)\)代表在知道特征A的取值之后,目标变量Y的条件熵。比如说特征A是客户的年龄,当我们知道了客户的年龄信息后,客户购买商品的不确定性就变成了。
信息增益就是两者的差值,它衡量的就是因为知道了特征A的取值,目标变量Y的熵减少了多少,换种说法,就是目标变量Y的不确定性降低了多少。信息增益越大,说明这个特征A对确定目标变量Y的值就越有帮助。
3. 条件熵
为了计算信息增益,我们还需要知道特征A下Y的条件熵\(H(Y|A)\),它的公式是:
这里的是特征A的第j个取值,比如说特征A是性别,那
就是 “男” 或 “女”;
是样本中
的比例,假如在我们的样本数据里,男性占总人数的 55%,那p(男)=0.55;
表示在
的情况下,Y的熵,还是以预测客户是否购买商品为例,H(Y|A = 男)就是在客户是男性的情况下,他们购买商品的不确定性。
我们把这个公式展开来看,会更加清晰。假设特征A有m个不同的取值,对于每个取值,我们都要计算
与
的乘积,然后把这些乘积都加起来,就得到了
。通过这样一步步的计算,我们就能准确地算出信息增益,从而判断出每个特征对于目标变量的重要程度,这在机器学习构建决策树等算法中非常关键。
展开:
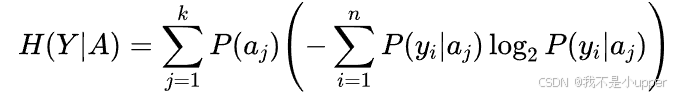
信息增益完整案例:基于鸢尾花数据集的深入剖析
在这部分内容中,我们将通过经典的鸢尾花(Iris)数据集,详细展示如何计算各特征的信息增益,依据信息增益选择最优划分,以及对结果进行可视化分析。同时,还会介绍针对大规模数据场景下的算法优化方法。
数据准备
首先,我们要准备好用于分析的数据。借助sklearn.datasets库中的load_iris函数,我们可以轻松载入鸢尾花数据集。随后,利用pandas库将数据整理成DataFrame格式,这样更便于我们对数据进行查看和处理。在这个数据集中,目标变量(也就是鸢尾花的类别)原本是用 0、1、2 这样的数字编码表示的,为了更直观地理解,我们将其转换为中文标签。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
# 载入鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# 将 species 替换为中文
mapping = {'setosa':'山鸢尾', 'versicolor':'杂色鸢尾', 'virginica':'维吉尼亚鸢尾'}
df['species_cn'] = df['species'].map(mapping)
df.head()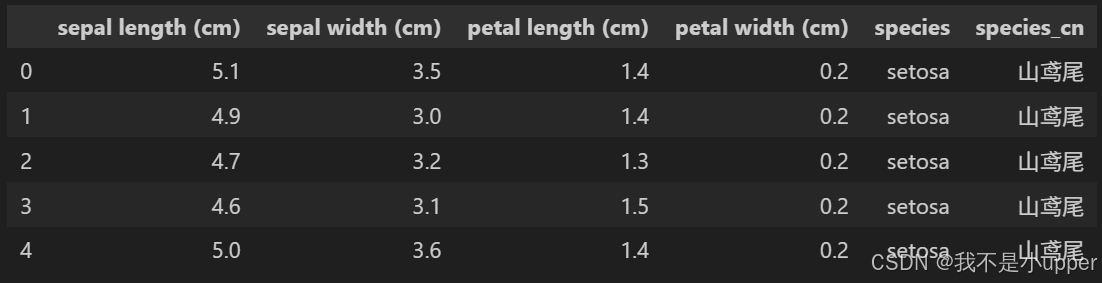
经过处理后,我们得到的df数据集包含 150 条样本记录。每条样本都具有 4 个特征,分别是萼片长度、萼片宽度、花瓣长度和花瓣宽度。species_cn列则使用中文明确表示了鸢尾花的类别,这在后续展示结果时会更加直观方便。接下来,我们将基于某个特征的特定阈值对数据集进行二叉划分,进而计算信息增益。
熵与信息增益计算
熵(Entropy)
根据之前介绍的熵的定义公式,在给定类别分布的情况下,我们可以通过以下代码实现熵的计算。
def entropy(y):
"""计算标签序列 y 的熵值"""
counts = np.bincount(y)
probs = counts / counts.sum()
probs = probs[probs > 0]
return -np.sum(probs * np.log2(probs))在这段代码中,输入的y是用整数编码的类别向量。首先,np.bincount(y)函数用于统计每个类别出现的次数。然后,通过将每个类别的出现次数除以总次数,得到每个类别的概率probs。这里probs = probs[probs > 0]这一步是为了去除概率为 0 的类别(因为在实际计算中,概率为 0 的类别参与计算会导致错误)。最后,根据熵的计算公式
,
通过-np.sum(probs * np.log2(probs))计算出熵值。熵值越大,意味着分类的不确定性越高;反之,熵值越小,分类就越确定。
信息增益(Information Gain)
信息增益用于衡量在依据某个特征的阈值对数据集进行划分后,数据集不确定性的减少程度。下面是计算信息增益的代码实现。
def information_gain(X, y, feature_idx, threshold):
"""
计算在 feature_idx 上以 threshold 划分的信息增益
X: 特征矩阵,shape=(n_samples, n_features)
y: 标签向量,shape=(n_samples,)
"""
parent_entropy = entropy(y)
# 划分索引
left_idx = X[:, feature_idx] <= threshold
right_idx = ~left_idx
# 加权熵
n, n_left, n_right = len(y), left_idx.sum(), right_idx.sum()
if n_left == 0 or n_right == 0:
return 0.0
e_left = entropy(y[left_idx])
e_right = entropy(y[right_idx])
child_entropy = (n_left/n) * e_left + (n_right/n) * e_right
return parent_entropy - child_entropy在计算信息增益时,首先计算父节点(也就是未进行划分的原始数据集)的熵parent_entropy,这一步调用了前面定义的entropy函数。然后,根据给定的特征索引feature_idx和阈值threshold,将数据集划分为左右两个子集,left_idx和right_idx分别表示左右子集的索引。接下来,计算左右子集的样本数量n_left和n_right,如果其中一个子集的样本数量为 0,说明这种划分没有意义,信息增益直接返回 0。之后,分别计算左右子集的熵e_left和e_right,再根据左右子集样本数量占总样本数量的比例,计算加权熵child_entropy。最后,信息增益等于父节点的熵减去加权熵,即parent_entropy - child_entropy。信息增益越大,说明按照这个特征和阈值进行划分后,数据集变得越 “纯净”,不确定性下降得越多。
可视化分析
为了更直观地找到最优划分阈值,我们挑选 “花瓣长度(petal length)” 这一特征进行分析。通过计算一系列可能阈值下的信息增益,并绘制信息增益曲线,我们就能确定最优阈值。
import matplotlib.pyplot as plt
# 准备数据
X = df[iris.feature_names].values
y = iris.target
feat_idx = iris.feature_names.index('petal length (cm)')
values = np.unique(X[:, feat_idx])
thresholds = (values[:-1] + values[1:]) / 2 # 中点作为候选阈值
# 计算信息增益
ig_list = [information_gain(X, y, feat_idx, t) for t in thresholds]
# 绘制
plt.figure(figsize=(10,6))
plt.plot(thresholds, ig_list, marker='o', linewidth=2)
plt.xlabel('Threshold (cm)')
plt.ylabel('Information Gain')
plt.title('Information Gain vs Threshold\non Petal Length')
plt.grid(True, linestyle='--', alpha=0.5)
plt.fill_between(thresholds, ig_list, color='orange', alpha=0.3)
plt.scatter(thresholds[np.argmax(ig_list)], max(ig_list), s=150, color='red', label='Best Split')
plt.legend()
plt.show()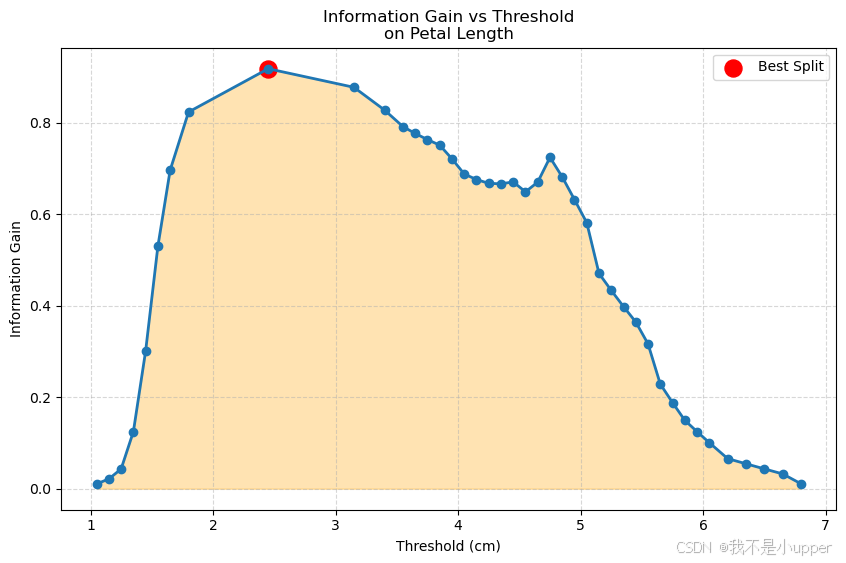
在这段代码中,首先提取数据集的特征矩阵X和标签向量y,并确定 “花瓣长度” 特征的索引feat_idx。然后,通过np.unique函数获取 “花瓣长度” 特征的所有唯一值,将相邻唯一值的中点作为候选阈值thresholds。接着,使用列表推导式,对每个候选阈值调用information_gain函数,计算出对应的信息增益,存储在ig_list中。最后,使用matplotlib库绘制信息增益曲线。横坐标表示候选阈值,纵坐标表示信息增益。曲线中的峰值点对应的阈值就是最优阈值,因为在这个阈值下,熵下降得最多,数据集划分得最 “纯净”。
算法优化
在处理大规模数据或高维数据时,前面逐阈值循环计算信息增益的方法会变得比较耗时。为了提高计算效率,我们可以采用向量化统计和增量式熵更新的方法进行优化。
def fast_best_split(X_col, y):
"""
向量化求单特征 X_col 最优划分点及对应信息增益
返回: (best_threshold, best_ig)
"""
# 排序
sorted_idx = np.argsort(X_col)
Xs, Ys = X_col[sorted_idx], y[sorted_idx]
# 全局熵
H_parent = entropy(Ys)
n = len(Ys)
# 初始化左/右计数
unique_classes = np.unique(Ys)
left_count = np.zeros(unique_classes.max()+1, dtype=int)
right_count = np.bincount(Ys, minlength=unique_classes.max()+1)
best_ig, best_t = 0.0, None
# 遍历可能分割点(跳过相同值)
for i in range(1, n):
c = Ys[i-1]
left_count[c] += 1
right_count[c] -= 1
if Xs[i] == Xs[i-1]:
continue
# 当前阈值
t = (Xs[i] + Xs[i-1]) / 2
# 计算左右熵(增量式)
H_left = -np.sum((left_count/ i) * np.log2(left_count/ i + 1e-9) * (left_count>0))
H_right = -np.sum((right_count/ (n-i)) * np.log2(right_count/ (n-i) + 1e-9) * (right_count>0))
ig = H_parent - (i/n)*H_left - ((n-i)/n)*H_right
if ig > best_ig:
best_ig, best_t = ig, t
return best_t, best_ig
best_threshold, best_ig = fast_best_split(X[:, feat_idx], y)
print(f"Optimized Best Threshold: {best_threshold:.3f}, Info Gain: {best_ig:.4f}")
在优化后的代码中,首先使用np.argsort对特征X_col进行排序,这样可以一次性计算所有可能划分点的左右计数。排序后的特征和标签分别存储在Xs和Ys中。接着计算全局熵H_parent,并初始化左右子集的类别计数left_count和right_count。在遍历可能的分割点时,每移动到一个新的分割点,只需要更新从左到右的一个样本类别计数,而不需要每次都重新扫描左右子集来计算熵,这就是增量式熵更新。在计算左右熵时,使用了类似熵计算公式的方法,但考虑了左右子集的样本数量变化。通过比较每次计算得到的信息增益ig,记录下最大信息增益对应的阈值best_t和信息增益值best_ig。最后返回最优阈值和最大信息增益。这种优化方法预先对数据进行排序,时间复杂度为 O (n log n),并且通过统计向量left_count与right_count,在单次遍历中就能完成增量更新,相比原来的方法,在大数据规模下效率有显著提升。
运行优化后的代码,得到结果:“Optimized Best Threshold: 2.450, Info Gain: 0.9183”,这表明在 “花瓣长度” 特征上,最优阈值约为 2.45 cm,对应的信息增益约为 0.9183。通过这个阈值划分数据,基本可以将 “山鸢尾” 与其余两类鸢尾花分离,使得数据集的熵显著下降。
最后
信息增益由于其概念清晰、理论基础扎实,在分类决策树算法中得到了广泛应用。不过在实际的工程项目中,我们需要结合数据的具体特性,比如特征基数、样本规模、实时性需求等,灵活选择合适的度量方法,或者用增益率、基尼指数、方差减少等度量方法来替换信息增益,这样才能在模型的精度、计算效率以及可解释性之间找到最佳的平衡。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









